
点击 阅读原文 观看作者讲解回放!
罗先镇,哈尔滨工业大学社会计算与信息检索研究中心博士生,导师为车万翔教授和朱庆福助理教授。主要研究方向为代码智能。更多信息请查看个人主页https://luowaterbi.github.io/。
程序思维链(Program of Thoughts,简称PoT)利用可执行的代码表示推理的中间步骤,再通过执行代码获得最终答案,这保证了推理过程中逻辑计算的准确性。目前,PoT主要使用Python语言。然而,仅依赖单一语言忽视了其他编程语言的潜在优势,可能不是最优的解决方案。在本文中,我们对PoT中使用的编程语言进行了全面实验,发现并没有一种语言能在所有任务和模型中持续提供最优的性能。每种语言的效果因具体场景而异。受此启发,我们提出了一种任务和模型无关的方法,称为MultiPoT(Multilingual Program of Thoughts),它利用了多种语言的优势和多样性,广泛的提升了性能。实验结果表明,它显著优于Python Self-Consistency。此外,在几乎所有模型的所有任务上,它与最佳单语言PoT相比都实现了相当或更优越的性能。特别是在ChatGPT(gpt-3.5-turbo-0701)上,MultiPoT在平均性能上提升超过4.6%。
论文地址:https://arxiv.org/abs/2402.10691
“程序思维链”(Program of Thoughts, PoT)是指让大语言模型(LLM)生成连续的可执行代码以表示推理过程。通过额外的执行器或解释器执行这段代码,我们能够得到一个精确的结果。这种方法将计算的过程从语言模型中分离出来,可以避免计算上的错误。

图1 PoT与CoT(Chain of Thoughts)的对比[1]
本文的动机在于,作者发现所有关于PoT的相关研究都是基于Python的。然而,推理任务本身与具体编程语言无关,因此从理论上讲,使用任何一种编程语言都是可行的。
从任务角度来看,不同编程语言在处理PoT时形式上是不同的。例如,在图2的这张图片中可以看到,Python在进行日期计算时不支持直接输入年份,所以我们只能输入365天来进行有关年份的计算。然而,R和JavaScript则支持直接对年进行计算。这就可能导致当题目跟2008年有关时,Python忽略了这是一个闰年,只减少365天,导致计算错误。而R语言和JavaScript则不会出现这个问题。
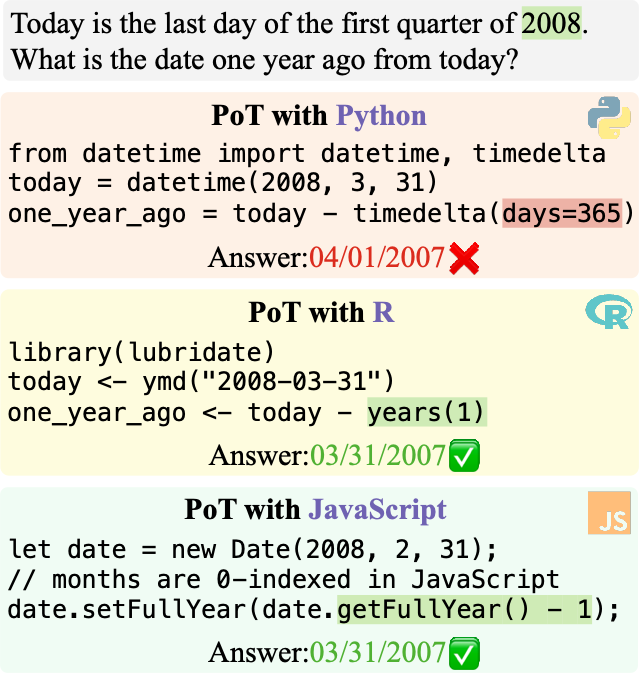
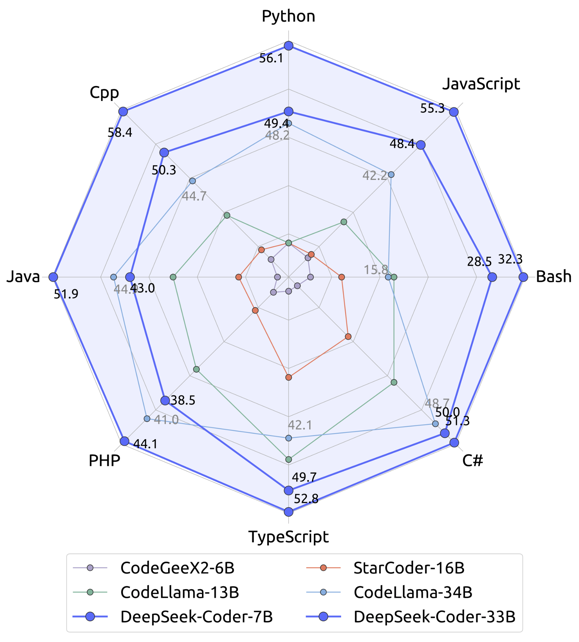
图 3 Deepseek Coder各个编程语言的性能[2]
从模型角度来看,当下的代码大模型(Code LLM)普遍具备多编程语言的能力,但这种多编程语言能力是不平衡的。例如,Deepseek Coder的C++性能要优于Python。
由此我们产生疑问,Python是否真的是PoT的最佳语言呢?
为了评估Python是否是PoT的最佳选择,本文扩展了PoT,引入了Python之外的其他多种编程语言。作者从当前GitHub上最流行的编程语言JavaScript开始。R语言因其灵活性和强大的功能性而著称,但在代码大模型(LLM)的预训练数据中占比相对较少。由于Python、JavaScript和R都是动态语言,本文还加入了两种最常见的静态语言——Java和C++,其中C++更接近底层语言。
在构建各语言的提示(Prompt)时,作者尽量保证与每种语言的最常见语法和风格保持一致。这包括使用内置函数、特殊语法、类型定义和常见的命名约定。这种细致的对齐确保模型在每种语言上都能发挥出自己的最佳性能。

之后,文中选择了五种具有代表性的推理任务,包括小学数学应用题、数学题,以及从BigBench-Hard中抽取出来的时间推理、表格推理和空间推理任务。
可以看到StarCoder、Code Llama、Deepseek Coder和ChatGPT在五种编程语言和五个任务上的性能表现。可以得出一个结论:Python不是最佳语言。Python没有在任何一个模型的任何一个任务上性能最优。同时,结果也显示出并不存在一个在所有场景下都是最佳的编程语言,甚至很难确定某一语言在所有任务上的表现相对较好。
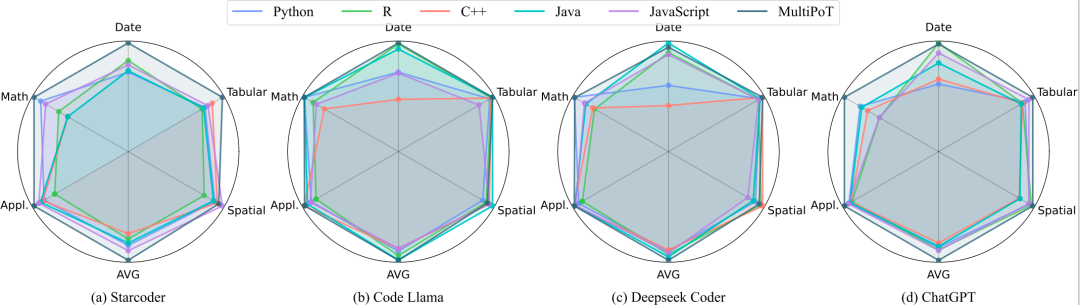
文中的实验结果显示,不同编程语言在各个任务和模型上的表现存在显著差异。例如,R语言在时间推理任务中表现最佳,但在数学任务中表现最差。C++在DeepSeek Coder上获得了最高的平均性能,但在其他模型上排名靠后。
作者深入研究了不同编程语言的推理能力。研究发现,虽然预训练阶段的数据分布确实会影响推理能力,但它并不能完全决定推理能力。
有趣的是,一个模型的代码生成能力与其推理能力并不完全一致,这表明这两种技能是有一定区别的。此外,作者还观察到,不同语言在零样本和三样本推理能力上的表现并不完全一致。这突显了精心构建提示词的重要性,以最大化模型的推理性能。
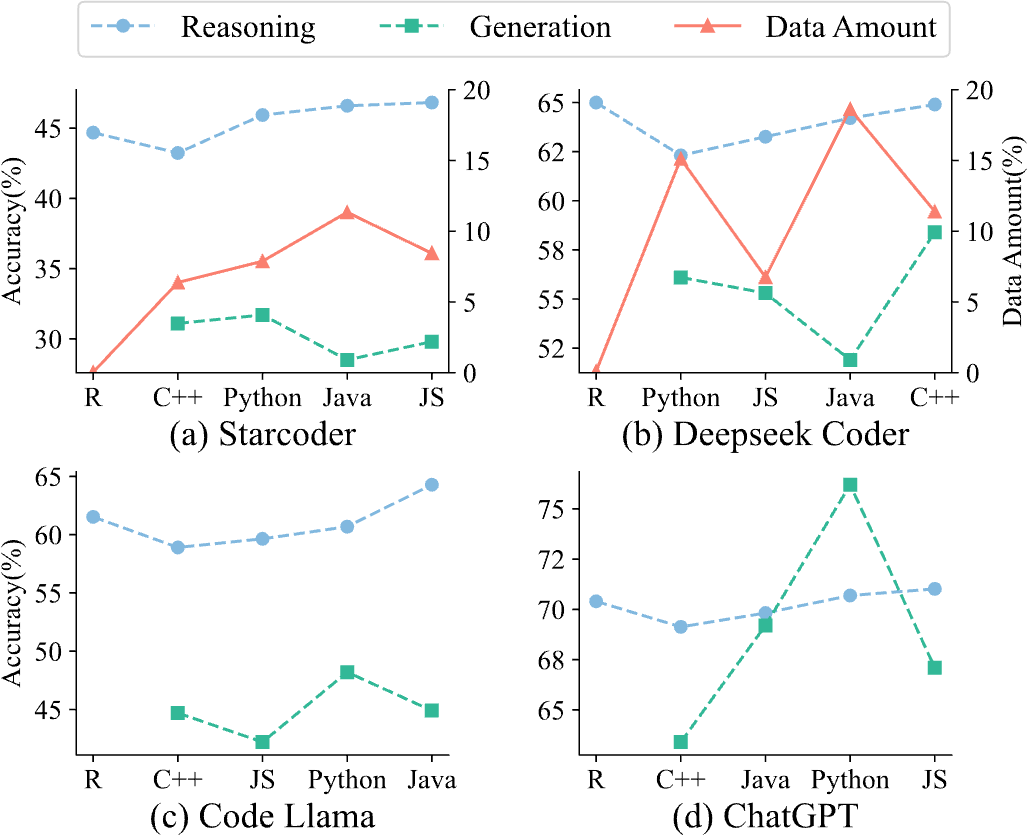
图 6 推理性能与预训练数据占比/模型代码生成性能的关系
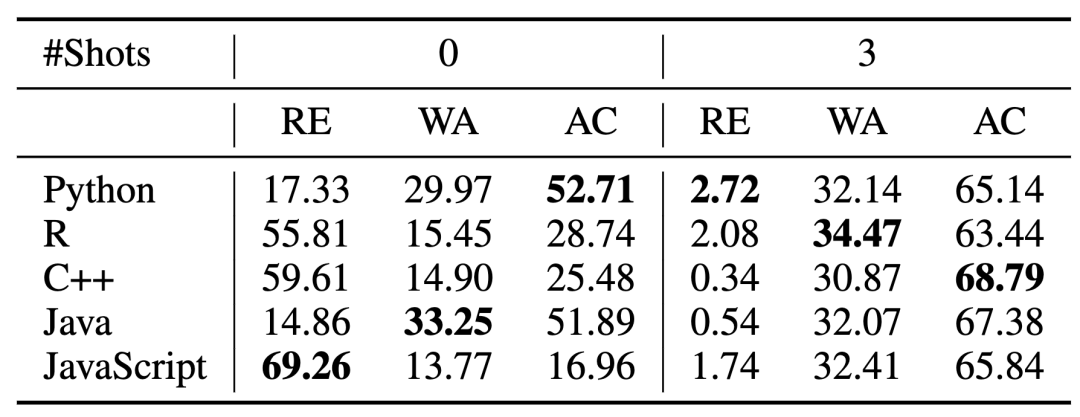
表 1 不同语言3shot与0shot的推理性能对比
接下来,就自然会想到,既然各个编程语言各自具有优势,并且彼此之间具有一定的独特性,我们是否能将它们集合起来加以利用呢?
在传统的Self-Consistency过程中,通常使用同一种语言生成多个样本,然后进行集成。一个比较简单的集成方式是投票机制。然而,这种方法会受到样本多样性的影响,可能会出现重复的错误。例如,如图所示,尽管有一个正确答案,但如果有四个错误的答案为6,投票结果可能仍然选择了错误的答案6。
在构建了多语言的PoT之后,一个直接的方法是在采样时不再使用单一语言,而是基于五种语言各采样一个样本。一方面,各个语言在各自擅长的任务上会表现的更好;另一方面,由于语言之间存在多样性,它们出现重复错误的概率也较低。

图 7 MultiPoT的方法图,与Self-Consistency的对比
文中比较了MultiPoT与Self-Consistency的性能。首先,作者发现单语言Self-Consistency无法解决不同语言之间的性能差距。之后,MultiPoT在几乎所有情况下都显著优于Python。最后,MultiPoT在各项任务和模型中一直能够匹配或超过任何单一语言所取得的最佳结果,突显了其有效性和稳定性。
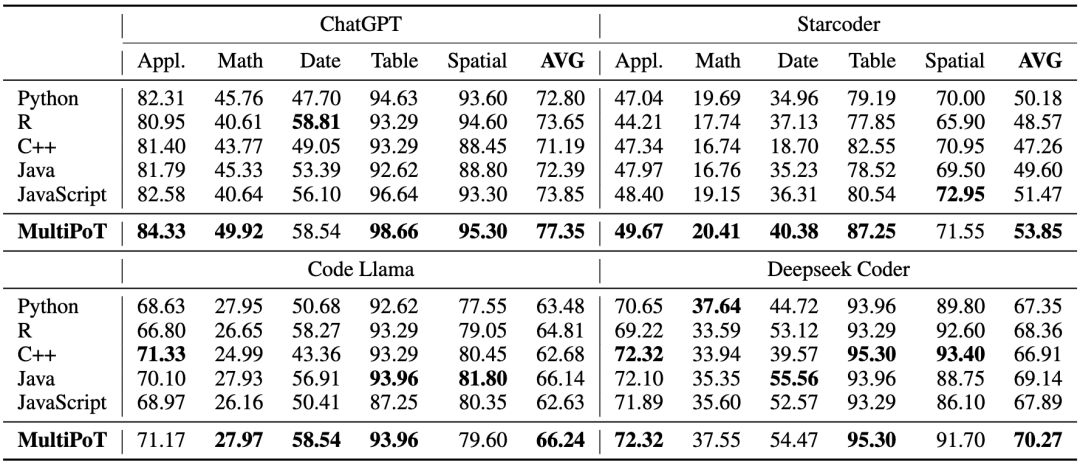
表2 MultiPoT与单语言Self-Consistency对比
本文对MultiPoT进行了更深入的分析,以更好地理解其优势,以下是关键的见解。MultiPoT生成至少一个正确答案的比例(Coverage Rate)是最高的,这表明它具有更高的潜在上限。当投票结果出现平局时,无论采用哪种策略,MultiPoT的性能差异始终小于1。这表明答案的多样性更大——错误答案不太可能重复,从而使正确答案更有可能被选中。
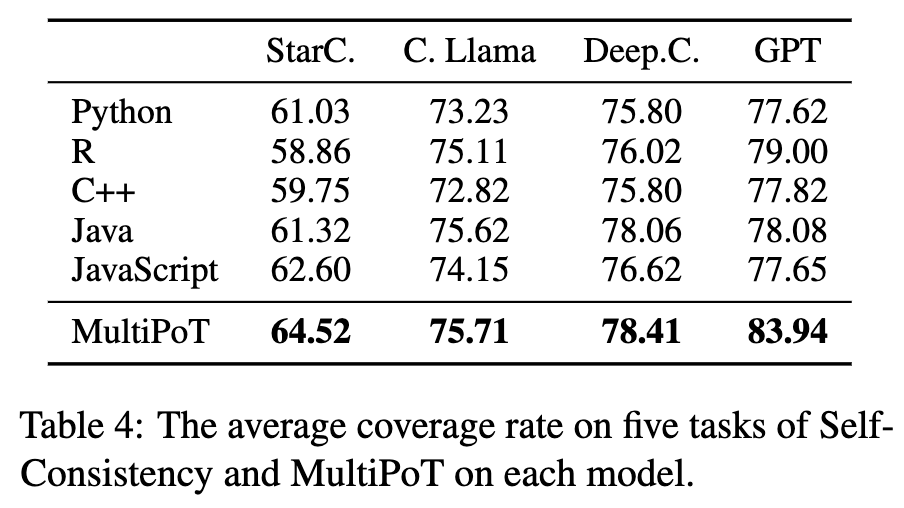
表 3 MultiPoT与单语言Coverage Rate的对比
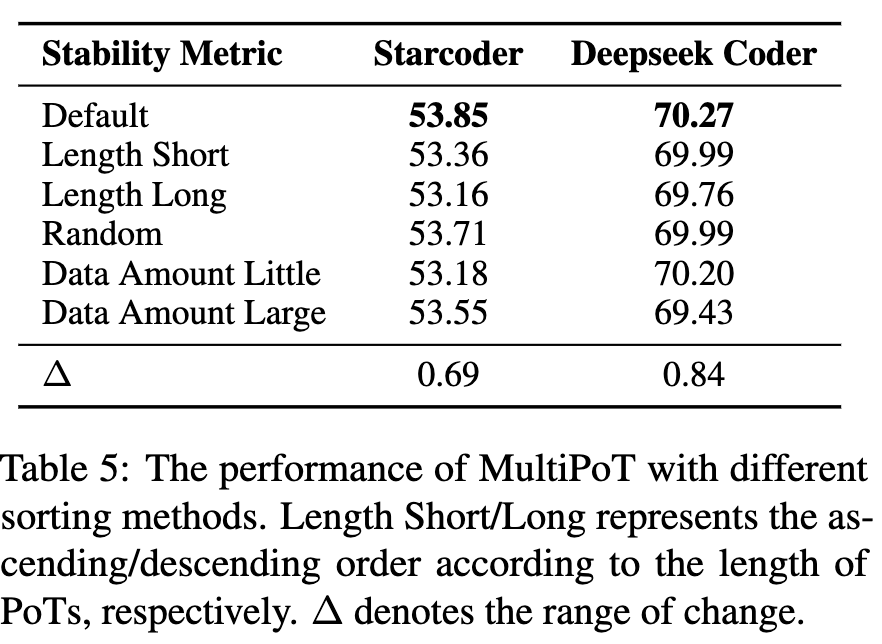
使用更多的语言数量和语言类型是有益的,这种多样性显著提升了整体性能。有趣的是,即使是利用大量Python语料持续预训练的Python版本代码大模型,MultiPoT仍然优于Python Self-consistency,尽管额外的Python训练略微伤害了Base版本代码大模型的多语言能力。
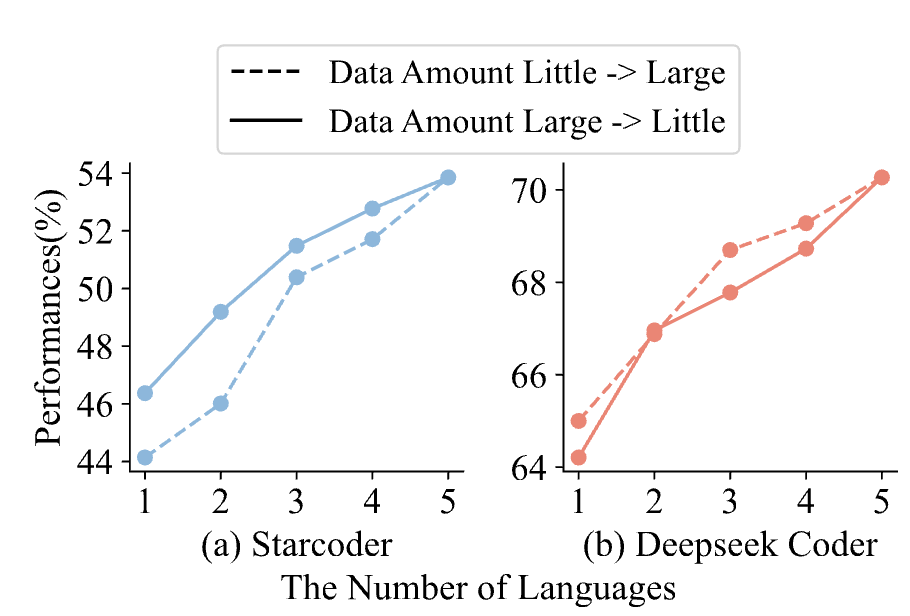

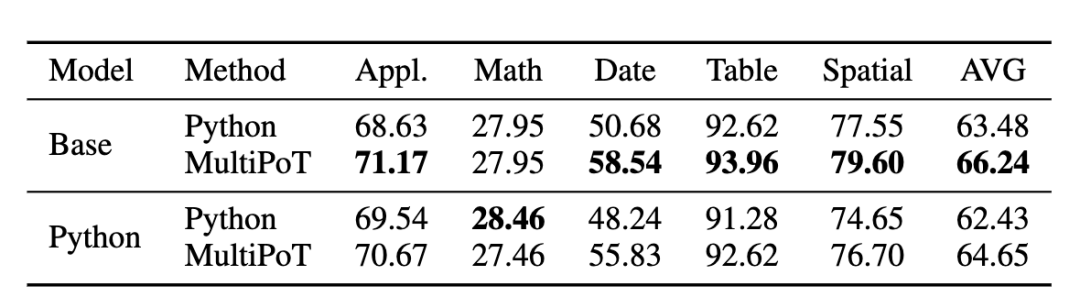
表 6 Python Code LLM和Base Code LLM的Python与MultiPoT性能对比
最后,文章在非数值推理任务中将MultiPoT与思维链(Chain of Thoughs)的Self-Consistency进行了比较,MultiPoT依然有着接近或者更好的表现。这表明了MultiPoT的广泛有效性。
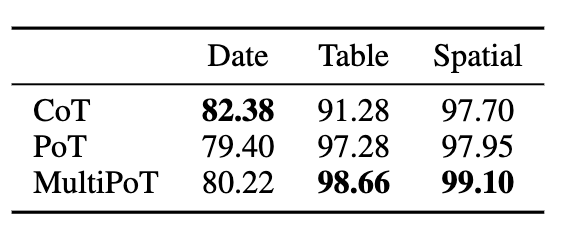
针对PoT只依赖Python的领域现状,本文在多个模型、多种任务上使用多种 编程语言进行了广泛的实验。实验结果表明,Python 并不总是PoT的最佳选择;而最佳语言取决于特定的任务和模型。基于这一结论,作者提出了 MultiPoT,这是一种简单而有效的多语言综合方法,它充分利用了不同编程语言的优势和多样性。在几乎所有情况下,MultiPoT 都明显优于 Python,并能达到或超过最佳单语Self-consistency结果。MultiPoT的稳定性和潜力为未来的研究提供了一个前景广阔的途径。
[1] Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks. Chen et al. TMLR.
[2] DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence. Guo et al. Arxiv 2024.
NeurIPS 2024|清华、加州理工重磅研究:强化自训练方法 ReST-MCTS*,让大模型持续“升级”
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾700场活动,超800万人次观看。










