
团队介绍:
本文由北京大学助理教授李萌课题组和蚂蚁技术研究院、蚂蚁密算的多位研究者共同推出,从隐私保护机器学习模型、协议和系统的三个层面,对高效隐私保护机器学习领域进行总结和展望。

引言:首篇跨层级高效隐私保护机器学习综述
在数据隐私日益重要的AI时代,如何在保护用户数据的同时高效运行机器学习模型,成为了学术界和工业界共同关注的难题。北大×蚂蚁团队最新完成的综述《
Towards Efficient Privacy-Preserving Machine Learning: A Systematic Review from Protocol, Model, and System Perspectives》系统性地梳理了当前隐私保护机器学习(PPML)领域的三大优化维度,首次提出跨协议、模型和系统三个层级的统一视角,为学术界和工业界提供了更加清晰的知识脉络与方向指引。
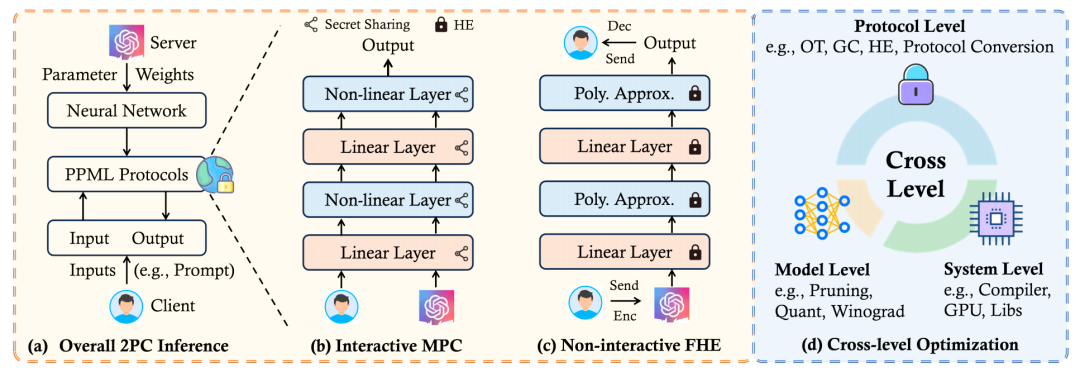
文章的总体结构如下:
层级一:协议层级优化
尽管密码学协议为数据隐私保护提供了严格的安全保证,但其应用于人工智能计算,仍面临巨大开销。本综述指出当前协议设计主要存在以下核心痛点:
1)基于不经意传输(OT)的协议有极高的通信开销和基于同态加密(HE)的协议面临严重计算瓶颈;
2)现有协议忽视模型固有的结构特性(如稀疏性、量化鲁棒性),因此缺乏“模型感知”的协议设计。
本综述分别从人工智能模型的线性算子和非线性算子切入,主要讨论了基于OT和HE的协议设计和发展脉络。综述中重点回答了在不同场景中,应该使用何种协议以及HE编码方式。综述还分析了在交互式和非交互式协议框架下的图级协议,比如秘密分享和HE之间的转换、全同态中的自举方案。以下是关于编码方案的总结:
层级二:模型层级优化
本综述强调在传统明文机器学习模型中的设计(如
ReLU剪枝、模型量化)在PPML中往往会导致高昂代价。综述系统地归纳了当前PPML领域的四类模型层优化策略:
1)线性层优化:比如高效卷积设计、低秩分解、线性层融合;
2
)非线性层ReLU和GeLU优化:比如多项式近似、剪枝和GeLU的替换;
3)非线性层Softmax优化:比如昂贵算子的替换、
KV cache剪枝、注意力头融合;
4)低精度量化,包括OT和HE友好的量化算法。下表概括了线性层和非线性层的优化方案:
层级三:系统层级优化
本综述指出,即便协议和模型层级已经得到优化,系统层级若无法“感知协议特性”,将难以释放真正性能。综述中梳理了两个方向的优化路径:1)编译器设计:从协议特性感知、灵活编码、Bootstrapping支持等方面展开了讨论;2)GPU设计:分别讨论了操作层面加速与PPML系统层面的优化,通过对比现有
GPU加速实现中典型PPML工作负载的执行时间,对相关技术进行了总结。下图是HE编译器的梳理:
下表对比了GPU加速的HE框架:
总结与讨论
本综述强调,仅仅在某一层级优化已难以满足大模型时代对隐私与效率的双重要求。综述提出必须从“跨层级协同优化”的角度重新设计PPML的方案,未来的研究方向包括:
1)协议
-模型-系统协同优化和设计;
2)构建面向大模型隐私推理的隐私计算方案;
3)面向边缘设备部署的轻量化隐私计算方案。值得一提的是,李萌老师课题组近年来围绕上述层面,与蚂蚁集团开展了一系列相关研究工作。
综述详细讨论了跨层级优化带来的挑战与机遇,分别阐述了模型和协议的系统优化、协议和系统的系统优化。例如模型量化难以直接给
PPML带来期望的收益,非线性层优化难以带来系统级的效率提升,现代GPU加速了明文机器学习,但其有限的精度支持给HE所需的高精度模块化算术带来了挑战。
综述还进一步从线性层和非线性层角度讨论了大模型对PPML的独特挑战,并提出除了无需训练的优化方式,还可以考虑用参数高效微调(比如LoRA)等技术去构建PPML
友好的大模型结构。
> 写在最后 <
原文链接:https://arxiv.org/pdf/2507.14519
团队还建立了一个长期维护的GitHub项目,持续收录高质量PPML文献,欢迎大家star,并提出宝贵的意见和补充:
https://github.com/PKU-SEC-Lab/Awesome-PPML-Papers











