近日,阿里发布了Animate Anyone,只需一张人物照片,结合骨骼动画,就能生成人体动画视频。

项目地址:https://humanaigc.github.io/animate-anyone/
论文地址:https://arxiv.org/pdf/2311.17117.pdf
Github:https://github.com/HumanAIGC/AnimateAnyone
在图像生成领域视频,尤其是在角色动画(通过驱动信号从静态图像中生成角色视频)生成中,其中角色详细信息的一致性仍然是一个艰巨的问题。为了确保可控性和连续性,引入了一个有效的姿势指导器来指导角色的动作,并采用了一种有效的时间建模方法来确保视频帧之间的平滑过渡。本方法可以通过数据驱动的方式对任意角色进行动画制作,相比其他图像到视频的方法,其在角色动画方面表现更优。此外,本方法在时尚视频和人类舞蹈合成的基准测试中取得了最先进的结果。

一、Animate Anyone介绍
模型架构,如下图所示:
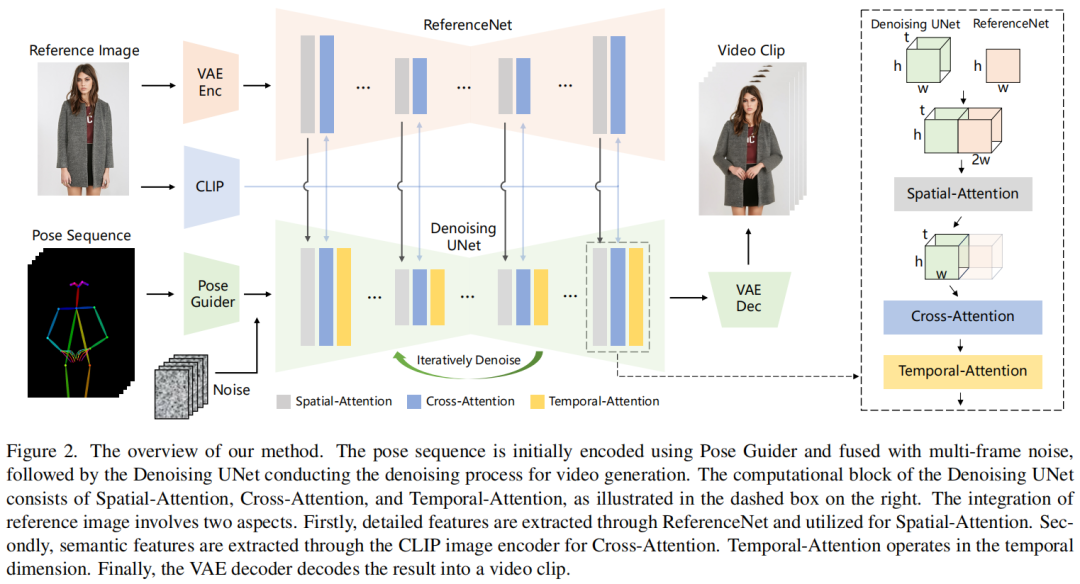
网络的初始输入由多帧噪声组成。去噪UNet基于SD的设计进行配置,采用相同的框架和块单元,并继承SD的训练权重。该方法包含三个关键组件:1)ReferenceNet:编码参考图像中字符的外观特征;2)Pose Guider:编码运动控制信号,实现角色的可控动作;3)Temporal Layer:编码时间关系,保证角色运动的连续性。
1.1 ReferenceNet
在文本生成视频的任务中,文本Prompt包含高级语义,只需要语义与生成的视觉内容相关性即可。然而,在图像生成视频任务,图像特征更详细一些,要求生成的结果更精确匹配。在之前的研究中,重点关注图像驱动生成,大多数方法都采用CLIP图像编码器作为交叉注意中的文本编码器,然而,这种设计未能解决与细节一致性相关的问题。一个原因由于这种限制,CLIP图像编码器的输入包括低分辨率(224×224)图像,导致丢失重要的细粒度细节信息。另一个因素是CLIP经过预训练以匹配语义强调高级特征匹配的文本特征,从而导致在特征编码内的详细特征的不足。
作者设计了一种参考图像特征提取网络ReferenceNet。对于ReferenceNet,采用了与去噪UNet相同的框架,不包括时间层。与去噪的UNet类似,
ReferenceNet从原始SD继承了权重,并且对每个SD的权重更新都是独立进行的。如上图2所示,将self-attention层替换为space-attention层,然后执行self-attention,并提取特征图的前半部分作为输出。这种设计有两个优点:首先,ReferenceNet可以利用原始SD的预训练图像特征建模能力,从而得到良好的初始化特征。其次,由于ReferenceNet和去噪UNet本质上相同的网络结构和共享的初始化权值,去噪UNet可以选择性地从ReferenceNet中学习相同特征空间中相关的特征。利用与文本编码器共享的特征空间,提供参考图像的语义特征,作为有益的初始化,加快整个网络训练过程。
ControlNet也采用类似的设计,它在去噪UNet中引入了额外的控制特征使用零卷积。然而,控制信息(例如深度或者边缘信息)在空间上与目标图像是对齐的,而参考图像和目标图像在空间上相关但不对齐。因此,ControlNet不是适合直接应用。后续的实验会有具体的分析。
虽然ReferenceNet引入了与去噪UNet相当数量的参数,但在基于扩散的视频生成中,所有视频帧都要进行多次去噪,而ReferenceNet在整个过程中只需要提取一次特征。因此,在推理过程中,它不会导致计算开销的大幅增加。
1.2 Pose Guider
ControlNet表现出超出文本Prompt之外且具有高度鲁棒性的条件生成功能。由于去噪的UNet需要微调,本文选择不纳入额外的ControlNet,以防止计算复杂度的显著增加。相反,作者采用了一个轻量级的姿势引导器。这个姿态引导器利用四个卷积层(4×4核,2×2步,使用16,32,64128通道,类似于ControlNet中的条件编码器)以与噪声潜分辨率相同的姿态图像对齐。然后,将处理后的姿态图像与噪声潜层相加,再输入到去噪的UNet中。姿态引导器使用高斯权重进行初始化,并且在最终的投影层中采用零卷积。
1.3 Temporal Layer
许多研究表明将时间层加入文本生成图像(T2I)的模型中可以捕获视频帧的时间依赖关系,这种设计有助于从预训练好的T2I模型迁移图像生成能力。我们的时间层在Res-Trans块内的空间注意力和交叉注意力组件之后进行集成。temporal层的设计灵感来自AnimateDiff。通过残差连接将来自时间层的特征纳入原始特征。时间层只应用于去噪UNet的Res-Trans块内。对于ReferenceNet,它计算单个参考图像的特征,不参与时间建模。由于姿态引导器实现了角色连续运动的可控性,实验表明,时间层确保了外观细节的时间平滑和连续性,避免了复杂的运动建模。
二、Animate Anyone训练策略
训练总共分为两个阶段:第一阶段使用单个视频帧进行训练,在去噪UNet中排除了时间层,模型以单帧噪声作为输入,同时训练ReferenceNet和Pose Guider。参考图像从整个视频剪辑中随机选择。Denoising UNet和ReferenceNet的模型使用SD的预训练权重进行初始化,而Pose Guider使用高斯权重进行初始化,最后的投影层使用零卷积。VAE的编码器和解码器以及CLIP图像编码器的权重都保持不变。这个阶段的优化目标是在给定参考图像和目标姿势的条件下生成高质量的动画图像。第二阶段将时间层引入先前预训练好的模型,并使用AnimateDiff的预训练权重进行初始化。模型的输入是一个24帧的视频剪辑。在这个阶段,只训练时间层,固定网络的其他权重。
三、Animate Anyone实验效果分析
3.1 实验设置
从互联网收集了5K个角色视频片段(2-10s时长)进行训练,并采用DWPose提取角色的姿势序列(包括身体和手),并使用OpenPose对其进行渲染为姿势骨架图像。训练硬件为4个NVIDIA A100 GPU。在训练过程中,使用了两个阶段的训练,
在第一个训练阶段,采样单个视频帧,并调整大小和中心裁剪到768×768的分辨率,batch size设置为64,训练30000步;在第二个训练阶段,使用24帧视频序列,并设置batch size为4,训练10000步。两种学习率都设置为1e-5。在推理过程中,重新调整姿势轮廓的长度来匹配角色参考图像中的特征轮廓,并使用DDIM采样器进行20步去噪。作者采用了时间聚合中的方法,将不同批次的结果连接到生成长视频。为了与其他图像进行公平比较动画方法,作者还在两个特定的基准(UBC时尚视频数据集和TikTok数据集)上训练模型。
3.2 定性分析

Animate Anyone可以动画化任意角色,包括全身人物、半身肖像、卡通角色和人形角色。它能够生成高清晰度和逼真的角色细节,并在大幅度运动下保持与参考图像的时间一致性,同时在帧之间展现时间连续性。更多视频结果可在补充材料中查看。
3.3 对比分析
Animate Anyone在时尚视频合成和人类舞蹈生成两个基准测试中进行了评估。使用SSIM、PSNR和LPIPS等指标进行图像质量的定量评估,使用FVD指标进行视频质量的评估。
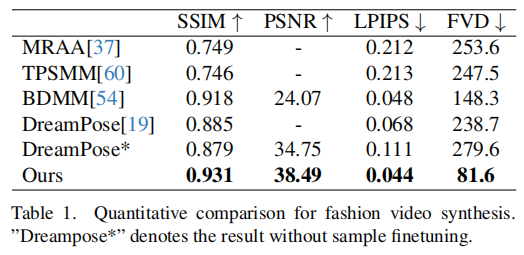
时尚视频合成

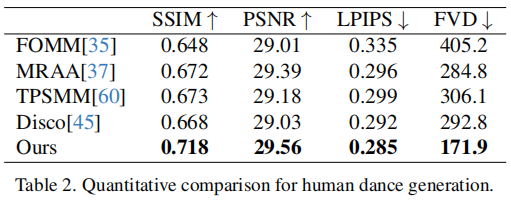
人类舞蹈生成

图像到视频通用方法

3.4 消融实验

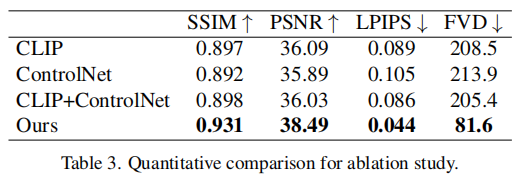
四、Animate Anyone不足之处
1.与许多视觉生成模型类似,模型可能难以为手部运动生成高度稳定的结果,有时会导致失真以及运动模糊;
2.由于图像只提供了一个视角,生成角色移动时未见部分的问题是不确定的,可能会导致不稳定性;
3.由于使用了DDPM,该模型的生成效率较低。
参考文献:
[1] https://arxiv.org/pdf/2311.17117.pdf










