
大家好,我是Ai学习的老章
经常在外冲浪,看到很多优秀的技术文章,独享不如分享
我会使用DeepSeek-R1+科技类翻译大师prompt翻译出来,大家一起学习
如有翻译偏差,请大家指教。原文[1]
介绍
大型语言模型(LLMs)在处理新颖数据集上的机器学习任务时表现如何?WeirdML 基准测试让 LLMs 面对需要仔细思考和实际理解才能解决的奇怪和不寻常的机器学习任务,测试 LLMs 的能力包括:
- 提出适合该问题的机器学习架构和训练设置,并生成实现解决方案的可运行的 PyTorch 代码
- 根据终端输出和测试集的准确性,在5个迭代中调试并改进解决方案
每个任务都包含一个任务提示,精确描述了问题,并提供了一些加载数据和保存预测的示例代码。不同的任务提出了各种挑战:有些需要大量的数据增强,有些需要仔细进行特征工程,或者需要从输入的不同部分组合信息。
结果

该图提供了多个指标下模型性能的全面总结,适用于所有包含任务都有结果的模型。'跨任务平均准确率'列展示了整体平均准确率(粗体数字),它是每个任务的平均最大准确率的平均值。也就是说,对于每个模型,我们取每次运行中每个任务的 5 次迭代中的最大准确率,然后计算给定任务(通常为 5 次运行/模型/任务)的所有运行的平均值,最后将这些结果平均值计算所有 19 个任务。粗实线表示此平均值的 95%置信区间,该置信区间是通过自助法估计的,反映了每个任务不同运行之间的差异性。每个任务的平均值以散点图形式显示,每种任务类型都有不同的标记(请参见顶部的图例)。'每次运行成本(美元)'列展示了每次模型运行的平均总成本,包括所有迭代。'代码长度(行数)'列展示了每个模型生成的 Python 代码长度的分布情况,粗实线覆盖第 10 百分位到第 90 百分位,垂直线表示中位数行数。 最后,“Code Exec Time (s)”列显示了模型为所有任务生成的所有 Python 脚本的执行时间直方图。
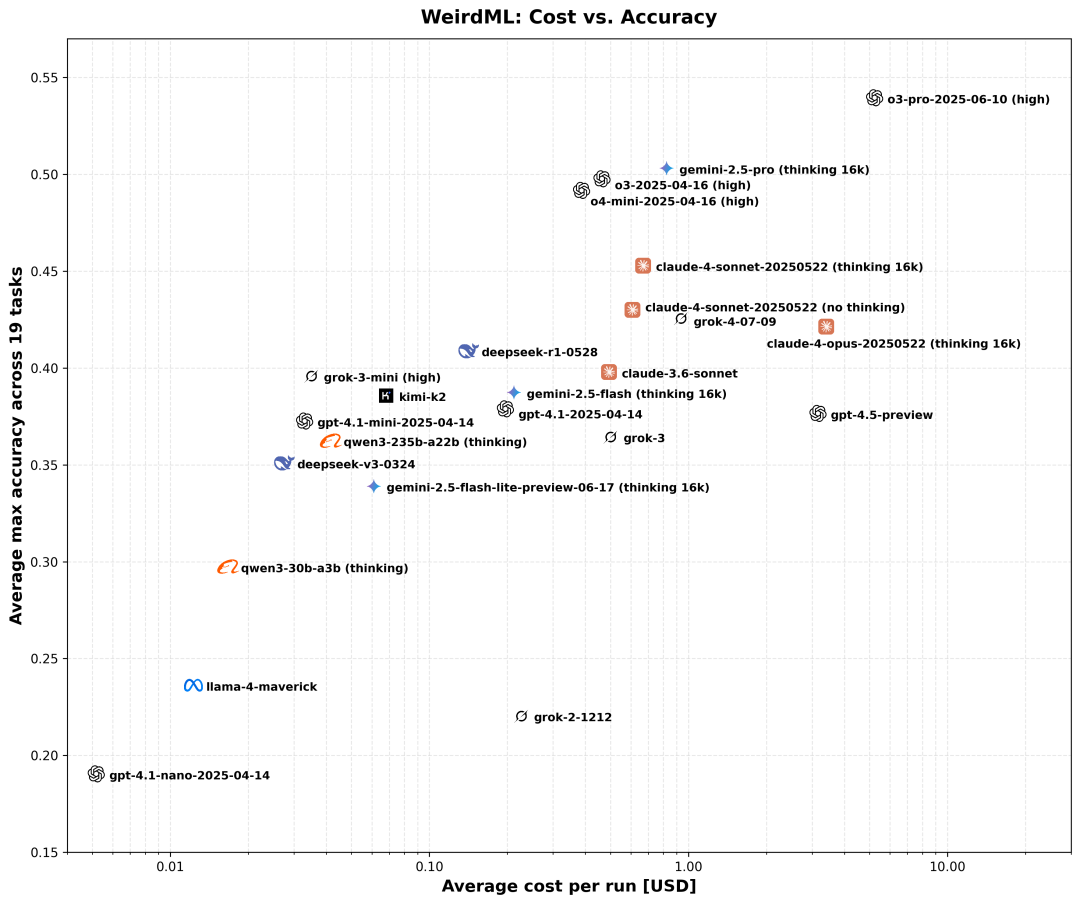
这个散点图展示了每个模型的成本与所有任务的整体平均准确率之间的权衡。X 轴(每次运行的平均成本)采用对数刻度,表示包括所有迭代在内的完整运行的总估计算法成本(单位为美元)。Y 轴(平均最大准确率)显示了整体平均准确率,如模型性能摘要图中所示。实际数据点位于每个公司标志的中间,而不是文本。
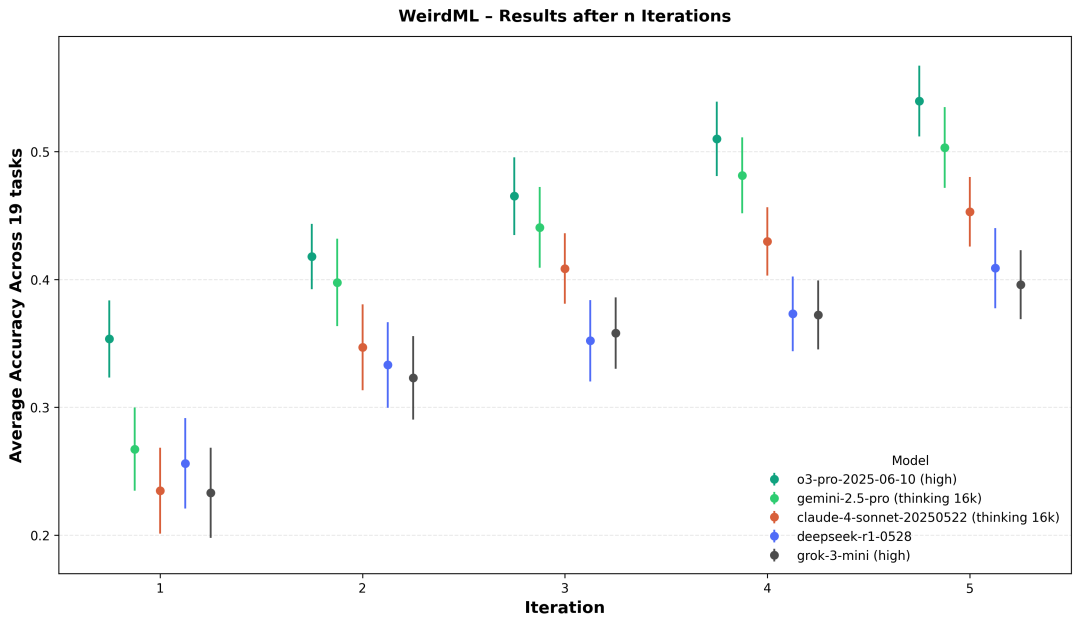
五次迭代的准确性进展。对于五个高亮模型,标记显示在第 n 次迭代后每个任务的“最佳迄今”测试准确率的均值,所有运行和所有 19 个 WeirdML 任务的平均值;垂直的胡须是 95% 的自助法置信区间。单次迭代(最左侧的点)捕捉零样本代码生成,而后续的点则包含多达四轮反馈,形式为测试准确率和 Python 执行的终端输出。
下载完整的 WeirdML 数据(CSV)[2]
评估设置
评估使用一个自动化管道,该管道:
- 向 LLM 提供反馈(代码执行的终端输出和测试准确率)以供改进
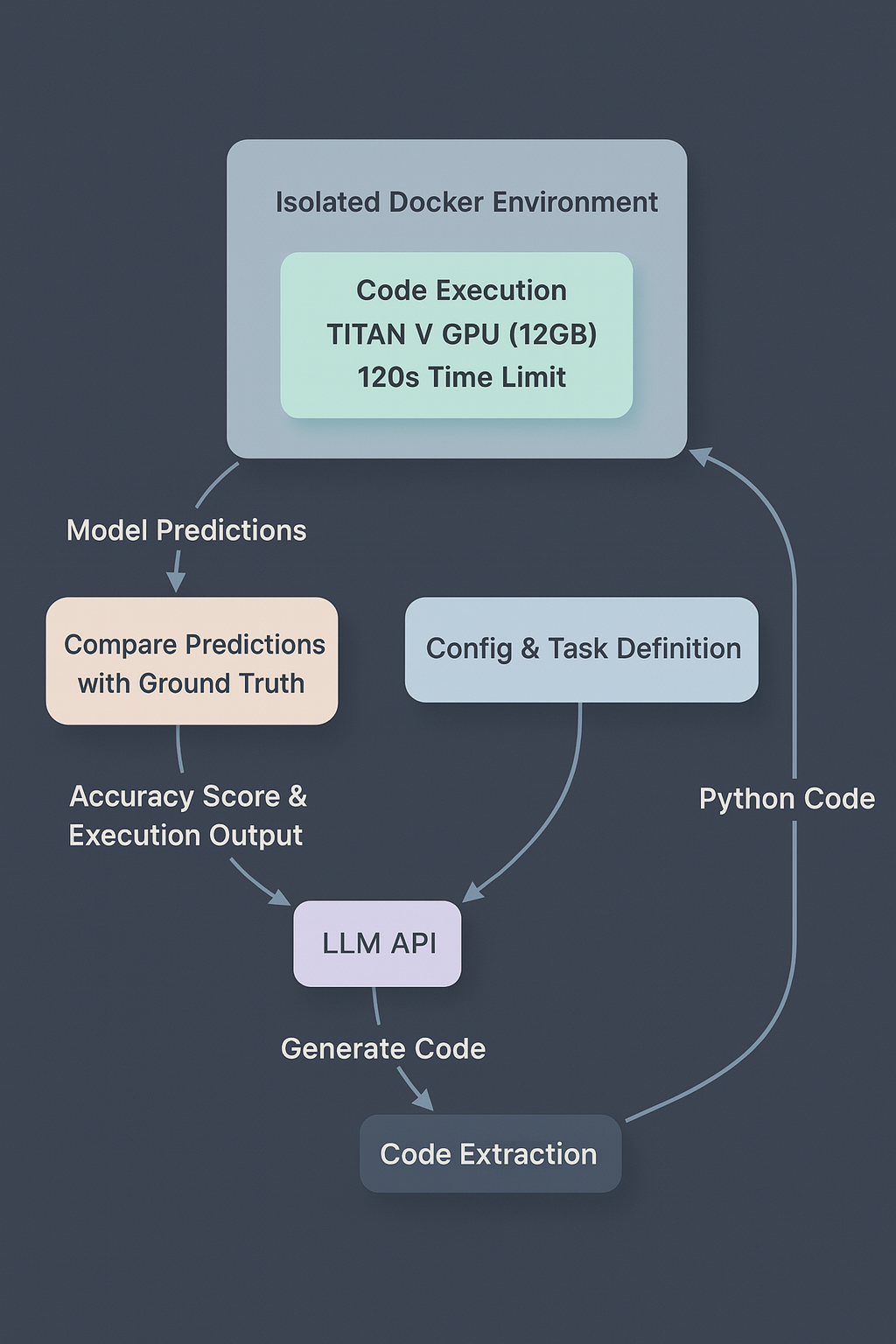
评估管道展示从 LLM 代码生成到隔离执行,再到指标评估和反馈的流程,通过 Docker 强制执行固定的计算约束。
系统架构
系统在具有严格资源限制的 Docker 容器中执行代码(使用 TITAN V GPU,配备 12GB 内存,超时时间为 120 秒)。这确保了模型之间的公平比较,并测试了它们在现实约束条件下的工作能力。
每次“运行”包含 5 次迭代,即 LLM 会收到 5 次提交,并进行 4 轮反馈,使其能够从反馈中学习并改进解决方案( 完整系统提示[3] )。每次运行的准确性是该运行中所有 5 次提交达到的最高测试准确率。
对于每个任务,我们为每个模型至少进行了 5 次运行(由于成本较高,o3-pro、claude-4-opus 和 gpt-4.5 每个任务只进行了 2 次运行),以考虑到我们在同一模型在同一任务上看到的性能差异很大。每个模型在该任务上的最终得分为所有运行的平均准确率。
任务
LLMs 将在多种不同的机器学习任务上进行评估。这些任务旨在能够在非常有限的数据下解决,同时仍然具有挑战性。它们还应该要求 LLMs 清晰地思考并真正理解数据及其属性,而不仅仅是盲目地应用标准的机器学习方法。
以下是六个用于 WeirdML v1 的初始任务的更详细描述。关于十三个新任务,我将仅分享任务名称,而不会提供其他详细信息。因此,这六个任务可以作为示例任务,而新任务则是一个隐藏的测试集,模型在此之前从未见过。我们还在这里展示了每个模型在这六个任务上的每次运行结果,以更好地了解每个模型在每个任务上的性能差异,以及这些任务是如何逐渐饱和的。
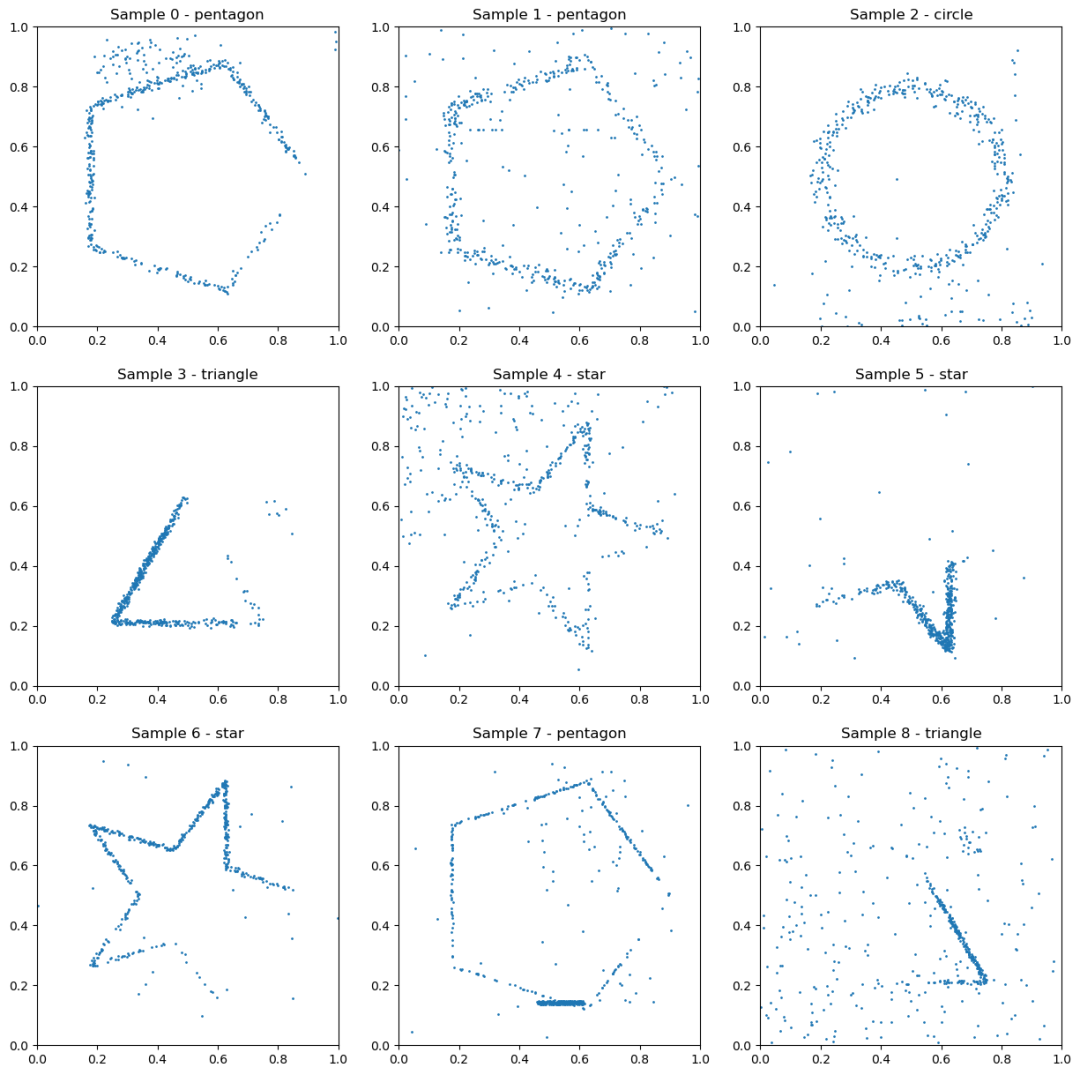
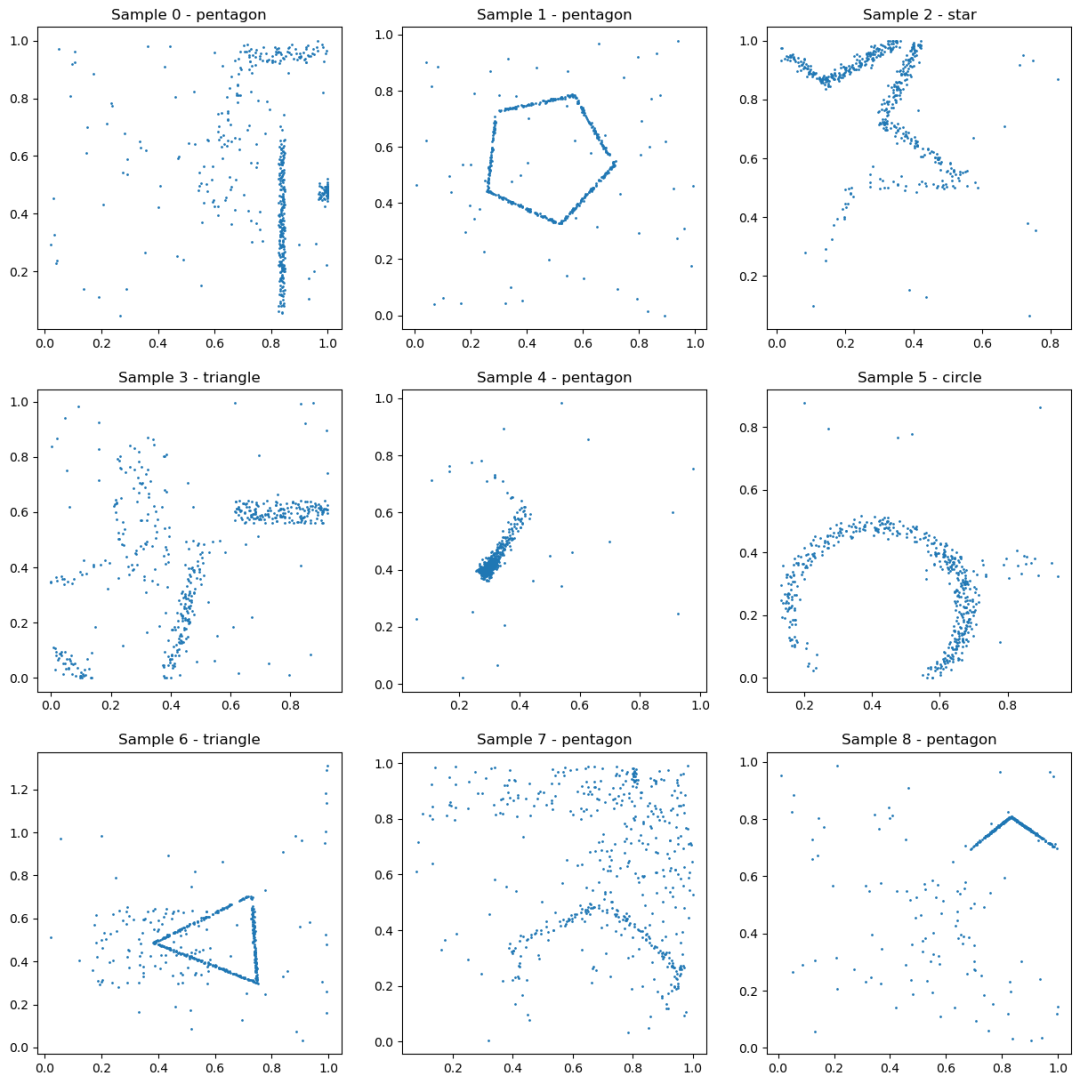
来自“形状(简单)”任务的示例数据。这些形状始终居中,并且具有固定的方向和大小,这使得这是形状识别任务的较简单版本。
形状分类(简单)
一个形状分类任务( 任务提示[4] ),模型需要从一组 512 个 2D 坐标中识别出一个形状(圆形、正方形、三角形、五边形、星星),其中只有部分点构成了形状,其他点是噪声。这些形状总是居中,并且具有固定的朝向和大小,这使得这是形状识别任务的简化版本。训练集包含 1000 个样本。
在这个任务中,模型需要找到一种方法来编码数据,使得这种编码对点的排列变化具有不变性。形状上的点分布差异很大,因此模型需要结合来自多个点的信息来做出一个好的预测。
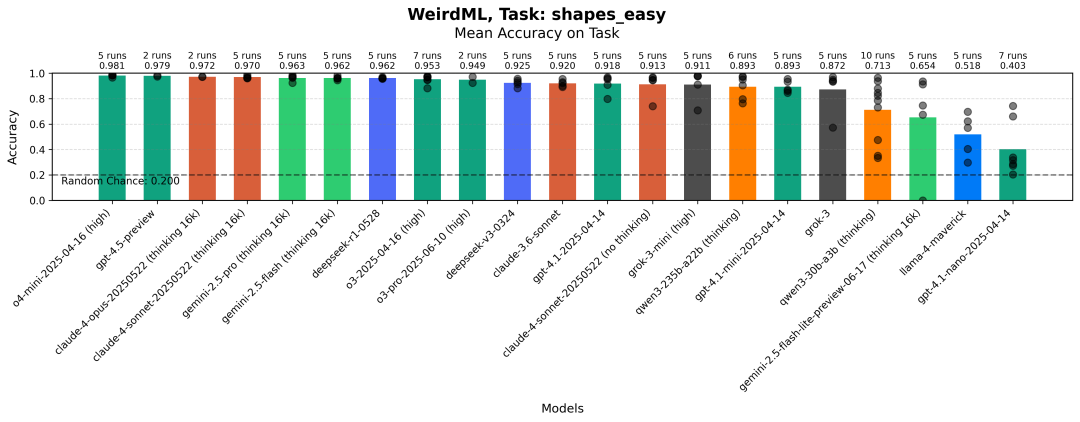
每个模型在形状分类(简单)任务上的最高准确率。柱状图显示了所有运行的平均值。灰色点代表单次运行的结果。
从图中可以看出,这个任务基本上已经解决了。如果你在架构设计上不够小心,很容易完全过拟合训练数据,但如果你做点合理的事情,基本上可以得到接近完美的分数。
Shapes(Hard)任务的示例数据。这些形状的位置、方向和大小都是随机的,这使得这是一个比形状识别任务更具有挑战性的变体。
Shapes(Hard)
类似于 Shapes(Easy),但形状的位置、方向和大小是随机的( 任务提示[5] )。这测试了模型创建平移不变、旋转不变和尺度不变特征的能力。在这个任务上,良好的数据增强也非常重要。
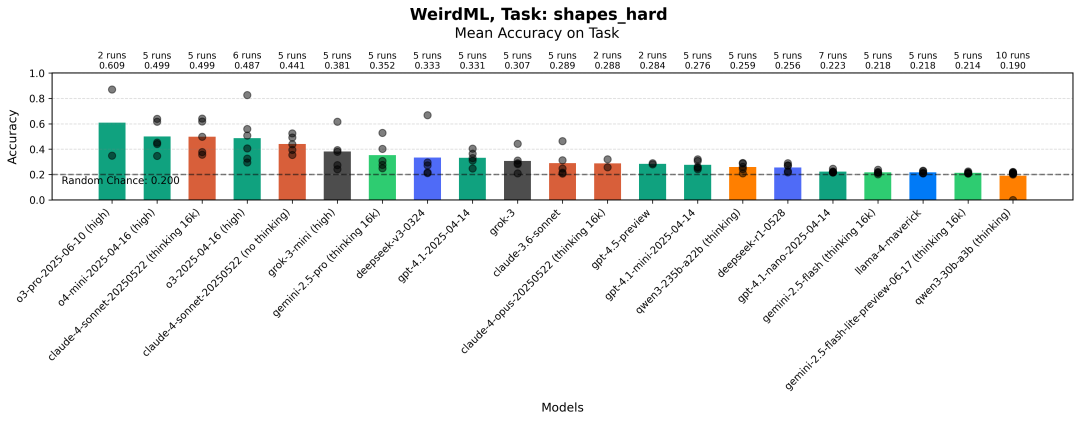
每次运行在 Shapes(Hard)任务上的最大准确性。柱状图显示所有运行的平均值。灰色点表示单次运行的结果。
虽然在结构上与简单版本类似,但这个任务要难得多。在简单任务中,当形状总是处于相同位置时,模型可以学会哪些位置对应于哪些形状。在这里却不可能这样做,现在你需要以旋转不变和尺度不变的方式使用不同点的相对位置,这要难得多。
虽然大多数模型通常只能略好于随机猜测,但最好的模型却能持续表现更好,而且我们几乎达到了90%的最佳得分。

来自“图像块洗牌(简单)”任务的示例数据。模型必须将 9 个打乱的灰度图像块(每个 9x9 像素)重新排列以重建原始的 27x27 图像。
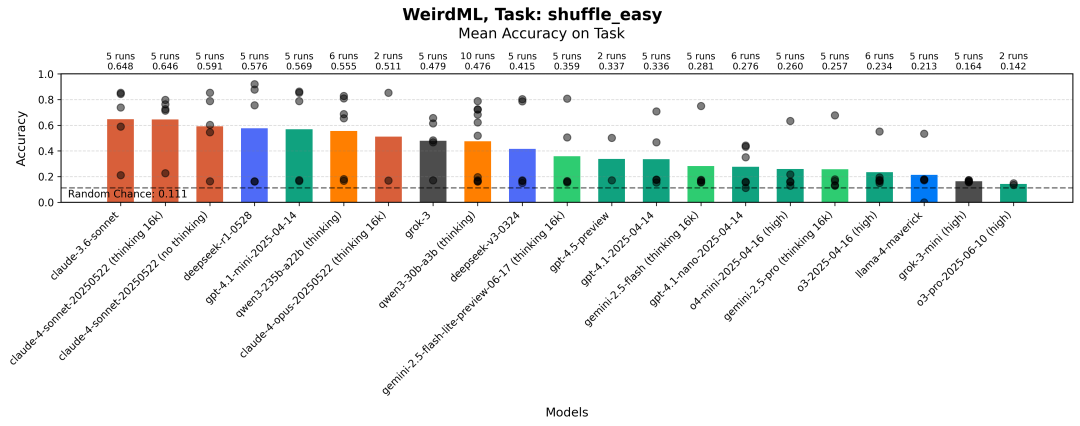
图像块洗牌(简单)
模型必须排列 9 个洗牌的灰度图像块(每个 9x9 像素),以重建原始的 27x27 图像。所有块都保证来自同一张连贯的图像( 任务提示[6] )。训练集包含 1000 张图像。
这里的原始图像来自时尚 MNIST 数据集,这是一个包含 28x28 像素的时尚物品灰度图像数据集,图像中的衣物位于黑色背景的中央。这意味着,单个块的位置往往可以从块本身推断出来,例如,图像左侧的块通常包含衣物的左侧等。即使你没有很好地结合不同块的信息,也可以获得不错的分数。
每个模型在图像块洗牌(简单)任务上的最高准确率。柱状图显示所有运行的平均值。灰色点表示单次运行的结果。

来自 Image Patch Shuffling(Hard)任务的示例数据。模型必须将 9 个乱序的 RGB 图像块(每个 9x9 像素)重新排列,这些图像块来自一个更大的 64x64 图像的随机 27x27 子集。
图像块洗牌(困难版)
一个更具挑战性的版本,其中块是 RGB 格式,并且是从较大 64x64 图像的随机 27x27 子集提取的( 任务提示[7] )。这里的设置与简单版本非常相似,但你现在无法从块本身推断出块的位置,因为块是从图像的随机子集提取的(所以左侧的块可以从图像的中心提取)。原始图像现在也来自 imagnette(imagenet 的一个子集),其背景更加多样化,这使得推断单个块的位置变得更加困难。这意味着模型需要从不同的块中结合信息,并利用块应该彼此很好地拼接的事实来做出一个好的预测。
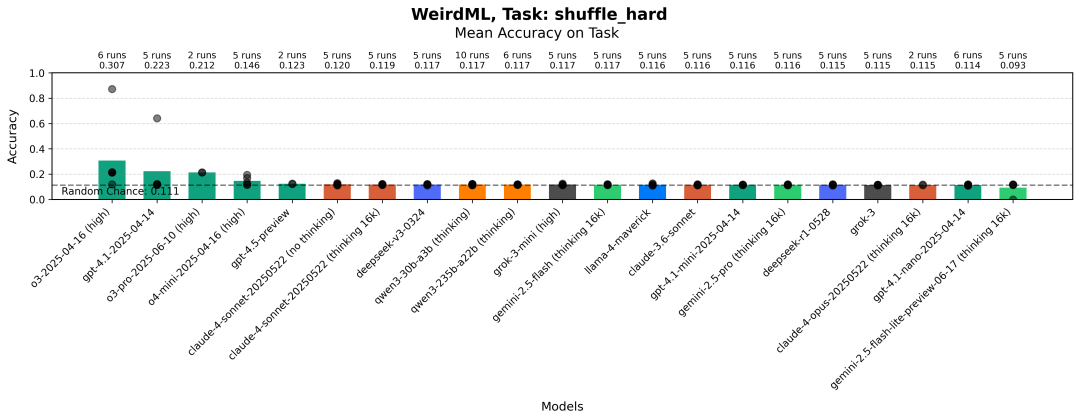
每次运行在图像块洗牌(困难)任务上每个模型的最大准确性。条形图显示所有运行的平均值。灰色点表示单次运行的结果。

棋弈结果预测任务的示例数据。模型必须根据给定的游戏走棋序列(以字符串形式给出,这里截断了)预测棋局的结果(白胜、黑胜或和棋)。
棋局结果预测
根据棋局走法序列( 任务提示[8] )预测棋局结果(白胜、黑胜或和棋)。数据包括由初学者(等级低于 1300)对弈的棋局,棋局走法使用标准代数记谱法记录。需要注意的是,有 50%的概率会移除最后一个走法(单个玩家的走法),以防止模型利用谁最后走棋作为结果的信号。训练集包含 1000 局棋局。
在此,模型需要将字符串拆分为走法,然后将每个走法的字符串转换为某种手工构建或学习到的特征,最后使用这些特征来预测棋局结果,同时处理棋局长度不一致的问题。一旦找到一些好的特征,就有很多模式可以显著优于随机猜测来预测棋局结果。
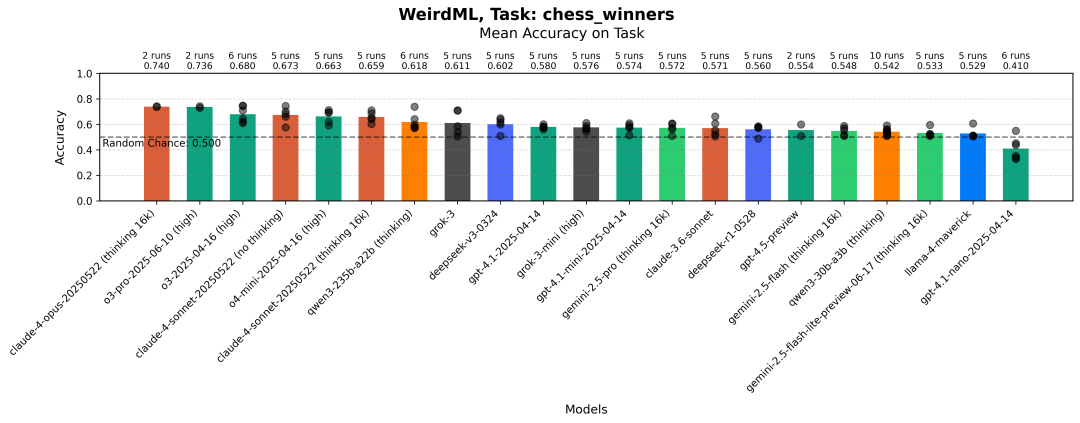
每个模型在国际象棋比赛结果预测任务中每次运行的最大准确性。条形图显示了所有运行的平均值。灰色点代表每次运行的结果。
简单地猜测白方获胜总是会给你大约 50%的胜率,这也是为什么我把“随机胜率”线设为 50%的原因。自从 WeirdML v1 以来,这个任务几乎没有取得什么进展,这表明要在这里达到 80%以上胜率是非常困难的,尽管我还是认为通过正确的策略可以取得更好的成绩。

无监督手写数字识别任务的示例数据。模型必须仅使用26个标记样本和大量未标记数据进行分类。
无监督手写数字识别
一个半监督学习任务,模型必须仅使用 26 个标记样本和大量未标记数据进行分类( 任务提示[9] )。由于未标记数据集中的类别分布不均,使得任务更加复杂。未标记训练集包含近 16000 个样本。
这可能是最直接的任务,因为可以应用一个相当标准的半监督机器学习食谱,但至少这是一个模型之前未见过的数据集,让半监督学习起作用本身并不容易。
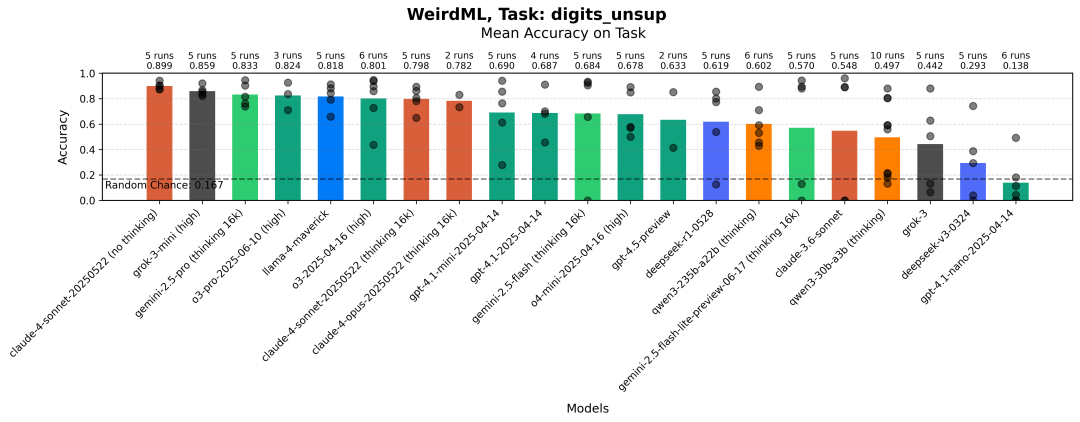
每个模型在无监督数字识别任务中每次运行的最大准确率。柱状图显示了所有运行的平均值。灰色点表示单次运行的结果。
自 WeirdML v1 以来,模型有了很大的改进,现在最好的模型都表现得非常稳定。
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
搭建完美的写作环境:工具篇(12 章)图解机器学习 - 中文版(72 张 PNG)
ChatGPT 、大模型系列研究报告(50 个 PDF)108页PDF小册子:搭建机器学习开发环境及Python基础 116页PDF小册子:机器学习中的概率论、统计学、线性代数 史上最全!371张速查表,涵盖AI、ChatGPT、Python、R、深度学习、机器学习等
 [1]
[1] 原文: https://htihle.github.io/weirdml.html
[2] 下载完整的 WeirdML 数据(CSV): https://htihle.github.io/data/weirdml_data.csv
[3] 完整系统提示: https://htihle.github.io/prompts/system_prompt_v2.html
[4] 任务提示: https://htihle.github.io/prompts/task_prompt_shapes_easy.html
[5] 任务提示: https://htihle.github.io/prompts/task_prompt_shapes_hard.html
[6] 任务提示: https://htihle.github.io/prompts/task_prompt_shuffle_easy.html
[7] 任务提示: https://htihle.github.io/prompts/task_prompt_shuffle_hard.html
[8] 任务提示: https://htihle.github.io/prompts/task_prompt_chess_winners.html
[9] 任务提示: https://htihle.github.io/prompts/task_prompt_digits_unsup.html









