本文作者:于怡宁,河南大学中原发展研究院
本文编辑:兰博文
技术总编:李婷婷
Stata and Python 数据分析
爬虫俱乐部Stata基础课程、Stata进阶课程和Python课程可在小鹅通平台查看,欢迎大家多多支持订阅!如需了解详情,可以通过课程链接(https://appbqiqpzi66527.h5.xiaoeknow.com/homepage/10)或课程二维码进行访问哦~
通常来说,卫星传感器获取的主要是地表的太阳辐射反射信号,而夜光卫星传感器独辟蹊径,采集的是夜间灯光、火光等产生的辐射信号。传感器在夜间工作,能探测到城市灯光甚至小规模居民地、车流等发出的低强度灯光,并使之区别于黑暗的乡村背景。因此夜间灯光影像可作为人类活动的表征,成为了人类活动监测研究的良好数据源;目前,夜间灯光数据主要用于城镇扩展研究,社会经济因子估算以及其它环境、灾害、渔业、能源等领域。
美国国家极地轨道环境卫星(NPP)可见红外成像辐射套件传感器(VIIRS)提供的夜间灯光数据,该卫星一天绕地球运行约14圈,每次绕行时间约102分钟。在绕行过程中,VIIRS传感器每隔6分钟成一次像,每天成像240次,成像幅宽为3060公里,成像分辨率为750米。近年来,越来越多的研究基于NPP/VIIRS夜间灯光数据刻画更加精细尺度的个体行为,下面介绍怎么批量获取该卫星数据。
卫星数据官方的解释文档:
https://ladsweb.modaps.eosdis.nasa.gov/missions-and-measurements /products/VNP46A2#overview
VNP46A2产品把地球分成了18*36个网格。
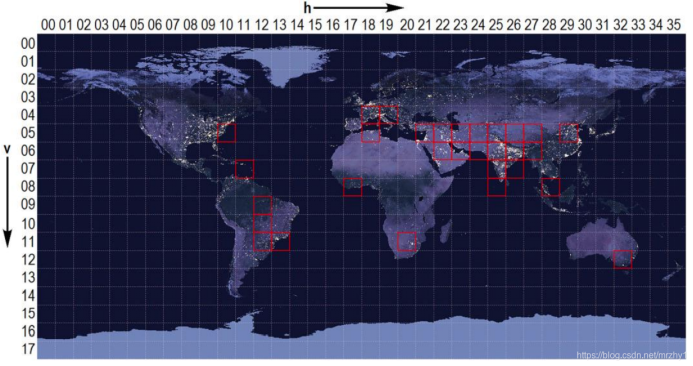
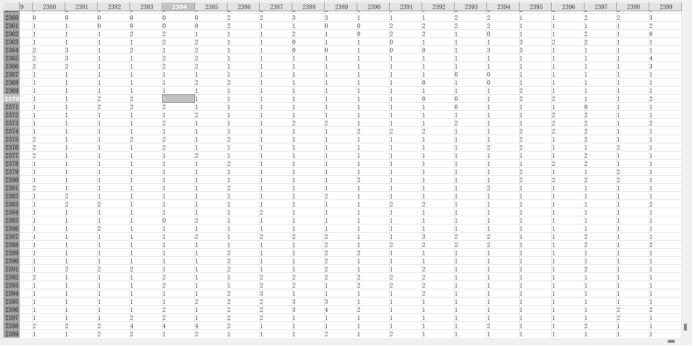
再把10度*10度的网格分成了2400*2400份,每份的面积为500*500m,其中的数字代表该区域的灯光亮度。
下面使用wget来下载卫星数据,首先需要登录NASA官网按照步骤注册账号:
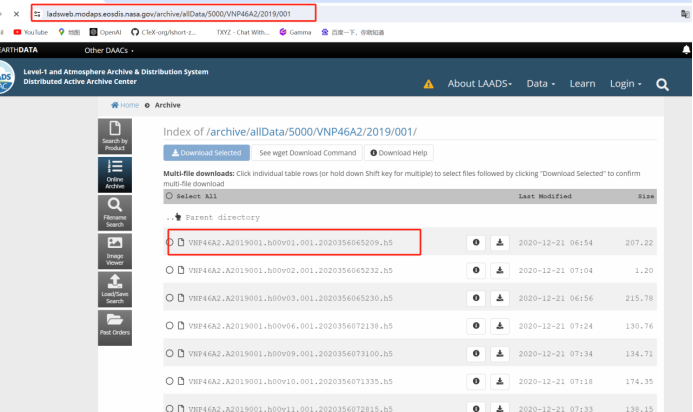
https://ladsweb.modaps.eosdis.nasa.gov/archive/allData/5000/VNP46A2/2019/001可以观察到前面的https://ladsweb.modaps.eosdis.nasa.gov /archive/allData/5000/VNP46A2都相同,2019是数据的年份,001是第一天的数据,下面获取2019年第一天所有数据的下载地址:
import requestsfrom lxml import etreeurl = "https://ladsweb.modaps.eosdis.nasa.gov/archive/allData/5000/VNP46A2/2019/001"headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"}res = requests.get(url=url,headers=headers)tree = etree.HTML(res.text)url_xpath = "//td[@class='product-cell']/a/@href"time_xpath = "//td[3]/text()"url_list = tree.xpath(url_xpath)time_list = tree.xpath(time_xpath)for i,j in zip(url_list,time_list): url = "https://ladsweb.modaps.eosdis.nasa.gov" + i print(url,j)
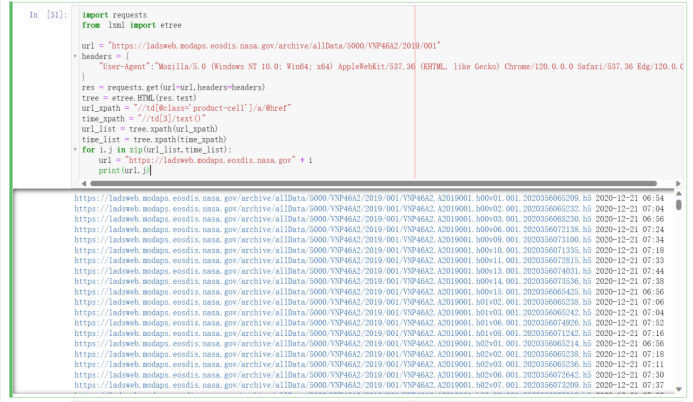
https://ladsweb.modaps.eosdis.nasa.gov/archive/allData/5000/VNP46A2/2020/001/VNP46A2.A2020001.h25v03.001.2021055120623.h5
h25中的h代表经度,v03中的v代表纬度,h25v03代表第26列第4行的数据。
下面使用wget来下载卫星数据:
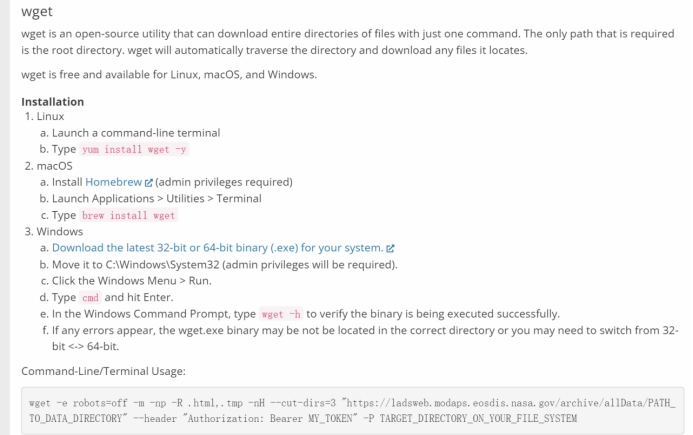
https://eternallybored.org/misc/wget/
通过这个网址下载wget插件,然后将其放在python环境的根目录下。
登录账号密码后可以在此处获取wget的token:
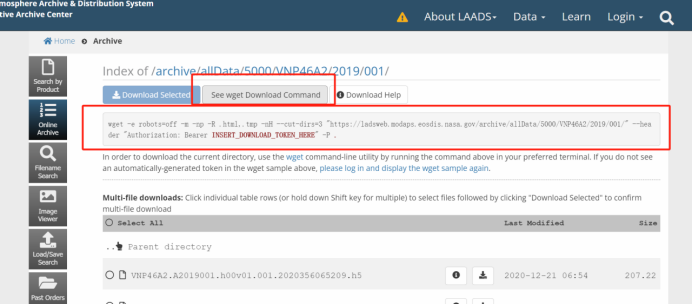
下面是完整的代码:
import requestsfrom lxml import etree
url =
"https://ladsweb.modaps.eosdis.nasa.gov/archive/allData/5000/VNP46A2/2019/001"headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"}res = requests.get(url=url,headers=headers)tree = etree.HTML(res.text)url_xpath = "//td[@class='product-cell']/a/@href"time_xpath = "//td[3]/text()"url_list = tree.xpath(url_xpath)time_list = tree.xpath(time_xpath)for i,j in zip(url_list,time_list): url = "https://ladsweb.modaps.eosdis.nasa.gov" + i print(url,j)import osimport time import datetimeimport calendarimport requestsfrom subprocess import callfrom bs4 import BeautifulSoupfrom subprocess import calltieList=['h25v03', 'h25v04', 'h25v05', 'h25v06', 'h25v07', 'h25v08']yearMonth=[2020,1] totalDay=calendar.monthrange(yearMonth[0],yearMonth[1])[1]baseDay=datetime.date(yearMonth[0],1,1)for day in range(1,totalDay+1): tempDay=datetime.date(yearMonth[0],yearMonth[1],day) dl=str(yearMonth[0])+str((tempDay-baseDay).days+1).zfill(3) webURL='https://ladsweb.modaps.eosdis.nasa.gov/archive/allData/5000/VNP46A2/'+dl[0:4]+'/'+dl[-3:] webHTML=requests.get(webURL) soup=BeautifulSoup(webHTML.text,'html5lib') fileNameNode=soup.find_all('a',attrs={'class':'hide'}) for fnn in fileNameNode: fileName=fnn.text try: if fileName.split('.')[2] in tieList: fileURL='https://ladsweb.modaps.eosdis.nasa.gov'+fnn.get('href') print(fileURL) wgetcmd='wget -e robots=off -m -np -R .html,.tmp -nH --cut-dirs=3 "'+fileURL+'" --header "Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJlbWFpbF9hZGRyZXNzIjoieXluNjI2ODg5QGdtYWlsLmNvbSIsImlzcyI6IkFQUyBPQXV0aDIgQXV0aGVudGljYXRvciIsImlhdCI6MTcwMzc2MTQ3NywibmJmIjoxNzAzNzYxNDc3LCJleHAiOjE4NjE0NDE0NzcsInVpZCI6InN0YXJyeWJlcnJ5IiwidG9rZW5DcmVhdG9yIjoic3RhcnJ5YmVycnkifQ.3K9bKzttlQDBt02LgfRS2yvDKTKBDXC5WiXCRNNE6B0" -P E:/NASA数据/数据' call(wgetcmd) except: pass
数据下载完成。

重磅福利!
为了更好地服务各位同学的研究,爬虫俱乐部将在小鹅通平台上持续提供金融研究所需要的各类指标,包括上市公司十大股东、股价崩盘、投资效率、融资约束、企业避税、分析师跟踪、净资产收益率、资产回报率、国际四大审计、托宾Q值、第一大股东持股比例、账面市值比、沪深A股上市公司研究常用控制变量等一系列深加工数据,基于各交易所信息披露的数据利用Stata在实现数据实时更新的同时还将不断上线更多的数据指标。我们以最前沿的数据处理技术、最好的服务质量、最大的诚意望能助力大家的研究工作!相关数据链接,请大家访问:(https://appbqiqpzi66527.h5.xiaoeknow.com/homepage/10)或扫描二维码:
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
微信公众号“Stata and Python数据分析”分享实用的Stata、Python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
武汉字符串数据科技有限公司一直为广大用户提供数据采集和分析的服务工作,如果您有这方面的需求,请发邮件到statatraining@163.com,或者直接联系我们的数据中台总工程司海涛先生,电话:18203668525,wechat: super4ht。海涛先生曾长期在香港大学从事研究工作,现为知名985大学的博士生,爬虫俱乐部网络爬虫技术和正则表达式的课程负责人。
此外,欢迎大家踊跃投稿,介绍一些关于Stata和Python的数据处理和分析技巧。
投稿邮箱:statatraining@163.com投稿要求:1)必须原创,禁止抄袭;2)必须准确,详细,有例子,有截图;注意事项:1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。2)邮件请注明投稿,邮件名称为“投稿+推文名称”。3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。








