论文题目
ISP MEETS DEEP LEARNING: A SURVEY ON DEEP LEARNING
METHODS FOR IMAGE SIGNAL PROCESSING
摘要
相机的整个图像信号处理器(ISP)依赖于几个过程来转换来自彩色滤波阵列(CFA)传感器的数据,如去马赛克、去噪和增强。这些进程既可以通过硬件执行,也可以通过软件执行。近年来,深度学习已经成为其中一些问题的解决方案,甚至可以使用单个神经网络代替整个ISP来完成任务。在这项工作中,我们调查了这一领域最近的几项研究,并对它们进行了更深入的分析和比较,包括结果和可能的改进点,供未来的研究人员使用。
1介绍
图像信号处理器(ISP)是数码相机的一个组成部分,能够执行各种任务来提高图像质量,如去马赛克、去噪和白平衡。ISP执行的一组任务被称为ISP管道,分为预处理和后处理步骤,不同的制造商可能不同[1]。如今,机器学习被用来取代部分或整个ISP管道。特别是,深度学习被用来取代ISP任务,用于去除噪声或一些阻碍网络处理的图像特征。深度学习网络在计算效率和处理时间方面提供了改进。本文旨在分析27篇基于深度学习的ISP管道的最新研究。
1.1图像信号处理
传统上,isp是数字信号处理器,从RAW图像重建RGB图像。在传统的相机流水线中,使用复杂且专有的硬件处理来执行图像信号处理[2]。它由几个处理步骤组成,包括降噪、白平衡、去马赛克等。ISP中具有损失函数的每一步通常是顺序执行的,残差在运行时累积[3]。后期的参数调整纠正了累积的误差。
传统方法大多采用启发式方法在ISP管道的每一步推导解[2],因此需要调整大量参数。此外,使用基于模块的算法顺序执行的多个ISP进程会导致每个执行步骤的累积错误。为了尽量减少这些错误,研究人员研究了新技术,其中与深度学习相关的算法开始受到更多关注。
1.2深度学习
尽管机器学习的研究可以追溯到1950年代[4],但直到最近十年,技术的进步才使其更复杂的领域得到了广泛的探索。计算能力的快速发展,加上每天产生的数据量的增长,引起了人们对机器学习技术使用的兴趣的微妙更新。因此,化学[5]、医学[6]、经济学[7]和物理学[8]等几个领域已经能够利用它的能力来加速或改进他们的工作,直接受到这种被称为深度学习领域的进化的影响。
深度学习作为机器学习的一个子集,由基于人工神经网络的算法组成,这些算法使用多层神经元从提供给它的原始数据中提取更高级的特征[9,10,11]。这类算法需要巨大的计算能力,而这种计算能力是近几年才出现的。在对计算能力要求很高的同时,深度学习算法的学习能力也随着提供给系统的数据量的增加而提高。出于这个原因,在运营中有大量数据涌入的领域,在深度学习中看到了一种有趣的方式来发现和理解隐藏的信息。
使用深度学习取得巨大成果的领域之一是图像处理(计算机视觉的一个子集),更具体地说,是使用卷积神经网络(CNN)。cnn是一类受生物过程启发而更倾向于处理视觉图像的神经网络,其创建方式是神经元的连接模式模仿动物视觉皮层的模式[12,13]。cnn的另一个重要方面是,遵循与其他网络不同的路径,它们使用非常少的预处理,能够自己学习以优化内核。这些特征使得cnn在图像处理任务中的使用更加普遍。
1.3 ISP与深度学习的关系
使用CNN取代基于硬件的ISP的意图是合理的,因为CNN可以补偿输入图像中的信息损失,使其比传统实现的ISP更可靠,因为传统的ISP在每一步都会累积误差[1]。[31]是最早提出用CNN代替智能手机ISP摄像头并使用PyNet网络提供RAW-to-RGB数据集的人之一。这些展示了CNN在图像处理方面的潜力,甚至可以取代最先进的互联网服务提供商。
网络cnn不仅在低层次的视觉任务中表现出显著的优势[2],在物体检测和分割等高级任务中也表现出良好的效果[14]。有了这些优势,使用cnn将RAW图像转换为RGB图像成为可能。
尽管取得了良好的效果,但使用CNN替代ISP的工作却很少。[3]提出了在传统ISP管道中执行必要调整的困难,并开发了一种执行ISP管道的CNN。
1.4与其他作品的比较
巩固一个正在发展的科学领域的最好方法之一是对该领域的最新技术进行调查。通过这种方式,可以方便地访问这类信息,使其更容易理解和选择针对个人情况使用哪种技术。例如,在深度学习领域,在许多不同的领域已经有了大量的调查,如农业[15]、网络安全[16]、自动驾驶[17]、医学成像[18],以及更多的技术领域,如CNN[19]。但对于最近的领域,比如使用深度学习来取代互联网服务提供商,可能仍然很难找到这种收集到的信息。
虽然已经有一些关于ISP各个步骤的调查,如去马赛克[20]和去噪[21],但仍然没有简单的方法来找到和比较端到端的ISP深度学习方法。在本文中,我们总结了许多这些方法,并将一些最先进的人工神经网络(ann)引入该领域。
1.5本工作的范围
对于本研究,文章根据三个要点进行研究:
•新颖性:介绍最新和重要的工作,包括通过深度学习方法替换部分或整个ISP管道的策略;
•最近开发的:所考虑的所有研究都是在2019年至2022年之间发表的,因此本研究非常新。
那些被考虑的论文并没有寻求相同的ISP任务和改进。图1显示了所审查文章中ISP研究的功能分布,表1给出了本工作中讨论的所有方法的列表。
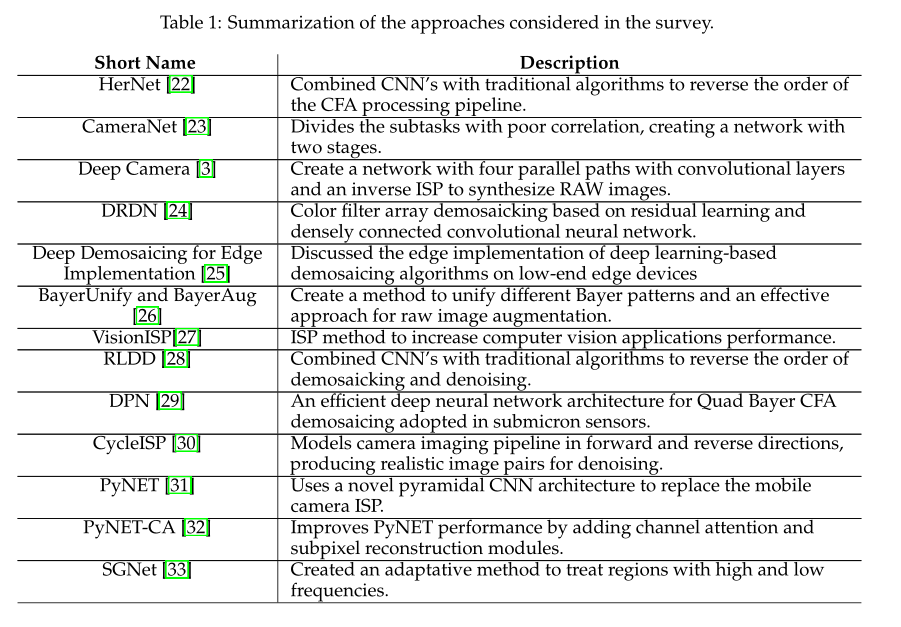
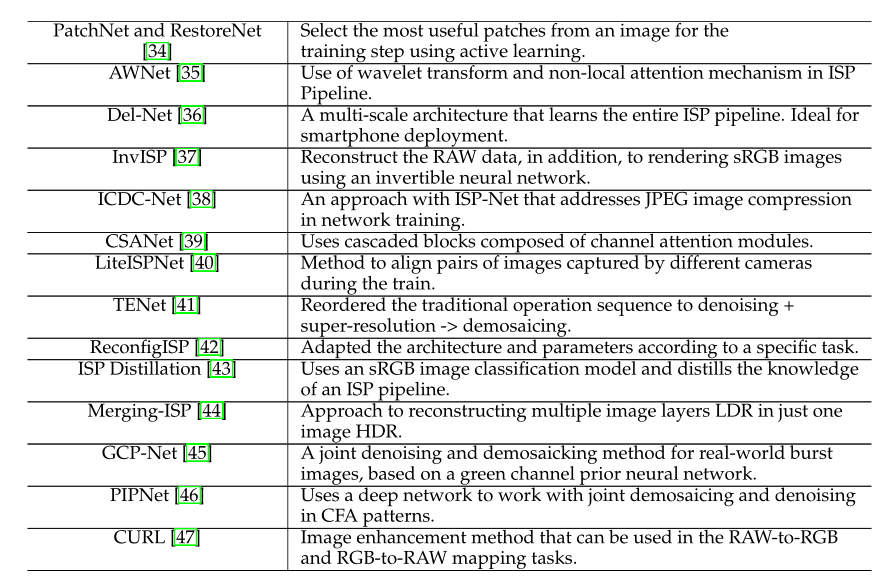
大约30%的论文提出了一个使用端到端深度学习方法的完整ISP管道框架。其他人则针对ISP管道的特定阶段开发了深度学习解决方案,例如去噪任务、联合去噪去噪任务、分辨率增强任务等。
他们中的一些人还提出了额外的和独特的ISP深度学习技术,如RAW数据增强和使用反向ISP过程从RGB图像生成RAW数据。
图2显示了我们如何映射所研究的ISP任务。我们将它们分为两组:ISP功能,当提议的解决方案涉及具体的ISP操作时,以及ISP管道,当提议的解决方案解决RAW到RGB或RGB到RAW操作和整个ISP程序时。
1.6工作结构
接下来的工作结构如下:第2节描述了ISP的总体概念、传统管道和算法。第三部分为本研究收集到的作品简历。第4节介绍文结果。第5节详细描述了本研究期间收集的方法。第6节总结了本文的工作。
2软件ISP
在过去的二十年中,由于使用数码相机作为次要或主要功能的嵌入式设备的普及,对可靠的数字图像捕获和处理系统的需求显着增长。如今,处理速度和图像质量是大多数这些设备的重要卖点。话虽如此,图像重建系统的研究从未如此重要。
传统上,数码相机由两个子系统结合而成,第一个子系统专门用于采集光敏模拟传感器网格测量的信号,通常称为传感器元件[1]。现代传感器元件对光线变化具有很高的灵敏度,但无法自行识别颜色变化。这个问题的一个可能的解决方案是使用3个不同的传感器元件,每个元件都有一个特定的滤波器来捕获特定频率范围的可见光。
这种策略除了会增加硬件成本外,还会带来许多技术问题,主要涉及传感器对准、光线入射差异等问题[1]。现代传感器元件有一个已知的模式光频率滤波器嵌入其中,这使得有可能重建一个彩色图像与一个单一的传感器元件。这些过滤器被称为颜色过滤器阵列(CFA)。拜耳滤色器(Bayer Color Filter, BCF)是一种特殊类型的红绿蓝(RGB) CFA模式,广泛应用于现代图像传感器中。BCF是建立在人类视觉系统(HVS)对绿色光谱的颜色更敏感的假设之上的。据此,BCF由一个2 × 2的网格模式组成,其中包含两个绿色、一个红色和一个蓝色传感器[1],如图3所示。
BCF滤波器放置在传感器元件的正前方。捕获过程产生的信号经BCF滤波后称为拜耳阵列(Bayer Array, BA),由每个像素的单色强度组成,遵循BCF模式。RAW图像文件是由BA数据和捕获时获取的元数据组成的,在本节中,诸如捕获时间、预处理策略、黑电平、光圈、曝光、ISO等信息通常封装在标准的可交换图像文件(EXIF)数据中。
现代图像传感器,如OmniVision的OV5647,使用由2624×1956光敏传感器网格组成的传感器元件,由一层BCF覆盖。除了图像数据采集外,该设备还提供了自动曝光控制(AEC)、自动白平衡(AWB)、自动带滤波器(ABF)、自动黑电平校准等多种处理选项,以提供更好的整体图像质量的RAW输出[4]。
一种ISP管道,通常称为数码相机的第二子系统。它建立在一系列旨在将RAW图像文件转换为可见数字对象的过程之上,以便显示和存储捕获的图像。传统管道的一些步骤将在这里进行一般性的探讨。
传统上,ISP管道被构造为一系列连续的操作。ISP的输入通常是RAW图像,输出是RGB编码的数字图像。商业使用的互联网服务提供商可能会根据制造商的需要,在顺序和操作类型上有所不同。这些信息是不可用的,然而,有一些基本的操作是大多数isp所必需的,并被用作研究这种类型的子系统的基础。也就是说,几乎所有的传统isp都有一些共同的阶段,这些阶段如下图4所示。
尽管现代图像传感器能够解决许多数据采集问题[4],但对RAW图像中包含的数据进行预处理对于验证信号完整性、识别和修复采集故障、防止错误通过以下操作传播非常重要。在ISP预处理的背景下,通常会提到三个阶段:信号调理、缺陷像素校正和黑电平偏移量。信号调理是指将传感器获得的数据进行归一化、线性化等必要的操作,使其适应ISP的处理[1]。
2.1黑电平偏移校正
黑电平偏移校正是由于图像传感器的不精度造成的,其目的是校正ISP输入值以减少黑电流效应,黑电流效应往往会增加传感器元件测量的光强,并在处理后的图像中造成模糊效果[1]。黑电平偏移的目的是确保图像中包含的黑色色调被正确注册。现代图像传感器通常提供包含用于黑电平校正的掩模的阵列[4]。
2.2缺陷像素校正
缺陷像素也是常见的和预期的采集误差达到一定数量[50],它们是由于生产误差、存储方法和温度问题引起的测量问题而发生的。一般来说,缺陷像素的识别是通过分析中心像素相对于其相邻像素的光强变化来完成的[50]。缺陷像素的校正有几种方法,其中一种方法是将相邻点的平均值应用于识别出的缺陷像素[50]。
2.3白平衡
在解决采集问题之后,传统ISP通常的第一步是对输入数据执行白平衡。虽然HVS能够识别不同类型光源照射下物体的白色,但数字系统不具备这种能力,不同频率范围的光会导致不同的测量值[51]。白平衡是一个步骤,旨在确保被测颜色重建后人眼具有自然色调[1]。isp经常使用的策略是AWB策略,虽然许多图像传感器已经内置了该功能,如OmniVision的OV5647,但许多isp单独实现它。一种常用的方法是使用灰色世界假设,即在大多数情况下,每个采样通道的平均颜色趋于相等。基于这一原理,绿色通道测量到的平均光强与其他通道测量到的平均光强之比作为在所有像素上进行校正的基础[51]。
2.4 Demosaicing
数字图像重建中计算量最大的步骤是将CFA数据转换为可见图像,这个过程称为去马赛克。执行此操作的一种循环策略是通过对CFA中每个像素的绝对值进行一些权重插值。尽管大多数商业上使用的去马赛克技术都受到专利保护。一些开源应用程序,如RawTherapee,使用的去马赛克技术是透明的。在此应用中,使用自适应均匀定向[52]等算法重建可见图像。
图5显示了智能手机三星G9600的ISP管道输出(第三张图)与图像传感器发送的RAW图像(第一张图)的对比。分析传感器输出的元数据,可以确定捕获过程中使用的CFA颜色模式是Bayer Green-Red-Blue-Green模式。该信息用于在原始RAW上执行去马赛克(第二张图像)。第二张和第三张图像之间的比较突出了ISP管道中所有步骤的重要性,以便重建高质量的照片。
2.5去噪
图像去噪是数字图像重建任务中的一个复杂步骤,其目标是去除输入图像中的噪声以估计原始图像。由于图像传感器硬件组件的缺陷或异构性,以及由于图像压缩的原因,传统的ISP流水线通常采用这一步骤。图像去噪在视觉计算领域的许多应用中都非常重要,近年来受到了很多关注[53,54,55,21,56]。已经提出了几种图像去噪方法。它们可以分为经典方法和深度学习方法。经典的方法包括空间域法和变换域法,前者在图像中使用滤波器去除噪声,后者改变输入图像的域,然后使用去噪过程来改善图像。在大多数情况下,深度学习方法是基于cnn的方法。在本次调查中,将引用一些深度学习用于图像去噪的研究成果[57,26,58,33,59,60]。
2.6 Deblurring
模糊是数字图像处理中难以避免的常见伪影,它可以由各种来源引起,如运动模糊、失焦、相机抖动、极端光强、ISP管道累积误差等。鉴于此,文献中存在许多手工去模糊算法来缓解这一问题[61,62],其中一些被包含在isp中。razlight和Kehtarnavaz[63]提出了一种针对手机的去模糊方法,通过考虑亮度和对比度来校正模糊图像。另一方面,Hu等人[64]考虑使用智能手机的惯性传感器、陀螺仪和加速度计进行核估计,并利用在线校准来同步相机和传感器。然而,这些经典方法中的许多只涉及某些情况,实现手工特征提取,并且需要前两个步骤[61]:模糊检测和模糊分类。深度学习是最近几年解决这些问题的另一种选择,可能将所有这些步骤联合在一个单独的步骤上[65]。
2.7后处理步骤
每个相机制造商可以使用不同的,通常是专有的处理方法来提高图像质量。后处理步骤的目的是对经过前面处理的图像进行一些调整。一些最常见的后处理步骤是边缘增强,去除彩色伪影和取芯[1]。这些技术使用启发式方法,需要大量的微调。
例如,去马赛克步骤可能会引入有问题的工件,例如图像其余部分的拉链边缘和五彩纸屑。在后期处理阶段,在不损失图像清晰度的情况下,将这些伪影保持在最低限度是至关重要的[1],一些相机制造商使用边缘增强技术,通过减少图像中包含的低频物体,使图像更具吸引力。这些问题的解决方案涉及许多变量,从捕获传感器的大小到所使用的去马赛克技术。
2.8渲染色彩空间
渲染的色彩空间通常用作输出,并且具有有限的比例,不像基于场景的未渲染。渲染的色彩空间是基于从未渲染空间的图像中提取的数据创建的,其最大包含8b,而未渲染空间的可变范围在12 - 16b之间[1],因此,将未渲染空间转换为渲染空间的过程包含动态范围的损失。
最常见的渲染空间是sRGB[1]色彩空间,这在多媒体中已经变得很常见。另一个常见的渲染空间是ITU-R BT.709-3,它是为高清电视而设计的。sRGB标准采用ITU-R BT.709-3定义的主频。正是这些模式定义了将未呈现的空间转换为大多数输出媒体强制的8b值的方法。
根据预览模式,需要将图像转换为适当的色彩空间。一个例子是在使用加色系统的CRT显示器观看的情况下,给定所使用的显示模型、偏移值、色温和gamma值,图像需要转换为8b输出。
当目标是存储时,我们有两种解决方案,具有非常大的传感器集和更大的存储空间的专业相机,通常以专有格式或标签图像文件格式/电子摄影(TIFF/ EP)存储图像。以TIFF/EP形式存储的图像有额外的信息,如相机设置细节和颜色变换矩阵[1]。JPEG2000是一种国际标准,除了提供控制数据压缩大小和图像分辨率等特性外,它还提供了比通用JPEG标准更有效的压缩。然而,尽管JPEG2000带来了好处,但它的计算复杂性和高内存成本是限制因素。
鉴于现代ISP管道的高度复杂性和调整需求,许多研究正在进行,旨在使用机器学习将RAW图像数据转换为高质量的输出。这项工作显示了这些研究的最新水平。
3 相关方法
在本节中,我们回顾了基于深度学习的方法在替代传统手工ISP管道中的应用,其中包括反马赛克、去噪、白平衡、色调调整和曝光平衡等操作。此外,我们简要总结了一些使用这种方法来提高其他计算机视觉任务性能的工作。
3.1 HERNet
高分辨率网络(high-resolution Network, HERNet)[22]是一种可以在不过度消耗GPU内存的情况下学习高分辨率图像补丁的局部和全局信息的网络。该网络有局部和全局特征提取两条路径,并引入了金字塔全图像编码器[22],实现了输出图像的正则化,有助于减少人工制的数量。此外,本工作提出了逐步增加输入分辨率来训练模型,这使得性能稳定,训练时间短。
局部信息路径由多尺度残差块(Multi-Scale Residual Blocks, MSRBs)[66]组成,该块具有两个卷积层,分别具有3x3和5x5并行核。此外,在全局信息路径中,采用了带有改进残差中残差(RIR)[67]模块的Autoencoder机制进行特征提取。改进的RIRs模块旨在减少GPU内存的使用,特别是对高分辨率图像,然后通道注意单元被移除,并堆叠剩余的。最后,作者使用ZRR数据集[31]对模型进行训练和验证,并且只使用L1损失进行训练。不幸的是,L1损失倾向于在不对齐的数据集中产生模糊的图像。
采用渐进式训练对网络进行训练,在训练过程中,输入图像的分辨率不断提高,网络结构始终保持不变。因此,这个过程可以使网络更快地收敛。此外,HERNet在AIM 2019 RAW到RGB映射挑战赛中获得了保真度赛道1第二名和感知赛道2第一名。在AIM 2019 RAW到RGB映射挑战赛中,HERNet获得了保真度赛道1第二名和感知赛道2第一名。
3.2 CameraNet
CameraNet[23]为基于深度学习的ISP管道提出了一个有效且通用的框架,该框架将CNN的两个阶段堆叠在一起。这样做的动机是ISP管道的一些子任务相关性较差,然后将来自ISP管道的子任务分为两个阶段:第一阶段是恢复阶段,任务包括去马赛克,去噪和白平衡,增强阶段是第二阶段,执行任务包括曝光调整,色调映射,颜色增强和对比度调整。此外,使用Adobe Camera Raw1和Adobe Lightroom 2为数据集HDR+[68]和FiveK[69]中的每张图像创建两个ground truth。每个真值都被用来训练不同的阶段。
在CameraNet管道中,在这两个主要阶段之前,输入图像要进行预处理,去除坏像素,用插值进行初始去马赛克,并将RGB转换为CIE XYZ空间,因为它与人类感知有关。此外,由于U-Net具有多尺度提取的特点,它是这两个阶段的基础模型。我们做了一些改变,比如在网络的最底层增加了一个完全连接的层,并在每个阶段使用不同的处理块。恢复阶段使用普通卷积块,增强阶段使用残差连接来改进细节。此外,在实验中,CameraNet生成的图像在HDR+和主要是SID[71]数据集中比DeepISP[70] Network具有更少的噪声、伪影、更好的颜色映射和更高的定性分数。对这种差异的解释可能是SID数据集中的高水平噪声和CameraNet中两个阶段中弱相关子任务的分离。在FiveK数据集中,两种方法在SSIM上都取得了相当的结果,但CameraNet在PSNR和Color Error指标上取得了更好的结果,因为该数据集是用高端相机捕获的,降低了噪声水平。与深度学习方法相比,使用默认设置生成图像的DCRAW和CameraRAW的结果最低,这是由于传统方法的局限性。
3.3 Deep Camera
作为第一个提出替代整个ISP管道的CNN网络,Deep Camera[3]是一个具有四条平行路径的小型网络:一条主路和另外三条短路径,中间有一个卷积层。对此的解释是,与ResNet相比,该模型非常小,因此网络不能很好地将输入复制到块的输出。此外,作者创建了一个反向ISP来从一个大型数据集[72]中重建RAW图像,该数据集包含11,000张图像和几种类型的场景和光源,其中训练和实验阶段使用结果数据集。
CNN模型在白平衡和图像重建任务上优于传统方法,提供了许多更好的图像。然而,在一些具有许多不同颜色的图像中,算法更好。此外,深度相机可以做缺陷像素校正,并用于其他彩色滤光片马赛克,如富士胶片的X-Trans彩色滤光片。
3.4 DRDN
DRDN[24]提出了一种卷积神经网络对彩色滤光片阵列去马赛克。使用拼接图像作为输入,提出的模型以端到端方式进行训练,以生成去拼接图像输出。与其他传统的基于卷积神经网络的反马赛克模型相比,该模型不需要对拼接后的输入图像进行初始插值,因此计算复杂度较低。由于残差学习[73]和密集连接的卷积神经网络[74],它还解决了许多深度神经网络遇到的梯度消失问题。此外,该模型采用了分块卷积神经网络来考虑局部特征和亚像素插值层,从而更高效、准确地生成去马赛克输出图像。
本文对具有挑战性的去马赛克任务进行了特殊的解释和情境化,引用了类似的先前方法,并强调了每种方法可以改进的地方。该研究详细说明了与所考虑的数据集相关的训练参数和方面。最后,进行了大量的性能比较,其中所提出的方法在绝大多数情况下脱颖而出。另一方面,考虑到所研究的数据集具有中等大小的图像,本文没有透露验证阶段获得的推理时间。同样,作者可以更深入地讨论在某些评估病例中DRDN没有达到最佳PSNR的原因[24]。
3.5边缘实现的深度去马赛克
在本文[25]中,作者讨论了在低端边缘设备上实现基于深度学习的去马赛克算法的主要挑战。他们对深度神经网络架构进行了广泛的搜索,获得了彩色峰值信噪比(CPSNR)的帕累托前作为损失与参数数量作为模型复杂性。本文为去马赛克方法提供了一个有价值的参考框架,分为六类:边缘敏感法、定向插值和决策方法、频域方法、基于小波的方法、统计重建技术和基于深度学习的方法[75]。同样,作者回顾了其他相关的去马赛克方面,如不希望出现的图像伪影和性能评估方法。
这项研究基于离散的和构造良好的超参数,如过滤器和块的数量,跳过连接的长度,以及深度可分离卷积的使用,对体系结构进行了详尽的搜索。提出了一种正确的神经结构搜索和帕累托构造的方法和数学理论。重点是关于神经结构搜索收敛的五个全新定理。最后,具有简单穷举搜索的设计空间优于最先进的空间,并且在不同资源约束下为边缘实现带来了一系列损失与复杂性,克服了与评估次数和搜索算法复杂性相关的缺点。作为缺点,作者应该更多地讨论给定架构搜索在其他图像处理任务中的使用,而不仅仅是在边缘实现挑战中。
3.6 BayerUnify and BayerAug
Liu等[26]提出了两种基于dnn的RAW图像去噪新技术。第一种是拜耳模式统一(BayerUnify)方法,它可以有效地处理来自不同数据源的各种拜耳模式。第二种方法是bayerpreserving augmentation (BayerAug),允许对RAW图像进行适当的增强。将这两种技术与改进的U-Net相结合,该方法在NTIRE 2019真实图像去噪挑战中获得了令人满意的SOTA PSNR为52.11,SSIM为0.9969。
拜耳模式统一(BayerUnify)由两个阶段组成。在训练阶段,研究通过裁剪统一了不同拜耳模式的原始数据。例如,该技术将BGGR拜耳格式映射到其他格式(RGGB、GRBG和GBRG)中,选定的区域,将任何拜耳模式转换为BGGR(或任何其他选择的模式)。在测试阶段,由于图像像素需要处理,该技术通过填充将拜耳模式统一起来。随后,进行网络去噪和去除多余的像素,使输出图像不统一并反转模式转换。
传统的数据增强方法通常是基于图像翻转或裁剪。然而,对于RAW图像,翻转过程可能会影响拜耳图案。BayerAug将翻转和裁剪结合起来,解决了这个问题。本文提出了三种不同的翻转方法,使Bayer RAW图像的数据增强没有任何问题。
该研究在智能手机图像去噪数据集(SIDD)[76]上评估了所提出的方法- 320对包含三种不同拜耳模式的有噪声和无噪声图像。使用L1 loss、AdamW[77]优化器和200,000次迭代对网络进行训练。
本文对拜耳模式的预处理和增强进行了较好的介绍,并对相关工作进行了讨论。本文对所提出的方法进行了适当的解释,并给出了网络结构和特殊的训练细节。在该框架参考下,该研究显示了利用深度学习技术处理RAW图像的一个有希望的方向。作为限制,作者可以与相同的NTIRE 2019挑战中的其他作品进行比较,并更深入地讨论所提出的方法在实际设备中的应用。
3.7 VisionISP
Wu等人[27]为计算机视觉应用提出了一种特殊的ISP方法。VisionISP在不丢失相关信息的情况下减少了数据传输需求,优化了后续计算机视觉系统的性能。该框架由三个处理块组成。第一个块,视觉去噪器,减少输入信号噪声并修改现有ISP上的调谐目标。该研究采用了Nishimura[78]提出的技术来优化去噪参数,为计算机视觉任务构建去噪器,而不是为图像质量。本文还强调了可以跳过去马赛克步骤,并且使用彩色滤波器阵列图像代替去马赛克图像并没有提高计算机视觉任务的性能。第二个块,视觉局部色调映射(VLTM),减少了比特深度,以更少的比特每像素实现类似的精度。VLTM使用全局非线性变换和局部细节增强算子。最后,可训练视觉缩放块(TVS)是一种通用的神经网络,用于处理和缩小后续计算机视觉引擎的输入。
VisionISP使用KITTI 2D目标检测数据集[79]进行训练和评估,这是一个自动驾驶基准数据集。该研究测量了每个VisionISP块对平均精度(mAP)的影响。作为实验中的计算机视觉任务样本,作者使用了SqueezeDet[80]框架及其原始代码。
本文对每个VisionISP组件进行了适当的解释和评价。作为一个积极的方面,实验表明,一旦TVS被训练,它可以与其他计算机视觉系统一起使用。VisionISP作为一个整体可以与计算机视觉主干联合或单独训练。此外,所提出的框架的每个组件都提高了计算机视觉引擎的性能,并且可以独立部署。
然而,本文可以提供更多的训练细节(例如,epoch数,时间推理,硬件等),并将VisionISP与当时其他计算机视觉优化系统的有效性进行更深入的比较。
3.8 RLDD
在本文[28]中,作者将卷积神经网络与传统算法相结合,颠倒了传统CFA流水线的顺序(去马赛克和去噪)。该方法,我们称之为RLDD,使用两个阶段去马赛克去噪。第一阶段通过组合基于梯度的无阈值(GBTF)方法[81]和卷积神经网络进行去马赛克,以克服子采样操作中图像分辨率的降低。第二阶段使用另一个卷积神经网络进行去噪,其目标是处理残余噪声。由于复杂的插值,残余噪声的性质发生了改变,卷积神经网络的目标是在不丢失图像细节的情况下去除残余噪声。
结果在Kodak[82]、McMaster[83]和Urban 100[84]数据集上进行了验证,并表明该模型在所有数据集上都优于最先进的去马赛克和联合去马赛克和去噪算法,具有更高的PSNR和SSIM值。两种方法之间的视觉对比结果证实了所获得的定量值,表明图像的视觉质量较好。然而,该方法的去马赛克和去噪的平均运行时间并没有超过所有评价的方法。
3.9 DPN
本研究提出了一种双金字塔网络(DPN[29]),这是一种用于亚微米传感器中Quad Bayer CFA去马赛克的高效深度神经网络架构。本文提供了有关ISP最先进挑战的准确背景和有用的Quad Bayer CFA分析,参考了相关的基于深度学习的解决方案。
所提出的体系结构由两个相连的特征图金字塔组成。其中一个由降阶块组成,另一个由升阶块组成,并结合密集的跳跃连接。除了受U-Net[85]启发的跳跃连接外,给定网络还应用了受ResNet[73]启发的残差学习。DPN还实现了线性特征映射增长。与传统的指数方法相比,这种线性方法导致的参数数量更少,对于内存限制有限的移动应用来说更精确。
在结果中,研究与三星手机中实现的传统ISP算法进行了比较,观察到清晰度,颜色纹理,边缘,纹理保存和视觉伪影减少方面的改进。与其他基于深度学习的方法相比,DPN在该框架参考下获得了更好的CPSNR值。由于所提出的网络架构的限制,输入图像的宽度和高度必须是2的倍数(L+1),其中“L”为分辨率级别。否则,必须在缩小块之前裁剪输入。此外,该研究可以用更大分辨率的图像进行测试,这些图像也可以在2019帧参考的手机中捕获,如全高清和4K图像。
3.10 CycleISP
Zamir[30]等人提出了CycleISP框架,该框架对相机成像管道进行建模,并在RAW和sRGB空间中生成逼真的图像对进行去噪。作者在合成数据上训练了一个新的图像去噪网络,并在真实的相机基准数据集上取得了最先进的性能。
CycleISP是两个阶段的组合。首先,该框架对相机ISP进行了正向和反向建模。其次,合成真实的噪声数据集,用于RAW和sRGB图像的去噪任务。CycleISP模型引入了RGB2RAW网络分支、RAW2RGB网络分支、辅助色彩校正网络分支和噪声注入模块。RGB2RAW和RAW2RGB模块独立训练,然后进行联合微调。
RGB2RAW分支将sRGB图像转换为RAW数据,不需要任何相机参数。该模块网络由卷积层、提出的递归残差群、双注意块和最终拜耳采样函数组成,生成拼接的RAW输出。RAW2RGB网络将清洁RAW图像映射为清洁sRGB图像。首先,将噪声注入模块设置为“OFF”,然后将2x2块封装为四个通道(RGGB)和图像分辨率降低块。为了保证输入的RAW数据可能来自任意摄像机,且具有不同的拜耳模式,RAW2RGB分支采用了拜耳模式统一技术[26]。接下来,使用卷积层和递归残差组将压缩后的RAW图像编码为深度特征张量。此外,作者提出了RAW2RGB网络的颜色校正分支,该分支接收sRGB图像输入并生成颜色编码的深度特征张量。
此外,还有一个联合微调,提供最佳质量的图像。为此,RGB2RAW的输出成为RAW2RGB的输入,RGB2RAW分支接收两个子损失的梯度,重建最终的sRGB图像。为了在RAW空间中合成真实的噪声图像对进行去噪,噪声注入模块打开“ON”,将不同级别的拍摄和读取噪声加入RGB2RAW的输出中。在此之后,CycleISP可以从任何sRGB图像中生成干净图像及其噪声图像对。对于sRGB空间,CycleISP模型使用SIDD[76]数据集进行微调,该数据集包含RAW和sRGB空间中的干净和噪声图像对。
在训练阶段,作者使用MIT-Adobe FiveK数据集[69],然后进行微调。他们使用DND[86]和SIDD[76]基准,用最先进的RAW和sRGB去噪方法评估了CycleISP的性能。CycleISP在这两种情况下都取得了更好的效果,其网络参数数量比之前最好的RAW去噪方法[58]少了近5倍,性能比之前最好的sRGB去噪算法[57]有所提高。此外,与其他评估模型相比,该方法提供了干净和无伪影的结果,并保留了图像细节。提出的框架模块得到了适当的描述,并通过消融研究得到了加强。作者提供了一个体面的实现细节部分,与相关方法进行了适当的比较,并进行了扎实的泛化能力研究。作为一个消极的方面,本文可以在消融研究中展示更多的细节,提供更多关于除了RAW2RGB分支之外的其他CycleISP模块的个人贡献的信息。
3.11 PyNET
PyNET[31]是一种新颖的金字塔形CNN架构,旨在取代智能手机中存在的整个ISP管道。该方法具有倒金字塔的形状,由五个不同的层次组成,从下到上依次训练,每个层次依次训练,训练后的输出用于上一层次的训练阶段。这种方法中的卷积滤波器大小从第5级的3x3到第1级的9x9不等。因此,较低层次学习全局图像处理,而较高层次学习重建最终图像,恢复较低层次缺失的细节。该网络使用三种不同的损失函数组合进行训练。用均方误差(MSE)训练最低的4级和5级,以学习全局颜色和亮度校正。第二级和第三级通过结合MSE和基于vgg的训练[87]来细化物体的颜色和形状。最后,第一级用MSE、VGG和SSIM损失进行训练[88],并在局部颜色处理、去噪、纹理增强等方面进行校正。
此外,作者还展示了苏黎世RAW到RGB数据集,该数据集由2万张RAW-RGB图像对组成,其中RAW图像使用华为P20智能手机拍摄,RGB图像使用专业高端佳能5D Mark IV相机拍摄。
为了验证该方法,进行了三个实验。首先,将PyNET与SPADE[89]、DPED[90]、U-Net[85]、Pix2Pix[91]、SRGAN[92]、VDSR[93]和SRCNN[94]等方法进行比较。在这个比较中,PyNET在PSNR和MS-SSIM度量值上优于所有其他方法。
第二个实验采用Amazon Mechanical Turk3平台测量生成图像的质量,将PyNET、Visualized RAW和华为P20 ISP的图像与佳能5D Mark IV数码单反相机生成的图像进行对比。在这个对比中,PyNET产生的图像达到了比目标单反相机更好的MOS效果。最后,在没有重新训练网络的情况下,使用黑莓KeyOne智能手机拍摄的RAW图像对PyNET进行了测试。将PyNET生成的图像与黑莓的ISP生成的图像进行比较,PyNET生成的结果很好,但是,在曝光和清晰度方面,结果并不理想。
3.12 SGNet
许多方法成功地结合了高度相关的任务,减少了ISP管道中多个进程单元的累积误差。因此,SGNet[33]在一个独特的网络中加入了去马赛克和去噪。
由于图像中高频区域的校正比较复杂,作者提出了提取代表图像区域频率的密度图。这种密度图可以帮助网络了解每个区域的难度水平,并且在高频区域比其他模型更好地适应。此外,一半的拜耳图案包含绿色像素;随后,从该通道中更容易恢复缺失的像素。因此,网络有一个分支来重建绿色通道,从而帮助重建其他通道。此外,SGNet在两个分支中使用残差密集块(RRDB)进行特征提取。此外,该网络在一组损失函数中进行训练,该损失函数考虑了绿色通道、完整图像、物体、纹理边缘和噪声去除的重建保真度。
在针对超分辨率、去噪和去马赛克任务的数据集中,SGNet在PSNR和SSIM方面优于最先进的方法。此外,与ADMN[59]、CDM[95]、Kokkinos[96]、deepjoin4[60]和FlexISP[97]相比,SGNet可以更有效地去除波纹伪像,并在高频区域给出比ADMN和Deepjoint更清晰的图像。然而,作为消极的一点,这项工作并没有显示出对计算效率的关注,这对于使用反马赛克和去噪的应用是必不可少的。
3.13 PatchNet and RestoreNet
在本文[34]中,作者提出了一种基于主动学习(数据驱动)的方法,该方法学习从图像中选择最合适的patch用于训练步骤,而不会给推理步骤增加额外的成本。为了做到这一点,该方法称为PatchNet,为每个补丁分配一个权重,以定义在训练期间是否使用或忽略它。该方法是一个多阶段前馈网络,每个阶段由几个卷积块和一个下采样算子组成。然后逐步将图像转换为一组可训练性标量,最后进行二值化以获得网络输出。
除了PatchNet之外,作者还提出了RestoreNet,这是一种应用从PatchNet中提取的结构知识来恢复原始图像的体系结构。在Vimeo-90k[98]、MIT Moire[60]和Urban 100[84]数据集上验证了结果,并与Kokkinos[96]、SGNet[33]、CDM[95]和DeepJDD4[60]方法进行了比较。在三种不同的噪声水平(5、15、25)下比较了这些方法。在所有的比较中,提出的方法在JDD任务中获得了更好的PSRN值。
消融研究分析了不同补片尺寸对PatchNet去马赛克性能的影响,结果表明,补片尺寸越大,补片性能越好。研究增加补丁大小所涉及的计算成本,以及这会在多大程度上改变网络的复杂性。
3.14 AWNet
在这项工作[35]中,研究人员提出了一种能够增强智能手机生成图像的方法,即用类似于CNN(卷积神经网络)的U-Net[85]取代基础ISP,称为AWNet。
网络被分成两个分支,每个分支使用不同的输入,因此有不同的模型。第一个分支使用RAW模型接收224 × 244 × 4张RAW图像,第二个分支使用去马赛克模型接收448 × 448 × 3张去马赛克图像。两个分支分别进行训练,并在测试过程中对结果进行平均。
该网络的结构遵循U-Net,对每个分支的输入应用三个主要模块:全局上下文密度、残差小波上采样和残差小波下采样。采用离散小波变换(DWT)后的低频分量提取采用resdense模块,将其送到下一层,而down-sampling则提取所有分量。提取后,每一层的两组分量都被上采样并与上一层连接。最后,应用金字塔池模块,生成该分支的输出。
对于测试阶段,应用了一个自集成机制,由8个集成变体组成。然后,使用PSNR (dB)值对这些变量进行评估,这些值将用作权重来生成模型的最终预测。RAW模型的PSNR为21.36 dB,去马赛克模型的PSNR为21.52 dB。通过将该调谐模型应用于AIM 2020智能手机ISP挑战赛[99]的苏黎世数据集的两条赛道,该研究分别达到了第5位和第2位。
利用这些结果作为使用小波变换和全局上下文块的理由,研究人员将AWNet的结果与使用ZRR数据集的其他流行网络架构(如U-Net、RCAN[67]和PyNet[31])进行了比较。通过比较它们的性能,研究人员发现AWNet能够优于U-Net, RCAN和当前最先进的PyNet。
3.15 PyNET-CA
PyNET-CA是一种端到端移动ISP深度学习算法,用于RAW到RGB重构[32]。
该网络通过增加通道关注和亚像素重构模块以及减少训练时间来提高PyNET[31]的性能。PyNET-CA具有考虑图像局部和全局特征的可逆金字塔结构。PyNET-CA的基本模块是基于[67]的通道注意模块、DoubleConv模块和MultiConv通道注意模块,前者具有两个2D卷积操作和LeakyReLU激活,而前者将DoubleConv模块和通道注意模块的特征连接起来。
超像素重建模块帮助网络以更高的质量和计算效率重建最终图像。为此,PyNET-CA使用MultiConv通道注意力模块对图像进行上采样,然后使用1×1卷积层,并在模型的最后一级通过亚像素变换对特征进行上采样。结果显示在Zurich Dataset[31]上,与PyNET[31]相比,它显示出更好的PSNR和SSIM值。本文没有给出网络参数的数量,尽管作者引用了训练时间的减少,但没有给出将这些结果与PyNET[31]进行比较的表格。
3.16 Del-Net
Del-Net[36]是一种单阶段端到端深度学习模型,它学习整个ISP管道,将RAW拜耳数据转换为高质量的srgb图像。该网络使用空间和通道注意块(改进的UNet)[100]和增强注意模块块[57]的组合。空间和通道注意块允许网络在空间和通道上捕捉全局细节,因此有助于色彩增强。增强注意模块块有助于去噪,从而提高PSNR值。考虑到颜色增强、去噪和细节保留能力,Del-Net生成的图像在视觉上可与最先进的网络(PyNET[31]、AWNet[35]和MW-ISPNet[99])相媲美,同时减少了multi - add(图像的复合乘法-累积操作次数)。总之,这使得该网络成为智能手机部署的理想选择。它还需要在准确性度量和复杂性之间进行权衡。结果显示在Zurich Dataset[31]上,与PyNET[31]相比,它表现出更好的细节保留,与MW-ISPNet ignatov2020aim相比,它表现出更好的去噪,与AWNet[35]相比,它表现出更好的颜色增强。虽然Del-Net的细节恢复能力不如MW-ISPNet[99]。
3.17 InvISP
InvISP[37]重新设计了ISP管道,允许在没有任何内存开销的情况下重建几乎与相机RAW图像相同的RAW图像,并且还像传统一样生成令人愉悦的sRGB图像,该方法通过对RGB图像进行逆压缩来实现RAW图像的重构。为了实现这一目标,作者设计了一个由一堆仿射耦合层和一个可逆1x1卷积组成的可逆神经网络的raw到rgb和rgb到raw映射。此外,该模型还集成了一个可微JPEG压缩模拟器,通过傅里叶级数展开,可以从JPEG图像中重建出近乎完美的RAW图像。双向训练网络,共同优化RGB和RAW重建过程。对来自MIT-Adobe FiveK数据集的佳能EOS 5D子集和尼康D700子集进行模型评估[69]。为了从RAW图像中渲染sRGB图像的真实性,使用了LibRAW库,该库允许模拟ISP管道的步骤。实验表明,与RAW合成方法UPI[58]和CycleISP[30]相比,PSNR有所提高,这意味着可以更准确地检索RAW图像。将该方法与可逆灰度[101]和U-net[71]基线进行比较,结果显示PSNR和SSIM值更好,表明该模型对RAW图像检索和RGB图像生成具有更强的鲁棒性。
3.18 ICDC-Net
在本文中,作者提出了一种解决网络训练中JPEG图像压缩问题的ISP-Net[38],我们在这里称之为ICDC-Net。图像可能在压缩过程中丢失信息,这一事实在以前的卷积神经网络的ISP管道中没有得到解决。为此,作者应用了全卷积压缩伪影仿真网络(CAS-Net)。
该网络可以将JPEG压缩伪影添加到图像中,并且通过对训练压缩伪影减少网络所需的输入和输出进行反向训练。在这项工作中,作者将CAS-Net连接到一个ISP网络,因此ISP网络可以在考虑图像压缩的情况下进行训练,并考虑压缩伪影。本研究使用的ISP-Net为带信道注意模块的U-Net [102], CAS-Net的架构为不带信道注意模块的U-Net[85]。
结果出现在来自MIT-Adobe FiveK数据集的尼康D700子集上[69]。为了从RAW图像中渲染sRGB图像的地面真值,我们使用了LibRaw库。采用80和90两个不同的qf对sRGB图像进行压缩,每个模型分别进行训练。实验结果表明,与压缩无关的网络相比,该网络可以产生更好的图像质量。
3.19 CSANet
作为移动AI 2021学习智能手机ISP挑战赛的第二名[39]和PSNR得分的第一名,信道空间注意网络(CSANet)[103]是一个旨在计算性能和最终图像结果质量的网络,每张图像最多推断90.8 ms。该网络有三个主要部分:低规模、级联处理区块和高档。在第一部分中,为了减少计算时间和参数数量,作者在常规卷积之后使用跨步卷积块进行了降尺度的特征提取。随后,该网络有一个双注意模块(DAM),其灵感来自卷积块注意模块(CBAM)[104]。该DAM包括空间注意模块,用于学习特征映射中的空间依赖关系;通道注意模块,用于学习特征映射的通道间关系。并在最后一部分进行卷积转置和深度空间升级到最终的RGB图像。这项工作的另一个重要部分是由Charbonnier loss[67]、SSIM loss和Perceptual loss组成的损失函数,以减少生成的图像与真值之间的感知差异。
在移动AI 2021学习智能手机ISP挑战赛验证数据集的定量指标中,CSANet优于该挑战赛的基准模型PUNet,并且运行时间更短。此外,它的结果与在AIM 2020中获得高分的网络AWNet[35]相当,并且推理时间更好。与其他参赛作品相比,该作品以令人满意的运行时间和最高质量分数排名第二。正如在智能手机上的测试所显示的那样,CSANet可以用于嵌入式系统。此外,正如预期的那样,注意模块的使用有助于更好地进行颜色映射。
3.20 LiteISPNet
在一些数据集中,RAW和RGB图像是用不同的相机拍摄的。因此,图像对存在不对齐和颜色不一致的问题,给训练和制作带来了困难模糊的结果。针对这一问题,Zhang等人[40]提出了一种训练带有不对齐图像的网络并将RAW映射到RGB的方法。作者使用预训练的光流估计网络PWC-Net[105]对图像对进行对齐,并设计了一个全局颜色映射(global color mapping, GCM)来匹配输入和目标图像之间的颜色,以方便对齐。此外,LiteISPNet负责将raw映射到rgb。它简化了MW-ISPNet[99],提出了一种基于U-Net的多级小波ISP网络,减少了每个残差组中RCAB的数量,改变了每个小波分解前卷积层和残差组的位置。这些变化分别减少了大约40%和20%的模型大小和运行时间。
在两个数据集,作者测试了网络ZRR数据集[31],和SR-RAW[106],有两个变种的真相:原来的GT和GT一致。ZRR数据集,LiteISPNet与三个(PyNet [31], AWNet[35],和MW-ISPNet)和超过所有指标一致GT但有点比MW-ISPNet SSIM指标原始GT。此外,这个模型获得更好的感知结果LPIPS度量[107]。最后,在定性比较中,该网络比其他模型保留了更多的细节。使用SR- raw数据集,作者还与SR方法进行了比较,如SRGAN[92]、ESRGAN[108]、SPSR[109]和RealSR[110]。它生成的图像噪声更小,模糊更少,细节更多,并且在几乎所有指标上都有更好的得分,只有原始GT的PSNR指标有损失,这有利于模糊图像。
3.21 TENet
通常,ISP管道是由三个核心组件按固定顺序组成的操作序列:去马赛克、去噪和超分辨率。然而,Qian等[41]通过大量的实验表明,对操作顺序进行简单的重新排序可以提高图像质量。然后,作者创建了三位一体增强网络(TENet),该网络将操作顺序重新排序为去噪(DN),超分辨率(SR)和去马赛克(DM)。DN块是第一个,因为RAW图像上的噪声具有高斯-泊松分布[111],然后更直接地解决;RAW图像的噪声会阻碍后续的任务;此外,这种噪声在图像处理操作中变得复杂。此外,高分辨率图像中的DM产生的伪影较少,而超分辨率算法可以放大DM产生的伪影。因此,SR是该体系结构中的第二个块。
DN产生模糊的形象,作者加入了DN和老在一块独特的消除积累误差图像操作,导致最后管道:DN + SR - > DM。在考虑这两个阶段有效地利用,损失函数是由两个损失:Ljoint,即l2-norm损失最终的输出图像,l2-norm损失DN + SR结果和高分辨率之间的无噪声的马赛克图像输入图像。因此,最后的损失是这两个损失的总和。此外,作者使用残差稠密块(RRDB)[108]构造所有块的中心部分。
他们还注意到,以前合成DM的数据集是次优的,原因有三个:1)用于合成RAW图像的图像是由相机ISP插值的结果;2)对模型进行训练,学习一种用于摄像机ISP的平均DM算法;3)合成的RAW图像比真实的RAW图像信息量少。出于这个原因,PixelShift200数据集citeqian2021rethinking是用200张2k分辨率的全彩色采样图像创建的。由于像素移位技术,图像的每个像素都是彩色信息,没有去马赛克。此外,通过双三次下采样核[94]、镶嵌核[58]以及加入高斯-泊松噪声模型[111],从这些高分辨率RAW图像中生成低分辨率RAW图像。
将该模型与ADMM[59]、Condat[112]、Flex-ISP[97]和DemosaicNet4[60]在Urban 100[84]、Kodak、McMaster[83]和BSD100[113]等常用基准数据集上进行去噪和去噪任务的比较。TENet在定性指标上优于这些模型,因此产生更少的波纹、颜色伪像和更细粒度的纹理。该网络生成的干净图像具有精确的细节,并在数据集中添加高斯白噪声,其中ADMM和DemosaicNet生成平滑的结果,FlexISP不能正确处理噪声,ADMM生成颜色混混伪像。
总之,这项工作在ISP和SR问题上优于最先进的模型,此外还提供了一种新的方法来训练具有不对准数据集的DNN模型。此外,这种新方法实现了轻量级网络,例如在工作中使用的网络,并且生成的结果接近或高于更健壮的模型。然而,作者没有在嵌入式系统中测试该模型。
3.22 ReconfigISP
ReconfigISP[42]是一种可重构的ISP,其架构和参数根据特定的任务进行调整。为了实现这一目标,作者实现了几个ISP模块,并给定特定任务,通过自动调整数百个参数来配置最佳管道。该方法保持了图像重建过程中步骤的模块化,其中每个模块在ISP管道中发挥明确的作用,并通过训练一个可微代理来允许每个模块的反向传播。可微代理旨在通过卷积神经网络模拟不可微模块,从而允许优化模块的参数。因此,使用神经结构搜索来探索ISP体系结构,其中模块接收体系结构权重,如果权重低于预设阈值,则将其删除。这也降低了计算复杂度,加快了训练过程。该网络中的损失函数是根据需要的具体任务来选择的。
为了验证该建议的有效性,作者在不同的传感器、光照条件和效率约束下进行了图像恢复和目标检测实验。在SID数据集[71]和S7 ISP数据集[70]上验证了结果,表明该网络优于传统的ISP管道,实现了比Camera ISP更高的PSNR值。与U-Net相比[71],该方法在训练中patch数量较少的数据中获得了更好的PSNR值,但在大规模数据中获得了更低的PSNR值。
3.23 ISP蒸馏
在ISP Distillation[43]中,作者提出了一种使用sRGB图像分类模型和ISP管道的Knowledge Distillation[114]对RAW图像进行图像分类的模型,以降低传统ISP的计算成本。传统的ISP管道主要针对人类视觉,而本文仅针对机器视觉提供了解决方案。因此,作者将视觉模型直接应用于RAW数据。使用RAW和RGB对的数据集来克服直接在RAW图像上训练数据时出现的性能下降。该数据集用于预训练模型,该模型随后被提取到负责直接处理原始数据的另一个模型。
为了验证该建议,测试了两个案例。第一种方法是在ImageNet数据集上预训练的模型上放弃去噪和去马赛克预处理[115]。第二种方法是在HDR+数据集上预训练的模型中丢弃整个ISP管道[68]。
使用ResNet18[73]和MobileNetV2[116]进行验证。两个实验都显示了在前1和前5指标上的良好性能。因此,与RGB相比,ISP蒸馏是在RAW图像上实现类似分类性能的一个步骤。虽然文中提到ISP蒸馏节省了ISP的计算成本,但文中并没有给出计算成本。
3.24 Merging-ISP
merge - isp[44]由一个深度神经网络组成,负责在一个图像HDR(高动态范围)中重建多个图像层LDR(低动态范围)。因此,输入数据包含动态或静态场景中的RAW图像,网络将它们映射并在一个出口HDR中卷积所有层。在卷积之前,DnCNN[117]概念应用了一个5x5大小和64层的滤波器,然后应用了两个5x5大小和64层的滤波器,最后应用了三个1x1大小和激活sigmoid的滤波器。在得到的输出中,数据量减少,而不使用另一个受训者,LDR合并在一个HDR中,包括四个卷积层。merge - isp: Multi-Exposure High Dynamic Range Image Signal Processing 7,第一层100个滤波器的接收域从7 × 7减少到最后一层3个滤波器的接收域为1 × 1。请注意,没有必要对输入数据应用光流。
为了训练网络,我们使用了基于Kalantari[118]数据集的合成数据集和真实数据集。数据包含动态和静态场景,如前所述。其次,利用旋转技术增加数据集,以50步长提取21万个大小为50 × 50像素的非重叠斑块;此外,他们进行了超过70次的训练,恒定的学习率为10e−4,批次大小为32。在每个epoch期间,所有批都随机洗牌。与其他isp合并方法相比,该方法在PSNR、SSIM和HDR-VDP-2参数上取得了最好的结果。
3.25 GCP-Net
Guo等[45]研究了一种基于cnn的真实图像去噪和去马赛克联合方法。针对该任务,由于绿色通道比CFA RAW数据中的红色和蓝色通道具有两倍的采样率和更好的质量,因此作者提出了一种绿色通道先验神经网络- GCP Net。该模型从绿色通道中提取GCP特征进行深度特征建模,对图像进行上采样,评估帧偏移量,消除噪声影响。给定的工作还寻求了逼真的噪声模型[119],[58],以及一组突发图像而不是单个CFA图像。
GCP- net结构由两个分支组成——GCP分支和重构分支。
GCP分支通过使用多个卷积和LReLu块[120],从有噪声的绿色通道拼接中提取绿色特征及其噪声级图。
重建分支估计出干净的全彩图像。该分支由帧内模块(IntraF)、帧间模块(InterF)和合并模块组成,利用突发图像、噪声图和GCP特征作为引导信息。intrf块对每帧的深度特征建模,并使用GCP特征指导特征提取。InterF在特征域中使用可变形卷积[121]来弥补帧之间的移位。像EDVR[122]和RViDeNet[123]一样,采用锥体处理来处理可能的大运动。此外,InterF在偏移估计中包含LSTM正则化,提供时间约束。合并模块为全分辨率图像重建提供自适应上采样。
该研究使用Vimeo-90k开放高质量视频数据集合成训练数据[98]。训练持续了两天,使用PyTorch框架和两个Nvidia GeForce RTX 2080 Ti GPU。作者使用Vid64[124]和REDS4[122]数据集进行消融实验。
在对比实验中,作者在合成数据和实际数据上对所提出的模型进行了测试。在这两种情况下,GCP-Net在定量和定性上都优于其他最先进的Join去噪-去马赛克算法,如FlexISP[97]和ADMM[59]。本文进行了完整的介绍和相关工作说明。还有一个适当而详细的实验部分,包括关于训练参数的细节。消融研究证实了主要GCP-Net成分的有效性。所选择的比较数据集增强了所提出的模型值,特别是在实际数据验证中。
3.26 PIPNet
在本文[46]中,作者提出了一种深度网络,用于Quad Bayer CFA和Bayer CFA模式的联合去马赛克和去噪。所提出的网络使用注意机制,并以目标函数为导向,包括感知损失,以在像素-bin图像传感器上产生愉悦图像。该网络被定义为像素-bin图像处理网络(PIPNet),使用UNet作为框架,并通过降尺度和升尺度操作遍历不同的特征深度,以利用所使用的架构。作者还扩展了该方法,以重建和增强用智能手机相机捕获的感知图像。
结果在MSR去噪数据集[125]、BSD100[113]、McMaster[83]、Urban 100[84]、Kodak[82]和WED[126]数据集上进行了验证,并在三种不同噪声水平(5,15,25)下与deepjoin4[60]、Kokkinos[96]、Dong[127]、DeepISP[70]和DPN[29]方法进行了比较。在所有比较中,PIPNet在PSNR、SSIM和DeltaE2000指标上表现更好。在质量上,该方法也优于其他方法。然而,该网络仅使用传统拜耳传感器收集的数据进行测试,这可能会影响网络在其他场景下的性能。
3.27 CURL
在本文[47]中,作者提出了一种基于全局图像调整曲线的图像增强方法,该方法受到进行图像修图的摄影师的启发。可以使用这种称为CURL的方法在两种不同的情况下。第一种是RGB到RGB的映射,其中输入的RGB图像被映射到另一个视觉上令人愉悦的RGB图像,第二种场景是raw到RGB的映射,其中整个ISP管道都完成了。
该方法由转换编码器-解码器(TED)主干和CURL块两种体系结构组成。TED类似于U-Net[85],但没有跳过连接,除了1级跳过连接被多尺度神经处理块所取代,该神经处理块通过对CURL块的局部像素处理提供增强图像。CURL块是一个神经曲线层块,它利用图像在三种颜色空间(CIELab, HSV, RGB)中的表示,意图通过新的多色空间损失函数指导下的颜色,亮度和饱和度调整来全局细化其属性。CURL损失函数旨在优化最终图像的不同属性,如色度、色调、亮度和饱和度。
为了验证该方法,我们进行了两个实验,其中评估了中至中等曝光RAW对RGB映射的影响,以及预测摄影师对RGB到RGB映射的修图效果。首先,在三星S7数据集上验证了结果[70],与U-Net[85]和DeepISP[70]方法相比,CURL获得了最佳的PSNR和LPIPS指标,但在SSIM指标上与DeepISP方法并列。第二,在MIT-Adobe FiveK数据集上验证结果[69],并与HDRNet[128]、DPE[129]、White-Box[130]、distortion -and- recover[131]和DeepUPE[132]方法进行比较,其中CURL在PSNR和LPIPS指标上得分更高,但DeepUPE在SSIM上得分最高。定性卷曲产生的图像非常愉快的人眼。
4 Methodology
本节描述了我们如何在本调查所涵盖的作品之间进行定性比较,并对这些论文进行分析,以突出改进的地方、亮点和发展这一研究领域的方法
4.1数据集
为了进行定量评估,我们将本调查所涵盖的作品与更多探索的数据集进行了比较。为此,我们使用这些作品提供的结果和图像恢复任务中最常用的指标PSRN和SSIM作为比较的基础。我们对我们分析的研究中每个最常用的数据集进行了简要讨论。表2给出了本节讨论的所有数据集的列表,详细说明了图像的数量、大小和下载链接。
4.1.1 Zurich RAW to RGB (ZRR)
ZRR数据集由Ignatov等人[133]提出,目的是获得大规模的真实世界数据集,该数据集处理的任务是将智能手机相机拍摄的原始RAW照片转换为专业单反相机拍摄的高质量图像。拟议中的数据库是公开的,总计22gb,包含由佳能5D Mark IV数码单反相机和华为P20手机在不同地点、不同照明和天气条件下同步拍摄的20K真实图像。这些照片是在自动模式下拍摄的,但是有些RAW-RGB图像对并不完全对齐,这需要预处理和匹配。ZRR是本调查中考虑的一些RAW到RGB映射问题作品的数据集选择[22,36,31,40,35,32]。
4.1.2 Urban 100
Urban 100数据集由100张高分辨率图像组成,其中包含各种现实世界的城市场景和结构。它是由Huang等人[84]提出的,以解决室内、城市和建筑场景缺乏高分辨率数据集的问题。Urban 100使用来自Flickr5的合成图像构建,在知识共享许可下,产生1.14 GB的数据集。它是一个著名的超分辨率任务公共数据库[29,28,34,46,33,29]。
4.1.3 McMaster数据集
McMaster数据集由Zhang等人[83]提出,由18张尺寸为500x500的柯达胶片拍摄的子图像组成,然后进行数字化。子图像是从8张高分辨率自然图像中裁剪而来,尺寸为2310x1814。当与柯达彩色图像数据集进行比较时,显示的图像颜色更饱和,图像对象之间的颜色过渡也更多。然而,该数据集在场景变化和颜色渐变方面仍然有限。在本调查的一些文章中,McMaster数据集被用于颜色去马赛克[46,28,29,24,41]。
4.1.4 Kodak
Kodak 6是一个小型数据集,由24张768x512或512x768尺寸的摄影质量图像组成,具有各种各样的位置和照明条件。最初,它是一个柯达照片CD样本,其中一些图像是由柯达的专业摄影师拍摄的,还有一些是从柯达国际报纸快照奖(KINSA)的获奖者中挑选出来的。该数据集包含照片-cd (PCD)格式和PNG格式的原始图像,每像素24位。此外,许多工作使用柯达数据集进行压缩测试,并验证执行诸如去马赛克、去噪和全ISP管道等任务的方法[46,28,24,29,41]。
4.2论文分析
对某些研究领域的作品进行分析,是发现今后作品发展和完善的新途径的基础。在这次调查中,对论文进行了以下几点分析:
•方法的细节:对许多方法的细节分析可以带来新的想法,并识别出未来作品可以提出解决的问题。
•使用的数据集:相机硬件有许多细微差别,并产生自己的噪声,很难模拟。然后,使用合适的数据集来训练和验证工作是创建新的ISP方法要考虑的重要部分。
•对计算成本的关注:在几乎所有的ISP应用中,计算成本都是一个重要的考虑点,主要用于嵌入式系统和移动设备。
•方法评估:如何评估方法可以很好地计划,以表明这项工作在确定的研究领域的贡献。
5结果
在本节中,我们对定量比较的工作进行了分析,并指出了一种方法比其他方法更好的可能原因。我们将本节分为四个小节,每个小节讨论在数据集中获得的结果。首先,我们讨论了 Zurich RAW到RGB数据集,该数据集包含来自不同区域的图像对和对之间的不对齐。其次,我们讨论了Urban 100数据集,该数据集由100张具有真实城市场景和结构的高分辨率图像组成。然后,按照顺序,我们讨论了 McMaster 数据集中的作品,其中捕获了18幅图像,在第四部分中,我们讨论了柯达数据集,其中包含24张大小为768x512或512x768的摄影质量图像,通常用于压缩测试,并验证诸如去马赛克和去噪等任务的方法。
5.1 Zurich RAW to RGB
HERNet和LiteISPNet提供的版本在表3中有更好的结果,但它们分别使用了不同的数据分布和与真实情况一致的RAW图像。在剩余的结果中,AWNet在PSNR和SSIM分数上优于其他方法,使用自集成策略可以解释这一点,因为RAW和Demosaiced版本的分数相对低于集成版本。此外,AWNet RAW版本的结果略高于LiteISPNet和PyNet-CA,这可能是小波变换和上下文全局块的结果。此外,LiteISPNet引入了一种额外的方法来对齐图像,改善了网络训练,取得了令人印象深刻的结果。
5.2 Urban 100
Urban 100数据集用于许多图像恢复任务。然后,工作人员对该数据集进行修改,以满足特定的任务。如表4所示,与其他方法相比,RLDD的得分最高,但它是在去除图像边界的情况下进行验证的,这个因素可以帮助提高得分。此外,即使在有噪声的数据中进行验证,PIPNet也具有与DPN相当的结果。注意机制的引入带来了与深度和空间维度的良好相关性,这可能是本数据集中这些有希望的结果的原因。
5.3 McMaster
DRDN+和DRDN方法在表5的PSNR指标中显示出更好的结果。这些方法都是基于cnn的模型,专注于去马赛克。DPN方法同样注重去马赛克,在SSIM度量中显示出更好的结果,在定性评估中显示出更好的伪影减少。TENet网络在PSNR和SSIM指标上的性能最低,然而,值得注意的是,该网络的目标是使整个ISP管道增强,而不仅仅是去马赛克任务。
5.4 Kodak
表6显示了柯达数据集中审阅的论文结果。RLDD[28]具有最佳的PSNR度量性能,而DRDN+[24]具有最佳的SSIM度量性能。RLDD框架结合了去噪和去马赛克技术,提供了适当的定量和定性结果。需要强调的是,RLDD作者从柯达图像的边界中去掉了10个像素来计算PSNR。TENet和PIPNet在数据集中引入了人工噪声模型,进行更深层次的去噪研究。DRDN在效率和准确性方面脱颖而出,很大程度上是因为它的块卷积神经网络考虑了局部特征和亚像素插值层。
5.5源代码链接
表7给出了本调查中提到的一些作品的源代码链接
6讨论
在本节中,我们提供了这些作品在方法论和评价方面的改进点。然而,它有很多亮点,可以为学习相机isp提供很多帮助。本节将讨论上述作品的消极和积极之处,并提出一些问题,这些问题可能会演变成该研究领域的新途径。
6.1不同摄像机创建的数据集
一些数据集[31,39]具有由不同相机捕获的成对图像,其中使用这些数据集的工作的主要目标之一是学习高质量相机的特征,并将其应用于具有更多限制的相机。由于设备之间的差异,这些数据集具有一致性关于图像补丁对的问题。做RAW到RGB映射可能是具有挑战性的,因为补丁像素不对应于它们的像素。简单的解决方案是对齐成对,但如何做到这一点是主要问题。Zhang等人[40]提出使用深度学习,其性能优于使用偏差数据集训练的模型。许多作品[39,35,31,36]用来缓解这个问题的另一种方法是调整损失函数,使其不惩罚生成的图像与真实情况不一致的模型。用损失训练的模型试图更接近人类感知,对不对齐更不敏感,并生成具有更多细节的图像。目前,最接近这一点的指标使用深度学习技术,使用预训练的深度学习模型使用提取的图像特征[107,134]。这样就产生了一个疑问,即如何在不增加训练过程的计算成本的情况下,使用最佳的失调解决方案来缓解问题。这个问题本身可以成为一个搜索点,例如对不同相机的RAW和RGB图像的对齐方法,便于创建新的数据集,提高新作品的性能。
6.2方法
从架构构建到工作验证或数据集的选择,每个阶段的论证都有助于分享知识和研究领域的发展。然而,有些作品没有做到这一点。例如,Liu等人[33]并没有很好地解释为什么使用一些数据集,Liu等人[26]并没有表明使用U-Net模型的动机。此外,许多方法在其论文中没有提供源代码[22,24,23,3,25,28],这使得未来的验证和与其他方法的比较变得困难,从而降低了验证的可靠性。
6.3评估协议
当数据集中缺少RAW和RGB图像时,使用合成的RAW图像数据训练模型是提高泛化的好方法。然而,这并不是验证所提出的映射ISP方法的一个很好的选择,因为合成的RAW图像数据是由RGB处理图像的插值结果,其像素信息较少,并且由此产生的相机硬件噪声复杂且难以生成。
然而,许多作品使用为去噪、去模糊或超分辨率等任务创建的数据集,并从这些数据集生成RAW图像,这些数据集不相信这些方法在现实世界中的适用性。这个问题提出了如何创建具有良好表征和高质量的RAW到RGB数据集以供进一步研究的问题。
另一方面,很少有作品在嵌入式系统或移动设备中测试模型。这可能是一个问题,因为大多数isp的应用都是在计算能力较低的设备中,这样的验证错误并不能证明在实际应用中的可能使用。鉴于此,移动2021挑战赛发布了“在移动npu上使用深度学习学习智能手机ISP”的任务。[39]它考虑了移动npu中的处理和执行时间,以及像前两个挑战一样的图像质量。这一建议可以鼓励未来的作品更多地关注这些问题。
7结论
ISP管道是一种重要的技术组合,对于从相机传感器创建高质量的数字图像至关重要。本调查对深度学习技术在ISP任务中的应用进行了深入研究,包括网络在解决部分步骤或完整管道中的应用。此外,它还提供了对ISP和深度学习领域的介绍,以及对软件ISP的详细概述,包括其基本原理和各个步骤。
本文所调查的作品是根据其新颖性,目标任务和应用的深度学习技术进行选择的。在27篇被评审的论文中,30%的论文采用dnn替代完整的ISP管道。这揭示了一个新的趋势,即探索cnn学习所有ISP单个任务的泛化能力,旨在将所有任务应用于单个前向操作中。
此外,本工作还总结了五个经常用于ISP任务的数据集:Urban 100[84]、ZRR数据集[133]、Kodak8和McMaster数据集[83]。高质量数据集的可用性对于任何深度学习应用领域的新解决方案的研究和开发都是必要的。在这种情况下,新的与isp相关的数据集可以改善调查数据集存在的一些局限性。
最后,在本次调查的发展过程中,我们发现了一些关键点,并将其强调如下:
•使用不同的相机生成RAW-to-RGB数据集会产生对齐问题,需要在dnn训练期间应用额外的技术。这些缓解器会增加计算成本,并干扰网络的整体性能。
•更好的消融研究,考虑到提出的解决方案中存在的每个架构组件的影响,以及源代码的分发,可以促进新技术的未来发展和研究领域的整体改进。
•随着越来越多的方法被提出到ISP管道替换任务中,一个更加一致的评估程序,以及共同目标数据集的定义,将促进方法之间的比较,帮助定义最先进的性能。
•除了作为主要目标应用程序之一之外,取代完整ISP管道的网络移动应用程序很少被讨论。对提议的方法在边缘设备上的性能进行更深入的评估,对于确定可以优化的组件或针对这些目标环境的新技术非常重要。
作为未来的工作,我们打算采用两种主要方法来实现基于深度学习的ISP应用:
•开发一个完整的ISP管道网络,专注于在树莓派板上执行,旨在探索边缘部署的挑战。
•视觉变压器在完整ISP任务中的应用,旨在探索变压器在其他计算机视觉任务中取得的良好效果。









