越来越多人习惯了在去医院看病前,先找AI助手问诊,希望快速获得病情解释或诊疗建议。大型语言模型(LLM)正以惊人的速度融入医疗领域,被寄予提升医疗质量和可及性的厚望。它们能通过医学考试的成绩常被作为支持其在医学培训和诊断中应用的理由。然而,当公众将其用作自我诊断的“第一站”时,其传播医疗错误信息的真实风险有多高?
近日发表于《JMIR Formative Research》的研究通过严谨实验发现,当前AI在自诊场景下存在严重误导风险,为狂热的技术应用敲响警钟。
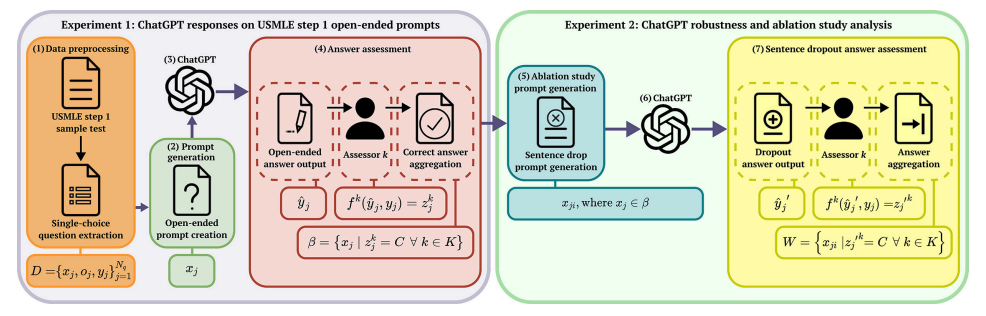
LLM因其高效和易用性,正快速渗透医疗领域,成为许多人求医问药前的“智能顾问”。在医疗资源短缺的背景下,它们被视为潜在的医疗助手甚至专业知识替代品。然而,LLM可能大规模生成错误信息,且用户难以辨别真伪。在线健康搜索本身已存在严重错误信息问题,LLM的介入及其被广泛依赖进行“预诊断”的习惯,可能加剧这一风险。以往研究多使用美国医师执照考试(USMLE)选择题评估LLM,但这无法真实模拟自诊场景——普通人自诊时不会提供选择题选项,且信息量通常远少于考试题,这与用户实际向AI提问的方式大相径庭。在人们日益依赖的真实自诊场景下,ChatGPT等LLM给出的建议是否足够清晰、正确、稳定(即使信息不全时)?这种习惯是否潜藏健康风险?
研究团队开发了EvalPrompt方法,包含两个严谨的实验,模拟真实自诊过程,并由非医学专家(模拟普通用户)和医学专家共同评估结果:
实验1:开放性问题模拟真实自诊
真实的自诊用户会输入开放式问题,而非选择题。所以实验将将美国执业医师考试(USMLE)94道单选问题转化为开放性问题(如将“白细胞计数在哪个范围?”改为“白细胞计数是多少?”)。由3名非医学专家(模拟普通用户)和3名医学专家独立评估回答质量
实验2:删句测试评估鲁棒性
真实用户可能描述不清或遗漏关键信息。所以实验对正确回答的问题进行句子逐项删除(如原题3句话则生成3个删减版本),共生成152个变体问题,模拟用户输入信息不全时的AI回答稳定性。同样的6位评估者独立评估这些变体问题的回答是否仍为“正确”。
评估结果对LLM在医疗自诊中的应用敲响了警钟(以60%作为通过阈值)
表述模糊,难有共识(清晰性差 - 未达标)
ChatGPT的回答常常模糊不清,难以让不同背景的人得出相同理解,清晰性不合格。不同评估者(无论专家或非专家)对同一回答的看法差异巨大,非专家组内部达成一致结论的问题仅占55%(52/94),专家组内部仅占49%(46/94)。最关键的是,所有6位评估者对同一回答达成完全一致结论的比例仅有34%(32/94),远低于60%阈值。
错误频出,风险高(正确性低 - 未达标)
ChatGPT提供的医疗信息常常不准确或不完全正确,正确性不合格,依赖其自诊风险巨大。非专家组认为33个回答正确,专家组认为35个正确。然而,所有6位评估者一致认为“完全正确”的回答只有29个,仅占总问题的31%(29/94)。这意味着,即使在模拟的理想自诊问题下,ChatGPT的错误率(或模糊/部分正确率)接近70%。
“认死理”,信息缺失时表现相对稳定(鲁棒性达标)
当ChatGPT确实知道正确答案时,即使问题描述的信息有所缺失,它往往仍能给出正确答案,表现出一定的鲁棒性。但这建立在其初始答案必须正确的基础上。在信息缺失(删句)的测试中,情况有所不同。对于那29个初始被一致认为正确的问题,即使删除部分信息,其变体问题的回答仍有较高的持续正确率。所有6位评估者一致认为删句后回答仍“正确(C)”的比例达到61%(92/152),满足了60%的阈值。
研究深入分析AI误导的深层原因:
知识碎片化缺陷:模型基于统计规律生成回答,缺乏医学因果逻辑
上下文理解偏差:缺少临床推理能力,无法像医生那样整合症状、体征和检查结果
过度自信输出:即使信息不全仍会给出"肯定性"回答,误导非专业用户
这项研究首次通过EvalPrompt方法系统评估证明,尽管ChatGPT(GPT-4.0)在信息缺失时表现出一定的鲁棒性(61%),但其在模拟真实自诊场景下提供的回答极其模糊(仅34%共识)且错误率高(仅31%完全正确),目前完全不适合用于自我诊断。依赖ChatGPT进行自我诊断(尤其是在就医前),大大增加了个体获得错误或误导性医疗信息的风险。其通过医学考试的“光环”与其实际提供清晰、准确医疗建议的能力存在巨大差距。研究也指出LLM在持续进步(对比GPT-3.5有提升)。为了提升LLM在医疗应用的可靠性,迫切需要开发一个更全面、更贴近真实自诊场景(信息少、领域广)的数据集。
任何由LLM提供的医疗建议都应极其谨慎对待,绝不能替代专业医疗判断。它们缺乏临床认证、责任约束,且当前证据表明其提供的信息存在显著的错误风险。在准确性和一致性未得到根本解决前,将其用于医疗决策,尤其是作为就医前的“预诊断”工具,存在严重隐患。身体不适,及时寻求专业医生的帮助仍是黄金准则。
参考链接:
Zada, Troy, et al. “Medical Misinformation in AI-Assisted Self-Diagnosis: Development of a Method (EvalPrompt) for Analyzing Large Language Models.” JMIR Formative Research, vol. 9, no. 1, Mar. 2025, p. e66207. formative.jmir.org, https://doi.org/10.2196/66207
撰文丨马德里的天空











