论文题目:Deep learning for cross-domain data fusion in urban computing: Taxonomy, advances, and outlook
论文地址:https://arxiv.org/pdf/2402.19348

创新点
本文是首次对基于深度学习的跨域数据融合方法在城市计算中的应用进行全面系统的综述。以往的研究虽然在特定领域有所探讨,但缺乏对城市计算中多模态数据融合方法的系统性总结。
提出了一个全新的分类框架,从数据来源、融合方法和应用场景三个维度对相关研究进行分类。这种分类方式不仅涵盖了现有的研究,还为未来的研究提供了一个清晰的组织结构。
方法
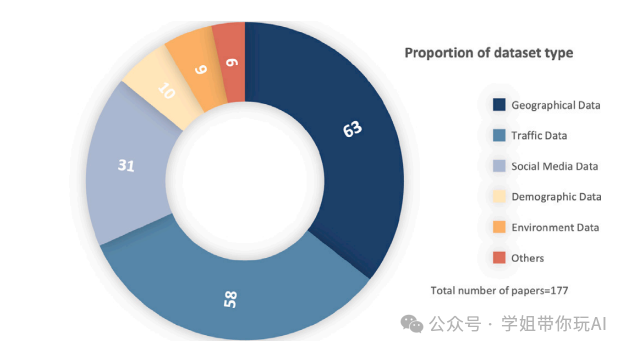
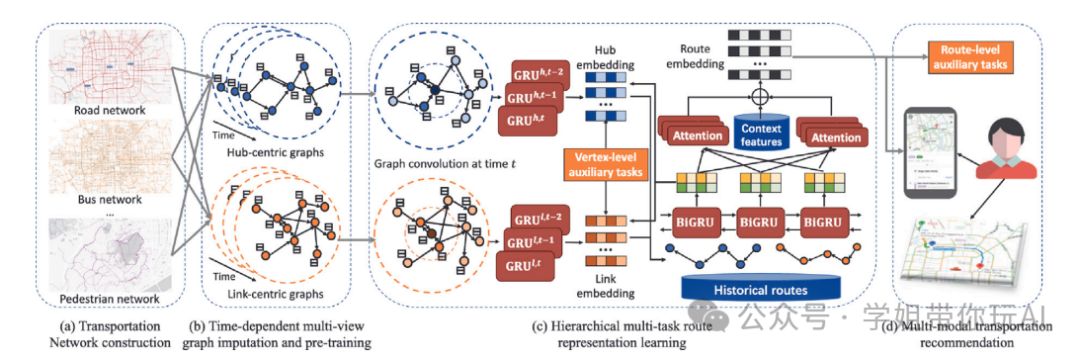
本文提出了一种基于深度学习的跨域数据融合方法,用于城市计算中的多模态数据处理。核心方法是将数据融合分为四个主要类别:基于特征的融合、基于对齐的融合、基于对比的融合和基于生成的融合。这些方法通过整合来自不同源(如地理、交通、社交媒体、人口统计和环境数据)的多模态数据,以提高城市规划、交通管理、经济分析、公共安全、社会研究、环境监测和能源管理等领域的应用效果。
跨域城市计算的基本框架
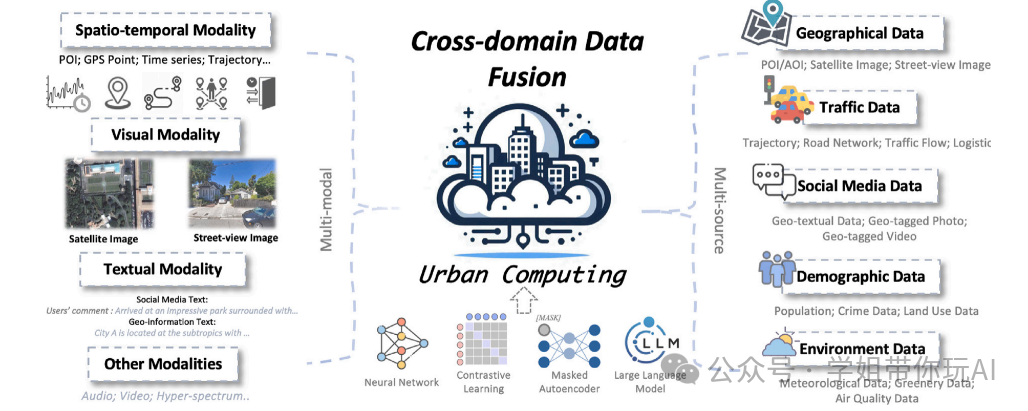
本图展示了跨域城市计算的基本框架,从数据模态和数据来源两个视角进行说明。图的左侧展示了城市数据的多模态融合过程,包括时空数据、视觉数据、文本数据等,这些数据通过数据融合技术整合在一起。右侧则展示了这些数据的具体来源,如地理数据、交通数据、社交媒体数据、人口统计数据和环境数据。图中还强调了跨域数据融合的必要性,即仅依赖单一数据源或模态可能无法全面解决城市任务。
深度学习跨域数据融合的分类框架
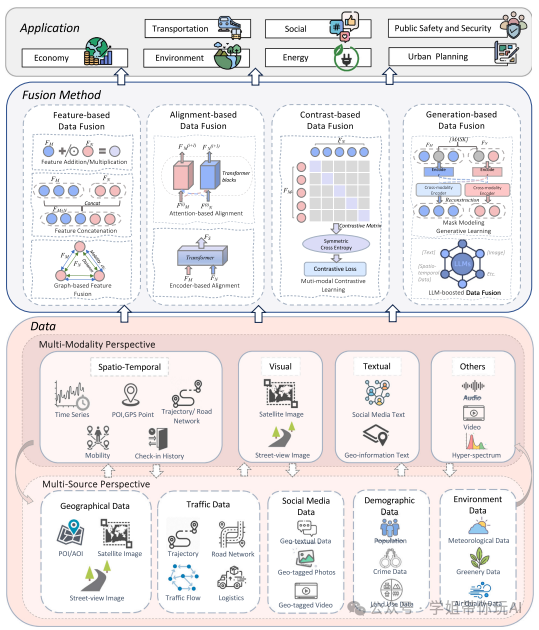
本图展示了本文提出的深度学习跨域数据融合的分类框架。框架从数据、融合方法和应用三个维度进行分类,每个维度下又细分为多个子类别。例如,数据维度分为地理数据、交通数据、社交媒体数据等;融合方法分为基于特征的、基于对齐的、基于对比的和基于生成的;应用领域分为城市规划、交通、经济等。
基于对齐的跨域数据融合的一般框架
本图展示了基于对齐的跨域数据融合的一般框架。图中分为两个部分:基于注意力机制的对齐和基于编码器的对齐。基于注意力机制的对齐通过计算不同模态之间的注意力权重,实现信息的对齐和融合。基于编码器的对齐则通过共享编码器结构,将不同模态的数据映射到一个共享的特征空间中。
UrbanVLP 的多粒度视觉-语言预训练基础模型
本表展示了一个名为 UrbanVLP(Urban Vision-Language Pre-trained model)的多粒度视觉-语言预训练基础模型,该模型专门用于城市指标预测。UrbanVLP 结合了多粒度的视觉线索(如卫星图像和街景图像)以及与之相关的文本描述,通过预训练的方式学习城市区域的综合表示,从而为下游任务提供强大的特征支持。在图中,UrbanVLP 的架构清晰地展示了如何将视觉信息(如卫星图像和街景图像)与文本信息(如对图像的描述或相关标签)结合起来。这种多模态的融合方式使得模型能够更好地理解和分析城市环境中的复杂场景。例如,卫星图像可以提供城市的大规模布局和地理信息,而街景图像则能够捕捉到更细致的街道和建筑特征。通过将这些不同粒度的视觉信息与文本描述相结合,UrbanVLP 能够学习到更全面、更丰富的城市区域表示。
-- END --
关注“
学姐带你玩AI”公众号,回复“数据融合”
领取多模态数据融合论文合集+开源代码







