南华大学衡阳医学院附属第一医院学者挖掘NHANES(国家健康与营养调查)公共数据库,在《Nutrition Journal》(二区,IF=3.8)杂志发表了一篇基于中介分析与机器学习方法的洞见。
研究旨在探讨膳食炎症指数(Dietary Inflammatory Index, DII)、生物学衰老与心血管–肾脏–代谢(CKM)综合征分期及死亡率之间的关联。这个题目挺有意思的,中介分析与机器学习方法结合,这篇文章是如何设计和撰写的呢?我们一起来看看。
本研究纳入 2005–2018 年 NHANES公共数据库共纳入 7918 名参与者。膳食炎症指数(DII):采用 27 项成分计算 DII。生物学衰老:利用 R 语言包 “BioAge” 根据 8 项生物标志物计算生物学年龄和表型年龄,表型年龄则基于 9 项变量推算而得。
CKM 综合征:CKM 综合征定义为同时存在亚临床或临床心血管疾病(CVD)、慢性肾脏疾病(CKD)和代谢紊乱。通过20余项变量计算而来。并按 CKM 综合征严重程度分为两组:非晚期组(第 0–2 期)和晚期组(第 3–4 期)。
结局指标:包括全因死亡、CVD 死亡和非 CVD 死亡。
目前,NHANES公共数据库的挖掘分析中,基本都要综合指标了,如上述的DII、CKM综合征等,计算相对比较复杂。
如DII,先要找到文献依据,再挖掘27项成分,再对计算方法逻辑梳理,编写代码,计算得到DII指标。
为节省时间,也能保证计算的准确性,不妨使用郑老师团队基于R语言开发的NHANES在线下载和分析平台,这些综合指标已经计算好,可以直接分析,感兴趣的指标也可以和我们说,快马加鞭为您安排!欢迎联系:微信号aq566665获取试用链接。
结果表明,DII 与晚期 CKM 分期呈正相关。多变量Logistic回归显示,与DII最低三分位组相比,中位组和最高组的晚期 CKM 风险显著增加。限制性立方样条分析(RCS)显示 DII 与晚期 CKM 存在线性剂量–反应关系(非线性检验 P=0.41)。2.评估 DII 对 CKM 患者全因死亡率的影响Kaplan–Meier 生存曲线显示,DII最低三分位组全因死亡生存率最高,最高三分位组最低,Log‑rank 检验均 P Cox 回归结果表明,中位和最高三分位组与最低组相比,全因死亡风险分别增加 20%和 45%。并且,DII与全因死亡也呈线性剂量–反应关系(非线性检验 P=0.35)。3.生物学衰老在 DII 与CKM分期、DII 与死亡率关联中的潜在中介作用首先,较高的 DII 水平与更高的生物学年龄和表型年龄显著相关。加速衰老(表型及生物学年龄)均与晚期 CKM 分期及全因死亡显著相关。
中介分析显示:
4.构建八种机器学习模型,对 CKM 分期(第 3/4 期)进行分类及预测全因死亡,结合SHAP方法解析各 DII 组成成分的相对贡献。
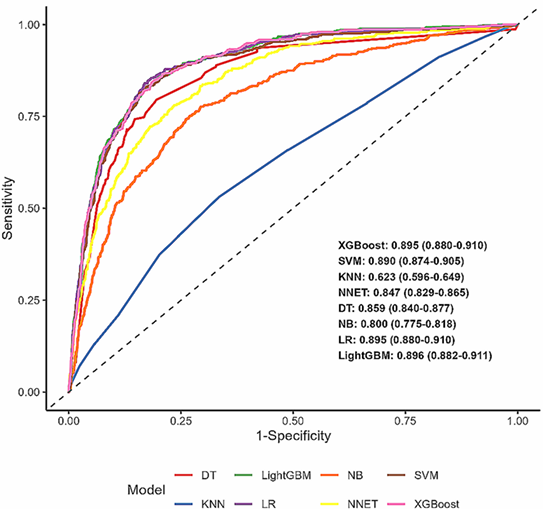
基于验证集的加权集成 SHAP 值排序结果显示:
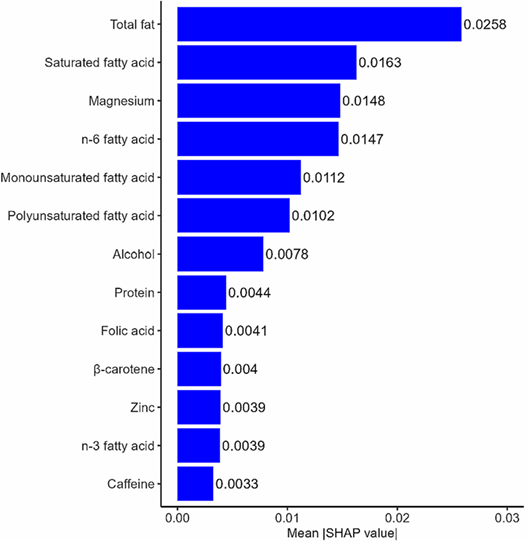
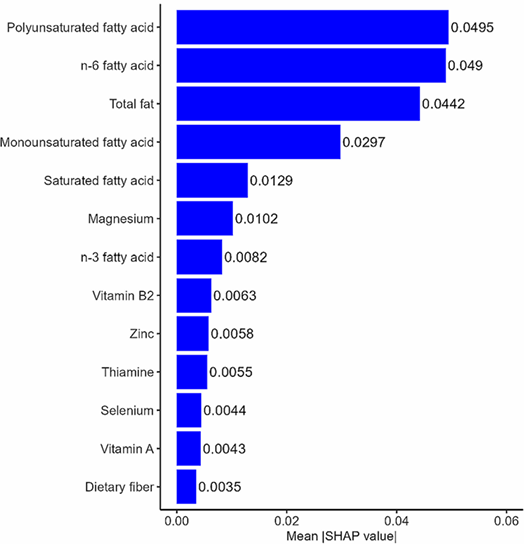
可以看出,这项研究中,中介分析和机器学习是作为两个近乎独立的模块的。这篇文章挖掘NHANES公共数据库,做了很多分析,研究思路清晰,诸位可以看看!参考文献:Ge, J., Zhu, L., Jiang, S. et al. Association of dietary quality, biological aging, progression and mortality of cardiovascular-kidney-metabolic syndrome: insights from mediation and machine learning approaches. Nutr J24, 105 (2025). https://doi.org/10.1186/s12937-025-01175-9
如果您也想模仿这篇文章的思路,郑老师团队可以帮您实现,不妨扫描下方二维码。联系郑老师统计团队。











