前不久,Nature发表了一篇小样本机器学习论文,讲的是一个表格处理模型TabPFN,平均2.8s解读任意表格,开箱即用,在精度和速度上实现了突破性进展。
有人说这是电子表格的ChatGPT时刻,倒也不夸张,本身小样本机器学习对于解决数据稀缺问题就十分重要(应用场景多),如今也正处于快速发展阶段(创新空间大),关于它的研究一直是热门,现在有了如此突破,后续发展态势必将更加火爆。
目前,小样本机器学习尚有很多问题没解决,对于科研人来说,潜在创新方向或可考虑:模型架构优化、数据增强技术、跨领域迁移与泛化、绿色高效算法、安全与鲁棒性研究...
如果打算深入研究,建议看看我整理的12篇小样本机器学习论文,都是前沿成果,有参考会更容易找到思路,代码也附上了,方便各位复现。
扫码添加小享,回复“小样本机器”
免费获取全部论文+开源代码

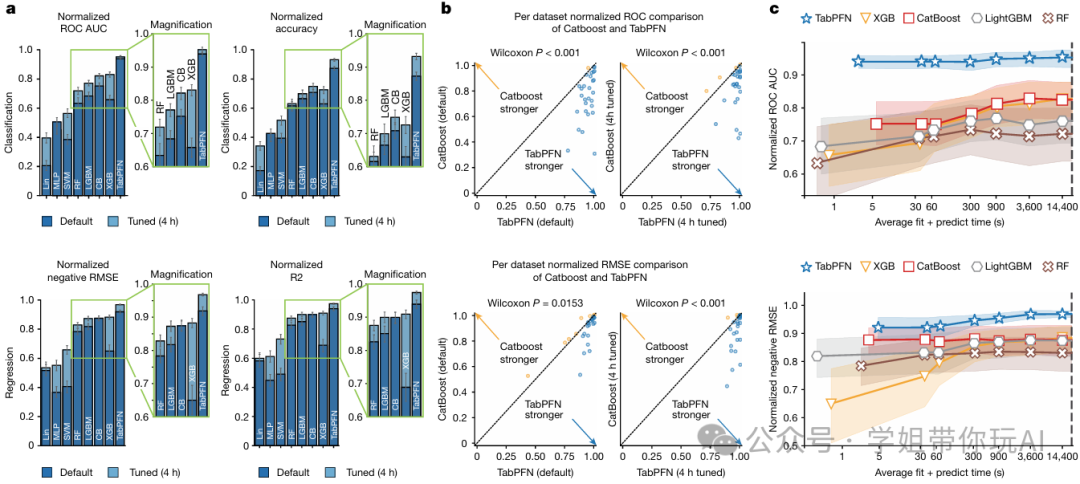
Accurate predictions on small data with a tabular foundation model
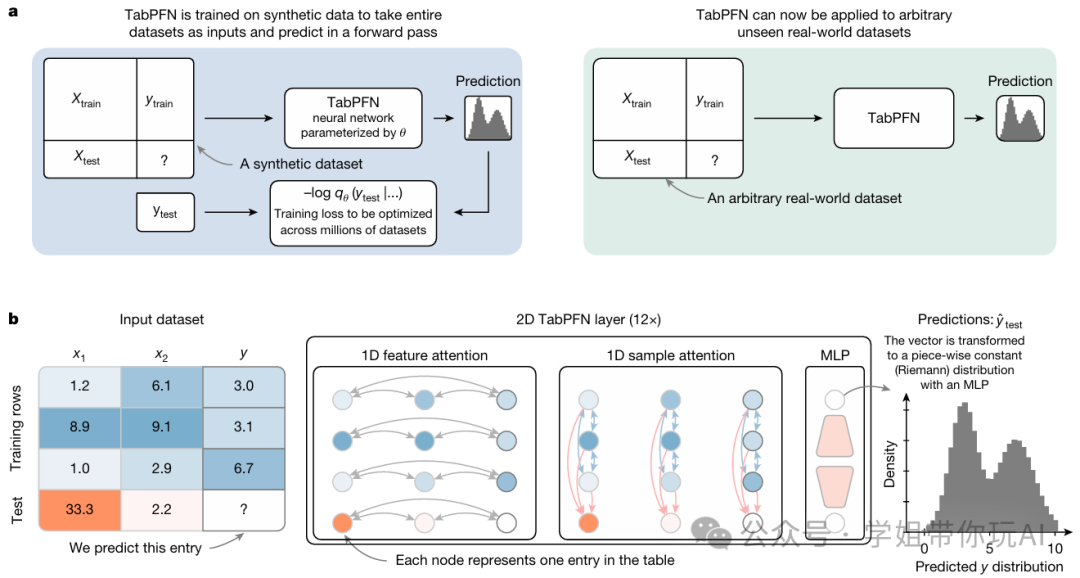
方法:文章介绍的TabPFN主要针对的是小样本机器学习场景,尤其是处理小到中等规模的表格数据,通过在合成数据上预训练和改进的Transformer架构,TabPFN实现了快速高效的训练与预测,显著优于传统方法,同时具备数据生成和可解释性等基础模型特性。
创新点:
- TabPFN利用上下文学习(ICL)框架,通过生成大量合成表格数据集并训练一个基于Transformer的神经网络,自动学习和解决这些合成预测任务。
-
TabPFN在表格数据建模中表现出色,特别是在中小型数据集(最多10,000个样本和500个特征)上。
- TabPFN不仅具备强大的预测性能,还展现出基础模型的特性,如数据生成、密度估计和可重用嵌入的学习。
Enhancing Few-Shot Learning with Integrated Data and GAN Model Approaches
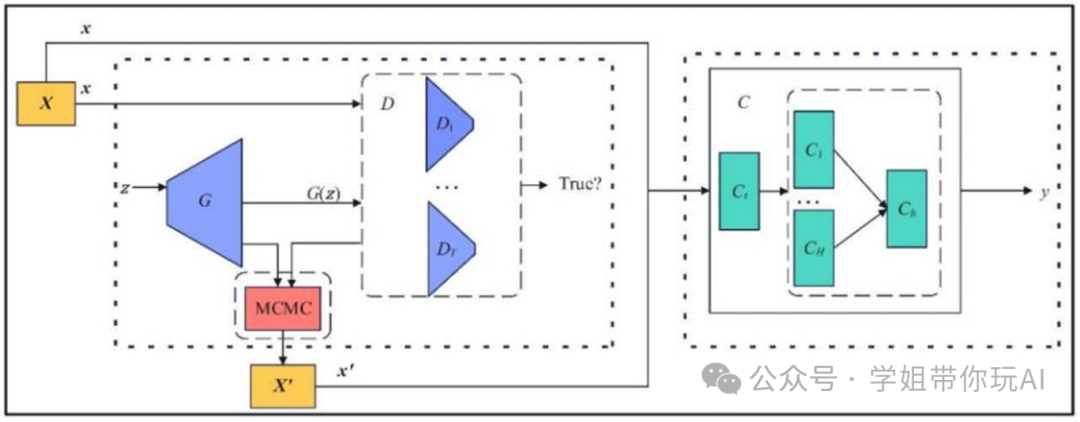
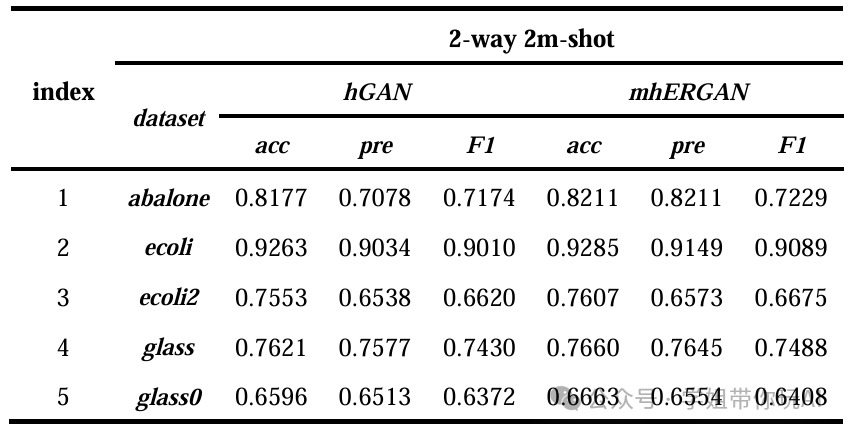
方法:论文提出了一种小样本机器学习方法,通过结合GAN生成数据增强和模型微调,并利用MCMC采样与判别模型集成策略来校正GAN的生成和判别分布,同时采用MHLoss优化模型微调过程,从而提升模型在小样本数据上的性能和泛化能力。
创新点:
- 通过将生成对抗网络(GAN)与马尔可夫链蒙特卡洛(MCMC)采样相结合,提出了一种创新框架。
- 通过引入MHLoss和重新参数化的GAN集成策略,研究增强了模型的稳定性和加速了收敛过程。
- 通过MCMC采样和判别模型集成策略的结合,可以显著提高生成数据的真实性。
扫码添加小享,回复“小样本机器”
免费获取全部论文+开源代码
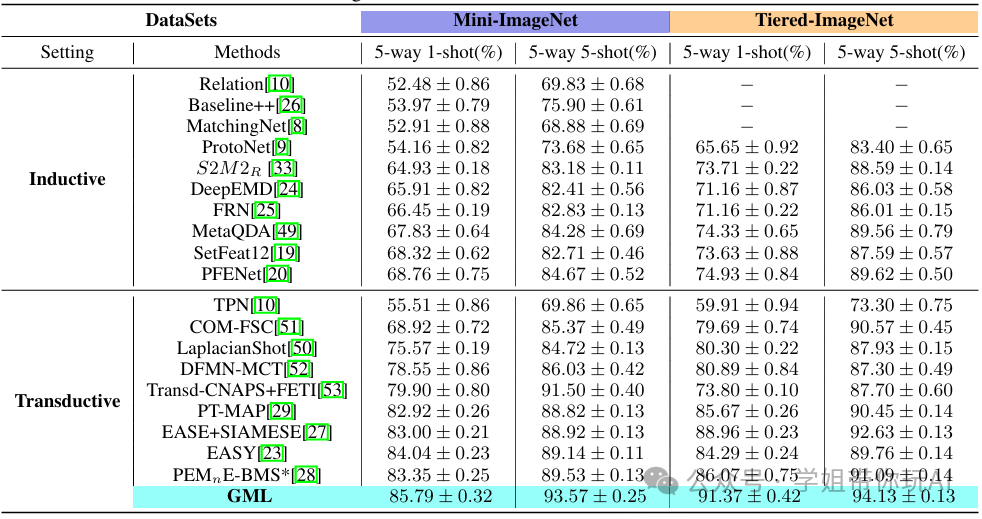
Few-shot image classification based on gradual machine learning
方法:论文提出了一种基于渐进式机器学习(GML)的小样本图像分类方法,通过深度网络提取图像特征,并利用因子图逐步对未标记样本进行分类,优先处理较简单的样本。这种方法显著提升了小样本学习的分类精度,并表现出更强的鲁棒性。
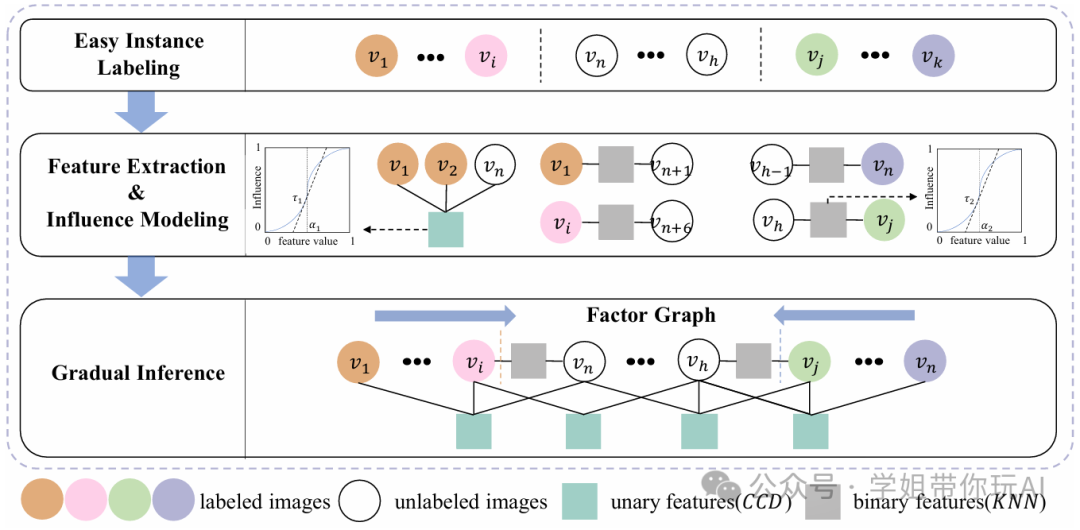
创新点:
- 提出了一种基于非i.i.d渐进式机器学习(GML)范式的新方法,通过在因子图中逐步进行因子推理,逐步对未标记样本进行分类。
- 设计了一个由一元和二元单调因子组成的因子图模型,这些因子可以通过现有的深度学习骨干网络轻松提取,从而实现少样本图像分类的渐进学习。
Ehrshot: An ehr benchmark for few-shot evaluation of foundation models
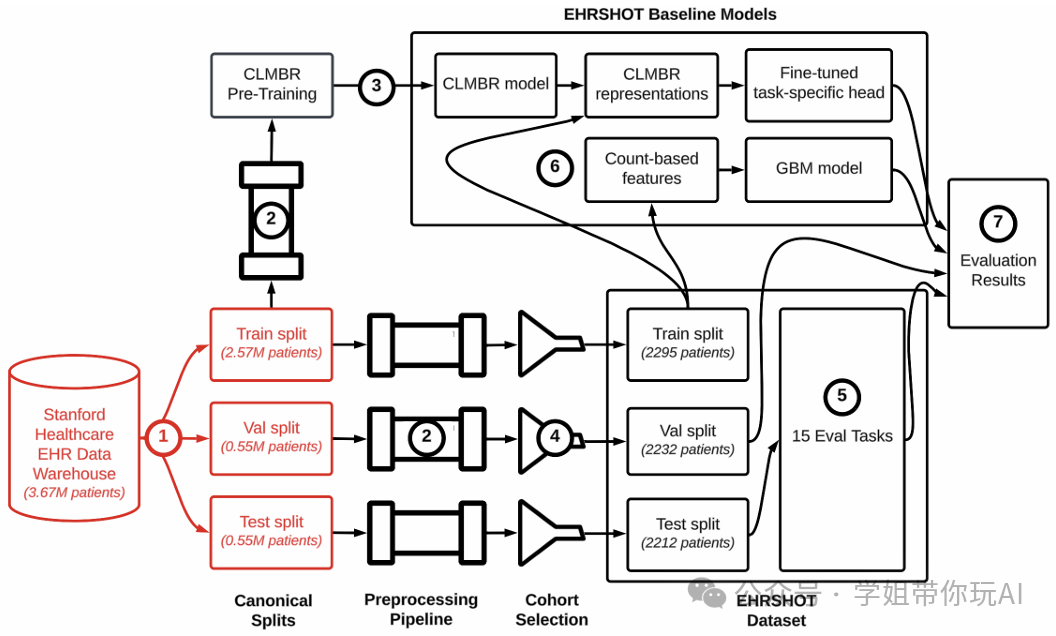
方法:论文提出了一个名为EHRSHOT的电子健康记录(EHR)数据集,用于评估基础模型在小样本学习中的表现。他们定义了15个临床预测任务,并预训练了一个1.41亿参数的模型CLMBR-T-base。通过在小样本场景下测试,展示了预训练模型在低数据量任务中的优势。
创新点:
- 发布了一个名为EHRSHOT的新数据集,包含来自斯坦福医学的6,739名患者的去识别化电子健康记录(EHR)结构化数据。
- 公开了CLMBR-T-base模型的权重,这是一个基于2.57百万患者的结构化EHR数据预训练的141M参数的临床基础模型。
- 定义了15个少样本临床预测任务,以评估基础模型在样本效率和任务适应性方面的优势。

扫码添加小享,回复“小样本机器”
免费获取全部论文+开源代码










