仅作学术分享,不代表本公众号立场,侵权联系删除

图像目标检测是找出图像中感兴趣的目标,并确定他们的类别和位置,是当前计算机视觉领域的研 究热点。近年来,由于深度学习在图像分类方面的准确度明显提高,基于深度学习的图像目标检测模型逐渐 成为主流。首先介绍了图像目标检测模型中常用的卷积神经网络;然后,重点从候选区域、回归和 anchor-free 方法的角度对现有经典的图像目标检测模型进行综述;最后,根据在公共数据集上的检测结果分析模型的优 势和缺点,总结了图像目标检测研究中存在的问题并对未来发展做出展望。
引言
计算机视觉(computer vision)是人工智能 (artificial intelligence,AI)的关键领域之一,是 一门研究如何使机器“看”的科学。图像目标检 测又是计算机视觉的关键任务,主要对图像或视 频中的物体进行识别和定位,是 AI 后续应用的基 础。因此,检测性能的好坏直接影响到后续目标 追踪[1-2]、动作识别[3-4]的性能。传统图像目标检测的滑窗法虽然简单易于理 解,但随目标大小而变化的窗口对图像进行从左 至右、从上至下的全局搜索导致效率低下。为了 在滑动窗口检测器的基础上提高搜索速度, Uijlings 等[5]提出了选择性搜索方法(selective search method),该方法的主要观点是图像中的 目标存在的区域具有相似性和连续性,基于这一 想法采用子区域合并的方式进行候选区域的提取 从而确定目标。Girshick 等[6]提出的基于区域的卷 积神经网络(region-based convolutional neural network,R-CNN)就是采用了选择性搜索方法提 取候选区域,进而越来越多的学者在不断改进确 定目标的方法的基础上提出新的检测模型。
本文首先介绍了图像目标检测模型中常用的 卷积神经网络;然后,重点从候选区域、回归和 anchor-free 方法等角度对现有的图像目标检测模 型进行综述;最后,根据在公共数据集上的检 测结果分析模型的优势和缺点,总结了现有图 像目标检测研究中存在的问题并对未来发展做 出展望。
基于深度学习的图像目标检测模型
本节将介绍近几年提出的基于候选区域、回 归和 anchor-free 的图像目标检测模型,总结各模 型相比之前模型的改进策略以及自身的创新点和 不足,并在 PASCAL VOC2007[17] 、 PASCAL VOC2012[17]和 MS COCO[18]等常用公共数据集上 做出比较。
基于候选区域的图像目标检测模型
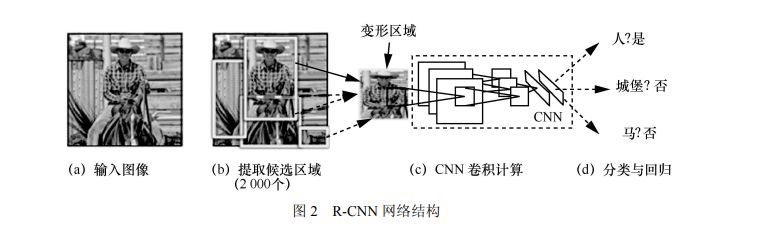
R-CNN 图像目标检测模型是 Girshick 等[6]于 2013 年提出的,它是候选区域和卷积神经网络这 一框架的开山之作,也是第一个可以真正应用于 工业级图像目标检测的解决方案,为基于 CNN 图 像目标检测的发展奠定了基础。网络结构如图 2 所示。R-CNN 首先使用选择性搜索方法从输入的 图像中提取出 2 000 个候选区域,使用剪裁[9]和变 形[19]的方法将候选区域的尺寸固定为 277×277 以 适应全连接层的输入,通过 CNN 前向传播对每个 候选区域进行特征计算;然后将每个候选区域的 特征向量送入特定线性分类器中进行分类和预测 概率值;最后使用非极大值抑制(non-maximum suppression,NMS)[20]算法消除多余的目标框, 找到目标的最佳预测位置。
R-CNN 图像目标检测模型虽然将 mAP(mean average precision,平均精度值)[17]在 VOC2007 和 VOC2012 数据集上分别达到了 58.5% 和 53.3%,在基于深度学习的图像目标检测领域取得 了重大突破,但由于其输入图像经过剪裁和变形 后会导致信息丢失和位置信息扭曲,从而影响识 别精度,并且 R-CNN 需要对每张图片中的上千个 变形后的区域反复调用 CNN,所以特征计算非常 耗时,速度较慢。基于 R-CNN 需固定输入图像尺寸以及检测 速度较慢的缺点,2014年He等[21]提出了SPP-Net, 该模型先是计算整个输入图像的卷积特征图,根 据选择性搜索方法提取候选区域,通过对特征图 上与候选区域相对应位置的窗口使用金字塔池化 (spatial pyramid pooling,SPP)可以得到一个固定 大小的输出,即全连接层的输入。与 R-CNN 相比, SPP-Net 避免了反复使用 CNN 计算卷积特征,在 无须对输入图像进行剪裁和变形的情况下实现了 多尺度输入卷积计算,保留了图像的底层信息, 在VOC2007数据集上测试时 mAP达到了59.2%, 在达到相同或更好的性能前提下,比 R-CNN 模型 快 24~102 倍。虽然 R-CNN 和 SPP-Net 在 VOC2007 数据集 上都获得了很高的精度,但两者将分类和回归分 为多阶段进行,使得网络占用了较多的硬件资源。2015 年 Girshick 等[22]提出了一种快速的基于区域 的卷积网络模型(fast R-CNN)。该网络首先用 选择性搜索方法提取候选区域,将归一化到统一 格式的图片输入 CNN 进行卷积计算,然后借鉴了 SPP-Net 中金字塔池化的思想,用最大值池化层 ROI pooling 将卷积特征变成固定大小的 ROI 特征 输入全连接层进行目标分类和位置回归。该网络 采用多任务训练模式,用 softmax 替代 SVM (support vector machine,支持向量机)[23]进行分 类,将分类和回归加入网络同时训练,在末尾采用可同时输出分类和回归结果的并行全连接层。fast R-CNN 减少了硬件缓存,提高了检测速度, 初步实现了端对端的图像目标检测,并且在 VOC2007 和 VOC2012 数据集上的 mAP 分别为 66.9%和 66.0%。
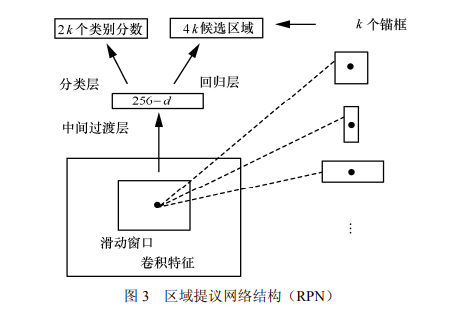
由于 fast R-CNN 无法满足实时检测的需求, Ren 等[24]提出了改进模型 faster R-CNN。该网络 的最大创新就是提出了区域提议网络(region proposal network,RPN),即在基础卷积网络提 取输入图像特征的基础上用 RPN 代替 fast R-CNN 中的选择性搜索方法进行候选区域的提取。RPN 是一个全卷积网络,网络结构如图 3 所示,该网 络可以同时在每个位置上预测出目标边界和目标 概率并产生高质量候选区域,然后通过 ROI pooling将卷积特征变成固定大小的ROI特征输入 全连接层进行目标分类和位置回归。RPN 和 fast R-CNN通过四步交替训练法使两个网络共享卷积 特征合并为单一网络,解决了区域计算的瓶颈问 题,在实现真正端对端训练模式的基础上满足了 实时应用的需求[23]。
2017 年 He 等[25]提出了 mask R-CNN 目标检 测模型,该模型以faster R-CNN为原型,即在faster R-CNN 中生成的候选区域中融入 FCN(fully convolutional network,全卷积神经网络)[26]作为 新的支路用于生成每个候选区域的掩膜,同时把 faster R-CNN 中 RoI pooling 修改成为了 ROI align 用于处理掩膜与原图中物体不对齐的问题。Mask R-CNN 在训练时可以同时生成目标边界、目标概 率和掩膜,但在预测时通过将目标边界和目标概 率的结果输入掩膜预测中以生成最后的掩膜,该 方法减弱了类别间的竞争优势,从而达到了更好 的效果,在 MS COCO 数据集上的 mAP 测试结果 达到 35.7%。
基于回归的图像目标检测模型
YOLO 及扩展模型
检测精度和检测速度是评判图像目标检测模 型好坏的重要标准[27]。基于候选区域的图像目标 检测模型,虽然在检测精度方面首屈一指,但是 它检测图像的效率低是其主要弊端。2016 年 Redmon 等[28]提出 YOLO(you only look once)检 测模型,该模型将图像目标检测抽象为回归问题, 通过对完整图片的一次检测就直接预测出感兴趣 目标的边界框和类别,避免了 R-CNN 系列中将检 测任务分两步进行的烦琐操作,解决了之前图 像目标检测模型检测效率低的问题。检测网络 将输入的图片分成 s×s 个网格,如图 4 所示,各 网格只负责检测中心落在该网格的目标,预测 出网格的类别信息以及多个边界框和各个边界 框的置信度,通过设定阈值过滤掉置信度较低 的边界框,然后对保留的边界框进行 NMS 处理 以确定最终的检测结果。YOLO 以回归替代了 之前图像目标检测模型的候选区域方法,在满足 实时需求的基础上检测速度达到 45 f/s,但由于 YOLO 在检测过程中仅选择置信度最高的边界框 作为最终的输出,即每个网格最多只检测出一个 物体,因此 YOLO 在检测紧邻群体目标或小目标 时效果不佳,在 VOC2007 上的 mAP 也仅有 66.4%。针对 YOLO 在目标定位方面不够准确的问 题,2017 年 Redmon 等[29]提出了 YOLO 的扩展模 型 YOLOv2 和 YOLO9000。YOLOv2 首先在卷积 层中添加批量归一化(batch normalization,BN)[30]技术使得模型的收敛性有显著的提升,然后借鉴 faster R-CNN 的思想用聚类方法产生的锚框替代 了 YOLO 中预测出的边界框,最后通过输入更高 的分辨率图像并对其进行迁移学习[31]从而提升网 络对高分辨率图像的响应能力,训练过程中无须 固定图像的尺寸,因此在一定程度上提升了网络 的泛化能力。除此之外 YOLOv2 还提出将一个由 19 个卷积层和 5 个 MaxPooling 层构成的 Darknet-19[28]网络作为骨干网进一步提升检测速 度。而 YOLO9000 则是在 YOLOv2 的基础上提出 了目标分类和检测的联合训练方法,使 YOLOv2 的检测种类扩充到 9 000 种。2017 年 Redmon 等[32] 提出了 YOLOv3 检测模型,它借鉴了残差网络结 构,形成网络层次更深的 Darknet-53,通过特征 融合的方式采用 3 个不同尺度的特征图进行目标 检测,并且用 logistic 代替 softmax 进行类别预测 实现了多标签目标检测,该网络不仅提升了小目 标检测效果,在边界框预测不严格并且检测精度 相当的情况下检测速度是其他模型的 3~4倍。
SSD 及扩展模型
2016 年 Liu 等[33]提出 SSD 图像目标检测模 型,该模型彻底淘汰了生成候选区域和特征重采 样阶段,选择将所有计算封装在单个深层神经网 络中,网络结构如图 5 所示。SSD 网络继承了 YOLO 中将目标检测问题抽象为回归问题的思 想,采用特征金字塔的方式进行检测,即利用不 同卷积层产生不同的特征图,使用一个小的卷积 滤波器来预测特征图上一组固定的默认边界框类 别和位置偏移量。为了实现较高的检测精度,在 不同尺度的特征图中进行不同尺度的预测,并设 置不同长宽比的边界框进行分离预测。由于图 像中的目标具有随机性,大小不一,所以小目 标的检测是由 SSD 使用底层特征图来实现的, 大目标的检测是由 SSD 使用高层特征图来实现 的,相对于 YOLO 精确度大幅度提高,并且效 率也有所提升。2017 年 Fu 等[34]提出 DSSD 检测模型,即将 Resnet-101 作为 SSD 的骨干网,在分类回归之前 引入残差模块,并且在原本 SSD 添加的辅助卷积 之后又添加了反卷积层,与 SSD 相比,DSSD 在 小目标的检测精度上有了很大的提升,但 Resnet-101 网络太深导致 DSSD 的检测速度相比 SSD 较慢。2017 年 Jisoo 等[35]在未改动 SSD 主干网络的基础上提出了 RSSD(rainbow SSD)检测 模型,该网络同时采用池化和反卷积的方式进行 特征融合,不仅增强了不同特征层之间的关系, 由于融合后的特征大小相同,还一定程度上增加 了不同层的特征个数。这种特征融合方式解决了 SSD 存在的重复框的问题,同时提升了对小目标 的检测效果,但与 SSD 相比检测速度较慢。2017 年 Li 等[36]提出了 FSSD,该模型通过重构一组金字 塔特征图充分融合了不同层不同尺度的特征,在 保证检测速度与 SSD 相当的同时使得检测精度有 了明显的提升。2019 年 Yi 等[37]借鉴注意力机制[38] 的思想在 SSD 检测模型中设计了一个注意力模 块,该注意力模块基于全局特征关系可以分析出 不同位置特征的重要性,从而达到在网络中突出 有用信息和抑制无用信息的效果,ASSD[37]检测精 度提高,但与 SSD 相比,检测速度较慢。
基于 anchor-free 的图像目标检测模型
图像目标检测发展日新月异,越来越多优秀 目标检测模型陆续被提出,基于候选区域和回归 方法的检测模型目前发展稳定并且成熟,而基于 anchor-free 的检测模型是当下目标检测领域中新 的热门研究方向,anchor-free 检测模型有两种, 分别为基于关键点的检测和基于分类和回归进行 改进的检测。
基于关键点的检测
2018 年 Law[42]受到 Newell 等在姿态估计[43-46] 中的关联嵌入的启发提出了 CornerNet,这是一种 新型的图像目标检测方法。CornerNet 将一个目标 检测为一对关键点,即目标边界框的左上角点和 右下角点,是第一个将图像目标检测任务表述为 利用嵌入角点进行分组和检测任务的模型,开启 了基于关键点的目标检测方法的大门。CornerNet 首先使用沙漏网络[15]作为其骨干网络输出最后一 层卷积特征,骨干网后接两个分支模块,分别进 行左上角点预测和右下角点预测,每个分支模块 包含一个 Corner pooling(角池化)和 3 个输出, 网络结构如图 7 所示。heatmaps(热图)输出的 是预测角点的位置信息,当图像中出现多个目标时,embeddings(嵌入)根据左上角点和右下角 点嵌入向量之间的距离对属于同一目标的一对角 点进行分组;offsets(误差)是输出从图像到特征 图的量化误差,用来对预测框进行微调。
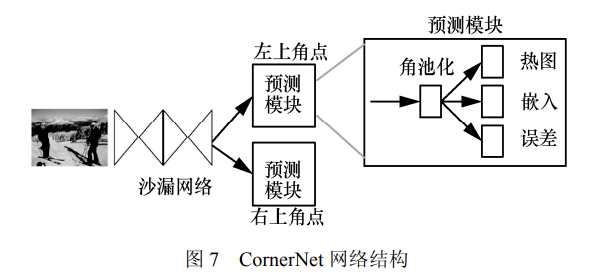
当角点在目标之外时,此时获取的信息不足 以进行当前的定位,为了能够更好地定位边界框 的角点,Law 等[42]介绍了一种新型池化层—角池 化层,该池化层包含两个特征图,在每个像素位 置,它将第一个特征图下侧的所有特征向量和第 二个特征图右方的所有特征向量最大化,然后将 两个合并后的结果相加输出最后的角点。CornerNet 极大地简化了网络的输出,彻底消除了 图像目标检测对候选区域和候选框的需要,在 MS COCO 上实现了 42.1%的 mAP,但当 CornerNet 将边界框的角点定位在物体之外时目标的局部 特征表现不强烈,并且在判断两个角点是否属 于同一目标时,由于缺乏全局信息的辅助导致 匹配角点时产生错误目标框,因此存在一定的 误检率。2019年Zhou等[47]借鉴CornerNet 的思想提出 一种新的检测思路,即通过关键点估计[48-50]网络 对每个目标预测出 4 个极值点和 1 个中心点,然 后提取极值点的峰值,暴力枚举所有的组合并计 算出每个组合的几何中心点,若几何中心点与预 测的中心点匹配度高于设定阈值,则接受该组合, 并将这 5 个极值点的得分平均值作为组合的置信 度。ExtremeNet[47]将目标检测问题转化成单纯的 基于外观信息的关键点估计问题,避免了对目标 隐含特征的学习,相对于 CornerNet 更好地反映了物体的信息,检测效果更好。
基于分类和回归进行改进的检测
自 2018 年 CornerNet 提出以来,基于 anchor-free 的目标检测模型在分类和回归的方法 上又有了新的创新,如 2019 年 Zhu 等[53]提出一种 基于 anchor-free 的动态选择特征层的方法,该方 法主要是在 RetinaNet 的基础上建立一个 FSAF(feature selective anchor-free)模块,即对每个层 次的特征都建立一个可以将目标分配到合适特性 级别的 anchor-free 分支,使得目标框能够在任意 特征层通过 anchor-free 分支进行编解码操作。FSAF 可以和基于锚的分支并行工作平行的输出预测结 果,有效地提升了 RetinaNet 的稳健性,解决了传统 基于锚框检测的网络根据候选框选择特征层的局限 性,并在 MS COCO 上实现了 42.8%的 mAP。传统基于锚框的检测网络面对变化较大的目 标时需要根据检测任务预定义锚框尺寸,通过手 工设置锚框提高召回率这一操作不仅占用较大的 计算和内存资源,还在一定程度上深化了正负样 本不平衡问题。2019 年 Tian 等[54]提出一种全卷积 目标检测网络 FCOS,类似语义分割中[55]利用逐 像素点预测的方式解决目标检测问题。为了提高 检测效果,FCOS 引入 center-ness 分支用于降低检 测效果不理想的目标框权重,然后通过 NMS 算法 确定最终检测结果。基于 anchor-free 的 FCOS 检 测网络极大地降低了参数计算,可以与其他视觉 任务相结合,并且尽可能多地使用正样本参与训 练,解决了之前检测模型中出现的正负样本不平 衡问题,但在检测时由于目标真实框重叠,可能 会出现语义模糊情况。2019年Kong等[59]提出了FoveaBox目标检测 网络,结合人类视觉系统是通过眼球中对物体感 应最敏锐的中央凹(Fovea)结构确定物体位置的 原理对目标真实框进行位置变换,更具体地说是 通过目标真实框找到目标对应在特征图中的中心 位置,然后设定两个缩放因子分别对目标真实框 向中心点进行收缩和扩展,将收缩边框的内部点 作为正样本,扩展边框外部点作为负样本。这种 通过位置变化忽略两个边框中间点的方法不仅增 加了正负样本之间的识别度、解决了样本不平衡 问题,还有效提升了检测性能,但与其他 anchor-free 模型相比检测精度略低,在 MS COCO 上实现的 mAP 仅有 40.6%。
图像目标检测模型对比
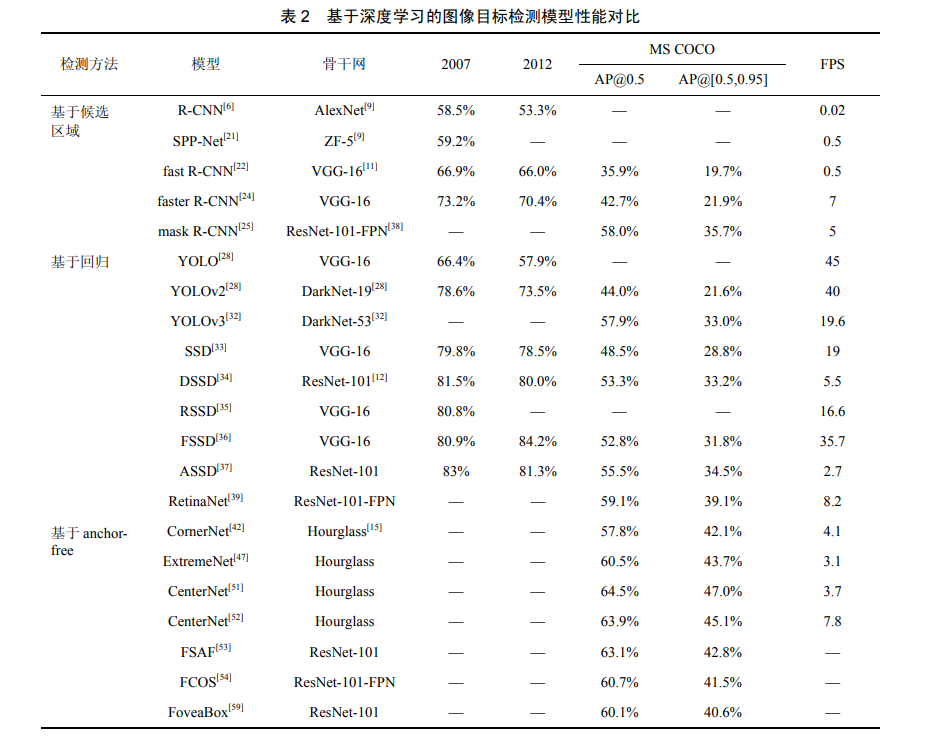
本文对现有经典图像目标检测模型的创新点 及优缺点做出对比,见表 1。无论是候选区域法、 回归法还是 anchor-free 法,提出模型的主要目的 都是为了能够高精度、高速率地识别并检测出目 标。由表 1 可以看出,基于候选区域法模型的提 出开启了用 CNN 提取特征的大门使图像目标检 测进入深度学习时代,回归法则解决了候选区域 法的速度瓶颈问题,实现了端对端的图像目标检 测。而基于 anchor-free 的算法消除了候选区域法 和回归法中候选框的设计,生成高质量的目标框 并在未来形成了一个有前途的方向。对本文中提到的图像目标检测模型在公共数 据集上的检测结果做出对比,见表 2。“—”表示 此数据集没有该模型的测试结果,2007 表示数据 集 VOC 2007,2012 表示数据集 VOC 2012;AP@0.5 表示该模型在 MS COCO 数据集上是取 阈值为 0.5 计算精度的,AP@[0.5,0.95]表示该模 型在 MSCOCO 数据集上是取 10 个阈值(间隔 0.05)计算精度的,即 mAP,表 2 中所有的数据 集精确率检测结果均以百分比为单位。FPS 表示 该模型每秒处理图片的数量。

欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)











