在快速发展的机器学习领域,深度神经网络彻底改变了我们从数据中进行学习的方式,并在各个领域取得了显著的进步。然而,随着这些模型对私人数据的依赖,隐私泄露的风险日益突出。最近,一种新的隐私攻击方式——模型反演攻击(Model Inversion Attack, MIA)引起了广泛关注。MIA 利用训练好的模型来提取其训练数据中的敏感信息,揭露了神经网络中的隐私风险;MIA 已在多个领域证明了有效性,包括图像、文本和图数据领域。尽管 MIA 的研究影响显著,但目前仍然缺少系统性的研究,使得这一关键领域的诸多进展没有得到清晰的归纳和梳理。为此,在我们最新的综述研究中,我们详细地探讨了 MIA 这一研究问题,由问题定义出发,我们总结了不同数据领域的具体攻击方法及应用实例,整理了应对性防御策略,及常用的数据集和评估方法。在本综述中,我们不仅对当前研究成果进行梳理,还提出了未来发展方向的深度思考,旨在为相关研究者提供清晰的综述分析,并以此激发更多未来研究的探索和创新。Model Inversion Attacks: A Survey of Approaches and Countermeasures论文地址:
https://arxiv.org/abs/2411.10023Survey Repo:
https://github.com/AndrewZhou924/Awesome-model-inversion-attack

基本概要
MIA 的基本设定如图 1 所示。在 MIA 中,攻击者通常会使用经过训练的模型来提取该模型的训练信息。具体而言,MIA 会使用已知输入反复查询模型,并观察其输出以了解模型的行为方式。通过多次执行此操作,攻击者可以收集到用于构建模型的训练数据的详细信息并从模型的输出中抽取敏感数据信息。典型的高风险应用有人脸识别与医学诊断,在这之中 MIA 能够抽取并恢复敏感的个人私有信息,对用户或患者的隐私造成巨大的威胁。  ▲ 图1. Model Inversion Attack的问题设定和基本框架
▲ 图1. Model Inversion Attack的问题设定和基本框架
尽管具体的攻击和防御方法取得了一定的发展,但考虑到 MIA 中对于恢复数据的核心关键问题,数据领域,目前还缺乏对这类隐私攻击与保护方法的系统分类研究,缺乏对某些方法有效或是失败原因的解释及优缺点分类。为此,我们在这项工作中首次全面地调研了 MIA,对其在图像,文本,和图数据领域的攻击与防御方法进行了细致的讨论,具体的文章结构如图 2。
 ▲ 图2. Model Inversion Attack综述的文章结构
▲ 图2. Model Inversion Attack综述的文章结构
除了给定 MIA 正式的定义,我们也讨论了与之相关的一些其他隐私攻击设定,并以图 3 为例,阐明了 MIA 与其他隐私攻击之间的具体区别,如问题设定,攻击对象,具体方法等。
 ▲ 图3. Model Inversion Attack与其他隐私攻击的设定区别
▲ 图3. Model Inversion Attack与其他隐私攻击的设定区别
针对图像、文本及图数据的MIA
在这个综述的主要部分,我们介绍并讨论了针对图像、文本和图数据领域中的 MIA 方法。我们首先概括总结了这些领域中 MIA 方法的发展和核心思路,通过介绍不同的研究工作,对方法的创新点进行了梳理。此外,我们还根据 MIA 中的关键问题,如黑白盒设定,对不同方法进行分类,并总结了设计先进方法的一般性原则,例如增强询问信息质量、利用模型内部信息和使用生成模型。在图像领域,MIA 场景通常分为两类:针对分类模型的标准分类(Standard Classification)和针对协作推理(Collaborative Inference)的场景。图 4 详细展示了这两种 MIA 的场景文献梳理及样例。对于标准分类,MIA 特指一种情况,即敌手试图从一个训练良好的目标模型中推断并恢复训练图像。在这种场景中,敌手仅能访问目标模型,并且输出是一个单热向量(one-hot vector),向量的维度对应于所需类别设置为一。通常在白盒设定(white-box setting)中采用基于优化的方法,其中模型反演问题可以通过基于梯度的优化(gradient-based optimization)来解决。另一种 MIA 涉及到协作推理,其中深度神经网络被分割为多个部分,每部分分配给不同的参与者。输入数据依次通过网络的每一部分,并由这些参与者处理以产生最终输出。这种框架在边缘-云场景(edge-cloud scenarios)中得到了推广,因为它可以解决边缘设备的计算和存储限制。通常,网络的初始层在边缘设备上本地处理输入,而剩余层被卸载到远程云服务器上。这种处理方式可以加快推断速度并降低能耗,但同时也引入了隐私风险,因为可能暴露中间结果。  ▲ 图4. 针对图像领域的MIA文献梳理及样例
▲ 图4. 针对图像领域的MIA文献梳理及样例
在文本领域,MIA 针对三种类型的模型:嵌入模型(Embedding model)、分类模型(Classification model)和语言生成模型(Language generation model)。图 5 详细展示了这三种 MIA 的模型应用场景的文献梳理及样例。嵌入模型将文本数据如单词和句子转换为低维的密集向量,这些向量捕获文本的语义含义。在这类模型上,MIA 通过优化方法或训练攻击模型来揭示向量中编码的敏感信息,从而威胁到数据隐私。分类模型用于将文本分类到预定义的类别或标签中,并常常输出每个类别的概率。利用这些输出概率和模型内部信息,MIA 能够推断出训练数据的敏感属性。语言生成模型根据大量文本数据学习语言的统计规律,并生成连贯的文本。在这些模型上,MIA 通过训练反演模型从模型的输出中恢复隐藏的输入或训练数据。  ▲ 图5. 针对文本领域的MIA文献梳理及样例
▲ 图5. 针对文本领域的MIA文献梳理及样例
在图数据领域,MIA 主要应用于三种策略:基于图相关知识的优化(Optimization via Graph-related Knowledge)、基于模型中间信息的优化(Optimization via Model Intermediate Information)以及从嵌入到图的投影学习(Learning the Projection from Embeddings to Graphs)。图 6 详细展示了这三种 MIA 的模型应用场景的文献梳理及样例。基于图相关知识的优化关注于通过图神经网络(Graph Neural Network, GNN)输出恢复图的连接性,即边的存在性。这种方法通常涉及使用节点特征、泄露的子图和辅助数据集,通过多层感知机(Multilayer Perceptron)等优化技术增强攻击精度,从而实现对图的重建。基于模型中间信息的优化研究 GNN 训练过程中可能泄露的私有拓扑信息。这通过将图重建攻击建模为马尔可夫链近似(Markov chain approximation)进行,分析 GNN 中的潜变量如何被利用来重构原始图的邻接矩阵,并通过量化原始图和攻击链中潜变量之间的相互信息来评估不同变量对隐私风险的贡献。从嵌入到图的投影学习侧重于将节点嵌入反向转换为图结构,包括基于解线性系统的算法和基于梯度下降优化的算法,以恢复从深度行走方法获得的嵌入所编码的信息。这种方法能恢复图的拓扑结构,并可以确定给定的子图是否包含在目标图中,以及基于图嵌入恢复图拓扑。
 ▲ 图6. 针对图数据领域的MIA文献梳理及样例
▲ 图6. 针对图数据领域的MIA文献梳理及样例
针对MIA的防御方法
在回顾了不同领域的 MIA 方法之后,我们对不同数据领域的防御方法进行了介绍。考虑到具体防御方法的应用阶段,我们可以将其分为训练中的防御及推断中的防御两大类,分别应用在模型部署前的训练或微调中,或是在模型部署后的推断应用中,如图 7 所示。在图像领域,训练时的防御策略包括差分隐私(Differential Privacy, DP)、误导性噪声添加、信息限制等方法。例如,通过引入生成对抗网络(Generative Adversarial Network)生成的假样本,使用 NetGuard 防御框架来误导攻击者,阻止其正确分类私有样本。此外,标签平滑的使用可以改善模型对 MIA 的鲁棒性,通过调整输出类别的置信度来减少信息泄露。推断时的防御主要通过输出扰动,如预测纯化框架,通过纯化输出以移除攻击者可利用的冗余信息。在文本领域,训练时的防御策略着重于防止过拟合和对抗性训练,以降低模型对训练数据的记忆能力,从而减少隐私泄露。例如,采用 dropout 技术随机停用神经元来防止过拟合。推断时的防御则通过数据混淆和采样策略来修改或掩盖输出,减少隐私泄露的风险。在图数据领域,训练时的防御方法包括使用差分隐私保护私有链接信息,并通过添加噪声或其他正则化方法来限制模型学习过程中的信息流。例如,通过随机响应技术保持节点度信息的 DP,或使用对抗性训练来增强隐私保护。推断时的防御策略则通过在输出或梯度上添加扰动来实现,如使用 DP-SGD 方法在图分类任务中应用差分隐私。这些防御技术不仅针对特定的数据类型和应用场景,还考虑到了在实际部署中保持模型效用与隐私保护之间的平衡,为防御 MIA 提供了多样化和有效的策略。
 ▲ 图7. 针对三种数据领域的MIA防御方法梳理
▲ 图7. 针对三种数据领域的MIA防御方法梳理

MIA数据集及评估方法
为了进一步便利研究者进行与 MIA 有关的隐私保护研究,我们整理了三种数据领域所用到的相关数据集,并详细标注了这些数据集的具体特征,例如数据维度、分辨率、类别数量等信息,适用于不同的现实场景。同时,我们也标注了这些数据集的来源及它们在相关研究中的应用情况,明确指出了哪些文章使用了这些数据集。这些详细的数据集信息将为未来的研究提供重要参考,帮助研究者快速找到适合的实验数据集,并理解其在不同研究场景中的适用性。这些数据集的详细信息已整理在表 4 至表 6 中。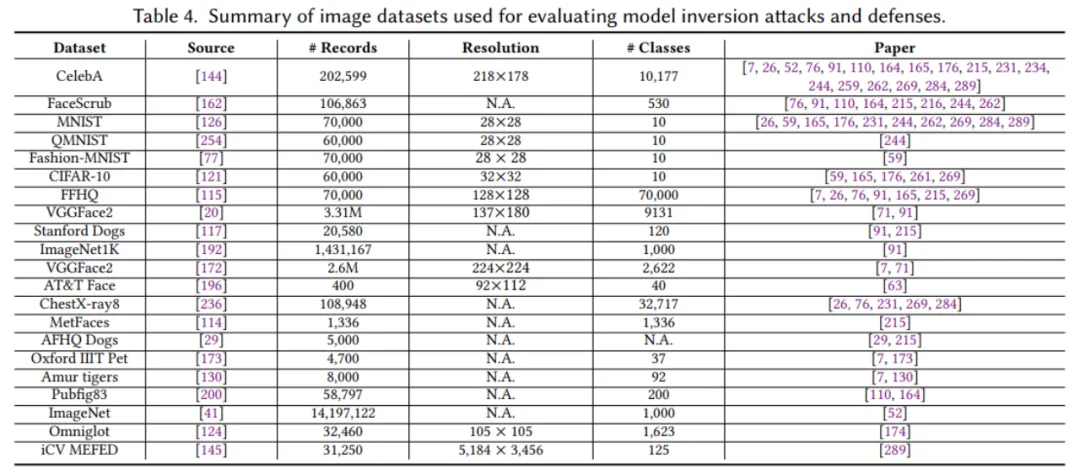
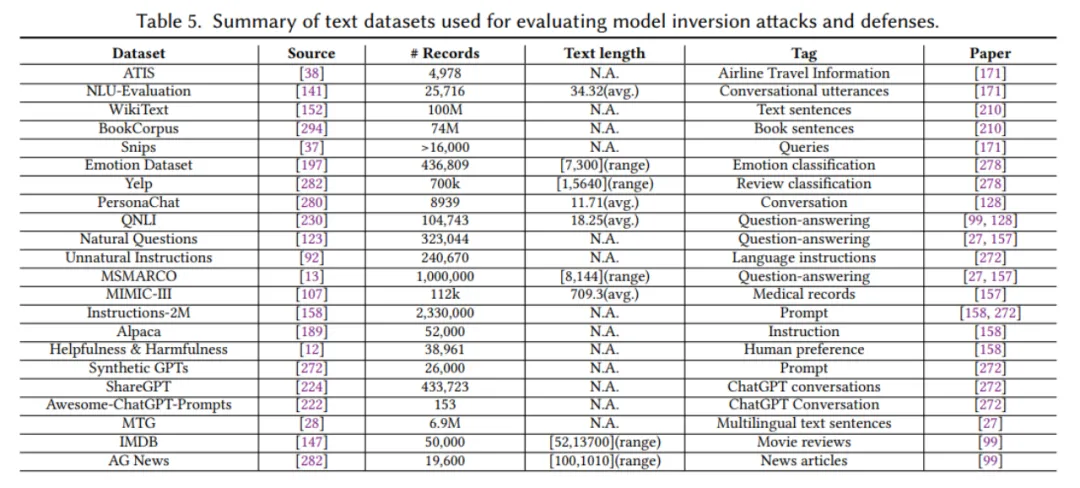
 ▲ 表4-6. MIA文献常用数据集(图像,文本,及图数据)整理
▲ 表4-6. MIA文献常用数据集(图像,文本,及图数据)整理
同时,我们也整理了 MIA 用到的评估指标。我们首先提取了在三个领域通用的指标,这包括准确率、召回率等基本指标,它们适用于大多数模型评估场景。接着,对于每个领域,我们分别整理了各自的特定指标。例如,在图像领域,有 Fréchet Inception Distance (FID) 和 Learned Perceptual Image Patch Similarity (LPIPS) 等,这些指标用于衡量图像生成的质量和真实感。在文本领域,有 BLEU、ROUGE 等,这些指标主要用于评估语言生成的准确性和流畅性。在图数据领域,有 Area under the ROC curve(AUROC)、Joint degree distribution 等,用以评估图结构的预测准确性和模型的预测能力。这些指标为 MIA 研究提供了一套全面的工具,使研究人员能够从多个维度评估和比较不同方法的效果,并促进了模型的优化和改进。



 ▲ 图8-11. MIA文献用到的部分评估指标(通用,图像,文本,及图数据)整理
▲ 图8-11. MIA文献用到的部分评估指标(通用,图像,文本,及图数据)整理
在我们的综述中,我们调研并讨论了针对 MIA 的三个主要数据领域的解决方案,总结了较为普遍的设计目标及原则。一般而言,MIA 的核心思想是尽可能多地利用先验知识从目标模型中提取更多信息,然后生成更真实的样本,有效地揭示训练数据。相反,防御 MIA 的目的是在模型中存储更少的关于训练数据的信息,这样对手就很难从目标模型中恢复隐私数据。虽然这个研究问题已经取得了很大进展,但仍有很多方面值得未来努力,以增强对隐私漏洞的理解:1)问题设定考虑更为实际的现实场景(如考虑不完备的监督信号);2)技术改进考虑结合生成式模型(如利用 diffusion model 的高质量生成效果);3)结合基础大模型考虑隐私漏洞研究对象的迁移(如考虑 LLM 及 VLM 的 MIA)。









