一、背景
药物开发是一个耗时且昂贵的过程,通常需要超过 10 年时间和平均高达 26 亿美元的投资才能将一种药物从初步发现推向市场。这些高昂成本主要归因于候选药物试验的高失败率。尽管在从数百或数千种化合物中选择候选分子上投入了大量资金,但新候选药物最终成功上市的比例仅约为 10%。因此,选择最有前途的候选分子将有助于加速研究过程并减少最终阶段的失败,从而最大限度地降低药物开发成本。
机器智能(MI),包括机器学习和深度学习,已成功应用于药物发现,并被视为候选药物选择的有前途方法。然而,MI 内部存在性能与可解释性之间的困境,这限制了其应用范围:
❝"深度学习模型在分类上表现优于机器学习模型,但更难以解释。深度学习模型更难解释的原因是,很难找到模型在分类中使用的特征与输出预测之间的直接可靠相关性。"
这些限制在药物开发中不利,因为该领域的研究人员不仅希望获得预测能力,还希望获得模型提供的知识。
开发解释深度学习模型结果的方法并非易事。相反,提高机器学习模型的性能可能提供更快、更简单的解决方案来缓解预测性和可解释性的困境。例如,自动机器学习(AutoML)是增强药物开发过程的一种有前途的策略。
二、方法
2.1 CILBO 管道概述
为了提高易于解释的机器学习模型在药物发现中的分类性能,作者提出了一种称为"使用贝叶斯优化的类不平衡学习"(CILBO)的管道。该管道使用贝叶斯优化来建议机器学习模型的最佳超参数组合,包括模型变量、训练和处理不平衡数据集的策略。
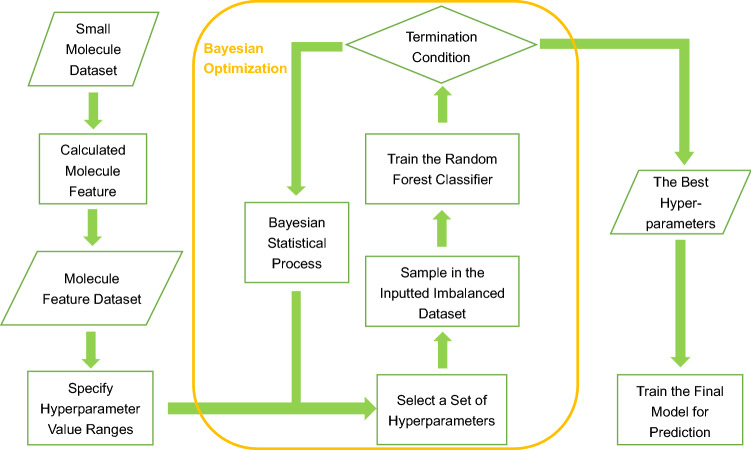
图 1. 最终模型构建工作流程
2.2 类不平衡问题
药物发现数据集通常高度不平衡,包含极少数功能性候选物(感兴趣类别)和数百或数千倍更多的非功能性分子(非感兴趣类别)。少数感兴趣类别更可能被预测为罕见事件,被完全忽略,或被假定为噪声或异常值,这会导致偏差并导致泛化性能不佳。
❝"虽然在疾病和药物相关领域的几项先前研究证明,适当解决类不平衡问题将提高模型的性能,但这个问题仍然经常被忽视。"
一旦机器学习模型应用策略来最小化不平衡数据集造成的分类偏差,它可能会进一步受益于 AutoML 算法改进的性能。
2.3 贝叶斯优化
贝叶斯优化是一种用于黑盒函数全局优化的顺序设计策略,不假设任何函数形式,特别适合药物开发等应用领域。这里使用的优化与常用的超参数优化不同,它解决了类不平衡问题。
2.4 模型选择与特征提取
作者选择了随机森林作为分类器,因为它能够限制过拟合并且易于解释。
❝"随机森林模型对过拟合具有鲁棒性,并且易于解释,因为可以使用常规方法来估计特征的重要性和特征之间的交互作用。"
可选的分子特征包括描述符、RDK 指纹、MACCS 键、Avalon 指纹、ECFP4 和 ECFP6,这些都是由 RDKit 2020.09.1.0 计算的。所有这些特征在模型的训练阶段都被单独测试,但不是特征的复杂组合。最终模型选择了 RDK 指纹作为分子特征,因为它提供了分子拓扑结构表示的描述,对于解释模型非常有用。
2.5 超参数优化
贝叶斯优化用于找到模型的最佳超参数。在这项工作中,贝叶斯优化不仅用于分类器,还用于专门处理不平衡数据集的策略。训练数据集高度不平衡,这可能会引入分类偏差。贝叶斯优化旨在为分类器提供最佳超参数组合,并缓解类不平衡问题。
需要优化的超参数包括:
| |
|---|
| |
| Categorical ([“gini”, “entropy”]) |
| |
| |
| |
| Categorical ([True, False]) |
| Categorical ([“balanced”, “balanced_subsample”, None]) |
| Categorical ([‘majority’, ‘not minority’, ‘not majority’]) |
最后两个超参数"class_weight"和"sampling_strategy"专门用于处理不平衡数据集。
2.6 数据集
训练模型使用的数据集与 Stokes 等人论文中描述的数据集相同,该数据集结合了来自 USFDA 批准药物库和从天然产物中分离出的分子。它包含 2335 个唯一化合物,其中 120 个对大肠杆菌有生长抑制活性。该数据集高度不平衡。
用于候选预测的数据集也是 Stokes 等人描述的相同数据集,来自 Drug Repurposing Hub,包含 6111 个处于人类疾病研究各个阶段的分子。通过移除训练集和 Drug Repurposing Hub 之间分子图谱相同的化合物,剩余的 4496 个分子用于两个模型的预测。
三、实验与结果
3.1 模型训练阶段性能评估
贝叶斯优化建议的最佳超参数列于表 1 中。最后两个超参数"class_weight"和"sampling_strategy"用于最小化数据集不平衡引起的偏差并提高整体模型性能。
表 1. 贝叶斯优化建议的最佳超参数
 框架表示用于处理不平衡数据集的超参数。
框架表示用于处理不平衡数据集的超参数。
使用这些最佳超参数和特征,模型在训练阶段经过 30 次五折交叉验证后的平均接收者操作特性曲线下面积(ROC-AUC)约为 0.917,高于 Stokes 模型的 0.896。在使用上述最佳超参数和分子特征增强后,并使用更多训练样本(训练集包括 90% 的分子),最终模型实现了 0.99 的 ROC-AUC(图 2)。
 图 2. 最终模型的 ROC-AUC*
图 2. 最终模型的 ROC-AUC*
基于最终模型测试集的混淆矩阵如表 2 所示。根据该矩阵,模型没有将任何非抗菌分子归类为抗菌分子,这表明该模型在识别候选化合物方面具有较低的假阳性率。
表 2. 最终模型的混淆矩阵
此混淆矩阵基于最终模型的测试集,预测分数高于 0.5 的分子被视为预测抗菌。
3.2 与 Stokes 模型在抗菌发现中的预测结果比较
最终模型随后应用于从 Drug Repurposing Hub 记录的库中识别具有抗菌特性的候选分子。通过比较两个模型对 162 个经验测试分子的预测结果,发现 CILBO 模型在预测抗菌特性方面与 Stokes 的深度学习模型相当有效。
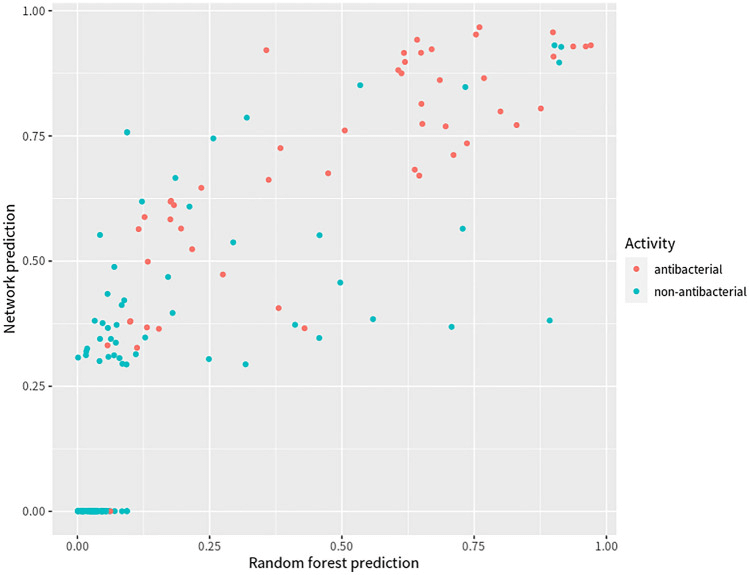
图 3. 两个模型的预测结果图。蓝点代表非抗菌;橙点代表抗菌。X 轴(Pred_Score_Forest)是由最终模型(随机森林分类器)预测的分数;Y 轴(Pred_Score_Net)是由 Stokes 最终模型(图神经网络)预测的分数。
具体而言,在 CILBO 模型中预测分数高于 0.5(模型默认阈值分数)的分子中,约 75% 被发现是经验测试的抗菌分子,而在 Stokes 模型中预测分数高于 0.5 的分子中,74% 是经验测试的抗菌分子。当在两个模型中选择高于 0.5 的阈值分数时,约 80% 满足条件的分子具有经验测试的抗菌特性,这高于任何单独模型的数量。
四、讨论与应用
机器智能(MI)被视为帮助缓解药物发现过程中高昂成本压力的有前途方法。然而,MI 内部的预测性和可解释性之间的困境限制了其在药物发现中的更广泛应用。因此,作者提出了"使用贝叶斯优化的类不平衡学习"(CILBO)管道来提高机器学习模型的分类性能。
CILBO 模型的一个关键自然优势是它易于解释。此外,训练像这里使用的随机森林模型这样的机器学习模型所需的时间至少比训练深度学习模型所需的时间短 100 倍。这提供了足够的时间自动尝试各种超参数并确定最佳超参数来增强模型。与普通深度学习模型相比,基于 CILBO 构建的模型的另一个明显优势是它对模型设计者和基础设施的依赖性较低。
特别值得注意的是,不平衡数据集在药物行业相当常见。它们可能在 MI 辅助药物开发过程中导致严重的分类偏差,但这个问题经常被忽视。作者在构建模型时考虑了这种不平衡问题,并使用特殊超参数来控制这种类型的偏差,旨在增强模型性能。
五、结论
作者构建了一个基于 CILBO(他们提出的管道)的特殊随机森林模型,并将这个机器学习模型与 Stokes 等人在抗生素发现中创建的深度学习模型进行了比较。比较结果以及模型的其他特性表明:
- 基于 CILBO 构建的机器学习模型的预测性能至少与深度学习模型一样好;
- 它自然更容易解释,相对更简单操作,不需要研究人员具有高水平经验;
- 包含类不平衡策略以控制分类偏差进一步提高了基于 CILBO 构建的模型的预测性能,并可能扩大其在药物开发中的适用性。
因此,作者设计的 CILBO 管道为促进药物开发中的机器智能提供了一种替代和简单的解决方案。










