这篇文章将使用 TensorFlow 构建一个卷积神经网络 (CNN):创建相同的简单图像分类器来预测给定图像是否为“X”。
步骤 1:导入库
import tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Densefrom tensorflow.keras.optimizers import Adamimport numpy as npimport matplotlib.pyplot as plt
为了确保每次运行代码时的结果一致,我们将设置一个随机种子,设置种子可以确保代码中的随机过程每次都以相同的方式运行,从而确保结果的一致性。这就像我们每次玩牌时都以完全相同的顺序洗牌一样。
np.random.seed(42)tf.random.set_seed(42)
第 2 步:理解和生成数据
首先,我们来生成模型需要学习分类的图像。
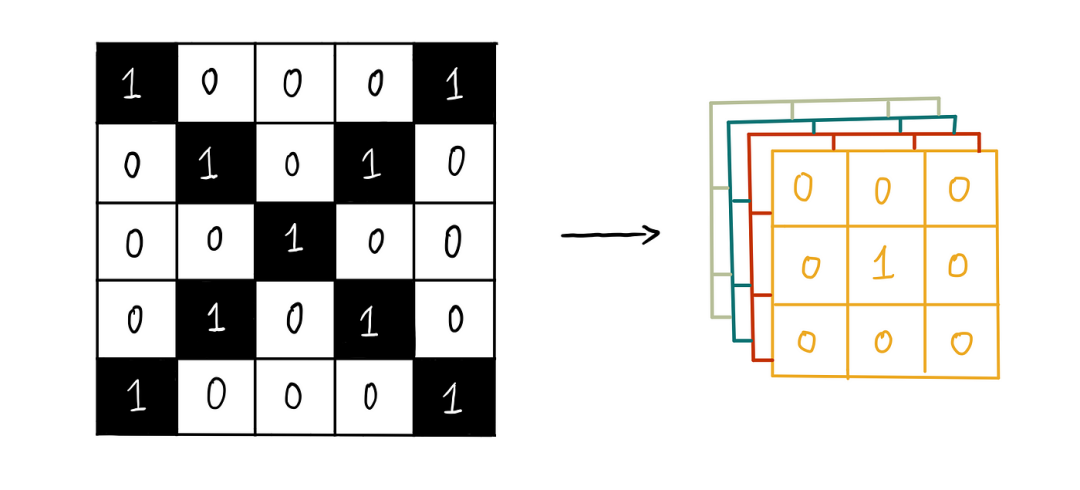
之前我们看到,一个“X”可以用一个 5×5 像素的图像来表示,如下所示:
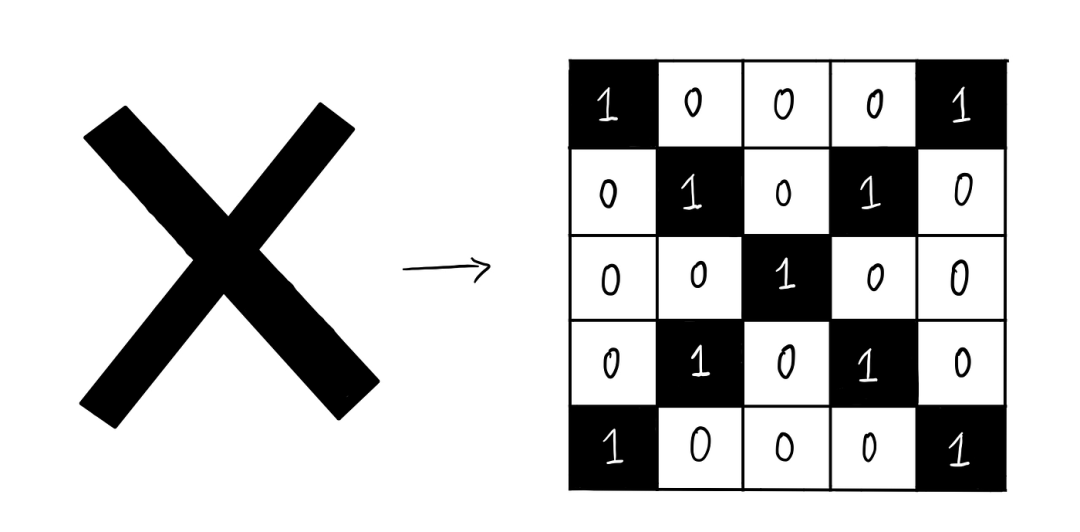
让我们将其翻译成代码:
# 'X' patterndef
return np.array([
[1, 0, 0, 0, 1],
[0, 1, 0, 1, 0],
[0, 0, 1, 0, 0],
[0, 1, 0, 1, 0],
[1, 0, 0, 0,
1]
])
此函数生成一个简单的 5×5 的“X”图像。接下来,我们将创建一个函数,用于生成不类似于“X”的随机 5×5 图像:
def generate_not_x_image(): while True: img = np.random.randint(2, size=(5, 5)) if not np.array_equal(img, generate_x_image()): return img
步骤3:构建数据集
函数准备就绪后,我们现在可以创建一个包含 1,000 张图片的数据集。我们会对它们进行相应的标记,包含“X”的图片标记为 1,不包含“X”的图片标记为 0:
num_samples = 1000images = []labels = []
for _ in range(num_samples): if np.random.rand() > 0.5: images.append(generate_x_image()) labels.append(1) else: images.append(generate_not_x_image()) labels.append(0)
images = np.array(images).reshape(-1, 5, 5, 1)labels = np.array(labels)
这段代码生成了 1000 张图像,其中一半包含“X”,另一半不包含。
然后,我们重新调整图像的尺寸,以确保它们的尺寸适合我们的 CNN。
为了有效地训练我们的模型,我们将此数据集分为训练集和测试集:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split( images, labels, test_size=0.2, random_state=42)
这种划分保留了 80% 的数据用于训练模型,20% 的数据用于测试模型。测试集可以帮助我们评估模型在新的、未见过的数据上的表现。
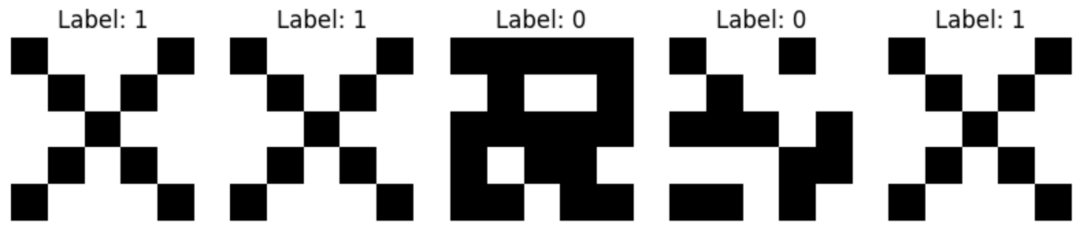
在深入研究模型构建之前,让我们先看一下数据集中的某些图像,以了解我们正在处理的内容。
def display_sample_data(images, labels, num_samples=5): plt.figure(figsize=(10, 2))
for i in range(num_samples): ax = plt.subplot(1
, num_samples, i + 1) plt.imshow(images[i].reshape(5, 5), cmap='gray_r') plt.title(f'Label: {labels[i]}') plt.axis('off')
plt.show()
该函数显示来自我们训练集的图像,帮助我们确认数据是否正确标记和格式化。
display_sample_data(x_train, y_train)
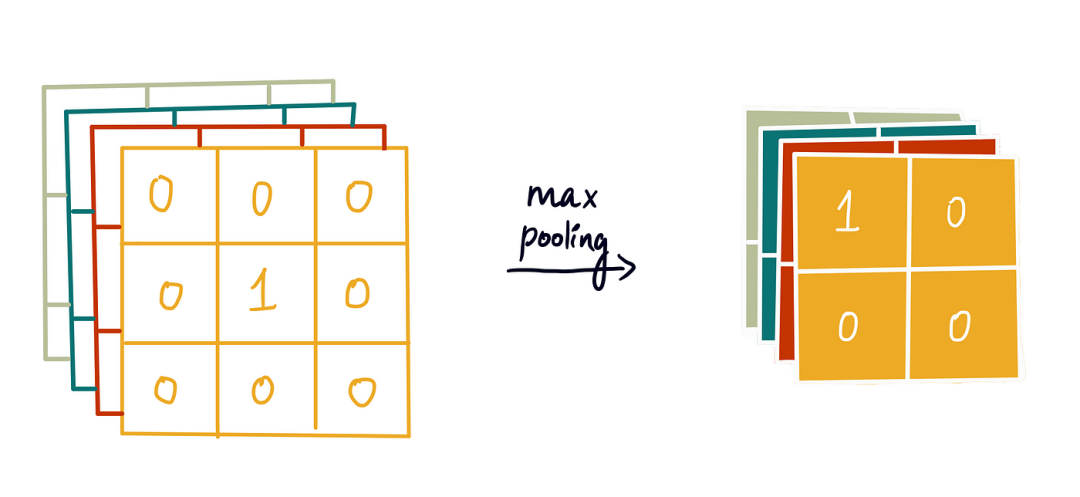
步骤4:构建CNN模型
现在我们的数据已经准备好了,让我们来构建 CNN:
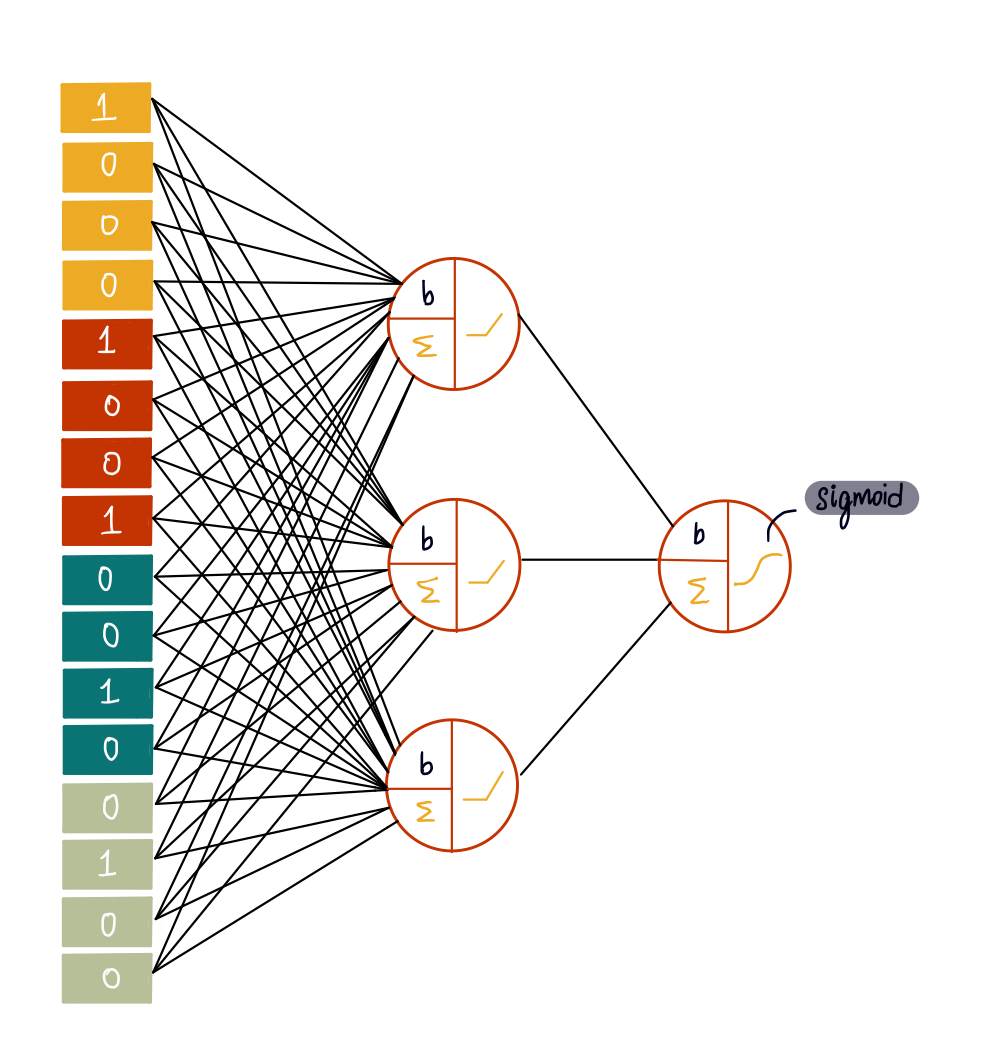
1)卷积层:
将四个 3×3 过滤器应用于输入图像以检测特征并创建四个特征图。
2)最大池化层:
减少特征图的尺寸,使模型更高效。
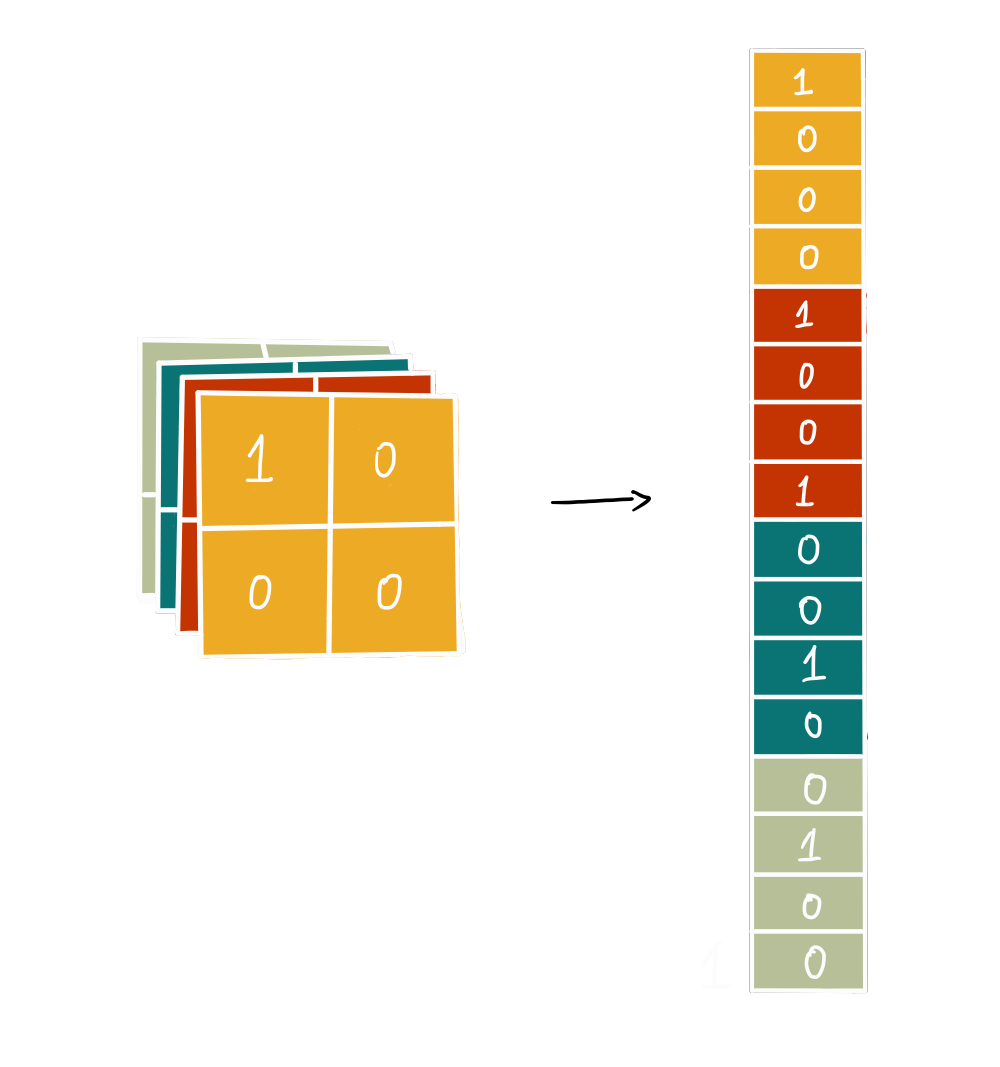
3)Flatten Layer:
将二维数据转换为一维数组,为神经网络做好准备。
4)隐藏层:
一个完全连接的隐藏层,具有三个神经元,均具有 ReLU 激活函数。
5)输出层:
具有 S 型激活函数的单个神经元。
模型代码如下:
model = Sequential([ Conv2D(4, (3, 3), activation='relu', input_shape=(5, 5, 1)),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(3, activation='relu'),
Dense(1, activation='sigmoid')])
步骤5:编译模型
编译模型至关重要,因为它定义了模型的学习方式。以下是编译函数各部分的功能:
1.优化器(Adam):
优化器调整模型的权重,以最小化损失函数。我们在这里使用Adam,但这里列出了其他可用的优化器。
2.损失函数(二元交叉熵):
衡量模型预测与实际结果的偏差。由于我们处理的是二元分类(X 或非 X),因此二元交叉熵比较合适。损失值是模型在训练过程中试图最小化的值。损失值越低,性能越好(即模型的预测值越接近实际值)。损失直接影响模型的训练方式,优化器会利用它来更新模型的权重,以最小化损失。
3.指标(准确率):
指标用于评估模型的性能。我们使用准确率来追踪所有预测中正确预测的比例。指标是评估模型性能的附加指标,但优化器不会在训练期间使用这些指标来调整模型。它们提供了一种评估模型性能的方法。
注意:虽然准确率是一个常用指标,但它并不总是最可靠的,尤其是在数据集不平衡等特定场景下。
model.compile( optimizer=Adam(), loss='binary_crossentropy', metrics=['accuracy'])
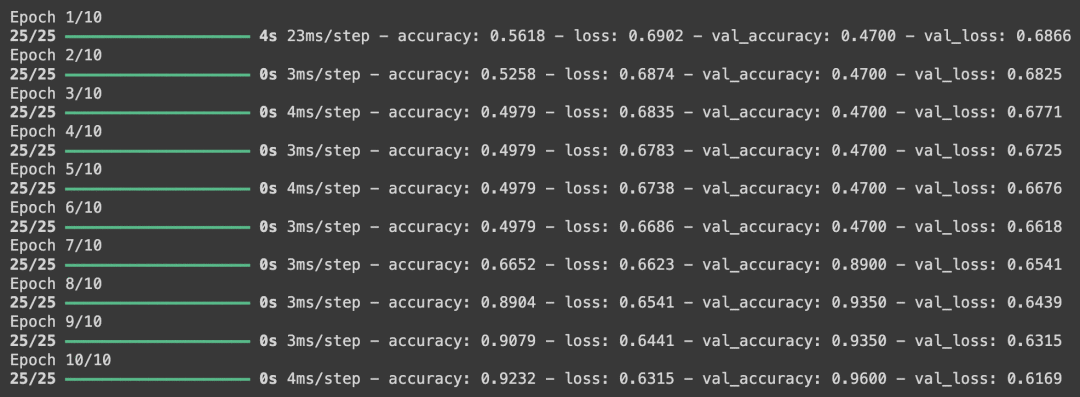
步骤6:训练模型
训练模型需要多次(epoch)输入训练数据,以便模型能够学习做出更准确的预测。
一个epoch指的是对整个训练数据集进行一次完整的遍历。我们将训练模型10个epoch:
history = model.fit( x_train, y_train, epochs=10, validation_data=(x_test, y_test))
步骤 7:评估模型
训练结束后,我们在测试数据上评估模型的性能:
loss, accuracy = model.evaluate(x_test, y_test)print(f'Test Accuracy: {accuracy * 100:.2f}%')

准确度指标告诉我们,测试数据中 94.8% 的图像被正确分类。
步骤 8:可视化训练过程
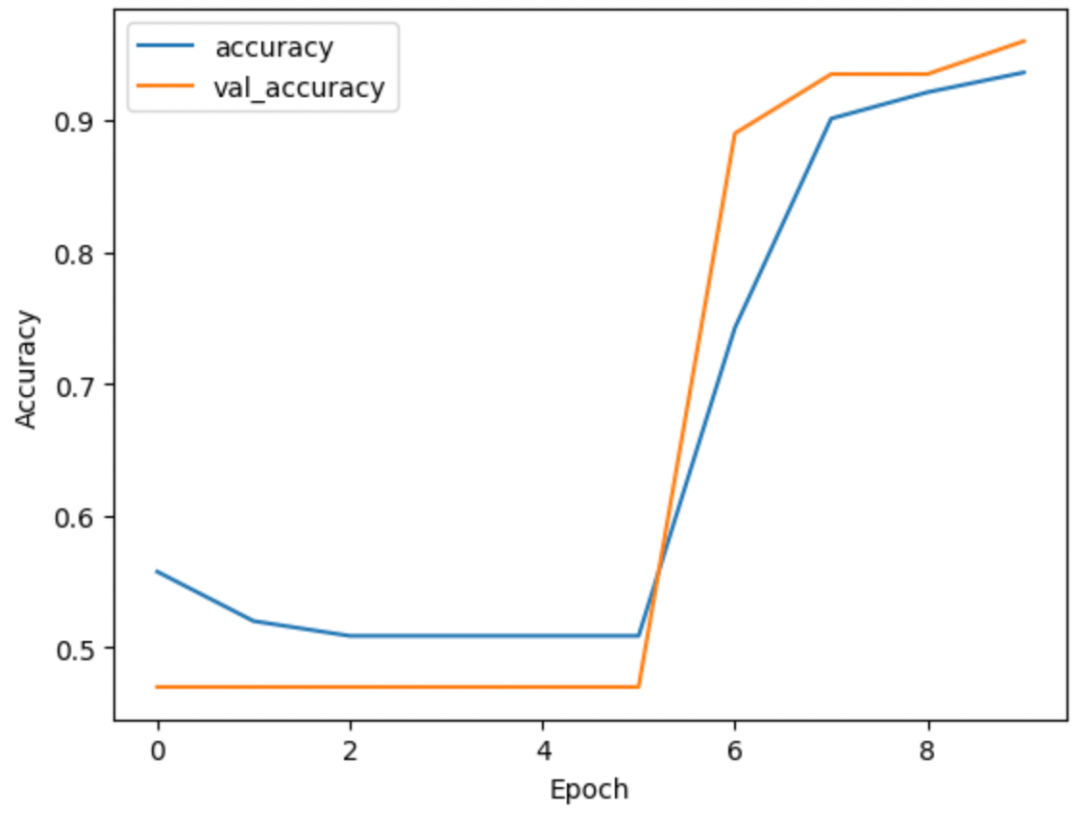
最后,让我们可视化一下模型准确率在各个时期的变化情况。这有助于我们了解模型在训练过程中的学习效果:
plt.plot(history.history['accuracy'], label='accuracy')plt.plot(history.history['val_accuracy'], label='val_accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.show()
https://medium.com/@shreya.rao/list/deep-learning-illustrated-ae6c27de1640











