解锁 Qwen-3 高性能调优。
 长按关注《AI科技论谈》
长按关注《AI科技论谈》
当业界聚焦于ChatGPT与DeepSeek生态开发时,Qwen-3的微调能力正成为开发者关注的新焦点——这项技术可将通用大语言模型转化为垂直领域的专业助手。
本文为大家系统解析如何基于特定场景对Qwen-3进行定向优化。希望读者可从中获取适用于实际场景的模型调优方法论。
一、Qwen-3简介
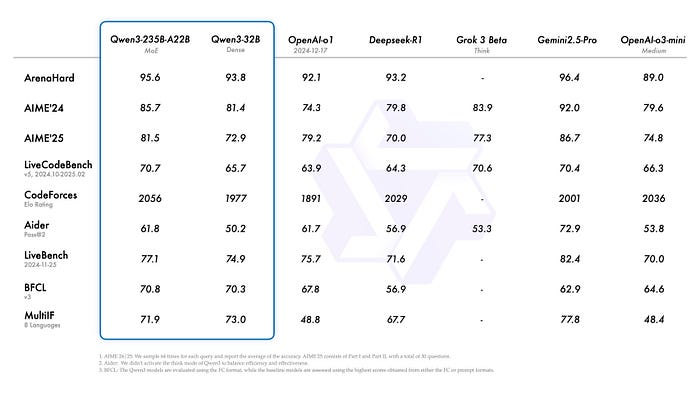
Qwen-3一经发布,就迅速成为开发者的首选工具,其在代码生成、数学推理、综合能力等评测中的领先表现是重要原因。
该模型在多项基准测试中超越主流大语言模型,包括DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等。值得注意的是,小型MoE模型Qwen-3–30B-A3B以10倍激活参数的优势超越
Qwen-32B,甚至仅40亿参数的Qwen-3–4B也能媲美Qwen-2.5–72B-Instruct的性能。
二、微调准备与环境搭建
技术依赖
微调Qwen-3需以下Python库支持:
- unsloth:该工具可使Llama-3、Mistral、Gemma及Qwen等模型的微调速度提升2倍,内存占用减少70%且不影响精度。
-
torch:深度学习基础框架,提供支持GPU加速的张量运算,对大语言模型训练至关重要。
- transformers:NLP领域主流开源库,提供便捷的预训练模型调用接口,是微调任务的基础组件。
- trl:基于Hugging Face开发的强化学习库,专为Transformer模型设计,简化RL与NLP的结合流程。
计算资源要求
微调大语言模型旨在使模型响应更贴合特定领域,无需重新训练全部参数,但仍对硬件有较高要求——完整参数存储需占用大量GPU显存。
本文以80亿参数的量化版Qwen-3为例进行演示,该模型需8–12GB显存。为降低入门门槛,使用Google Colab免费提供的15GB显存T4 GPU完成操作。
数据准备策略
微调需结构化任务数据,常见来源包括社交媒体、网站、书籍及研究论文等。本次将结合推理数据集与通用对话数据集,赋予模型更强的逻辑推理能力和prompt理解能力。
数据集均来自Hugging Face开源社区:
-
unsloth/OpenMathReasoning-mini:用于提升模型推理与问题解决能力。
- mlabonne/FineTome-100k:优化通用对话交互能力。
三、Python实现流程
安装依赖包
在Google Colab环境执行以下命令:
!pip install --no-deps bitsandbytes accelerate xformers==0.0.29.post3 peft trl==0.15.2 triton cut_cross_entropy unsloth_zoo
!pip install sentencepiece protobuf datasets huggingface_hub hf_transfer
!pip install --no-deps unsloth
若使用本地高性能GPU,终端执行:
!pip install unsloth
初始化模型与分词器
通过unsloth加载预训练模型,代码实现:
from unsloth import FastLanguageModel
import torch
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/Qwen3-8B-unsloth-bnb-4bit", # 80亿参数量化模型
max_seq_length=2048, # 支持2048token上下文
load_in_4bit=True, # 4位量化降低内存占用
load_in_8bit=False, # 8位模式(需更高显存)
full_finetuning=False, # 启用参数高效微调(PEFT)
# token="", # 访问权限模型需提供令牌
)
 正在初始化通义千问 3(Qwen-3)模型和分词器
正在初始化通义千问 3(Qwen-3)模型和分词器添加LoRA适配器
通过LoRA技术实现高效微调,代码如下:
model = FastLanguageModel.get_peft_model(
model,
r=32, # LoRA矩阵秩,值越大精度越高
target_modules=[ # 需适配的模型层
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
lora_alpha=64, # 缩放因子,通常设为r的2倍
lora_dropout=0, # 关闭 dropout
bias="none", # 不微调偏置项
use_gradient_checkpointing="unsloth", # 支持长上下文
random_state=3433, # 随机种子确保可复现
)
数据预处理
加载并标准化数据集:
from datasets import load_dataset
# 加载推理与对话数据集
reasoning_dataset = load_dataset("unsloth/OpenMathReasoning-mini", split="cot")
non_reasoning_dataset = load_dataset("mlabonne/FineTome-100k", split="train")
# 标准化推理数据为对话格式
def generate_conversation(examples):
problems = examples["problem"]
solutions = examples["generated_solution"]
return {
"conversations": [
[{"role": "user", "content": p}, {"role": "assistant", "content": s}]
for p, s in zip(problems, solutions)
]
}
reasoning_conversations = tokenizer.apply_chat_template(
reasoning_dataset.map(generate_conversation, batched=True)["conversations"],
tokenize=False
)
# 标准化通用对话数据
from unsloth.chat_templates import standardize_sharegpt
dataset = standardize_sharegpt(non_reasoning_dataset)
non_reasoning_conversations = tokenizer.apply_chat_template(
dataset["conversations"],
tokenize=False
)
推荐书单
《用Cursor玩转AI辅助编程——不写代码也能做软件开发》
本书是一本实用指南,全面介绍了Cursor这款革命性的AI驱动的代码编辑器。本书深入浅出地讲解Cursor的核心功能、工作原理和实际应用,旨在帮助读者快速掌握AI辅助编程技术。
全书分为基础篇、进阶篇、实战篇、参考与展望篇。基础篇介绍Cursor的安装配置和基本操作。进阶篇深入探讨Cursor的生成代码、智能补全和代码重构等核心功能。实战篇通过多个真实项目案例,展示如何在不同场景中发挥Cursor的强大功能。参考与展望篇介绍了Cursor最佳实践与使用技巧,也对AI辅助编程的未来做出展望。
【5折促销中】购买链接:https://item.jd.com/14992710.html
精彩回顾
Ollama+MCP 深度整合指南:从模型到LLM应用开发全流程方案
王炸组合MCP+LangChain,带你轻松创建LLM应用
只需5分钟,教你用Python搭建MCP Server
大模型新基座,基于FastAPI,利用Python开发MCP服务器
基于Docker,快速部署开源智能体框架n8n
Python专业级智能体框架Pydantic AI,高效创建生产级智能体






