一. 发色替换
在虚拟形象编辑、发型试换、人脸美颜等场景中,高质量的人像分割与发色替换已经成为图像处理领域的重要应用需求。
传统的图像分割方法往往难以精准处理复杂背景和细节结构,尤其是在人发区域容易出现边缘锯齿、融合不自然等问题。
本文尝试通过深度学习并结合传统的图像处理来实现这一功能。
二. 算法流程
基于深度学习的发色替换大致流程如下:
 算法流程.png
算法流程.png大致步骤如下:
- 人像前景提取:使用 MODNet 对原图进行前景分割,获取 mask。
- 人像区域裁剪:在 mask 基础上,对人像区域进行轮廓分析与扩展裁剪,特别考虑女生长发等情况,避免头发被截断。裁剪后得到一个人像局部 ROI,用于精细的人脸语义分割。
- Face Parsing 主要是获取头发区域:将裁剪后的人像 ROI 输入 face parsing 模型,获得每个像素的语义标签图。从中提取出头发对应的区域,生成头发掩码。
- 掩码映射与对齐:将 parsing 得到的头发掩码 resize 回裁剪前的人像 ROI 尺寸,再映射回整张原图中,形成与原图一致大小的 hair_mask。
- 发色替换与融合(HSV 模型):将原图转换为 HSV 色彩空间,在 hair_mask 区域内替换 H 通道为目标色相,适当增强 S 通道(饱和度),并保留 V 通道(亮度),确保头发结构、阴影与高光不被破坏。最后,将替换后的图像转换回 BGR,并仅在头发区域进行像素融合。
- 最终输出:生成的结果图像保留了原图背景、人像五官与光影信息,仅头发区域被自然地替换为目标发色。
三. 整体的实现
整个流程涉及到两个模型,每个模型的部署和加速都使用 ONNXRuntime,它们的调用我都封装好了。
下面以 Modnet 模型的调用为例:
#include "../onnxruntime/OnnxRuntimeBase.h"
usingnamespace cv;
usingnamespacestd;
usingnamespace Ort;
class Modnet:public OnnxRuntimeBase {
public:
Modnet(std::string modelPath, constchar* logId, constchar* provider);
void inferImage(Mat& src, Mat& mask);
private:
void preprocess(const cv::Mat& image);
Mat postprocess(float* output_data, int width, int height);
vector<float> input_image_;
int inpWidth;
int inpHeight;
};
#include "../../include/faceBeauty/Modnet.h"
Modnet::Modnet(std::string modelPath, constchar* logId, constchar* provider): OnnxRuntimeBase(modelPath, logId, provider)
{
this->inpHeight = 512;
this->inpWidth = 512;
}
void Modnet::preprocess(const cv::Mat& image) {
cv::Mat resized, float_img;
cv::resize(image, resized, cv::Size(512, 512));
resized.convertTo(float_img, CV_32FC3, 1.0 / 255.0);
this->input_image_.resize(this->inpWidth * this->inpHeight * image.channels());
for (int c = 0; c 3; ++c)
for (int h = 0; h this->inpHeight; ++h)
for (int w = 0; w this->inpWidth; ++w)
this->input_image_[c * this->inpHeight * this->inpWidth + h * this->inpWidth + w] = float_img.at<:vec3f>(h, w)[c];
}
// 假设 postprocess() 将 MODNet 输出 float* 转为 CV_32FC1 alpha mask(取值范围 0~1)
cv::Mat Modnet::postprocess(float* output_data, int width, int height) {
cv::Mat alpha(height, width, CV_32FC1, output_data);
// 拷贝一份,防止 output_data 被释放
return alpha.clone();
}
void Modnet::inferImage(Mat& src, Mat& mask) {
this->preprocess(src);
std::array<int64_t,4> input_shape {1,3, this->inpHeight, this->inpWidth};
Ort::Value input_tensor_ = Ort::Value::CreateTensor<float>(memory_info_handler, input_image_.data(), input_image_.size(), input_shape.data(), input_shape.size());
vector ort_outputs = this -> forward(input_tensor_);
auto output_data = ort_outputs[0].GetTensorMutableData<float>();
cv::Mat alpha = this -> postprocess(output_data, this->inpWidth, this->inpHeight); // CV_32FC1
cv::resize(alpha, alpha, src.size()); // 缩放到原图尺寸
alpha.convertTo(alpha, CV_32FC1); // 确保是 float32 类型
mask = alpha;
}
Modnet 模型的调用需要输入一张原图,就可以生成人像前景。
Face Parsing 的封装如下:
#include "../onnxruntime/OnnxRuntimeBase.h"
usingnamespace cv;
usingnamespacestd;
usingnamespace Ort;
class FaceParsing:public OnnxRuntimeBase {
public:
FaceParsing(std::string modelPath, constchar* logId, constchar* provider);
/**
* 通过推理获取人脸的 parsing
* @param src
* @param dst
*/
void inferImage(Mat& src, Mat& dst);
Mat getCombinedMask(const Mat& label_map, const std::vector<int>& label_values);
void getSkinMask(Mat& label_map, Mat& dst);
/**
* 获取语义分割的 mask
* @param src
* @param label_map
* @return
*/
Mat getSemanticSegmentationMask(Mat src, Mat label_map);
private:
void preprocess(Mat src);
Mat getLabelMap(float* output_data, int num_classes, int height, int width);
vector<float> input_image_;
int inpWidth;
int inpHeight;
// 定义调色板(BGR)
std::vector<:vec3b> palette = {
{
0, 0, 0}, {128, 0, 0}, { 0, 128, 0}, {128, 128, 0},
{ 0, 0, 128}, {128, 0, 128}, { 0, 128, 128}, {128, 128, 128},
{ 64, 0, 0}, {192, 0, 0}, { 64, 128, 0}, {192, 128, 0},
{ 64, 0, 128}, {192, 0, 128}, { 64, 128, 128}, {192, 128, 128},
{ 0, 64, 0}, {128, 64, 0}, { 0, 192, 0}
};
};
#include "../../include/faceBeauty/FaceParsing.h"
FaceParsing::FaceParsing(std::string modelPath, constchar* logId, constchar* provider): OnnxRuntimeBase(modelPath, logId, provider)
{
this->inpHeight = input_node_dims[0][2];
this->inpWidth = input_node_dims[0][3];
}
void FaceParsing::preprocess(Mat src)
{
Mat dst;
cvtColor(src, dst, COLOR_BGR2RGB);
resize(dst, dst, Size(this->inpWidth, this
->inpHeight), INTER_LINEAR);
dst.convertTo(dst, CV_32F, 1.0f/255.0f); // 归一化 [0,1]
// HWC->CHW 平铺
this->input_image_.reserve(1*3*this->inpHeight*this->inpWidth);
for(int c=0;c<3;++c)
for(int h=0; hthis->inpHeight;++h)
for(int w=0; wthis->inpWidth;++w)
this->input_image_.push_back(dst.at<:vec3f>(h,w)[c]);
}
// 解析 output_data 得到 label_map,便于未来可以提取更多比如 眼睛、嘴巴、鼻子 等等
Mat FaceParsing::getLabelMap(float* output_data, int num_classes, int height, int width) {
Mat label_map(height, width, CV_8UC1);
constunsignedint size = height * width;
for (int i = 0; i < size; ++i) {
int max_idx = 0;
float max_val = output_data[i];
for (int j = 1; j < num_classes; ++j) {
float val = output_data[j * size + i];
if (val > max_val) {
max_val = val;
max_idx = j;
}
}
label_map.data[i] = static_cast(max_idx);
}
return label_map;
}
// label_map: getLabelMap() 的输出
// label_values: 要合并的类别索引列表(如 {1, 13} 表示皮肤和头发)
// 返回值: 255 表示属于这些类别的像素,0 表示不是
Mat FaceParsing::getCombinedMask(const Mat& label_map, const std::vector<int>& label_values) {
CV_Assert(label_map.type() == CV_8UC1);
Mat combined_mask = Mat::zeros(label_map.size(), CV_8UC1);
for (int label : label_values) {
combined_mask |= (label_map == label);
}
combined_mask.convertTo(combined_mask, CV_8UC1, 255);
return combined_mask;
}
void FaceParsing::inferImage(Mat& src, Mat& dst) {
this->preprocess(src);
std::array<int64_t,4> input_shape {1,3,this->inpHeight, this->inpWidth};
Ort::Value input_tensor_ = Ort::Value::CreateTensor<float>(memory_info_handler, input_image_.data(), input_image_.size(), input_shape.data(), input_shape.size());
vector ort_outputs = this -> forward(input_tensor_);
// 读取输出 & 校验 [1,19,512,512]
float* out_data = ort_outputs.front().GetTensorMutableData<float>();
auto info = ort_outputs.front().GetTensorTypeAndShapeInfo();
auto dims = info.GetShape();
assert(dims.size()==4 && dims[1]==19 && dims[2]==512 && dims[3]==512);
// Argmax 得到 class_idx (CV_8UC1)
int H=512, W=512, C=19;
dst = getLabelMap(out_data,C,H,W);
}
void FaceParsing::getSkinMask(Mat& label_map, Mat& dst) {
// 提取“皮肤”区域作为人脸轮廓基础 (类别ID=1)
cv::Mat mask = (label_map==1);
// 形态学闭运算:填补小孔、平滑边界
int ksize = 25;
cv::Mat kernel = cv::getStructuringElement(cv::MORPH_ELLIPSE, cv::Size(ksize, ksize));
cv::morphologyEx(mask, mask, cv::MORPH_CLOSE, kernel);
// 提取并绘制外轮廓
std::vector<std::vector<:point>> contours;
cv::findContours(mask, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
cv::Mat contour_mask = cv::Mat::zeros(mask.size(), CV_8UC1);
cv::drawContours(contour_mask, contours, -1, cv::Scalar(255), cv::FILLED);
dst = contour_mask;
}
Mat FaceParsing::getSemanticSegmentationMask(Mat src, Mat label_map) {
int H = label_map.cols;
int W = label_map.rows;
// 生成彩色掩码
cv::Mat mask_color(H, W, CV_8UC3);
for (int h = 0; h < H; ++h) {
for (int w = 0; w < W; ++w) {
uchar cid = label_map.at(h, w);
mask_color.at<:vec3b>(h, w) = palette[cid];
}
}
cv::resize(mask_color, mask_color, src.size());
cv::Mat overlay;
double alpha = 0.6;
cv::addWeighted(src, alpha, mask_color, 1 - alpha, 0, overlay);
return
overlay;
}
Face Parsing 的模型使用 BiSeNet ,根据 Face Parsing 模型的定义输出的类别标签与面部部位的对应关系如下:
不同的模型对应的标签不同,如果需要更精细地区分“刘海”等,可能需要额外标注的数据集。
下面的代码给出了完整的算法流程和相关注释:
#include
#include
#include
#include
#include "include/faceBeauty/FaceParsing.h"
#include "include/faceBeauty/Modnet.h"
#include "include/onnxruntime/Constants.h"
usingnamespace cv;
usingnamespacestd;
/**
* 基于 alpha mask 裁剪人像 ROI,还要兼顾长发女生的情况
* @param alpha
* @param threshold
* @param expand
* @return
*/
cv::Rect getSmartFaceROIFromAlpha(const cv::Mat& alpha, float
threshold = 0.1, int expand = 40) {
// 二值化
cv::Mat binary_mask;
cv::threshold(alpha, binary_mask, threshold, 255.0, cv::THRESH_BINARY);
binary_mask.convertTo(binary_mask, CV_8UC1);
// 获取图像高度用于判断“顶部区域”
int height = binary_mask.rows;
int width = binary_mask.cols;
int top_cutoff = height * 2 / 3; // 只保留上 2/3 的区域
cv::Mat top_mask = binary_mask(cv::Rect(0, 0, width, top_cutoff));
// 轮廓提取(上部区域)
std::vector<std::vector<:point>> contours;
cv::findContours(top_mask, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
if (contours.empty()) {
return cv::Rect(0, 0, width, height); // fallback
}
// 合并有效轮廓为矩形框
cv::Rect face_rect = cv::boundingRect(contours[0]);
for (size_t i = 1; i < contours.size(); ++i) {
cv::Rect r = cv::boundingRect(contours[i]);
float aspect = r.width / (float)r.height;
if (r.area() 500 || aspect > 3.0f) continue; // 过滤宽高比过大的杂散区域
face_rect |= r; // 合并
}
// 向外扩展
face_rect.x = std::max(face_rect.x - expand, 0);
face_rect.y = std::max(face_rect.y - expand, 0);
face_rect.width = std::min(face_rect.width + 2 * expand, width - face_rect.x);
face_rect.height = std::min(face_rect.height + 2 * expand, height - face_rect.y);
return face_rect;
}
cv::Mat changeHairColor_HSV(
const cv::Mat& image,
const cv::Mat& hair_mask, // CV_8UC1, 255 for hair
int target_hue, // 0-179, OpenCV H 值
float saturation_scale = 1.2f // 控制染色鲜艳度
) {
CV_Assert(image.type() == CV_8UC3 && hair_mask.type() == CV_8UC1);
cv::Mat image_hsv;
cv::cvtColor(image, image_hsv, cv::COLOR_BGR2HSV); // 转 HSV
std::vector<:mat> hsv_channels;
cv::split(image_hsv, hsv_channels); // 分离 H/S/V
// 仅替换头发区域的 H 通道
for (int y = 0; y < hair_mask.rows; ++y) {
for (int x = 0; x < hair_mask.cols; ++x) {
if (hair_mask.at(y, x) > 128) {
hsv_channels[0].at(y, x) = target_hue;
hsv_channels[1].at(y, x) = cv::saturate_cast(
hsv_channels[1].at(y, x) * saturation_scale
);
}
}
}
// 合并回 HSV,转换为 BGR
cv::merge(hsv_channels, image_hsv);
cv::Mat recolored_bgr;
cv::cvtColor(image_hsv, recolored_bgr, cv::COLOR_HSV2BGR);
// 仅复制头发区域
cv::Mat final_result = image.clone();
recolored_bgr.copyTo(final_result, hair_mask);
return final_result;
}
int main()
{
string image_path =".../girl.jpg";
cv::Mat src = cv::imread(image_path);
imshow("src",src);
// 各种模型的加载
conststring& onnx_provider = OnnxProviders::CPU;
constchar* provider = onnx_provider.c_str();
string modelPath = "/Users/Tony/CLionProjects/MonicaImageProcessHttpServer/models";
string faceParsingModePath = modelPath + "/face_parsing_resnet34.onnx";
conststd::string& faceParsingLogId = "faceParsing";
FaceParsing faceParsing(faceParsingModePath,faceParsingLogId.c_str(), provider);
string modnetModePath = modelPath + "/modnet.onnx";
conststd::string& modnetLogId = "modnet";
Modnet modnet(modnetModePath,modnetLogId.c_str(), provider);
Mat mask;
modnet.inferImage(src, mask);
imshow("mask", mask);
cv::Rect face_roi = getSmartFaceROIFromAlpha(mask);
cv::Mat face_crop = src(face_roi).clone();
imshow("face_crop", face_crop);
// 人脸解析与获取掩码
cv::Mat class_idx;
faceParsing.inferImage(face_crop, class_idx);
imshow("class_idx",class_idx);
Mat ssm = faceParsing.getSemanticSegmentationMask(face_crop, class_idx);
imshow("ssm",ssm);
// 提取“皮肤”区域作为人脸轮廓基础 (类别ID=1)
cv::Mat hair_mask_small = (class_idx == 17);
imshow("hair_mask_small",hair_mask_small);
hair_mask_small.convertTo(hair_mask_small, CV_8UC1, 255);
// Resize 回 ROI 尺寸
cv::Mat hair_mask_roi;
cv::resize(hair_mask_small, hair_mask_roi, face_roi.size(), 0, 0, cv::INTER_NEAREST);
// 映射回原图尺寸
cv::Mat hair_mask = cv::Mat::zeros(src.size(), CV_8UC1);
hair_mask_roi.copyTo(hair_mask(face_roi));
imshow("full_hair_mask",hair_mask);
cv::Mat recolored = changeHairColor_HSV(src, hair_mask, 140, 1.3f);
cv::imshow("Recolored Hair", recolored);
waitKey(0);
return0;
}
先来看原图和最终的效果图。
下图表示:通过 MODNet 模型获取人像前景的mask
下面两张图表示:通过上述 mask 对人像区域裁剪,以及对人脸语义分割生成彩色掩码。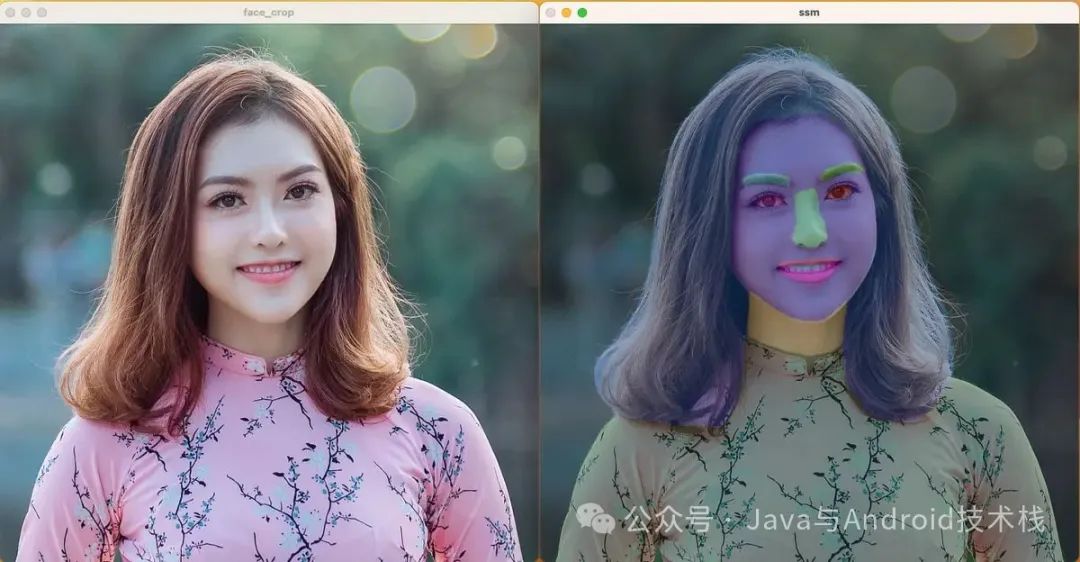
下面两张图表示:获取头发掩码以及将其映射回原图形成 hair_mask。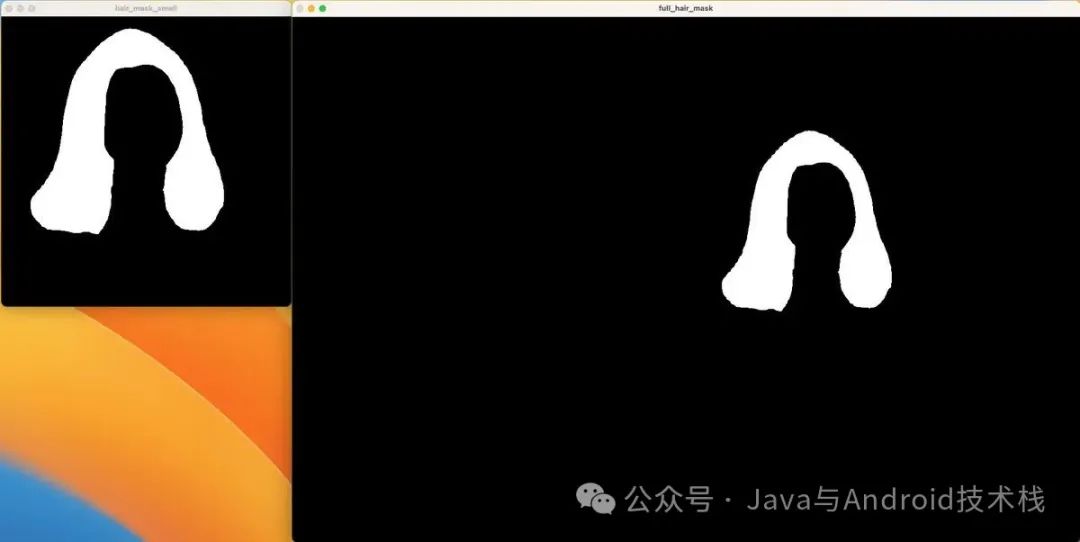
获取 hair_mask 之后,就可以进行发色替换了。最早使用 alaha blending 时,我发现头发颜色会很奇怪。为了更好地控制颜色的效果,尝试在 HSV 空间操作,果然效果好很多。仅替换色相(H)并保留亮度(V),这样可以保持头发纹理和光泽自然。
替换一下颜色看看效果:
 image.png
image.png再跑一些其他的人物图,看看效果: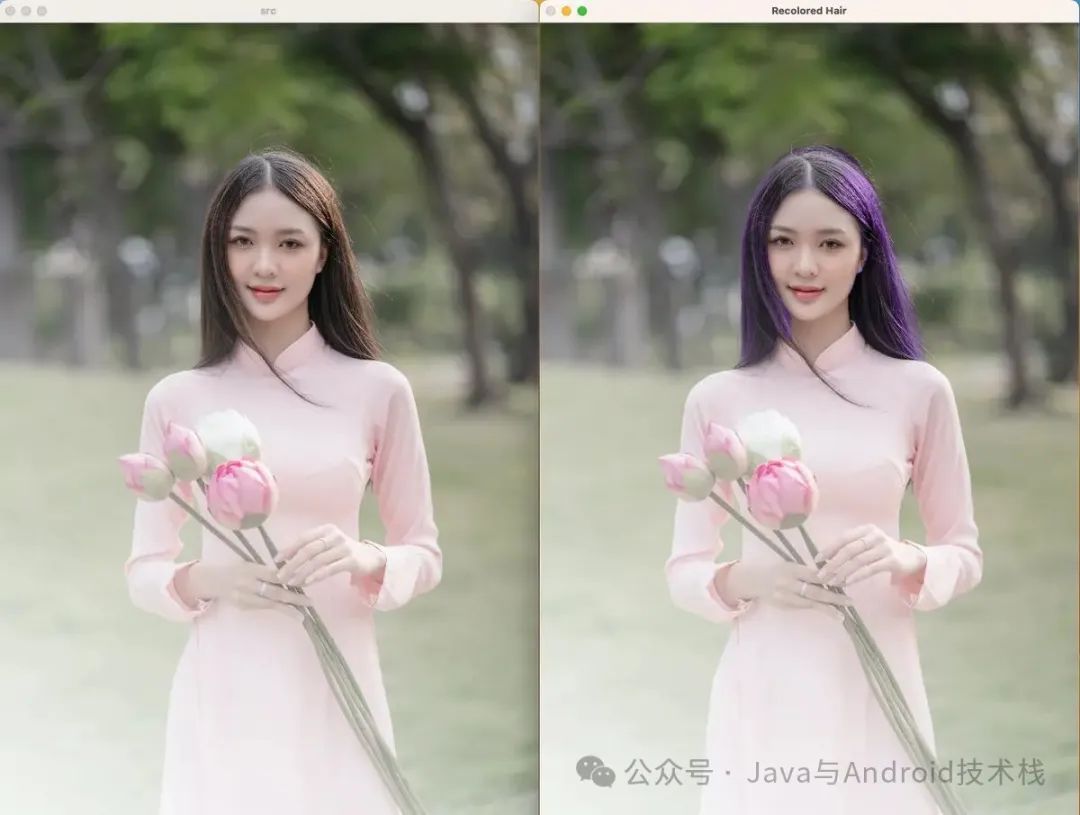
 image.png
image.png
各个模型文件和各个模型调用相关的代码可以在 https://github.com/fengzhizi715/MonicaImageProcessHttpServer 找到。
四. 总结
本文分享了一个完整的发色替换技术方案,基于 MODNet 实现鲁棒的人像前景分割,再借助 Face Parsing 技术精准定位头发区域,最终通过 HSV 空间的色调替换与融合算法,实现自然、真实的发色变化效果,并保留了原始图像的结构和背景信息。
当然, 上述代码也有很多不足之处和优化空间。比如 MODNet 虽然能快速实现人像前景分割,但是在处理多人的场景下效果并不是很好。如果有这种需求的话,可以尝试替换模型。再比如要提升 Face Parsing 的效果,可以使用精度更高的模型。
参考资料:
- https://github.com/ZHKKKe/MODNet
- https://github.com/yakhyo/face-parsing








