自动化机器学习建模文献分享-基于AutoPrognosis体系
 发表及杂志情况
发表及杂志情况 文章首页
文章首页全文地址:https://pmc.ncbi.nlm.nih.gov/articles/PMC10547178/
 方法学框架
方法学框架利用简约集成机器学习模型评估肺癌筛查资格:一项开发与验证研究
摘要
背景
目前,多个国家正考虑开展基于风险的肺癌筛查,但确定筛查资格的最佳方法仍不明确。集成机器学习有助于开发高度简约的预测模型,该模型既能保持复杂模型的性能,又能最大限度地提高简洁性和通用性,从而为个性化筛查的广泛应用提供支持。本研究旨在开发并验证用于确定基于风险的肺癌筛查资格的集成机器学习模型。
方法与结果
在模型开发阶段,我们采用了两个数据集:一是2006年至2010年招募的英国生物银行(UK Biobank)前瞻性队列中的216,714名曾吸烟者数据;二是2002年至2004年招募的美国国家肺癌筛查试验(NLST)随机对照试验对照组中26,616名高风险曾吸烟者数据。美国国家肺癌筛查试验在全美33个研究中心开展,将吸烟史至少为30包年、戒烟年限不足15年的高风险吸烟者随机分为两组,分别接受年度计算机断层扫描(CT)筛查或胸部X线筛查。在外部验证阶段,我们采用了美国前列腺、肺、结直肠和卵巢(PLCO)癌症筛查试验的数据,包括该试验胸部X线检查组的49,593名参与者以及所有80,659名曾吸烟者参与者。美国前列腺、肺、结直肠和卵巢癌症筛查试验于1993年至2001年招募参与者,旨在分析胸部X线筛查与不进行胸部X线筛查对肺癌筛查的影响。我们主要在该试验的胸部X线检查组进行验证,以便与在该试验对照组中开发的对比模型进行基准对比。研究开发的模型用于预测基线后5年内两种结局的风险,即肺癌确诊风险和肺癌死亡风险。我们通过受试者工作特征曲线下面积(AUC)评估模型的区分度,通过校准曲线和预期/观察比值评估模型的校准度,通过布里尔分数(Brier scores)评估模型的整体性能,并通过决策曲线分析评估模型的净获益。
研究开发的预测肺癌死亡风险模型(UCL-D)和预测肺癌发病风险模型(UCL-I)仅使用年龄、吸烟持续时间和吸烟包年这三个变量。尽管这两个模型所需的预测变量仅为现有对比模型的四分之一,但在区分度、整体性能和净获益方面,它们达到或超过了现有对比模型的水平。在基于美国前列腺、肺、结直肠和卵巢癌症筛查试验的外部验证中,UCL-D模型的受试者工作特征曲线下面积为0.803(95%置信区间:0.783, 0.824),校准效果良好,预期/观察比值为1.05(95%置信区间:0.95, 1.19);UCL-I模型的受试者工作特征曲线下面积为0.787(95%置信区间:0.771, 0.802),预期/观察比值为1.0(95%置信区间:0.92, 1.07)。在5年风险阈值分别为0.68%和1.17%时,UCL-D模型的灵敏度为85.5%,UCL-I模型的灵敏度为83.9%,在相同特异性条件下,这两个模型的灵敏度分别比美国预防服务工作组(USPSTF)2021年标准高出7.9%和6.2%。本研究的主要局限性在于,这些模型尚未在英国和美国以外的队列中进行验证。
结论
我们提出了用于预测曾吸烟者肺癌风险的简约集成机器学习模型,这一创新方法有助于简化多种场景下基于风险的肺癌筛查实施流程。托马斯·卡伦德及其同事开展了一项开发与验证研究,旨在利用简约集成机器学习模型评估肺癌筛查资格。
引言
筛查、早期发现和疾病预防项目正日益个性化,风险预测算法决定着个体的筛查资格和健康管理方式[1-3]。这种个性化有望改善此类干预措施的获益-风险比,并最终改善健康结局[4-6]。然而,要在人群层面开展这些项目,风险预测模型需满足两个条件:一是在模型开发、再训练或验证数据不足的情况下,模型仍具有良好的通用性;二是需考虑模型复杂性与实施可行性之间的平衡。
肺癌是全球癌症死亡的首要原因[7],使用低剂量计算机断层扫描(LDCT)对高风险人群进行肺癌筛查,可使筛查人群的肺癌特异性死亡率降低20%至24%[8,9]。但目前确定高风险人群的理想方法尚未明确。美国预防服务工作组(USPSTF)推荐采用二分法标准来筛选筛查参与者,具体标准为:年龄在50-80岁之间、吸烟史≥20包年、曾吸烟者戒烟年限<15年[10]。尽管如此,已有研究表明,基于风险预测模型确定肺癌筛查人群,相比仅采用基于风险因素的二分法标准,具有更优的获益-风险比和成本效益[11-14],因此欧洲的肺癌筛查试点项目已采用基于风险模型的筛选标准[15]。
迄今为止,大多数经过外部验证的肺癌预测模型都是基于美国的数据集开发的[12,16-21],这反映出目前具备长期随访数据、适合开展预测建模研究的队列相对有限。这意味着,全球大多数实施基于风险的肺癌筛查的医疗体系,都将使用基于美国人群开发的预测模型。这些模型常包含种族等变量,而不同国家、不同数据集对种族的分类方式存在差异;模型中涉及的学历变量,其标准也会随时间推移和地区不同而变化。在英国,已有研究表明现有模型在某些特定人群(如社会经济地位较低的人群)中表现欠佳,对这些人群风险的低估可能导致筛查项目加剧健康不平等[22]。
此外,目前已投入使用的风险模型在实施过程中面临挑战。在英国,肺癌筛查试点项目的资格认定基于PLCOm2012模型和利物浦肺癌项目(LLP)风险模型,这两个模型需要17个独特变量,而其中很少有变量能常规获取[23]。从潜在符合条件的个体中收集这些变量并解释结果,平均需要5至10分钟。若要确定100万人的筛查资格,每年需48至95名全职工作人员投入工作。据估计,英国55-74岁的潜在符合肺癌筛查资格的曾吸烟者约有680万人,且平均每年新增50万名满55岁的人群[24,25]。肺癌筛查只是目前正在开发或已投入使用的众多基于风险的项目之一,现有风险评估方式对国家筛查项目的有效实施构成了重大障碍。
本研究假设,采用集成机器学习方法,结合来自不同地理区域、不同人群和不同平均风险水平的训练数据,能够开发出预测变量最少且适用性广泛的肺癌筛查预测模型。通过这种方式,我们旨在将基于风险因素标准的简洁性与风险模型更优的预测性能相结合,同时确保模型在新场景下的通用性。
方法
数据来源与研究人群
模型开发与内部验证数据集
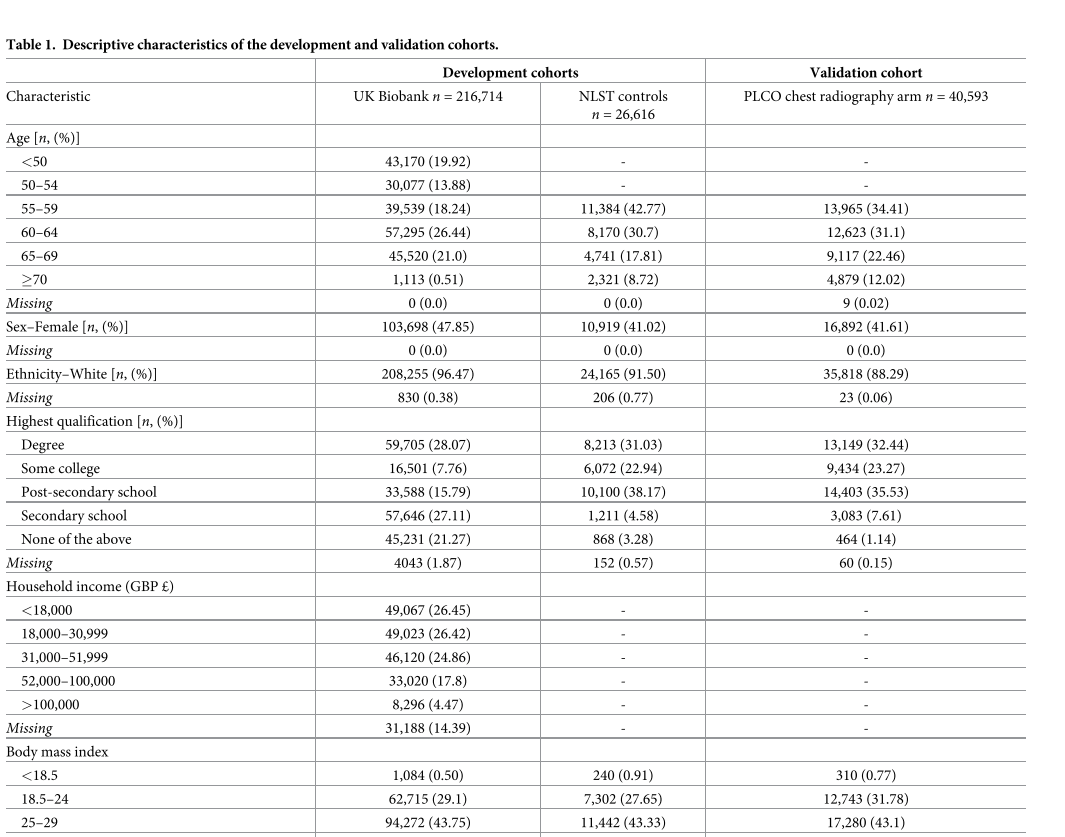
在模型开发阶段,我们首先使用了英国生物银行中216,714名无肺癌病史的曾吸烟者数据[26],随后整合英国生物银行和美国国家肺癌筛查试验(NLST)的数据,构建了一个跨国数据集(样本量n=26,616)(图1;参与者流程图详见S1附录中的图A和图B)。英国生物银行是一项大型前瞻性队列研究,于2006年至2010年在英国22个研究中心招募参与者,该队列将表型数据与医院和登记处的实时数据相关联[27]。在研究数据收集期间,英国尚未开展系统性的肺癌筛查项目。美国国家肺癌筛查试验是一项肺癌筛查随机对照试验,于2002年至2004年在全美33个研究中心开展,对比了计算机断层扫描(CT)与胸部X线检查在肺癌筛查中的效果,随访持续至2009年[28]。该试验的参与者仅限于肺癌高风险人群,具体纳入标准为:吸烟史≥30包年,曾吸烟者需在入组前15年内戒烟[28]。
 图1 用于确定肺癌筛查资格的UCL模型开发流程
图1 用于确定肺癌筛查资格的UCL模型开发流程图1 用于确定肺癌筛查资格的UCL模型开发流程:(a)数据集;(b)集成建模;(c)整体模型解释。注:(a)首先整合英国生物银行(UK Biobank)和美国国家肺癌筛查试验(NLST)的数据构建跨国数据集,用于开发新模型,随后在美国前列腺、肺、结直肠和卵巢(PLCO)癌症筛查试验的胸部X线检查组(可与在该试验对照组中开发的现有模型进行基准对比)和整个PLCO队列中对模型进行外部验证。(b)集成建模方法先对各个建模流程进行优化,再将各流程的结果整合,得出每个个体的单一预测结果。该部分展示了UCL-D模型的详细信息,包括在生成个体5年肺癌风险单一预测结果时,每个流程所对应的权重。(c)通过在英国生物银行数据集上运用沙普利可加解释(SHAP)方法[35],分析了不同变量对整体预测结果的贡献以及预测变量之间的交互作用。(c)中的第一个子图显示,在预测个体肺癌死亡风险时,吸烟持续时间是最重要的变量,其次是吸烟包年数,最后是年龄。后续三个依赖性子图展示了预测变量(X轴)与结局(Y轴)之间的关系,即该预测变量的取值对预测结果的重要性。纵向离散程度反映了交互效应的强弱,颜色则代表另一个变量。这些子图显示,吸烟持续时间不足约35年时,对模型预测结果的影响相对较小;当吸烟持续时间超过35年后,吸烟持续时间与吸烟包年数的交互作用显著增强,且呈现急剧变化。吸烟持续时间与吸烟包年数之间的这种关系,与前一个子图所示的结果一致,即除非两者均处于较高水平,否则吸烟持续时间对肺癌风险的影响大于每日吸烟量。也就是说,即使每日吸烟量较大,吸烟持续时间较短的个体,其预测风险仍较低。这与我们对肺生物学的认知一致,即个体戒烟后,肺部具备自我修复能力[56]。(c)中最后一个子图显示,在60岁以下人群中,年龄对模型预测结果的影响相对有限。(注:NLST为美国国家肺癌筛查试验;PLCO为美国前列腺、肺、结直肠和卵巢癌症筛查试验)
我们选择美国国家肺癌筛查试验的数据,是因为该试验与英国生物银行相比,具有地理分布不同、队列风险水平更高以及种族多样性更丰富的特点。英国生物银行的队列死亡率风险低于英国普通人群[29],而将美国国家肺癌筛查试验的数据与英国生物银行的数据整合后,预测模型的训练数据将涵盖更广泛的人群,从而有望提升模型性能。
外部验证数据集
在模型验证阶段,我们使用了美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)胸部X线检查组中40,593名无肺癌病史的曾吸烟者数据[30](详见S1附录中的图C)。这一选择使我们能够将所开发的模型与在该试验对照组中开发的对比模型进行基准对比。研究发现,胸部X线检查对肺癌死亡率无影响,对肺癌发病率也无统计学意义上的显著影响[30]。在S1附录的次要分析中,我们报告了模型在整个PLCO数据集(样本量n=80,659)两个组中的性能。
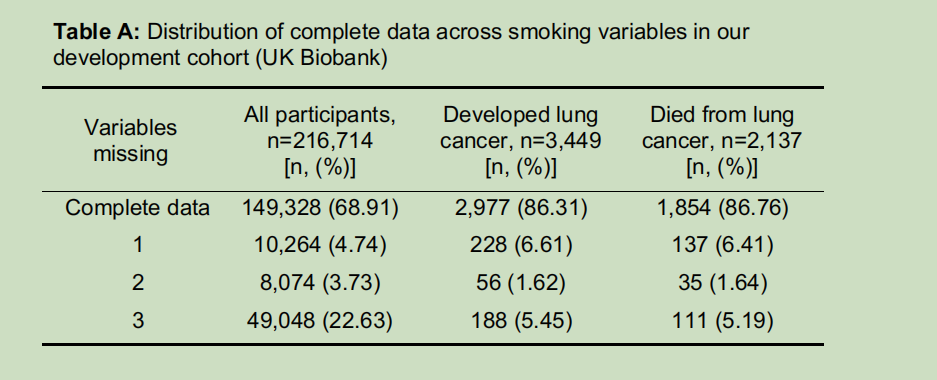
缺失数据处理
我们采用基于链式方程的多重插补法(MICE),结合预测均值匹配法,生成用于模型开发和验证的插补数据集[31]。由于英国生物银行中候选预测变量的平均缺失率为11%,我们为其生成了10个插补数据集。而美国前列腺、肺、结直肠和卵巢癌症筛查试验与美国国家肺癌筛查试验中所有相关变量的缺失率均<5%,因此我们为这两个试验各生成了5个插补数据集。详细信息详见S1附录中的表A和图D-F。
结局指标
我们开发的模型用于预测基线后5年内两种结局的绝对累积风险,即肺癌确诊风险和肺癌死亡风险。英国生物银行中参与者的肺癌发病状态和主要死亡原因,通过关联国家癌症登记处和国家统计局的数据确定[26]。在美国国家肺癌筛查试验和美国前列腺、肺、结直肠和卵巢癌症筛查试验中,参与者的主要死亡原因通过独立审核死亡证明确认[28,30]。其中,美国国家肺癌筛查试验通过提取医疗记录来确定肺癌诊断情况,而美国前列腺、肺、结直肠和卵巢癌症筛查试验则通过邮件和电话随访参与者来确认肺癌诊断情况[8,30]。
模型开发
我们利用开源自动化机器学习软件AutoPrognosis,开发了机器学习流程集成模型[32,33]。在本分析中,AutoPrognosis用于优化流程,该流程包括变量预处理步骤,随后进行模型选择和训练。之后,我们对这些优化后的流程进行整合,通过贝叶斯模型平均法对4个独立流程的预测结果进行加权组合,得出每个个体的单一预测结果(图1)[32]。我们尝试了多种模型算法,包括逻辑回归、随机森林和梯度提升方法(详见S1附录中“模型开发”部分的详细信息)。在整个过程中,对流程的训练和选择均以最大化受试者工作特征曲线下面积(AUC)(用于衡量模型区分度)为目标。
附件补充
模型构建
本研究采用AutoPrognosis工具[4,5]构建模型,并通过Cox比例风险回归模型进行对比与模型验证。
在本分析中,AutoPrognosis从252种潜在组合中筛选最优建模流程——每个流程包含三个阶段,即降维、预测变量预处理和模型算法。研究所考虑的具体算法如下:
-
降维算法:无降维、方差阈值法、主成分分析、独立成分分析。
- 预测变量预处理方法:无预处理、归一化、特征间多项式交互、基于最大绝对值的预测变量缩放、最小-最大缩放、均匀变换、标准化。
- 建模算法:逻辑回归、线性判别分析、二次判别分析、装袋算法、随机森林、Adaboost算法[6-8]、CatBoost算法[9,10]、LightGBM算法[11,12]、XGBoost算法[13,14]。
AutoPrognosis采用贝叶斯优化方法进行建模流程选择[4],同时使用Optuna工具[15]对所测试的每种建模算法的超参数进行调优。
集成模型通过两种方式生成:一是借助Python的combo包[16]中的堆叠法与聚合法,二是通过贝叶斯模型平均法[4]。所有建模流程及集成模型均在完整的模型开发数据集中进行训练。研究采用5折交叉验证来评估每个建模流程及每个流程集成模型的性能,并筛选出性能最优的集成模型。本研究考虑的集成模型最多包含4个不同的建模流程。也就是说,若单一建模流程(例如,不进行降维、仅对预测变量进行标准化、后续采用LightGBM机器学习算法的流程)的区分度优于多个流程组成的集成模型,则会选择该单一流程作为最优模型。设定集成模型中建模流程的最大数量时,综合权衡了模型性能与模型训练所需的计算时间,属于务实性设定。
模型解释
我们采用核沙普利可加解释(SHAP)算法对模型进行解释,并分析预测变量之间的交互作用(图1)[34]。核沙普利可加解释算法是一种基于置换的方法,其理论基础为合作博弈论。简而言之,该算法将每个变量逐一输入模型,模型预测结果的变化量即归因于该变量[35,36]。详细信息详见S1附录中“变量重要性与交互作用”部分。
附件补充
变量重要性与交互作用
本研究采用核沙普利加性解释(Kernel SHAP)方法,剖析不同变量对预测结果的贡献(包括变量间的交互作用)[23]。核沙普利(Kernel SHAP)是一种特征归因方法,通过计算沙普利值(Shapely values)来解释模型预测结果,其中沙普利值的大小代表单个预测变量对整体预测结果的贡献程度[23]。
沙普利值的计算方式为:将每个预测变量依次输入模型,然后将“移除该变量后个体预测结果的变化量”归因于该变量。例如,对于一名年龄55岁、吸烟持续时间30年、吸烟包年数60的个体,若模型仅使用“吸烟持续时间”和“吸烟包年数”进行预测,此时预测结果与完整变量预测结果的差异可归因于“年龄”这一变量。随后,对整个数据集中所有个体的这种归因结果取平均值,即可得到每个预测变量的最终沙普利值[24]。
通过SHAP方法得到的结果可表示为线性模型𝜙₀ + ∑𝜙ⱼ𝑥ⱼ,其中:𝜙₀为截距项,对应待解释数据集中的平均预测风险;𝜙ⱼ为各预测变量𝑥ⱼ(即年龄、吸烟持续时间和吸烟包年数)的SHAP值[23]。
变量选择
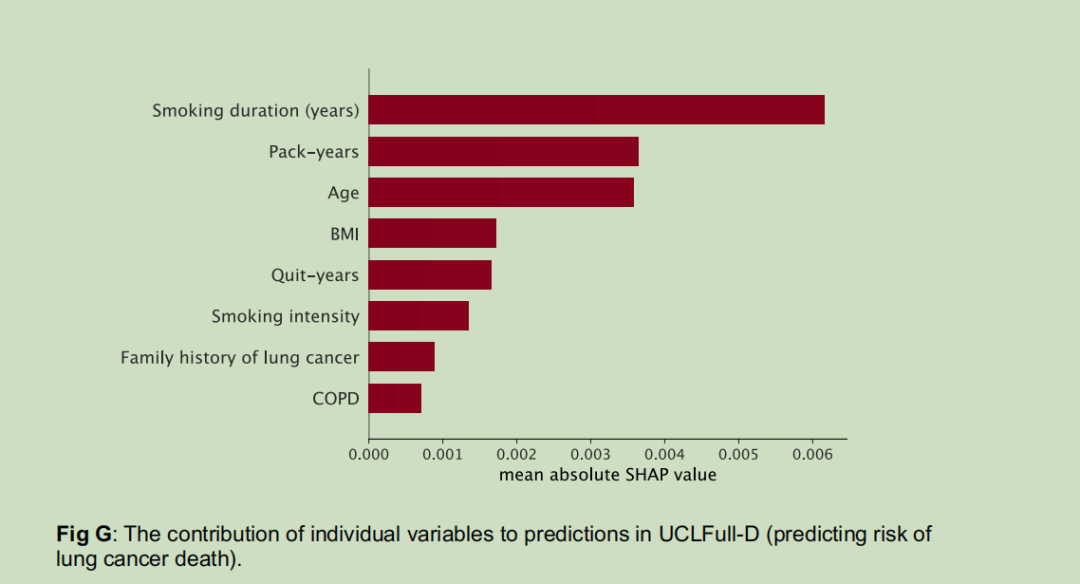
出于实用性考虑,我们仅从英国生物银行中选取同时存在于美国国家肺癌筛查试验和美国前列腺、肺、结直肠和卵巢癌症筛查试验中的候选预测变量(详见S1附录中的表B)。最终的预测变量列表是综合文献资料、领域专业知识、变量分布特征、在多种场景下的通用性以及模型在英国生物银行中的区分度确定的,据此开发了完整模型。通过分析特征重要性,我们发现年龄、吸烟持续时间和吸烟包年数是影响预测结果的关键因素,因此决定基于这三个变量开发模型(详见S1附录中的图G)。
统计分析
我们采用布里尔分数(Brier score)评估模型的整体性能[37],通过受试者工作特征曲线下面积(AUC)评估模型的区分度,利用校准曲线和预期/观察病例比评估模型的校准度,借助决策曲线分析评估模型的临床实用性[38]。在计算校准曲线时,我们首先根据个体的预测风险将其分为10个风险十分位数组,然后将预测概率与观察到的风险进行比较,其中观察到的风险采用Kaplan-Meier模型计算。在评估临床效用时,我们通过决策曲线分析,考量了模型在不同风险阈值下的净获益[38]。我们采用Hanley和MacNeil提出、经Robin等人改良的双尾bootstrap检验方法,对模型的区分度进行比较[39,40]。为确定模型潜在的风险阈值,我们采用固定人群策略,将整个美国前列腺、肺、结直肠和卵巢癌症筛查试验外部验证数据集中符合美国预防服务工作组(USPSTF)2021年标准的筛查合格人数作为参照。
在内部验证和外部验证中,我们对所有分析均进行了1000次有放回的bootstrap重抽样;采用百分位法计算效应量的点估计值和95%置信区间。在内部验证中,我们采用了经乐观校正的指标。所有分析均使用R软件[41]和Python软件[42]完成。
模型比较
在基准对比中,我们将新开发的模型与美国预防服务工作组(USPSTF)2021年标准(年龄50-80岁、吸烟史≥20包年、曾吸烟者戒烟年限<15年)[10],以及其他现有风险模型进行了比较。这些现有风险模型包括已投入使用的模型(PLCOm2012模型[18]和利物浦肺癌项目(LLP)2版模型[43]),以及经过外部验证且持续表现优于其他风险模型的模型(肺癌死亡风险评估工具(LCDRAT)和肺癌风险评估工具(LCRAT)[19])(详见S1附录中的表C)[13,22,44,45]。除PLCOm2012模型预测的是6年肺癌发病风险外,其余所有对比模型中,肺癌死亡风险评估工具(LCDRAT)预测5年肺癌死亡风险,肺癌风险评估工具(LCRAT)和利物浦肺癌项目(LLP)模型预测5年肺癌发病风险。目前已开发出利物浦肺癌项目(LLP)模型的第3版(经重新校准),但由于该版本尚未投入使用,我们在附录中呈现了完整的对比分析结果,并指出由于其使用的预测变量和系数与第2版相同,因此两者的区分度相当。此外,我们还将新开发的模型与基于相同数据集开发的Cox模型(详见S1附录中的方法部分),以及肺癌死亡风险评估工具(LCDRAT)、肺癌风险评估工具(LCRAT)和PLCOm2012模型的受限版本进行了比较。

除利物浦肺癌项目(LLP)模型外,其他所有对比模型的变量数据均完整可用。对于利物浦肺癌项目(LLP)模型,英国生物银行中缺乏家庭成员肺癌发病年龄的数据。参考ten Haaf等人的研究[44],并结合英国肺癌流行病学特征[46],我们假设所有有肺癌家族史的家庭成员肺癌发病年龄均超过60岁。在美国前列腺、肺、结直肠和卵巢癌症筛查试验的数据集中,缺乏石棉暴露史和肺炎既往史的数据,因此我们将这两个变量的值设定为0。我们使用R软件中的lcmodels包计算PLCOm2012模型、肺癌风险评估工具(LCRAT)和肺癌死亡风险评估工具(LCDRAT)的预测结果[47]。
结果
英国生物银行和美国国家肺癌筛查试验(NLST)(模型开发数据集)以及美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)(外部验证数据集)的描述性特征如表1所示。不同结局指标对应的人群特征详见S1附录中的表D-G。不同随访时间段的肺癌确诊人数和肺癌死亡人数详见S1附录中的表H。
研究发现,年龄、吸烟持续时间(年)和吸烟包年数是影响预测结果的主要因素。因此,我们重点开发了两个仅使用这三个变量的模型,即UCL-D模型和UCL-I模型。其中,UCL-D模型用于预测5年肺癌死亡风险,是一个加权集成模型,包含4种建模算法:AdaBoost算法[48,49]、LightGBM算法[50]、逻辑回归和线性判别分析;UCL-I模型用于预测5年肺癌发病风险,包含的算法为AdaBoost算法[48,49]、LightGBM算法[50]、Bagging算法和CatBoost算法[51]。集成流程的详细信息、权重以及算法超参数详见S1附录中的图H-I和表I-J。
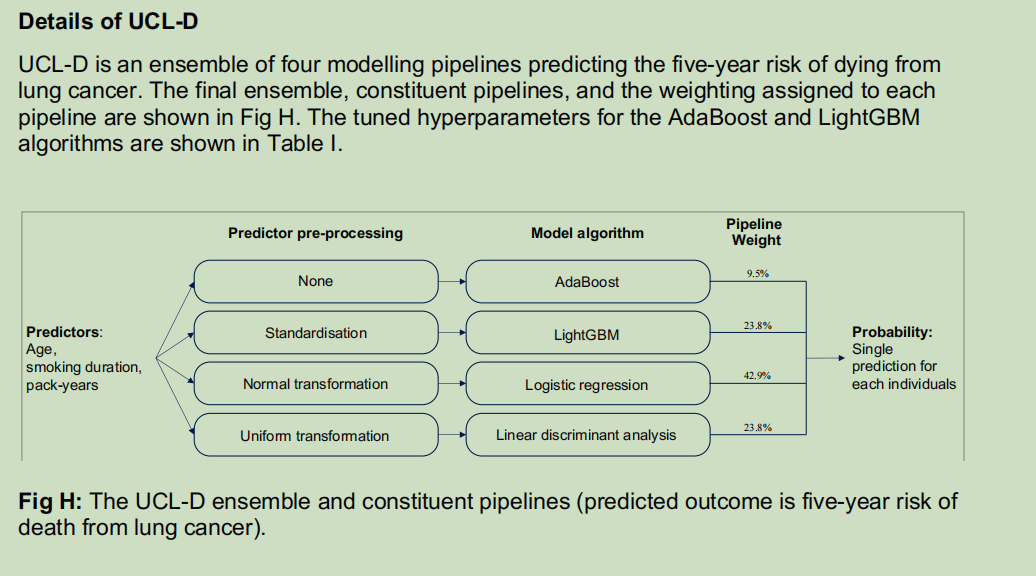
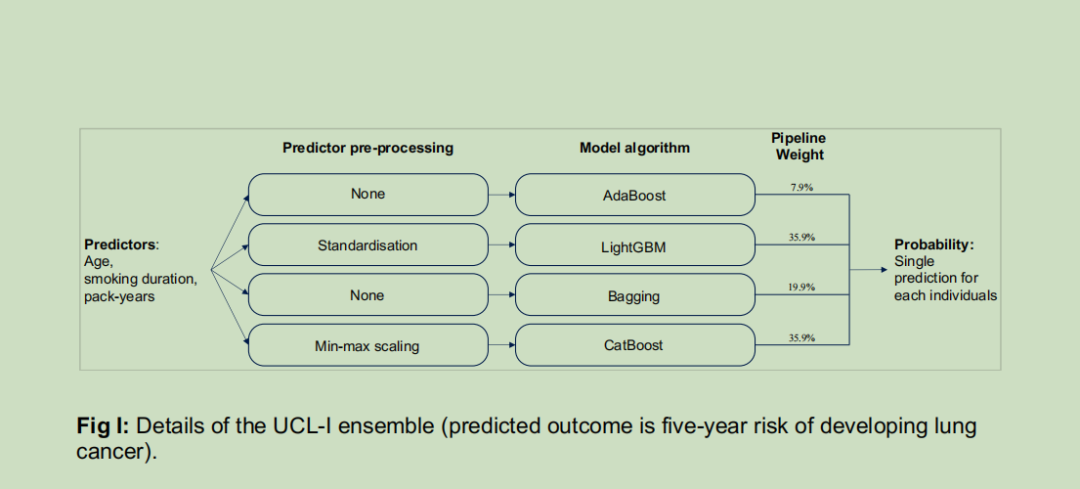
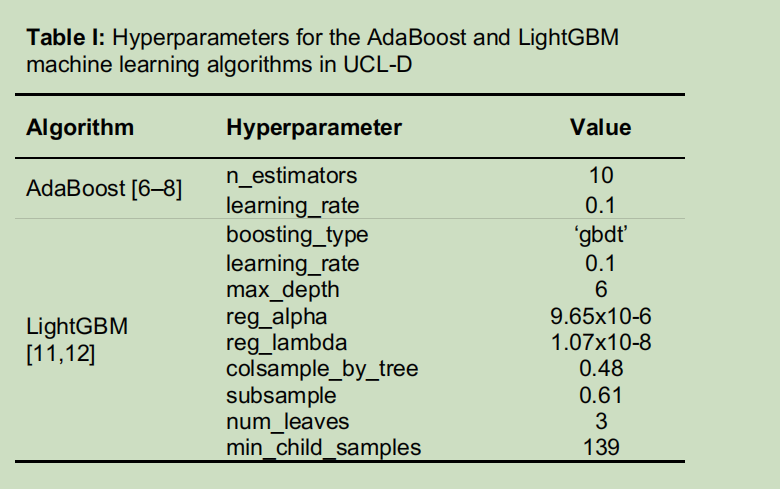
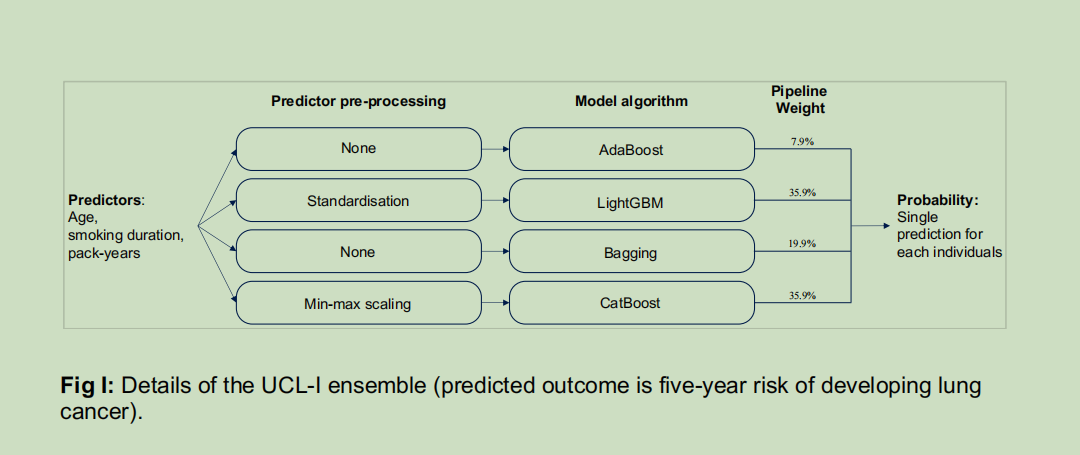
UCL模型
在内部验证和外部验证中,UCL-D模型和UCL-I模型均表现出良好的区分度(表2、表3和S1附录中的表K)、整体性能(S1附录中的表L-M)和校准度(图2、表4和S1附录中的表N),且在整体人群和各亚组中均如此。在美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)胸部X线检查组的外部验证中,UCL-D模型的受试者工作特征曲线下面积(AUC)为0.803(95%置信区间:0.783, 0.824),预期/观察(E/O)比值为1.05(95%置信区间:0.95, 1.19),布里尔分数(Brier score)为0.0084(95%置信区间:0.0075, 0.0093);UCL-I模型的受试者工作特征曲线下面积(AUC)为0.787(95%置信区间:0.771, 0.802),预期/观察(E/O)比值为1.0(95%置信区间:0.92, 1.07),布里尔分数(Brier score)为0.0153(95%置信区间:0.0142, 0.0164)。
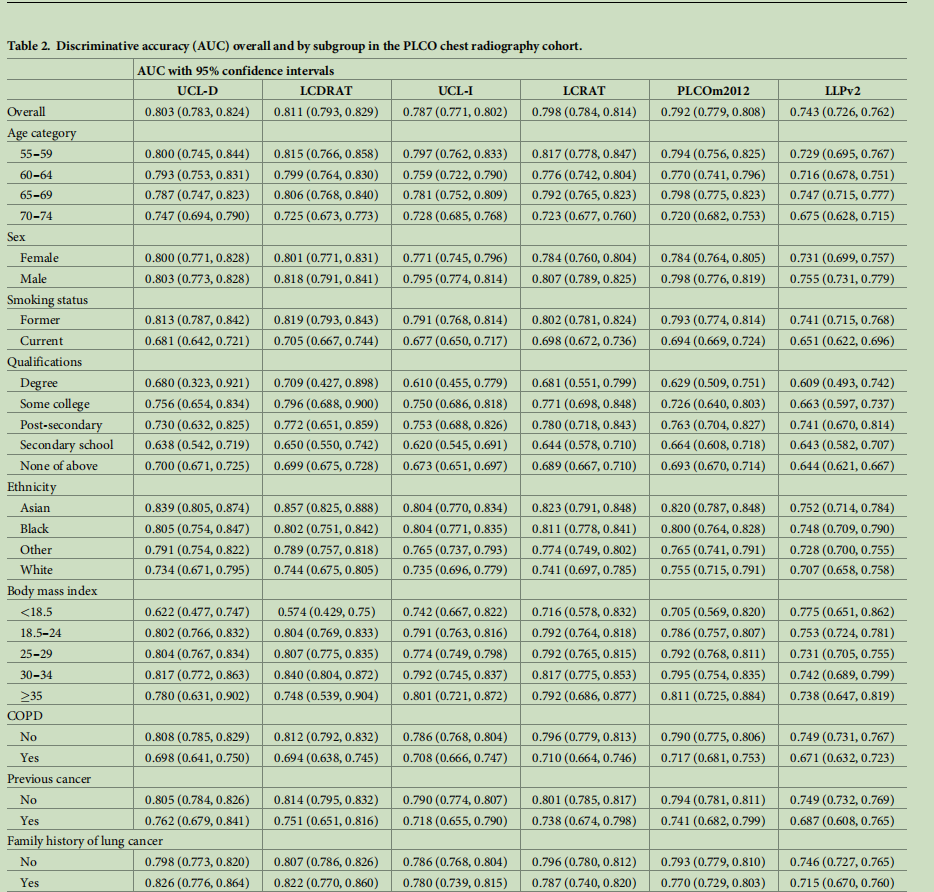
(注:AUC为受试者工作特征曲线下面积;COPD为慢性阻塞性肺疾病;PLCO为美国前列腺、肺、结直肠和卵巢癌症筛查试验;LLPv2为利物浦肺癌项目2版模型;LCDRAT为肺癌死亡风险评估工具;LCRAT为肺癌风险评估工具;UCL-D模型用于预测肺癌死亡风险;UCL-I模型用于预测肺癌发病风险。UCL模型在大多数亚组中均表现出稳定的区分度。值得注意的是,在体重指数<18.5的人群和慢性阻塞性肺疾病患者中,所有模型在现吸烟者中的受试者工作特征曲线下面积(AUC)均低于曾吸烟者。UCL模型在所有种族人群中均表现出良好的区分度。)
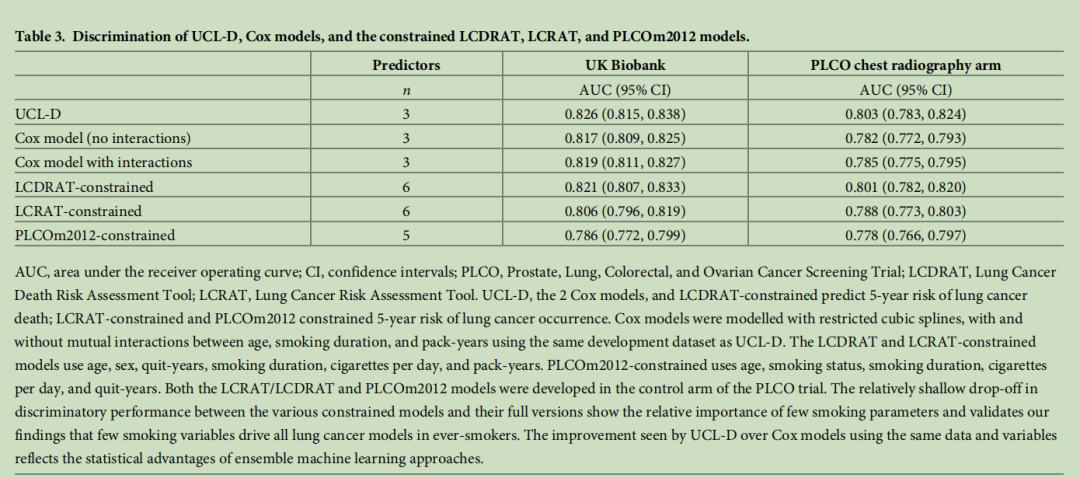
表3 UCL-D模型、Cox模型以及肺癌死亡风险评估工具(LCDRAT)、肺癌风险评估工具(LCRAT)和PLCOm2012模型受限版本的区分度
| | | 美国前列腺、肺、结直肠和卵巢癌症筛查试验胸部X线检查组(AUC(95%置信区间)) |
|---|
| | | |
| | | |
| | | |
| | | |
|
| | |
| | | |
(注:AUC为受试者工作特征曲线下面积;CI为置信区间;PLCO为美国前列腺、肺、结直肠和卵巢癌症筛查试验;LCDRAT为肺癌死亡风险评估工具;LCRAT为肺癌风险评估工具。UCL-D模型、两个Cox模型以及肺癌死亡风险评估工具(LCDRAT)受限版本用于预测5年肺癌死亡风险;肺癌风险评估工具(LCRAT)受限版本和PLCOm2012模型受限版本用于预测5年肺癌发病风险。Cox模型采用限制性立方样条构建,包含年龄、吸烟持续时间和吸烟包年数之间的交互项或无交互项,且与UCL-D模型基于相同的开发数据集。肺癌死亡风险评估工具(LCDRAT)和肺癌风险评估工具(LCRAT)受限版本使用的变量包括年龄、性别、戒烟年限、吸烟持续时间、每日吸烟支数和吸烟包年数;PLCOm2012模型受限版本使用的变量包括年龄、吸烟状态、吸烟持续时间、每日吸烟支数和戒烟年限。肺癌风险评估工具(LCRAT)、肺癌死亡风险评估工具(LCDRAT)和PLCOm2012模型均基于美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)对照组开发。各类受限模型与其完整版本的区分度差异较小,这表明少数吸烟相关参数具有重要作用,同时也验证了我们的研究结果,即曾吸烟者的肺癌模型主要由少数吸烟相关变量驱动。在使用相同数据和变量的情况下,UCL-D模型的性能优于Cox模型,这体现了集成机器学习方法在统计学上的优势。)
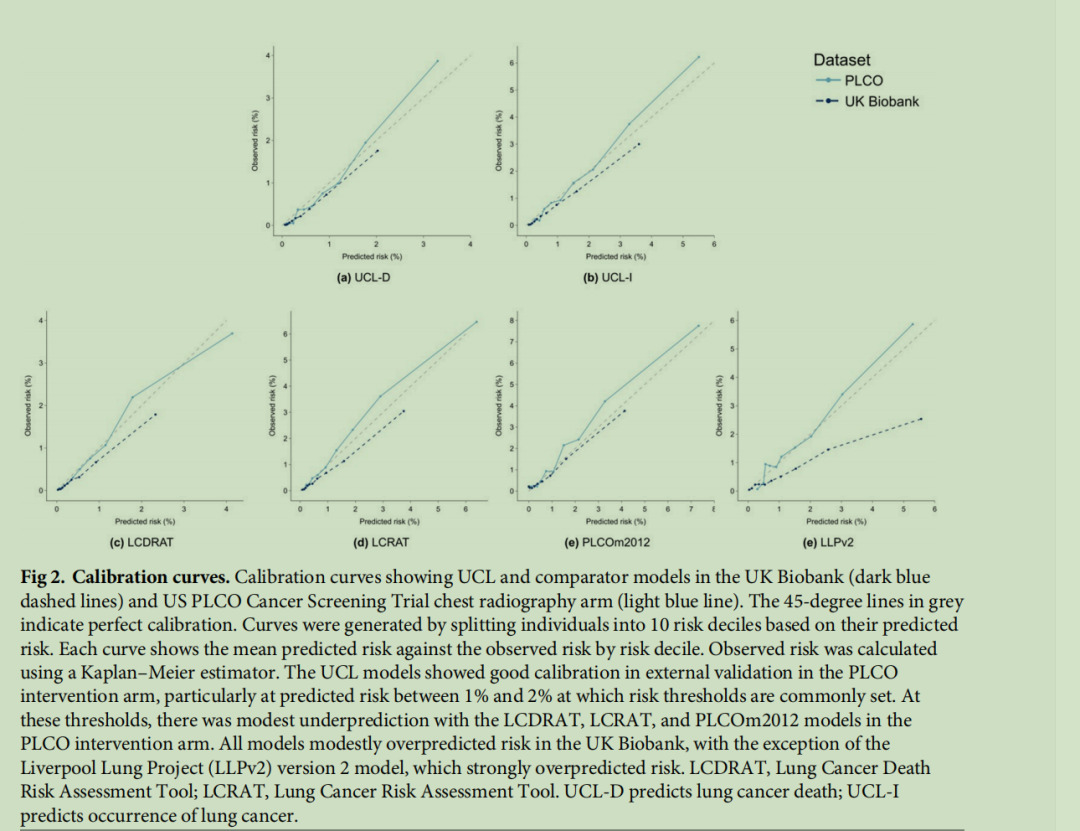
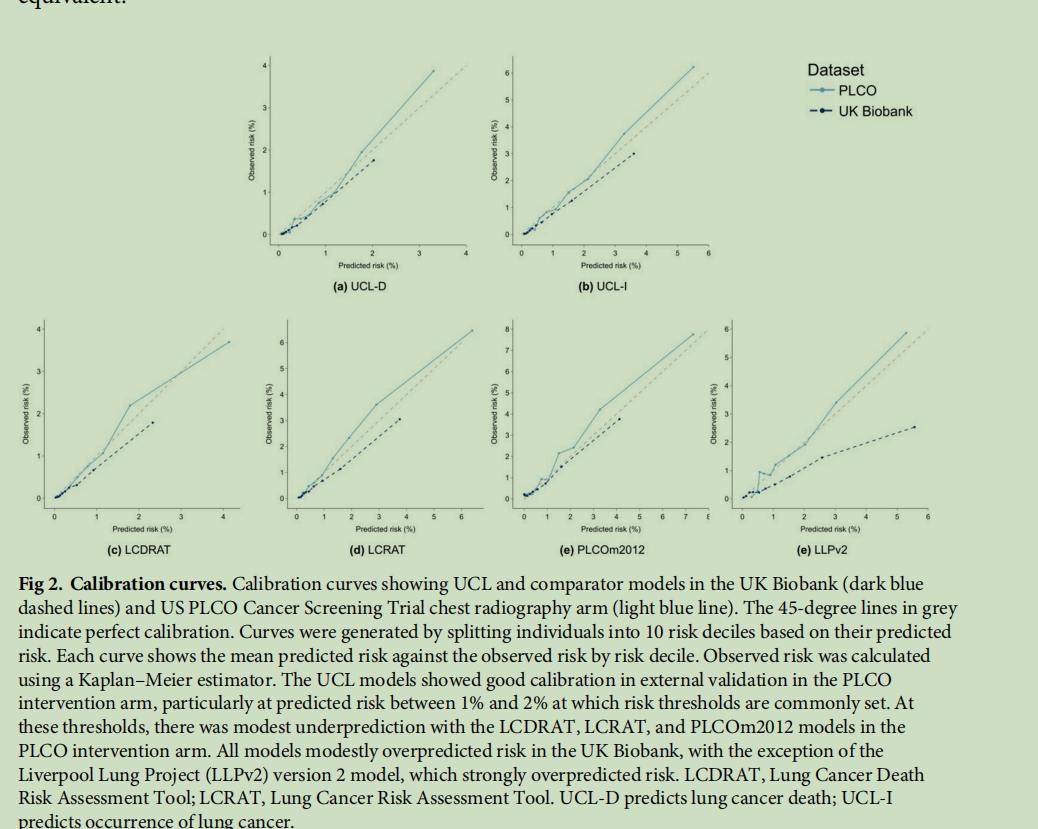
图2 校准曲线:图中展示了UCL模型和对比模型在英国生物银行(深蓝色虚线)和美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)胸部X线检查组(浅蓝色实线)中的校准情况。灰色45度线代表完美校准。通过将个体按预测风险分为10个风险十分位数组来绘制校准曲线,每条曲线均展示了各风险十分位数组的平均预测风险与观察到的风险。观察到的风险采用Kaplan-Meier估计法计算。在基于美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)干预组的外部验证中,UCL模型表现出良好的校准度,尤其是在通常设定筛查资格的1%-2%预测风险区间内。在此风险区间内,肺癌死亡风险评估工具(LCDRAT)、肺癌风险评估工具(LCRAT)和PLCOm2012模型在美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)干预组中均存在轻微的风险低估情况。除利物浦肺癌项目2版(LLPv2)模型存在明显的风险高估外,所有模型在英国生物银行队列中均存在轻微的风险高估情况。(注:LCDRAT为肺癌死亡风险评估工具;LCRAT为肺癌风险评估工具;UCL-D模型用于预测肺癌死亡风险;UCL-I模型用于预测肺癌发病风险)
(注:理想的校准度为1,即预期癌症病例数与观察到的癌症病例数相等。UCL模型在大多数亚组中均表现出良好的校准度,尤其在不同年龄组、不同性别和不同吸烟状态人群中校准效果较好。由于部分亚组的结局事件数量较少,某些亚组的置信区间较宽。值得注意的是,所有模型在至少一个种族亚组中均存在风险低估情况。在对比模型中作为预测变量、但未纳入UCL模型的变量所对应的人群(如慢性阻塞性肺疾病患者和有肺癌家族史的人群)中,部分模型也存在风险低估情况。COPD为慢性阻塞性肺疾病;PLCO为美国前列腺、肺、结直肠和卵巢癌症筛查试验;LLPv2为利物浦肺癌项目2版模型;LCDRAT为肺癌死亡风险评估工具;LCRAT为肺癌风险评估工具;UCL-D模型用于预测肺癌死亡风险;UCL-I模型用于预测肺癌发病风险。)
区分度
尽管UCL-D模型使用的变量数量仅为肺癌死亡风险评估工具(LCDRAT)的约四分之一,但在区分度方面,UCL-D模型与肺癌死亡风险评估工具(LCDRAT)表现相当(LCDRAT的AUC为0.811,95%置信区间:0.793,0.829;UCL-D与LCDRAT的AUC差异比较,p=0.18)。UCL-I模型与PLCOm2012模型的区分度相当(PLCOm2012的AUC为0.792,95%置信区间:0.779,0.808;UCL-I与PLCOm2012的AUC差异比较,p=0.15),且UCL-I模型的区分度显著高于利物浦肺癌项目(LLP)2版和3版模型(p<0.001)。
校准度
在通常设定筛查资格的风险阈值范围内,UCL模型的校准效果良好;在美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)胸部X线检查组中,UCL模型在最高风险十分位数组中仅存在轻微的风险低估(图2)。与之相比,PLCOm2012模型和肺癌风险评估工具(LCRAT)在观察风险为1%-4%的十分位数组中存在轻微的风险低估,而这种风险低估在临床实践中比风险高估的不利影响更大。由于PLCOm2012模型、肺癌死亡风险评估工具(LCDRAT)和肺癌风险评估工具(LCRAT)均基于美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)对照组开发,因此UCL模型所展现出的优异相对性能值得关注。除利物浦肺癌项目(LLP)2版模型存在明显的风险高估外,所有模型在英国生物银行队列中均存在轻微的风险高估情况。
整体性能
布里尔分数(Brier score)是衡量模型整体性能的指标,用于比较预测概率与实际结局的接近程度[37]。在英国生物银行和美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)胸部X线检查组中,各模型的布里尔分数差异较小或无差异(详见S1附录中的表L-M)。在美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)胸部X线检查组中,用于预测5年肺癌死亡风险的UCL-D模型和肺癌死亡风险评估工具(LCDRAT)的布里尔分数均为0.0084(95%置信区间:0.0075,0.0093)。布里尔分数会随疾病患病率的变化而变化,因此用于预测肺癌发病风险的模型布里尔分数更高。尽管如此,这些模型仍呈现出相同的性能模式:UCL-I模型的布里尔分数为0.0153(95%置信区间:0.0142,0.0164),肺癌风险评估工具(LCRAT)的布里尔分数为0.0152(95%置信区间:0.0143,0.0164),利物浦肺癌项目(LLP)2版模型的布里尔分数为0.0153(95%置信区间:0.0143,0.0165)。
筛查人群选择的风险阈值
根据美国预防服务工作组(USPSTF)2021年标准,在整个美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)数据集中,有34,654人(43.0%)符合肺癌筛查资格。在特异性相同的情况下,所有UCL模型的灵敏度均高于美国预防服务工作组(USPSTF)2021年标准,且预测5年肺癌死亡风险的模型灵敏度提升幅度更大(详见S1附录中的表O)。对于UCL-I模型,在5年风险阈值为1.17%时,其灵敏度较美国预防服务工作组(USPSTF)2021年标准提高了6.2%(UCL-I的灵敏度为83.9%,95%置信区间:82.0%,86.1%;USPSTF-2021的灵敏度为77.7%,95%置信区间:75.8%,80.2%)。与之相比,在5年风险阈值为0.68%时,UCL-D模型的灵敏度较美国预防服务工作组(USPSTF)2021年标准提高了7.9%(UCL-D的灵敏度为85.5%,95%置信区间:82.8%,88.2%;USPSTF-2021的灵敏度为77.5%,95%置信区间:74.6%,80.9%)。
在上述风险阈值下,UCL-D模型筛选出的筛查人群中,96.2%的人同时也符合UCL-I模型的筛查资格。经过10年随访发现,在仅符合UCL-D模型筛查资格而不符合UCL-I模型筛查资格的人群中,其肺癌发病风险和死亡风险往往高于仅符合UCL-I模型筛查资格而不符合UCL-D模型筛查资格的人群,但这种差异无统计学意义(详见S1附录中的图J;Logrank检验:肺癌死亡风险差异的p=0.15;肺癌发病风险差异的p=0.41)。
通过决策曲线分析发现,在所有风险阈值下,UCL模型的净获益均高于基于美国预防服务工作组(USPSTF)2021年标准的筛查(图3和S1附录中的图K)。在建议的风险阈值下,除利物浦肺癌项目(LLP)模型外,其他对比风险模型的净获益均相当。
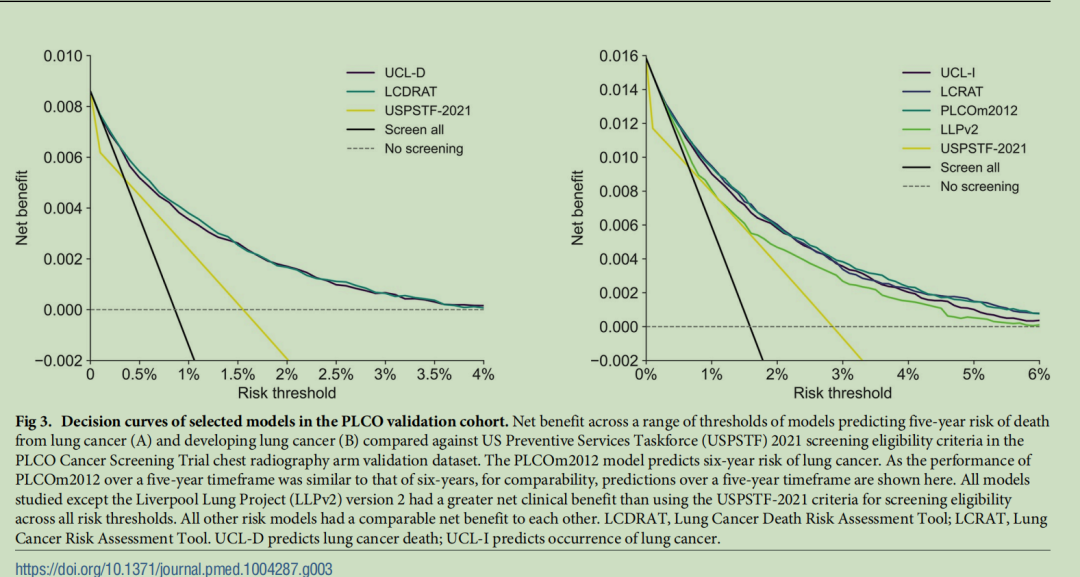
图3 美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)验证队列中所选模型的决策曲线:图A展示了预测5年肺癌死亡风险的模型在不同风险阈值下的净获益,并与美国预防服务工作组(USPSTF)2021年肺癌筛查资格标准进行对比;图B展示了预测5年肺癌发病风险的模型在不同风险阈值下的净获益,并与美国预防服务工作组(USPSTF)2021年肺癌筛查资格标准进行对比,所有分析均基于美国前列腺、肺、结直肠和卵巢癌症筛查试验(PLCO)胸部X线检查组验证数据集。PLCOm2012模型预测的是6年肺癌发病风险,由于该模型在5年和6年时间范围内的性能相近,为便于比较,此处展示其5年肺癌发病风险的预测结果。在所有风险阈值下,除利物浦肺癌项目2版(LLPv2)模型外,所有研究模型的临床净获益均高于基于美国预防服务工作组(USPSTF)2021年标准的筛查。其他所有风险模型之间的净获益均相当。(注:LCDRAT为肺癌死亡风险评估工具;LCRAT为肺癌风险评估工具;UCL-D模型用于预测肺癌死亡风险;UCL-I模型用于预测肺癌发病风险)
讨论
本研究开发了用于肺癌筛查的简约模型,该模型兼具现有基于风险因素标准的简洁性和复杂风险预测模型的预测性能。此外,基准对比结果表明,仅使用年龄、吸烟持续时间和吸烟包年数这三个预测变量的集成机器学习模型,其预测性能和临床实用性与需要11个预测变量的现有模型相当。
在本分析中,我们采用集成机器学习方法,综合了多个优化建模流程的预测结果。集成建模的核心原理是:不同模型会产生不同类型的误差,这些误差可在一定程度上相互抵消,因此将多个统计模型结合使用,有望提升单一模型的性能[52]。AutoPrognosis软件通过反复试验和优化多种建模方法,随后对这些方法进行集成,确保筛选出针对特定数据集的最优性能模型,同时通过清晰展示模型选择过程,保证研究的可重复性,从而避免了开发多个独立模型的需求。
在英国,国家卫生服务体系(NHS)肺癌筛查试点项目的资格认定标准为:利物浦肺癌项目(LLP)风险评分对应的5年肺癌绝对风险≥2.5%,或PLCOm2012模型对应的6年肺癌绝对风险≥1.51%[23]。目前同时采用这两种风险评分标准,且两种标准下的筛查资格对应的预测绝对风险差异超过1个百分点(5年风险阈值高于6年风险阈值),这凸显了在特定场景下选择最优基于风险筛查方法所面临的政策挑战。该资格认定方法需要收集17个不同的独特变量,还需将美国的教育水平分类和种族分类标准转换为英国对应的标准。据估计,英国目前约有700万现吸烟者[25](暂不考虑曾吸烟者),要在人群层面确定筛查资格,所需的时间和资源投入将面临巨大挑战。UCL模型仅使用三个明确的变量,却能达到与现有模型相当或更优的性能,因此可通过在线工具或基层医疗机构便捷地使用该模型,从而简化肺癌筛查的实施流程。
仅使用少量预测变量可能存在一个潜在问题,即模型在不同亚组中的性能可能欠佳。然而,在所有主要亚组中,UCL模型的性能均与现有模型相当,且在本分析涵盖的所有4个种族亚组中均表现良好。此外,UCL模型在不同亚组中的校准效果也较好,未出现因性别、吸烟状态或年龄不同而导致的校准差异。但在对比模型中作为预测变量的两个人群亚组(慢性阻塞性肺疾病患者和有肺癌家族史的人群)中,UCL模型存在一定程度的校准不足。此外,所有模型在至少一个种族亚组中均存在校准不足的情况。由于大多数模型的区分度良好,这表明可考虑降低风险阈值(尤其针对黑人人群),这与美国预防服务工作组(USPSTF)在2013年至2021年筛查建议中放宽年龄和吸烟强度标准的做法类似[53]。尽管仅将种族作为预测变量纳入模型对改善校准效果的作用有限,但仍需开展更多研究,以提高模型在不同种族人群中的校准度。
与Katki等人的研究结果一致[19],本研究发现,用于预测肺癌死亡风险的UCL-D模型,其区分度高于用于预测肺癌发病风险的模型。分析结果显示,UCL-D模型和UCL-I模型筛选出的筛查人群重叠率超过96%;经过长期随访发现,仅符合UCL-D模型筛查资格而不符合UCL-I模型筛查资格的人群,其肺癌死亡风险往往更高(详见S1附录中的图J)。微观模拟建模研究表明,使用预测肺癌死亡风险的模型与使用预测肺癌发病风险的模型相比,整体结局差异较小[13]。因此,UCL-D模型更适合用于临床实践。
本研究具有以下优势:首先,模型开发和验证均基于大型前瞻性队列;其次,外部验证队列在时间和地理分布上均与开发队列存在显著差异;再次,我们采用稳健的方法进行模型开发和内部验证,同时通过多种方法在广泛的亚组中对模型进行了全面的外部验证;此外,我们将所开发的模型与主流对比模型进行了基准对比;最后,UCL模型仅使用少量明确的变量,经过进一步验证和(必要时的)重新校准后,可在广泛场景中应用,且我们已公开模型,便于其他研究者进行独立评估。
本研究也存在一些局限性:第一,研究采用回顾性数据,因此将模型用于前瞻性确定筛查资格时,研究结果可能存在差异。不过,PLCOm2012模型和利物浦肺癌项目(LLP)模型已在前瞻性研究中得到验证,证实了基于风险模型的筛查相比基于风险因素的筛查具有显著优势。通过与这些模型进行基准对比,我们有理由相信UCL模型在筛查项目中的性能可靠。第二,为验证模型的通用性,需在英美以外的数据集上进行进一步验证,这将是我们未来的研究方向。第三,本研究分析基于研究队列数据,而非能更好反映普通人群特征的常规电子健康记录数据。与本研究中作为基准对比的模型类似,由于电子健康记录中通常缺乏详细的吸烟数据[54],UCL模型在常规电子健康记录中的性能可能无法达到本研究中的水平。尽管如此,考虑到现有电子健康记录中预测变量存在缺失和编码不准确等已知问题[55],筛查项目不太可能依赖现有电子健康记录数据。第四,本研究开发的风险模型未纳入从不吸烟者。目前,尚无任何风险模型能够准确识别出从不吸烟者中符合现有肺癌筛查标准的高风险人群。
综上所述,本研究采用集成机器学习方法,明确以提高模型简约性为目标,该方法在多种疾病领域均具有应用前景。我们开发的肺癌筛查资格预测模型仅需三个变量(年龄、吸烟持续时间和吸烟包年数),其性能达到或超过现有已投入使用的风险模型。未来应在其他数据集中对该模型进行进一步验证,并开展前瞻性研究验证其在临床实践中的应用价值。
数据可用性声明
为方便使用UCL模型,我们已建立相关网站并公开模型:https://github.com/callta/lung-cancer-models。AutoPrognosis软件的基础代码可从以下链接获取:https://github.com/vanderschaarlab/AutoPrognosis。本研究使用的英国生物银行、美国国家肺癌筛查试验(NLST)和前列腺、肺、结直肠和卵巢(PLCO)癌症筛查试验数据均为授权使用(授权编号分别为68073、NLST-806和PLCO-801)。这些数据受材料转移协议限制,无法直接共享。但研究者可通过以下渠道申请获取这些数据:英国生物银行(https://www.ukbiobank.ac.uk/)和美国国立卫生研究院(PLCO数据申请链接:https://cdas.cancer.gov/plos/;NLST数据申请链接:https://cdas.cancer.gov/nlst/)。
相关课程推荐









