8.0.28以下的MTS可能在运行一段时间后出现hang死的情况,大概如下(模拟的):
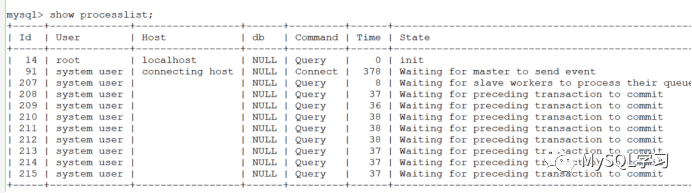
这个问题因此有一个2的31次方事务后触发的界限,实际上就是int类型的溢出导致,因此为定时炸弹,BUG如下:
这个BUG由印风提交,可以看出来跑了很久才触发,着实费劲,感谢大佬,否则真的很难知道为什么。
二、关于slave_preserve_commit_order的实现
实际上本参数主要控制的是从库的提交顺序和主库一致,其实现大概分为两个步骤:
在8.0中主要通过一个全局的Commit_order_manager结构进行记录,其中有2个部分比较重要:
1. 一个全部worker线程信息的vecoter容器,有多少个worker线程容器中就有多少个元素,其中每个元素代表一个worker,叫做node,包含一些重点的成员变量如下:
其中m_commit_sequence_nr和m_mdl_context是为唤醒worker线程准备的,这点和5.7不同,5.7中为全部唤醒然后每个worker循环判断。
while (queue_front() != worker->id)
8.0为精准唤醒,每个节点的m_commit_sequence_nr信息来自全局的m_commit_sequence_generator生成器。而m_stage主要由如下一些不同的状态,标记不同的截断。
FINISHED_APPLYING:事务已经应用,但可能没有提交,如果需要等待提交顺序转为REQUESTED_GRANT状态
REQUESTED_GRANT:事务不能提交,需要等到当前运行worker授予
MDL LOCK REGISTERED:事务已经注册也就是SQL线程分发了。
另外对于唤醒操作用的应该是MDL LOCK现成的实现。
2.一个提交队列,这个很显然,当worker线程第一次发现不是自己提交顺序的时候,就是根据这个提交队列来的,其为m_commit_queue,其为一个无锁化队列,暂未对无锁化进行研究,但是对其方法和push,pop,<>等函数的注释可以看出是一个先进先出的队列,比如:
其中Retrieves the value at the virtual index pointed by the head of the queue, clears that position,说明了其>>操作的作用,也就是从头部取信息,并且清理这个位置。
其包含的重点步骤有:
Commit_order_manager::register_trx ->cs::apply::Commit_order_queue::push
其中主要完成的步骤为将分配的worker的信息记录到node中,同时根据m_commit_sequence_generator生成器生成一个提交序列(本bug就是和这个生成器有关,重启实际上是重置了这个内存计数器),每个事务都会让这个计数器加1。并且将这个worker的work id 放入m_commit_queue队列中。并且将node的状态置为REGISTERED。
Commit_order_manager::wait ->Commit_order_manager::wait_on_graph
当worker线程准备提交的时候,也就是在进入flush队列之前,需要判断自己是否可以提交,这个时候判定的原则是当前worker 的node信息的worker id是否和m_commit_queue队列的头部worker id相同,
if (this->m_workers.front() != worker->id)
因为前面我们说了,m_commit_queue队列实际上就是记录的根据分发顺序记录的worker id。如果不能提交则进入等待,状态改为REQUESTED_GRANT,这个时候这个worker是需要别的worker唤醒的。
MYSQL_BIN_LOG::change_stage (Commit_stage_manager::BINLOG_FLUSH_STAGE) ->Commit_stage_manager::enroll_for ->Commit_order_manager::finish_one
注意这里是BINLOG_FLUSH_STAGE,也就是在保证flush队列的顺序,实际上也保证了commit队列的顺序,最终完成唤醒的函数是Commit_order_manager::finish_one,这个唤醒过程主要完成的任务就是唤醒下一个正在等待的worker线程,其重要方式为从m_commit_queue队列的头部拿一个worker id,实际上就是要唤醒的worker,然后通过下面3个条件来判定是否唤醒:
1)当前有worker线程
2)通过提交队列头部获取的下一个worker线程,其节点状态为FINISHED_APPLYING或者REQUESTED_GRANT
C)通过提交队列头部获取的下一个worker线程,其节点的m_commit_sequence_nr信息必须和当前提交事务的worker id的m_commit_sequence_nr+1 相同
A&&B&&C 同时满足才能唤醒下一个应该唤醒worker线程,实际上从现有的分析来看,这个过程不太可能出问题。但是BUG就出现C条件上。
现在我们来画一个图描述这种唤醒方式。假设,当前worker有4个,worker id分别为 0,1,2,3。当前全局计数器来到了2147483640,并且能够并发的GTID的seq number分别为4147483647,2147483648,2147483649,2147483650,而4147483647为较大的事务,因此在他提交之前其他3个事务不能提交。
然后其中4147483647分配给了worker 2,4147483648分配给了worker 0,4147483649 分配给了 worker 1,4147483650分配给了worker 3。那么当前等待和执行的图如下:
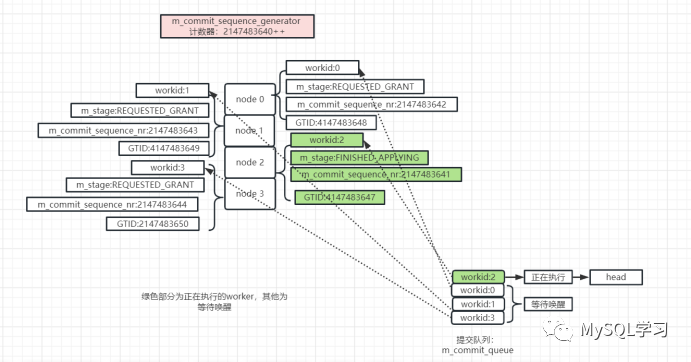
当GTID 4147483647事务执行完成后,需要唤醒GTID 4147483648事务,那么从m_commit_queue中取下一个workid:0就可以了,但是这里要比2147483641+1 是否等于2147483642,否则唤醒,也就是C条件,当然这里没有问题。
前面我们看到一个2147483641+1 是否等于2147483642是否成立的条件,但是在代码中虽然worker线程的m_commit_sequence_nr和m_commit_sequence_generator都是unsigned long long类型也就是8字节不带符号位的,但是自动推导的变量当worker的m_commit_sequence_nr的取出来后确实保存在一个int类型的变量中,也就是如下:auto this_seq_nr{0};
然后 this_seq_nr+1,如果这里this_seq_nr是2147483647,加1后者会发生溢出,如下:
(gdb) p this_seq_nr$4 = 2147483647(gdb) ptype this_seq_nrtype = int(gdb) p next_seq_nr$3 = -2147483648(gdb) ptype next_seq_nrtype = int
其中就是next_seq_nr发生了溢出,来到了负数。这个时候会比对-2147483648是否等于2147483648,如果等于才会唤醒,显然这里就不满足了,因此BUG产生,BUG产生后任何worker都不能唤醒,参考上面的图。-2147483648实际上就是
1000 0000 0000 0000 0000 0000 0000 0000
也就是2147483647+1
0111 1111 1111 1111 1111 1111 1111 1111
加了一个1因为符号位为1了,因此显示了最大的负数,也就是- 2的31次方,实际就是溢出了。这里可以用auto this_seq_nr{0ull}; 让自动推导为unsigned long long类型,则不会溢出。
因为所有的事务每次提交都会获取一个提交序列m_commit_sequence_nr,其来自全局生成器m_commit_sequence_generator,而m_commit_sequence_generator初始化的时候为1,我们直接修改其初始化值为2147483640,这样很快就会出现溢出的情况,否则模拟2147483647个事务不太现实。同时我们主库设置writeset,同时使用多核CPU,从库设置8个并行线程,意为最大限度的加大并发。
mysql> set global transaction_write_set_extraction=XXHASH64;Query OK, 0 rows affected (0.00 sec)mysql> set global binlog_transaction_dependency_tracking=WRITESET;Query OK, 0 rows affected (0.00 sec)
经过编译后,从库稳定重现。
重现后的DEBUG方式,这里选用条件断点,并且打到Commit_order_manager::finish_one的286行左右,由于断路原则,A&&B条件需要满足才会跑这个条件,也就是需要唤醒比较提交序列的时候,代码的this->m_workers[next_worker].freeze_commit_sequence_nr这行。
break rpl_slave_commit_order_manager.cc:286 if next_seq_nr < 0
观察:
(gdb) p *(this->m_workers[next_worker].m_commit_sequence_nr.m_underlying)
$11 = {<std::__atomic_base<unsigned long long>> = {static _S_alignment = 8, _M_i = 2147483648}, }
(gdb) p next_seq_nr
$12 = -2147483648
显然worker自生的m_commit_sequence_nr没有问题为2147483648,但是取出来后就是-2147483648并不相等,因此条件C不满足不做唤醒。
需要注意的是本问题和slave_preserve_commit_order参数有关,如果关闭则不会,因为关闭后整个Commit_order_manager结构将不会初始化,也就没有提交顺序一说了。
这个问题是MTS多线程并发下的一个问题且和参数slave_preserve_commit_order有关,并且无法自动解锁,因为已经无法唤醒等待的worker线程。
如果MTS 压力不大,一直是单线程woker在并发,因为没有需要唤醒的worker,那么可能永远也遇不到。
这个问题触发在自从库启动依赖执行了2147483647事务之后,一旦超过并且有需要唤醒的worker则不能唤醒,也就是说不一定是刚好在2147483647个事务上,可能稍微多一点,因为2147483647事务过后可能没有需要唤醒的worker,但是一旦压力上来就可能不能唤醒。也就是说hang住发生的时间点大于等于从库启动依赖执行了2147483647事务。
重启主从可以重置全局计数器,因此可以恢复运行。
8028修复了这个问题,图片修复代码主要如下:
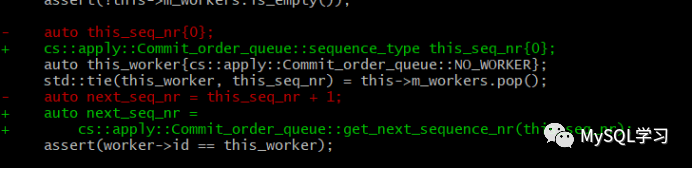
其中cs::apply::Commit_order_queue::sequence_type为一个unsigned long long类型。












