ITFormer团队 投稿
量子位 | 公众号 QbitAI
时序数据分析在工业监控、医疗诊断等领域至关重要。
比如航空发动机监控这个复杂工业场景中,工程师需分析海量多通道传感器数据,以判断设备状态并制定维护决策。
然而,现有研究多聚焦于分类、预测等单一任务,与实际工业场景中专家通过自然语言进行复杂交互和决策的需求存在显著差异。
上海交通大学航空航天学院李元祥教授团队、上海创智学院、复旦大学数据科学学院团队以航空发动机运维为背景,提出高效、可迁移的时序-语言桥接架构——ITFormer,将专家诊断过程抽象为”理解、感知、推理、决策”四个认知层次,并首次系统性地定义为“时序问答”任务范式。
团队基于NASA航空发动机数据,构建了包含11万余问答对的EngineMT-QA数据集。该数据集的任务设计紧密贴合专家的认知流程,为评估模型在真实工业场景下的推理能力提供了首个标准化基准。
结果显示,ITFormer以模块化设计实现了时序数据与大语言模型的高效融合,仅需训练不足1%的额外参数,便可在通用时序问答数据集上表现出优越的性能和良好的迁移能力,展现了卓越的“即插即用”特性。它可无缝适配PatchTST、Informer、Crossformer等多种时序编码器,以及Qwen、LLaMA、GLM等不同规模和架构的大语言模型。
此外,在使用EngineMT-QA进行预训练后,ITFormer的性能得到进一步的巨大提升,在全部五项任务上均达到SOTA水平,其中“因果分析”准确率高达0.83
。用户可以进行追问式探索,“昨天哪个设备的能耗最高?” “为什么它的能耗这么高?” “和上周同期相比情况如何?”。这种交互式的分析流程,让数据探索过程更符合人类的思维习惯,从而真正实现了数据分析的大众化。航空发动机能用大模型了
技术难点
高维数据的语义提取:单个时序样本可包含数万个数值(如32通道×600时间步),如何从中提取出有效的语义特征是首要难题。
抽象语义的对齐建模:时序信号的模式变化(如缓慢上升、突然波动)与物理系统的状态转换(如设备老化、突发故障)之间的对应关系高度抽象,难以直接建模。
多尺度时间依赖的处理:时序数据中的关键信息可能分布在不同的时间尺度上,模型必须具备处理多尺度依赖的能力。
ITFormer架构与关键模块
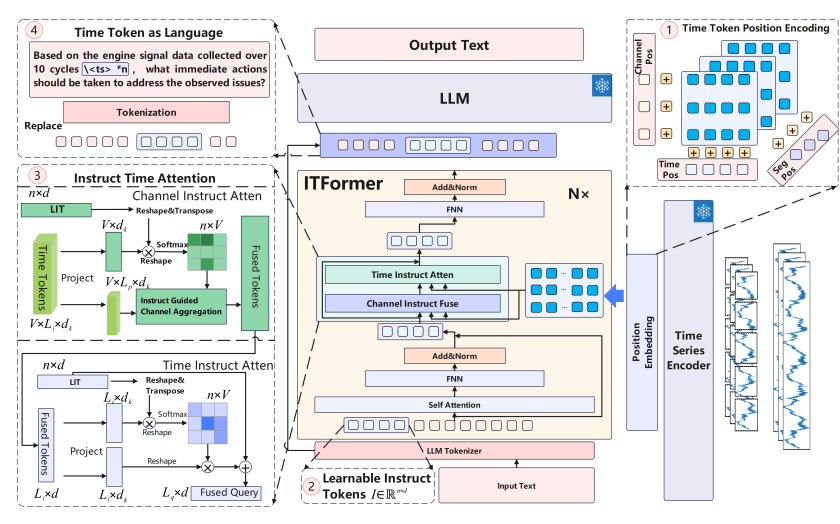
ITFormer的设计思想是作为一个轻量级的”桥梁”,在冻结预训练时序编码器和大型语言模型(LLM)的前提下,实现两者的高效对齐与融合。
时间令牌位置编码(TPE)
为精确表征多维时序数据的结构,TPE在三个层次上进行位置编码:时间步(Temporal Steps)、通道(Channels)和时序片段(Segments),确保模型能区分不同时间点、不同传感器以及不同数据段的语义信息。
可学习指令令牌(LIT)
为了让模型理解具体的任务指令,LIT在文本查询前添加了一组可学习的令牌。这些令牌通过自注意力机制,能够从自然语言查询中自动捕获并浓缩任务相关的语义信息,从而指导后续的跨模态融合。
指令时间注意力(ITA)
作为ITFormer的核心创新,ITA通过一个高效的两阶段过程实现跨模态对齐:
- 通道指令融合(Channel Instruct Fusing):根据LIT提供的任务指令,动态地对每个时间步上的多通道特征进行加权聚合,筛选出与任务最相关的传感器信息。
- 时间指令注意力(Time Instruct Attention):在上一步的基础上,再次根据任务指令,在时间维度上进行注意力加权,聚合最关键的时间片段信息。
这一设计显著提升了计算效率,同时保证了对齐的精确性。
时间令牌即语言(TAL)
该策略将ITA融合后的时序特征向量直接视为语言令牌,并替换掉文本查询中预设的占位符。这使得时序信息能以一种与语言模型兼容的方式,无缝嵌入到LLM的输入序列中,从而实现端到端的建模。
EngineMT-QA数据集设计
EngineMT-QA基于真实的工业应用场景设计,其任务层次反映了专家处理时序数据的认知过程。
数据规模:包含超过11万对高质量问答数据,源于NASA N-CMAPSS标准数据集。
数据维度:覆盖32个传感器通道,每个样本包含600个时间步。
质量保证:所有数据均经过领域专家的交叉审核,确保技术准确性。
适配主流LLMs,性能实现SOTA
EngineMT-QA数据集上的性能对比
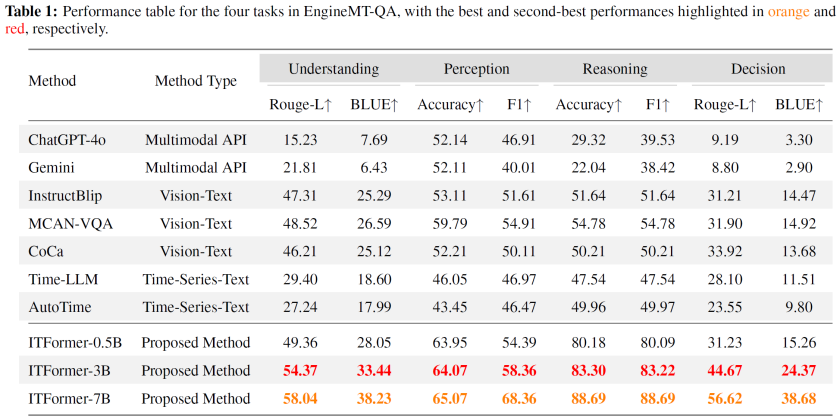
在EngineMT-QA数据集上,ITFormer的性能全面超越了包括主流多模态API,如ChatGPT-4o、Gemini,以及专用时序-文本模型Time-LLM、AutoTime在内的所有基线。尤其在需要深度分析的“推理”和“决策”任务上,F1分数和BLEU得分的显著领先,证明了ITFormer对复杂时序-语言关系具备强大的建模能力。
ITFormer模块有效性验证:消融实验
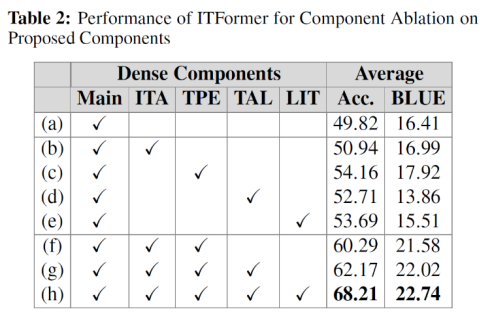
消融实验结果量化了ITFormer各核心组件的贡献。实验表明:TPE(时间令牌位置编码) 对模型性能的提升最为关键,是模型理解多维时序结构的基础。同时,ITA(指令时间注意力) 与TPE的结合能够产生显著的协同效应。最终,包含全部组件的完整架构性能最佳,验证了ITFormer系统性设计的有效性。
架构通用性:适配不同时序编码器与语言模型
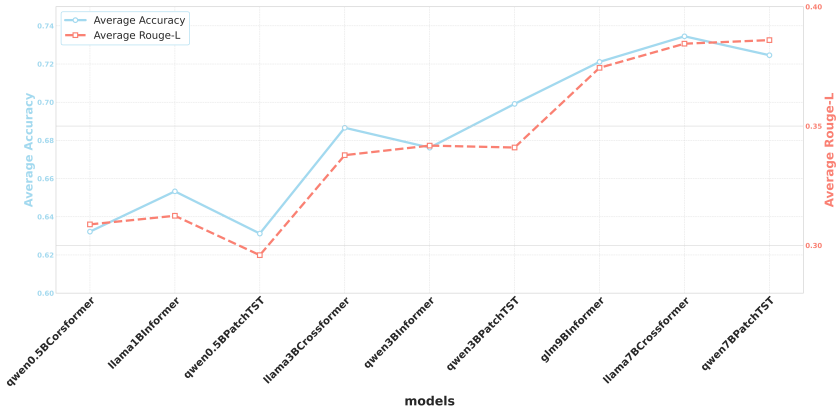
ITFormer展现了卓越的“即插即用”特性。实验证明,它可无缝适配PatchTST、Informer、Crossformer等多种时序编码器,以及Qwen、LLaMA、GLM等不同规模和架构的大语言模型。此外,随着底层语言模型规模的提升,整体任务性能也随之稳步提高,表现出良好的可扩展性。
跨域泛化与数据集价值
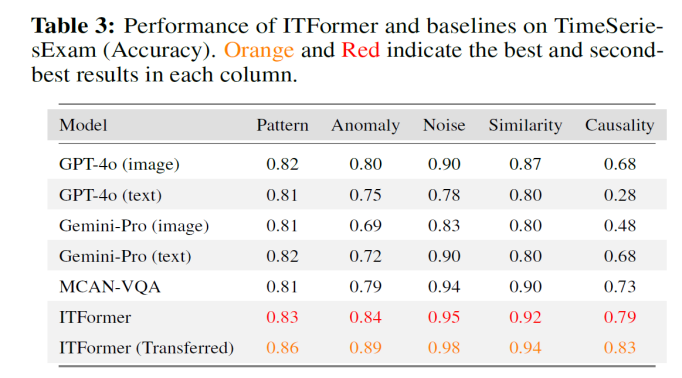
为验证模型与数据集的通用价值,研究团队在公开基准TimeSeriesExam上进行了测试。
结果显示:1.ITFormer方法的有效性:即便不经过预训练,ITFormer直接在TimeSeriesExam上训练,其性能已在多个任务上优于通用基线,证明了其架构设计的先进性。 2.EngineMT-QA数据集的价值:在使用EngineMT-QA进行预训练后,ITFormer的性能得到进一步的巨大提升,在全部五项任务上均达到SOTA水平,其中“因果分析”准确率高达0.83。
这充分说明,EngineMT-QA作为一个时序文本对数据集,能够为模型提供关于时序-文本关系的本质性知识,从而显著提升其在其他任务上的泛化能力。
推理效率验证
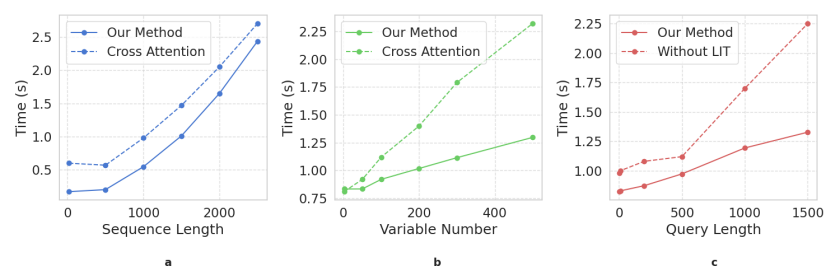
效率测试表明,ITA机制相较于传统的跨模态注意力(cross-attention),在处理多通道、长序列数据时推理速度优势明显。同时,LIT模块也能有效降低长文本输入带来的计算开销。这些结果证明,ITFormer的架构设计兼顾了高性能与高效率,为大规模实时应用提供了可能。
ITFormer及EngineMT-QA为时序AI社区提供了新的研究范式和宝贵资源,在工程和科学领域均具有广阔的应用前景。
时序QA论文合集:
https://github.com/Pandalin98/Awesome-Time-Series-QA-Papers
项目主页:
https://pandalin98.github.io/itformer_site/
论文链接:http://arxiv.org/abs/2506.20093
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!












