 夕小瑶科技说 原创
夕小瑶科技说 原创
作者 | 墨墨
随着美国大选的钟声日益迫近,一个在政坛阴霾下潜滋暗长的现象——信息操纵(Information Operations),再度跃入公众视野,成为全球瞩目的焦点。
在这个数字化的时代,社交媒体已不仅仅是记录生活琐碎与汲取资讯的窗口,它悄然间演变为了一场没有硝烟的战争前线,其中,信息操纵正以惊人的规模和组织性,对公众舆论发起挑战。
信息操纵,简而言之,是一种有计划、有组织地传播信息以左右公众看法的活动。
在光怪陆离的网络世界里,操纵者们如同隐形的导演,精心策划着一幕幕看似自发实则被操控的社会讨论。他们的策略复杂多变,常常隐藏于日常交流的缝隙之中,难以察觉。一方面,通过放大社会分歧,如种族、经济不平等议题,操纵者巧妙地煽动网民情绪,诱使真实用户在不自觉中为这些信息“代言”,扩大其影响力。另一方面,他们还企图侵蚀民众对民主机制的信心,播撒怀疑与不信任的种子。
更令人担忧的是,信息操纵的手法远不止于此。散布仇恨言论,利用虚假或误导性信息混淆视听,乃至涉足金融诈骗,都是其惯用伎俩。这些行为不仅操纵了公众的情绪波动,更深层次地干扰了社会的正常运行节奏,威胁到了社会稳定与安全的根基。

而近日,南加州大学的研究团队在arXiv上发布了一篇炙手可热的论文,揭示了如何利用大语言模型,来深入剖析并影响政治活动中的信息操纵策略。
该研究的核心在于探索大语言模型如何辅助我们理解和应对信息操纵。
这不仅仅是学术界的热议,更是对我们每个人如何接收信息的一次深刻反思。
下面就让我们一起来看看这篇论文吧!
论文标题:
Large Language Models Reveal Information Operation Goals, Tactics, and Narrative Frames
论文链接:
https://arxiv.org/pdf/2405.03688
背景:信息操纵正在影响着我们的生活
在当今数字化时代,社交媒体与网络活动的监测与分析面临着前所未有的挑战与机遇。
虽然近年来,在检测和遏制协同信息操纵活动方面取得了显著进展。但这场猫鼠游戏远未结束,当前技术在实现大规模自动化分析方面仍显乏力。目前,信息操纵分析大多依赖人工审核与标注,这一过程不仅耗时费力,还限制了我们深入理解活动目标与策略的能力。
而LLM的兴起改变了这一现状,本篇文章中,研究者首次探索了LLM在自动注解政治竞选目标、策略及叙事框架上的潜力,标志着AI技术在信息领域的又一重要应用尝试。
那么,研究者是利用LLM进行信息操纵分析的呢?
模型结构:如何分析信息操纵
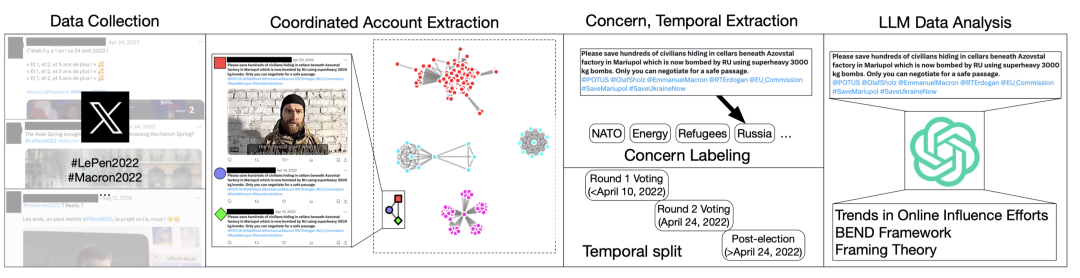
我们将分析过程拆解为以下这些步骤:
- 协同账户提取(Coordinated Account Extraction)
- 关注点与时间信息提取(Concern, Temporal Extraction)
- LLM数据分析(LLM Data Analysis)
我们将分别介绍这些步骤。
信息收集:获取 X 数据
我们从 X(原 Twitter)中挑选了2个典型的数据集,它们分别是:
2022 年法国大选数据集包含 2022 年 2 月 15 日至 6 月 30 日期间的 590 万条帖子(430 万条转发,160 万条回复,1.8 万条原始帖子,67.8 万位作者)。在这个数据集中,95% 的帖子是法语,其余 (5%) 是英语。
2023 年美菲联合军事演习数据集包含 2023 年 1 月 1 日至 2023 年 6 月 28 日的 470 万条帖子(320 万条转发,852 条回复,60.5 万条原始帖子,13 万条引用帖子,190 万位作者),时间跨度为 2023 年 1 月 1 日至 2023 年 6 月 28 日。在这个数据集中,94% 的帖子是英语,其余 (6%) 是塔戈洛语。
所有数据均在分析前删除了 ID 和 PII(个人身份信息),以提高匿名性,并且收集方法已得到相关机构审查委员会的批准。
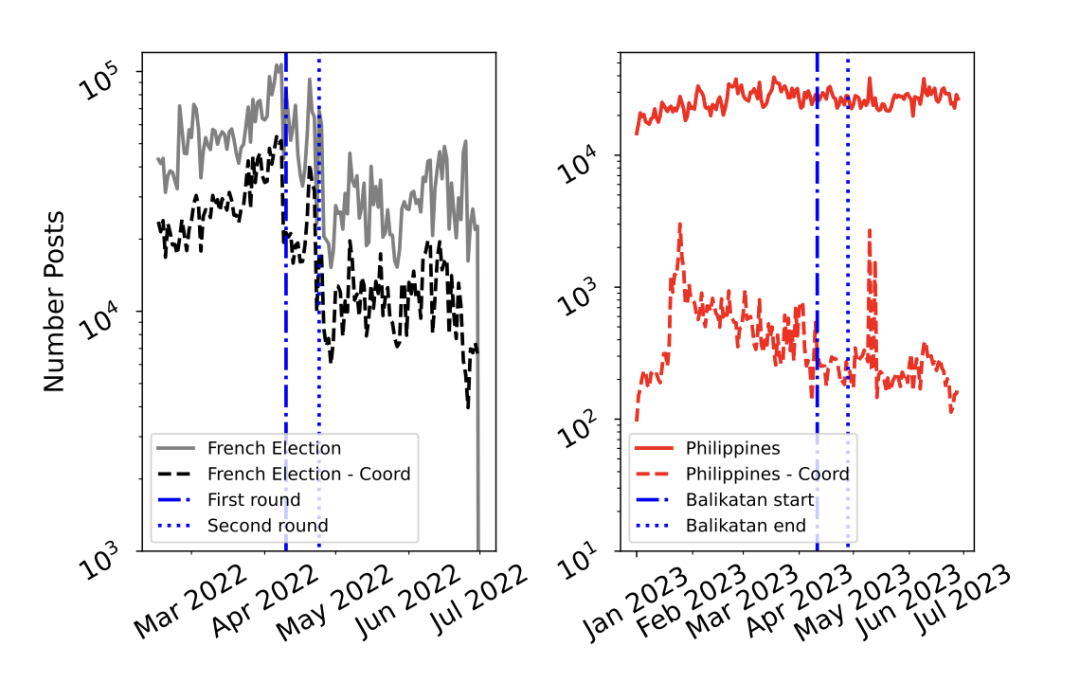
下图显示了协同账户(指行为高度类似的账户,疑似有组织的目标与受影响的公众)和非协同账户发布帖子的数量随时间的变化。左图来自2022年法国大选,第一轮和第二轮选举被分别标注。右图则是2023 年美菲联合军事演习。
协同账户提取
获得数据后,我们需要从中提取出协同账户信息。
我们使用给定帖子中标签的共现作为协同指标。如果两个帐户都发布了包含至少三个相同顺序的相同标签的帖子,则它们是协同账户。
这个简单的启发式方法捕捉到了这样一个概念:各个帖子的文本可能会有所不同,但如果它们在语义上相同,则主题标签通常会采用相同的顺序。也就是说,协同账户以不同语义发布了类似的内容,然后将它们打上了相同的标签。
上述方法都在ground-truth数据集中得到了很好的验证(Luceri等人,2023)。
通过协同账户判定,我们获得了协同关系连接的网络。这反过来意味着,我们可以将不同的协同账户活动独立看待,这已在之前的工作中得到验证(Burghardt 等人,2023)。
多标签分类提取关注点
对于协同账户发布的信息,我们需要发现其中的关注点(Concern)。
关注点,指那些充满争议和多维度的议题,讨论者的观点往往立场不相容,常被称为“楔形问题”。它们触及社会的核心价值观,如犯罪、环境保护等。这些问题之所以成为操纵工具,是因为它们能触动公众敏感神经,激发强烈的情感反应,进而分化人群,甚至影响政治活动和社会稳定。
社交媒体中的关注点检测是一项复杂且具有挑战性的任务。它的难点在于:
- 可变性:社交媒体讨论涉及广泛的关注点,其中许多是动态的,是从最近发生的事件中产生的。这种可变性要求检测方法具有很强的应对新问题的通用能力。
- 缺乏上下文:社交媒体数据集也非常庞大,并且通常缺乏足够的背景来准确解释和分类问题。上下文的缺乏阻碍了模型进行清晰分类的能力。
- 界限模糊:不同关注点之间的界限通常很模糊,因此很难清晰地描述和分类它们。这种模糊性使关注点检测的任务变得复杂。
为了应对这些挑战,我们提出了一个新颖的框架,利用LLM来自动检测关注点。框架概述如下图所示,由以下步骤组成:
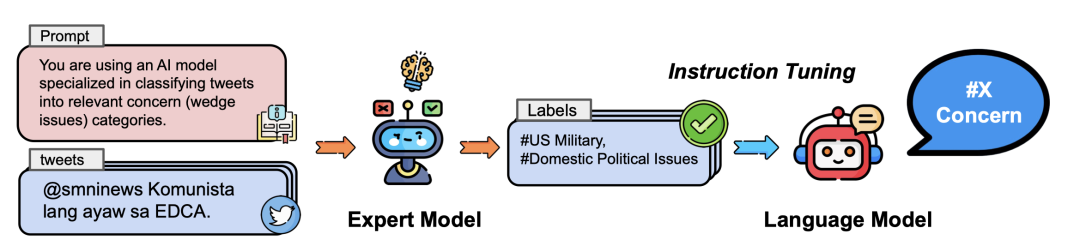
- 对数据进行采样,选取其中小部分数据(总计40,000 条帖子)使用专家模型(GPT-4)对其进行标签标注。
- 使用蒸馏的student模型(Llama-2-7B)来标注数百万个帖子,该模型通过 Instruction Tuning 进行训练。
利用LLM标注信息活动
利用LLM的多标签分类获得关注点后,我们使用 GPT-3.5 对其中的信息活动(指协同账户在网络上的协同活动)进行标注。
我们一共启用了3套标注框架。它们分别是:
(1)信息活动基本信息提取
(2)BEND 框架研究信息活动的目的
- 解释(Explain):提供主题的详细信息或阐述主题
- 分散注意力(Distract):讨论一个不同的、不相关的话题
(3)研究信息活动如何影响公众
此外,我们要求LLM标注:
- 故意的修辞谬误(在prompt中包含了来自互联网哲学百科全书的故意修辞谬误列表)
最后,为了防止LLM产生幻觉,我们利用GPT-3.5根据现有标注数据重新生成 X 帖子,随后再对生成的帖子按照之前的框架进行标注。对比前后的标注结果,用微调后的BART对结果进行了简单评估。
实验:评估关注点检测模型
构建完信息操纵识别模型后,我们需要对提出的模型进行评估。
首先是关注点检测模型。
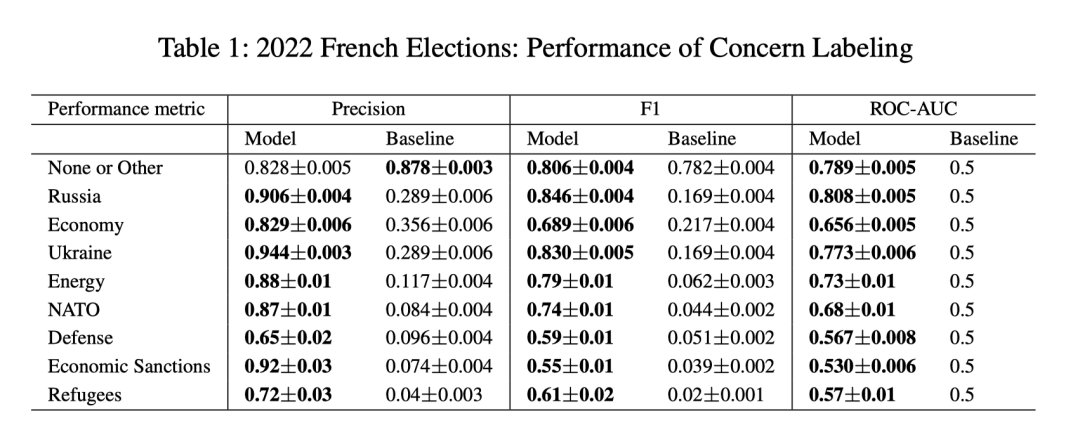
下表是模型在法国选举数据集上的表现。其中的偏差来自对预测值和真实值数据对进行 1000 次抽样的结果(由于训练时间长达数小时,因此无法使用训练数据进行抽样并重新训练模型)。基线则是对所有帖子打相同的标签的结果。
该模型具有相对较高的平均精度和F1分数,尤其对于诸如乌克兰、俄罗斯和北约的关注点有很优秀的表现,这表明该模型能够有效地识别相关关注点。
然而,难民和国防类别的表现较弱,这表明可能很难捕捉到这些关注点中的细微差别,部分原因是它们在帖子中出现的频率较低。
下表则是在美菲联合军事演习数据集上的评估。模型在国防和军事以及公共服务的关注点部分地表现出较低的性能,这部分是因为这些事件发生的频率较低。在犯罪、劳工和移民等关注点上则表现优秀。能源关注点只有一个标注过的帖子,所以我们没有验证它。
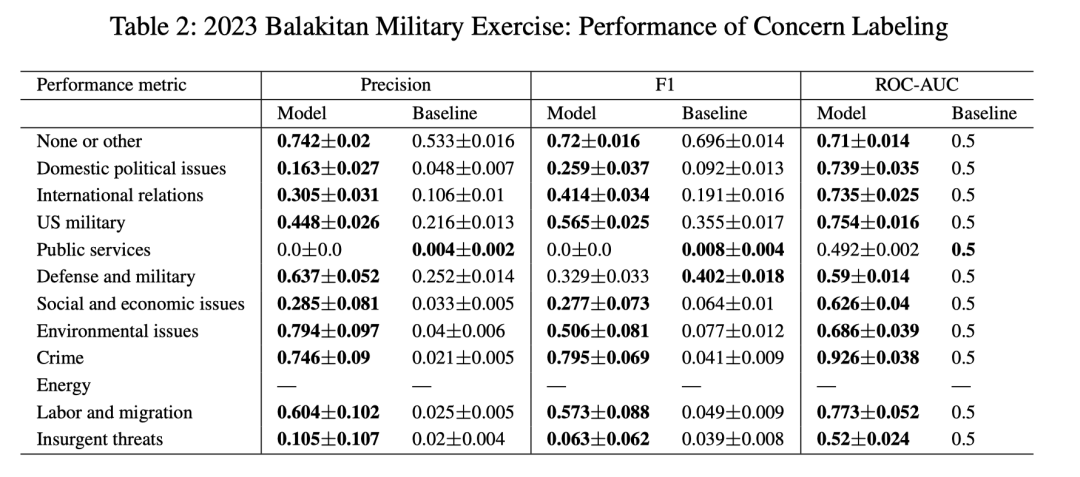
实验:评估协同账户发现模型
协同账户的发现也十分重要。下图展示了协同账户模型在两个数据集上的结果。其中左图是法国选举数据集,右图是美菲联合军事演习数据集。横轴是协同账户集群编号,纵轴则代表集群包含的账户数量。
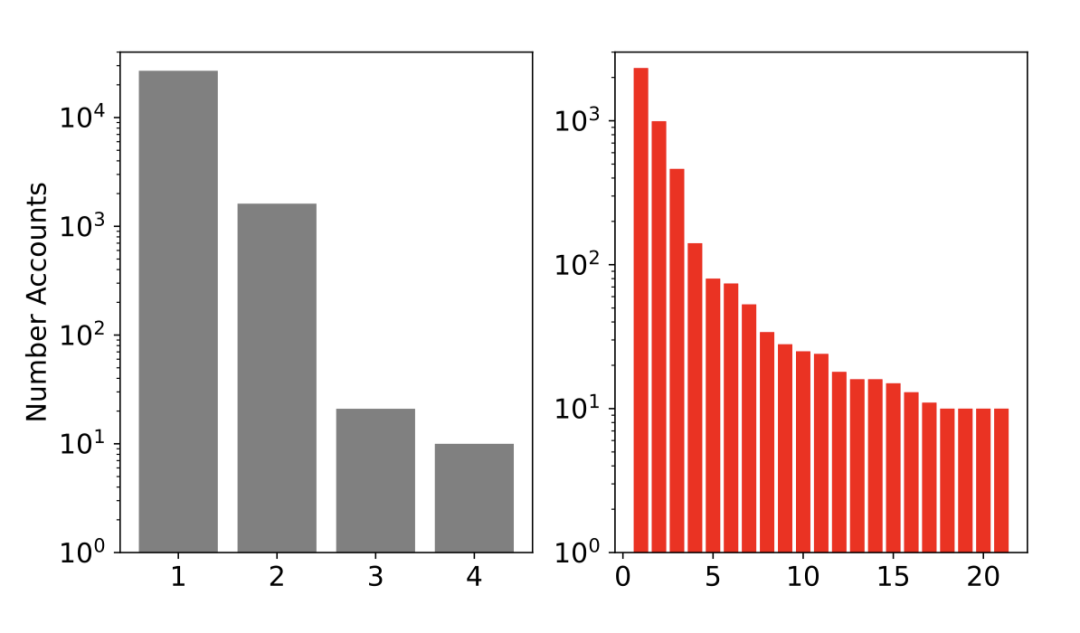
法国选举数据集中总共有 29K 个协同账户,美菲联合军事演习数据集中有 4700 个协同账户。这相当于 2022 年法国大选中的 270 万个帖子(占所有帖子的 45.5%)和美菲联合军事演习数据集中的 7.9 万个帖子(占所有帖子的 1.7%)。
虽然前一个数字听起来令人惊讶,但它们仅由 11.6% 的账户编写。
法国选举数据集的另一个特点是只有 4 个集群拥有超过 10 个协同账户,最大集群协同账户的数量极高。
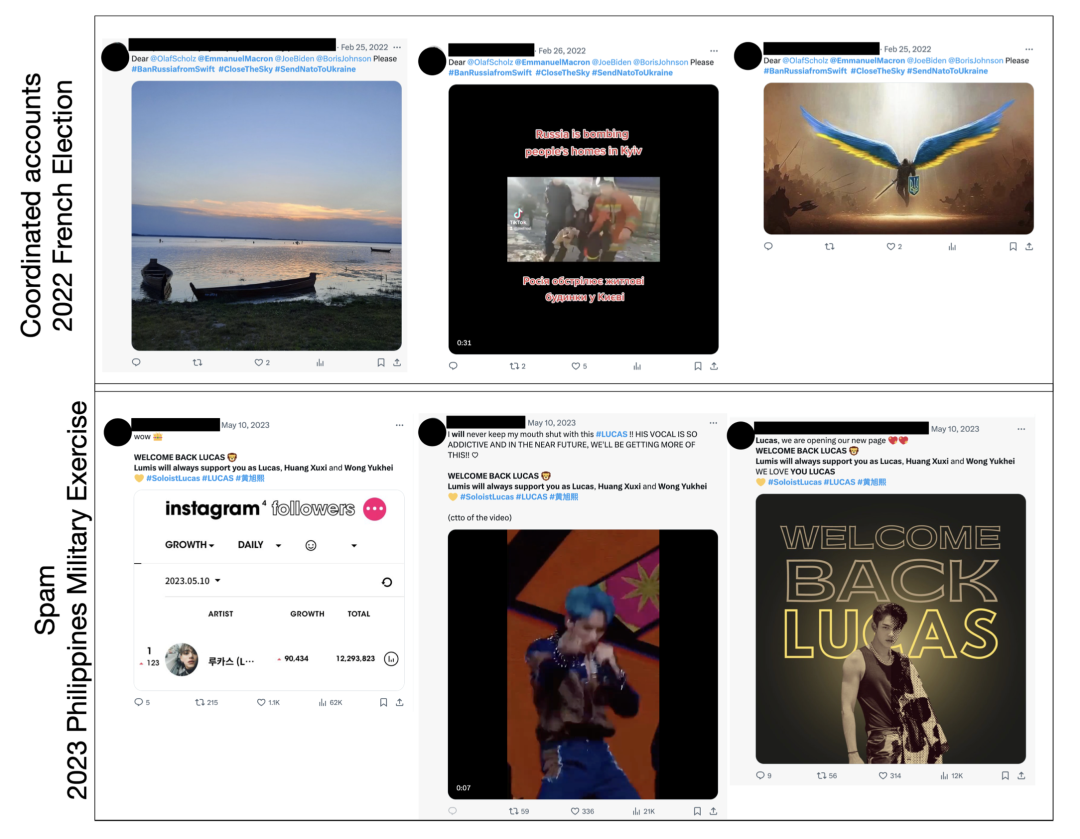
协同账户集群活动的例子如下图所示。在该图中,显示了 2022 年法国大选中的第二大集群(上方)和 2023 年美菲联合军事演习数据集中的最大集群(下方),我们看到了不同帐户发布了近乎相同的帖子,这是非真实人类活动的有力指标。
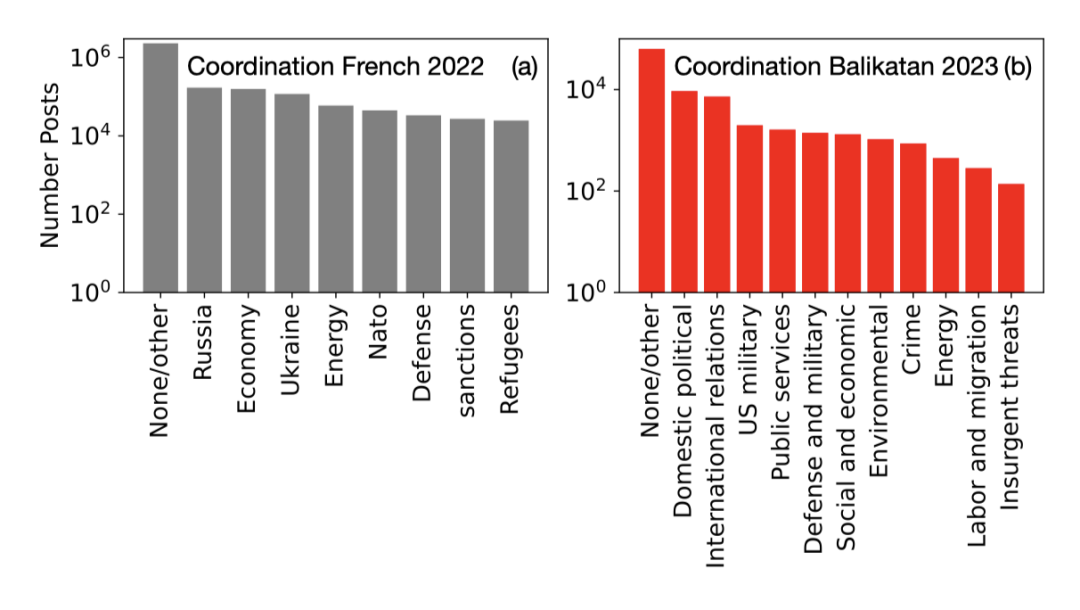
我们还在下图中分析了从这些协同账户中提取的关注点。该图显示了与我们捕获的每个关注点相关的帖子频率;俄罗斯是最常被提及的问题。与此同时,美菲联合军事演习数据集中最常讨论国内政治问题和国际关系。
与真实数据相比,国内政治和公共服务问题的频次明显过高。
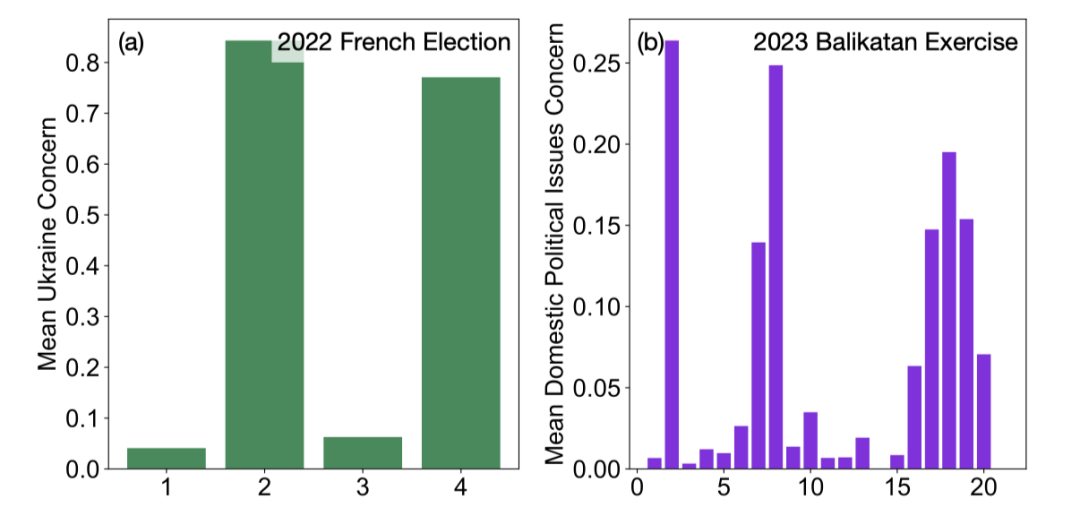
同时,这些协同账户所涉及的关注点是较为集中的。我们在下图中展示了对于两个示例话题的帖子,每个协同账户集群中涉及此问题账户的百分比。
这些数字显示了法国选举的两个集群中对乌克兰问题的过多关注(左图)。相比之下,右图显示了过多的国内政治担忧,特别是对于第二大集群而言。该集群包含反保守英国政党的信息活动(即攻击保守党的帖子)。
总结
在本篇论文中,研究人员巧妙地利用了GPT-3.5等LLM的强大功能,通过一系列精心设计的指标,在2022年法国选举和2023年美菲联合军事演习两个数据集上,对这些历史信息操纵案例进行了详尽的量化分析。
通过对这两个事件相关的海量多语种数据进行挖掘,GPT-3.5成功识别并归纳了背后信息操作的关键要素:目标设定、执行策略以及用于引导公众舆论的叙事框架。这一过程不仅展示了模型跨语言处理的能力,也凸显了其在复杂国际政治背景下的实用价值。
随着技术的不断进步,我们有理由相信,未来的网络空间将更加透明、安全。













