当我们学会识别一张人脸时,大脑中成千上万的神经元之间形成了特定的连接模式。这些连接的强度和方向就是我们"学到的知识"。在深度学习中,模型参数就扮演着同样的角色。
模型参数是神经网络在训练过程中自动学习到的内部变量,它们存储着模型从数据中提取的所有知识和模式。就像经验丰富的医生能够通过多年的临床实践积累诊断能力一样,神经网络通过调整这些参数来获得预测能力。
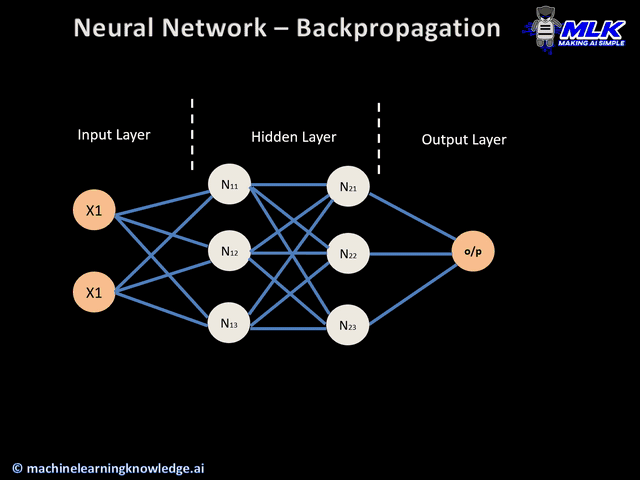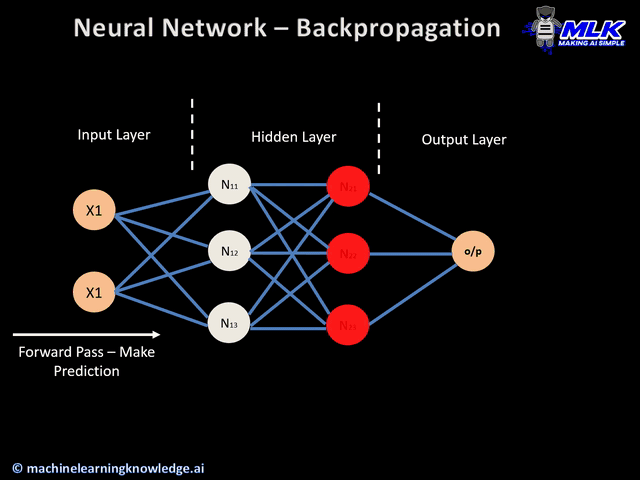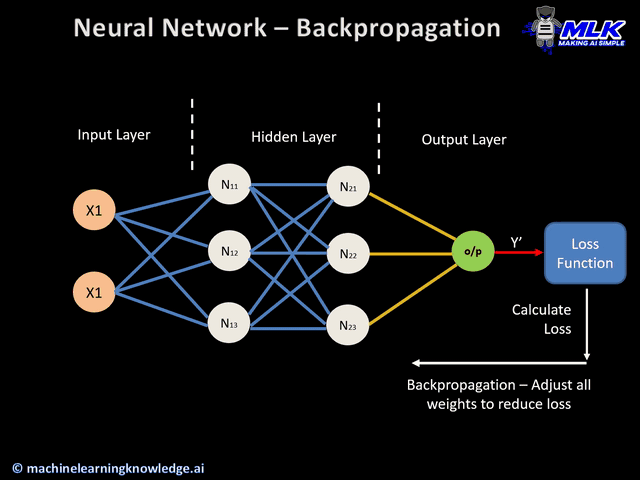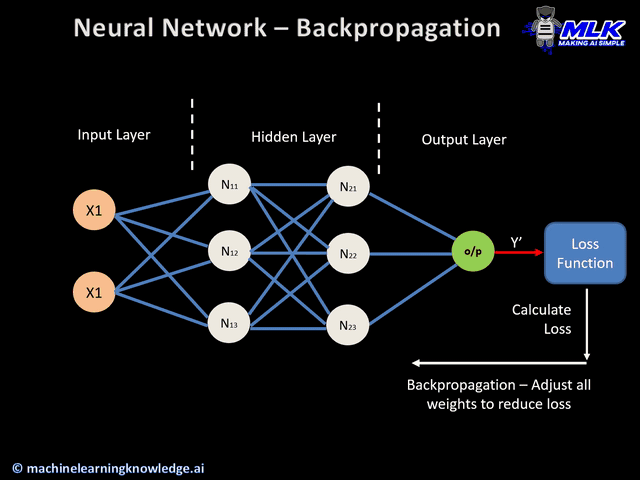
模型参数主要包含权重(Weights)和偏置(Bias)两大类,它们共同决定了网络的表达能力。
输入特征1 ---[w1]---> 输入特征2 ---[w2]---> 神经元 ---> 输出输入特征3 ---[w3]--->
权重决定了不同输入特征对最终结果的影响程度。
正权重:表示正相关关系,输入增大时输出也增大
负权重:表示负相关关系,输入增大时输出减小
权重绝对值:表示影响强度,越大影响越显著
在图像识别中,权重学会了这样的模式:如果检测到圆形轮廓(权重为2.3),并且有橙色特征(权重为1.8),同时边缘光滑(权重为1.2),那么很可能是橙子。如果检测到尖锐边缘(权重为-1.5),则不太可能是橙子。
(2)偏置(Bias)- 激活的基准线
加权输入之和 + 偏置 → 激活函数 → 神经元输出
偏置是一个常数项,它调整神经元被激活的难易程度。无论输入是什么,偏置都会被加到加权和中。
正偏置:降低激活门槛,神经元更容易被激活
负偏置:提高激活门槛,神经元更难被激活
零偏置:不调整激活门槛
在文本分类中,某个神经元用于检测"是否为垃圾邮件"。如果偏置为-2,意味着加权和需要达到2才能激活;如果偏置为1,则加权和只需要达到-1就能激活。偏置实际上在调整判定标准的严格程度。
模型参数是如何自动学习的?梯度下降的魔法
模型参数的学习过程就像是在黑暗中摸索下山的路。我们不知道山的形状,但可以通过感受脚下的坡度来判断前进方向。

第一步:当前位置(当前参数值)→ 第二步:感受坡度(计算梯度)→ 第三步:选择方向(梯度反方向)→ 第四步:迈出步伐(更新参数)
新参数 = 旧参数 - 学习率 × 梯度
梯度:告诉我们错误减少最快的方向
学习率:控制每次调整的幅度
负号:确保我们朝着减少错误的方向前进
训练过程中,每个参数都在不断调整;成千上万个参数通过协调配合,共同构建起模型的预测能力。
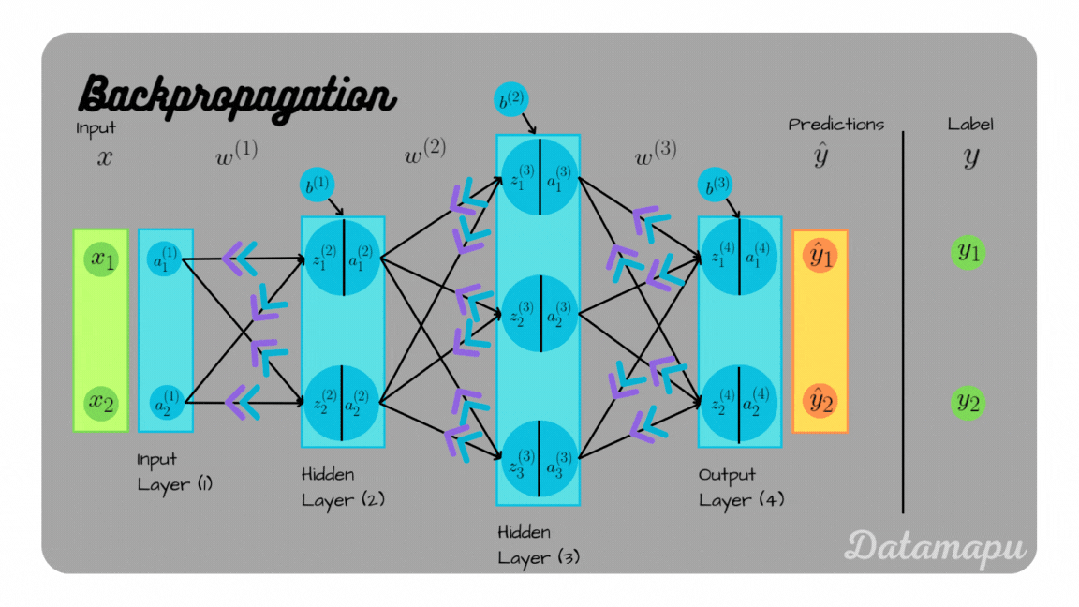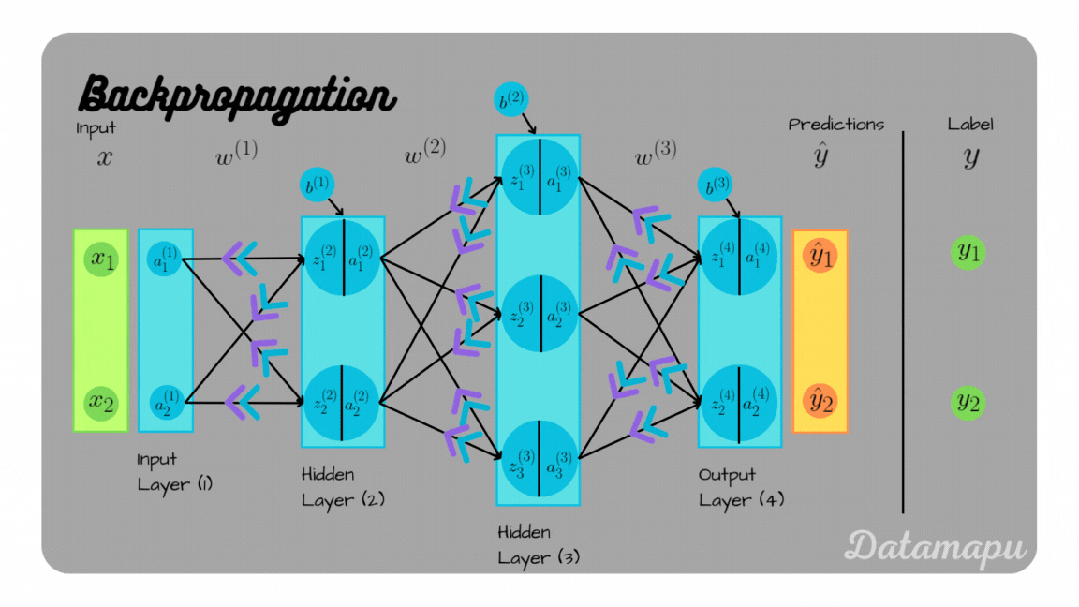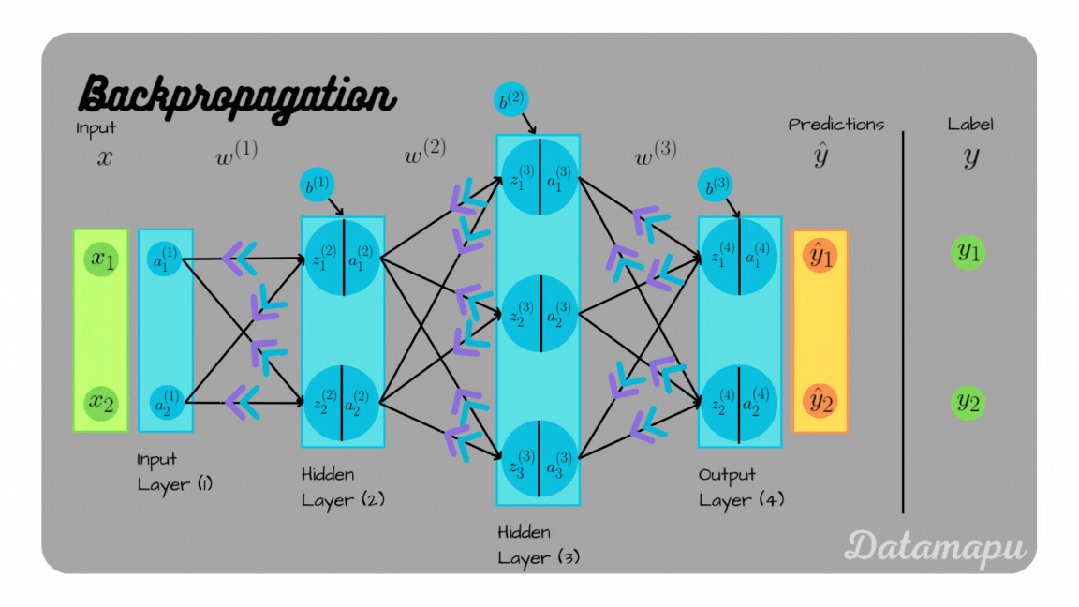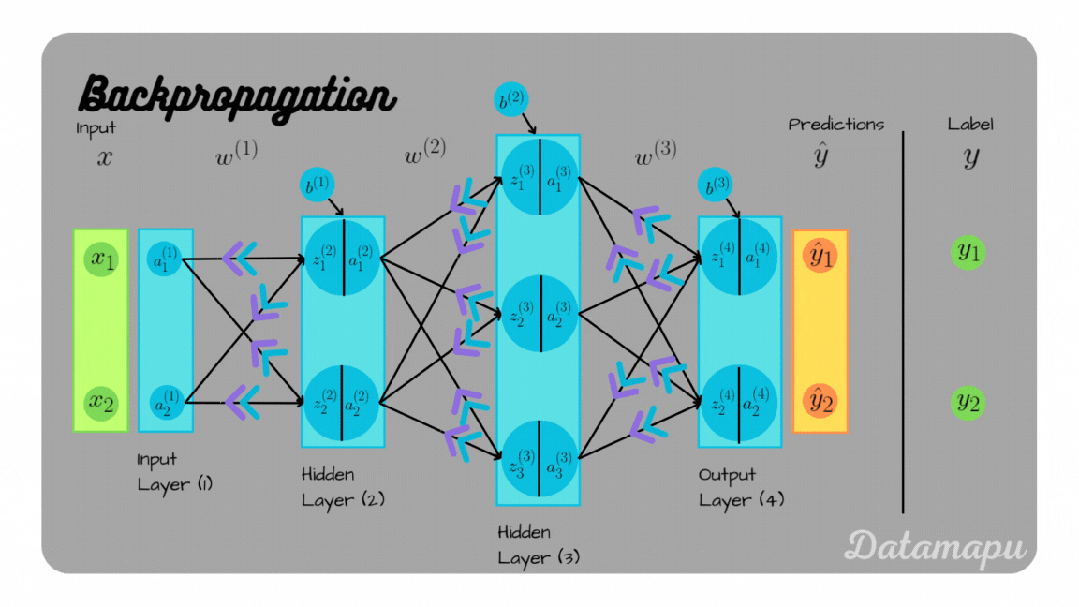
超参数的本质是什么?教学方法的选择
如果模型参数是学生"学到的知识",那么超参数就是"学习的方法"。不同的教学方法会产生不同的学习效果一样,不同的超参数设置会极大地影响模型的训练效果。
超参数是在训练开始之前由人工设定的配置参数,它们控制着整个学习过程的行为。这些参数不是通过数据学习得到的,而是需要基于经验、理论和实验来确定。
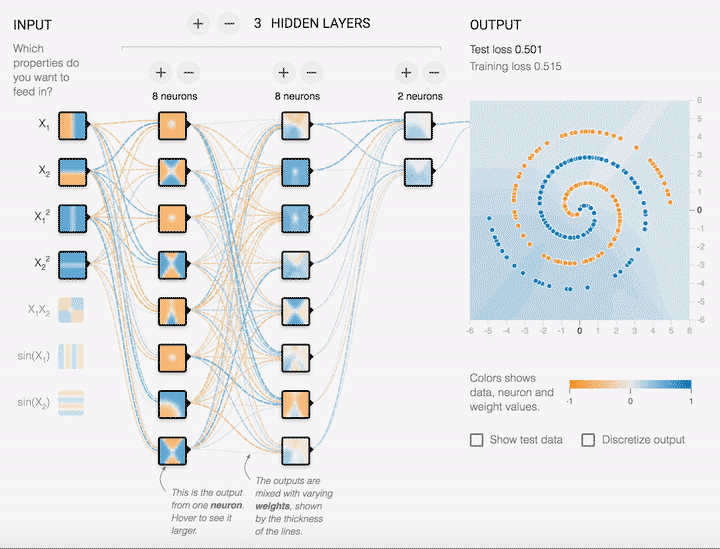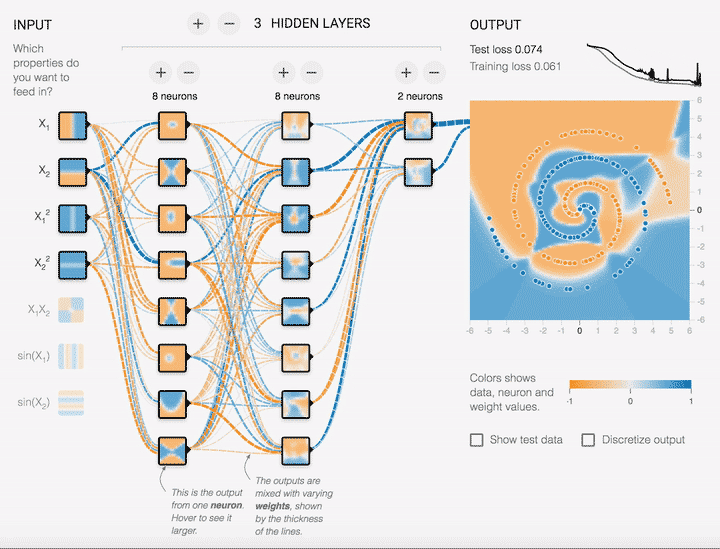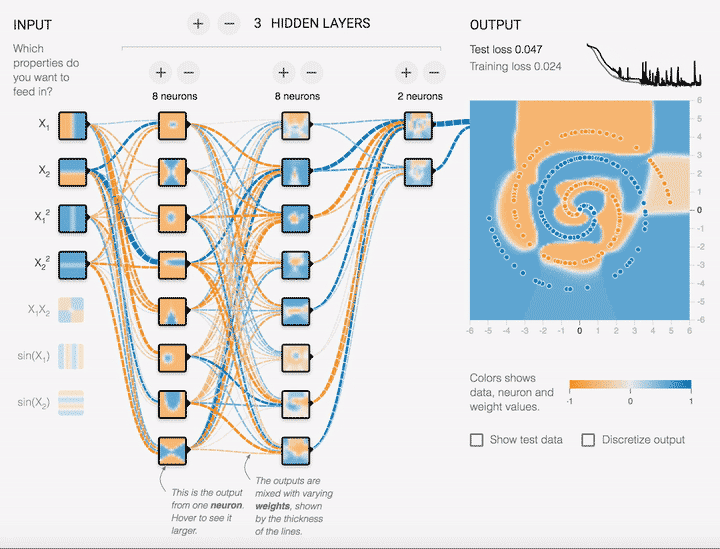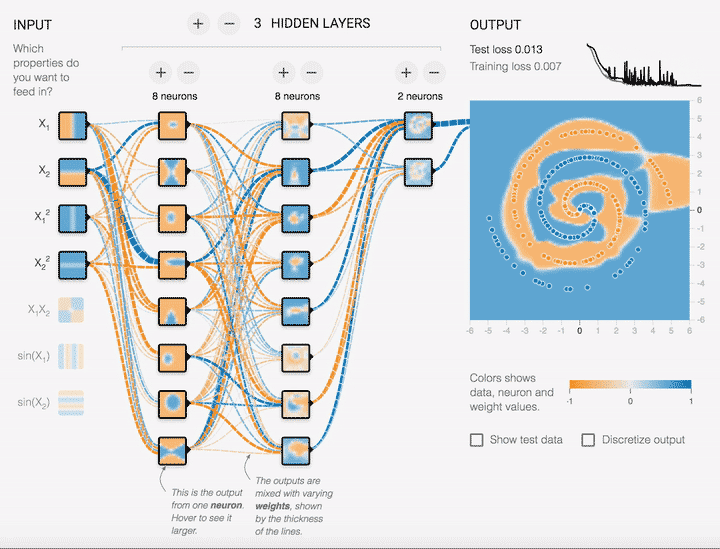
超参数有哪些关键类型?
超参数可以分为三大类,每一类都对训练过程有着至关重要的影响。
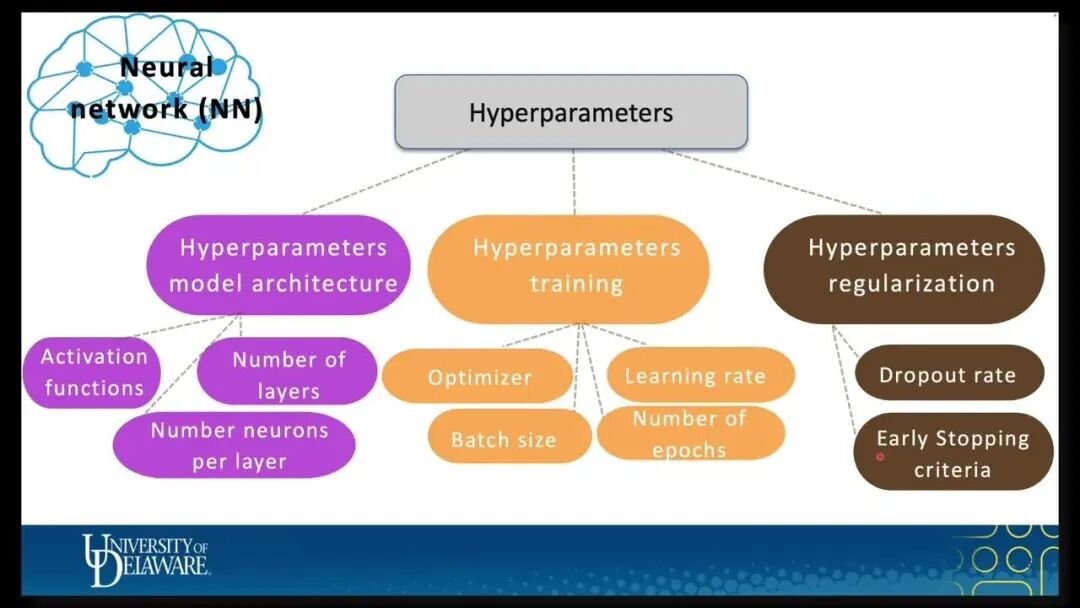
(1)模型训练类超参数
模型训练类超参数决定了模型参数更新的速度和频率,直接影响训练的收敛性和稳定性。
学习率(Learning Rate):0.001 ~ 0.1批次大小(Batch Size):16, 32, 64, 128...训练轮数(Epochs):10, 50, 100, 1000...优化器类型:SGD、Adam、RMSprop...动量(Momentum):0.9, 0.95, 0.99...学习率衰减:指数衰减、余弦退火...
(2)网络结构类超参数
网络结构类超参数定义了模型的架构和容量,决定了模型能够表达的复杂程度。
隐藏层数量:2层、3层、10层、100层...每层神经元数量:64、128、256、512...激活函数:ReLU、Sigmoid、Tanh...卷积核大小:3×3、5×5、7×7...卷积核数量:32、64、128、256...池化方式:MaxPooling、AveragePooling...
(3)正则化类超参数
正则化超参数就像学习过程中的"纪律约束",防止模型过度拟合训练数据。
Dropout率:0.1, 0.2, 0.5...权重衰减:0.001, 0.01, 0.1...批归一化:是否使用
如何找到最优的超参数组合?系统化的搜索方法
超参数调优需要在大量可能的组合中找到最优配置,这需要系统的搜索策略和充分的实验验证。
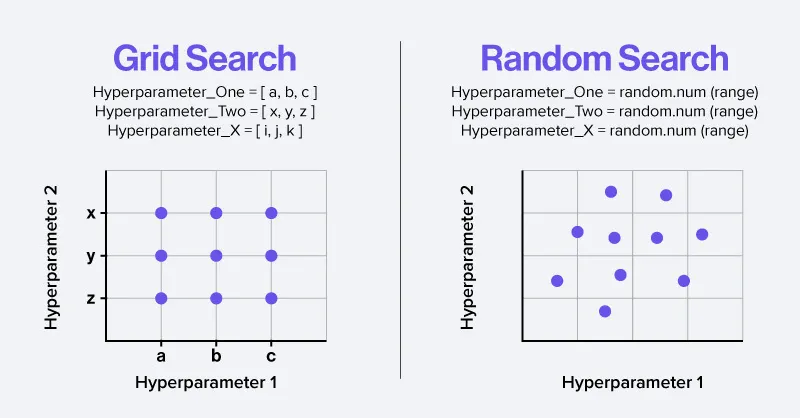
(1)网格搜索(Grid Search)- 地毯式搜索
这种方法虽然可靠,但计算量巨大,适合参数空间较小的情况。
for learning_rate in [0.001, 0.01, 0.1]: for batch_size in [16, 32, 64]: for hidden_size in [64, 128, 256]: 训练模型并评估性能
(2)随机搜索(Random Search)- 随机采样
for trial in range(100): learning_rate = random.uniform(0.001, 0.1) batch_size = random.choice([16, 32, 64, 128]) hidden_size = random.choice([64, 128, 256, 512]) 训练模型并评估性能
在参数空间中随机采样组合进行尝试。研究表明,在很多情况下,随机搜索比网格搜索更高效。
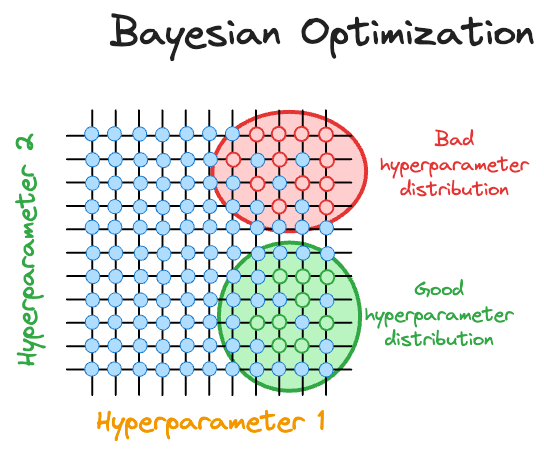
(3)贝叶斯优化(Bayesian Optimization)- 智能搜索
初始化:随机尝试几组超参数for trial in range(max_trials): model = build_surrogate_model(history_results) next_params = acquisition_function(model) score = train_and_evaluate(next_params) history_results.append((next_params, score))
基于历史实验结果建立概率模型,智能选择下一个最有希望的参数组合。这就像经验丰富的老师能够根据学生的表现智能调整教学方法。
彻底搞懂深度学习-AutoML自动调参(动图讲解)
深度学习的成功离不开模型参数和超参数的完美配合。模型参数是"学到的智慧",通过数据驱动的方式自动获得;超参数是"学习的策略",需要人类的智慧和经验来精心设计。
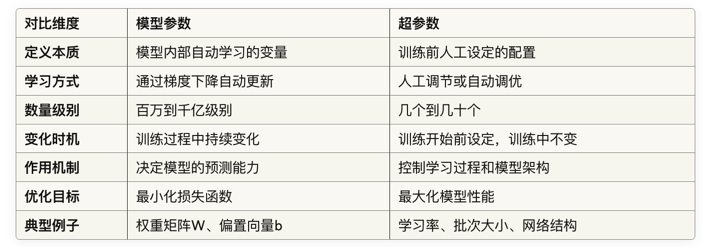
为了让大家更好地理解两者的区别,让AI整理了一个表格,将它们进行详细对比。