作者 | 丁彦军
本文为「恋习 Python」投稿
深陷抄袭之名、诉讼纠纷的《爱情公寓》终于上映了。
情怀粉们的力量不容小觑,截止到撰稿,《爱情公寓》票房已经突破 3.72 亿大关,稳坐票房冠军的宝座,院线排片占比高达 40.0%。
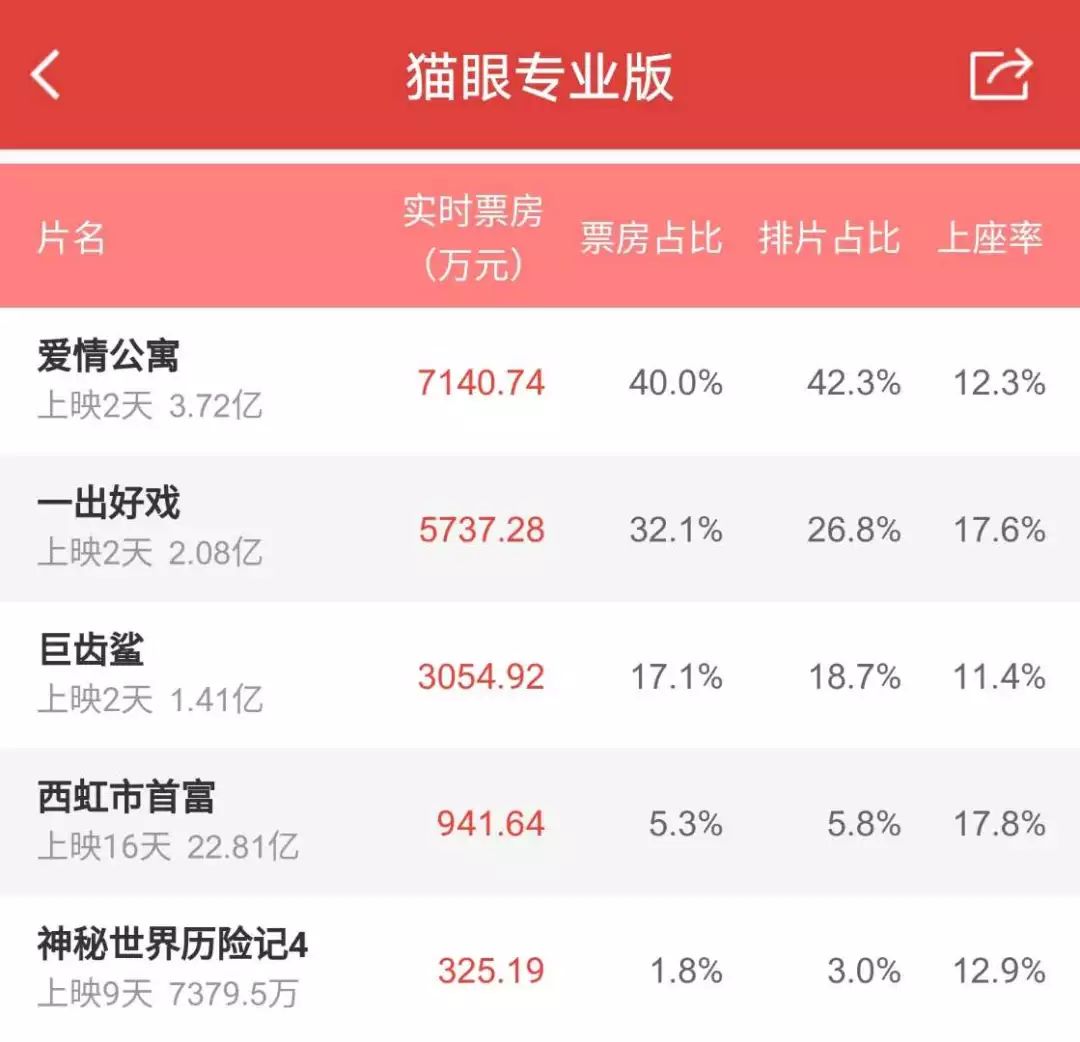
和超高票房背道而驰的,是各大社交平台上一边倒的差评。豆瓣万人打分,九成观众果断打了一星,只无奈豆瓣没有零星选项。

不知道有多少像我这样的情怀粉丝们,满怀期待地买了电影票,走进电影院,却发现是交了智商税。
豆瓣短评区里,观众们的状态已经出离愤怒,近乎暴走的状态。有人揭露电影挂羊头卖狗肉,电影内容和《爱情公寓》故事主线毫无关系,是山寨电影、诈骗电影、电影中的拼多多。
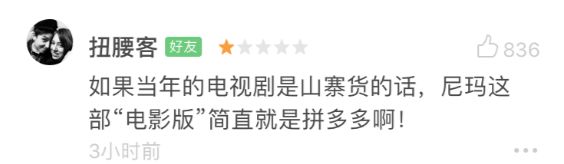
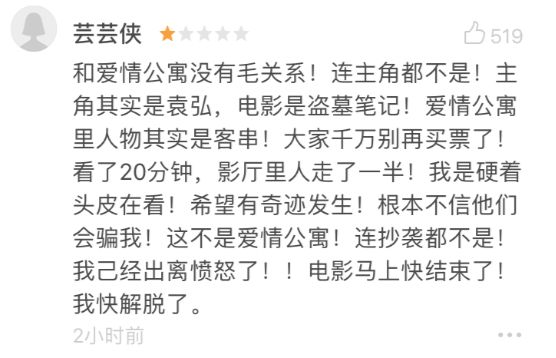
为了燃解我心头之恨,笔者将会跟你一起用猫眼上万条评论数据来分析,网友对这部电影的反响是否烂到刷新国产片不要脸的下限?
还是老规矩,整体思路将会从数据获取、数据清洗、数据可视化三部曲来进行:

数据获取清洗
整体思路与之前获取《邪不压正》评论一样,详情见《邪不压正》评分持续走低,上万条网友评论揭秘,是救救姜文还是救救观众?
具体代码如下:
import requests
import time
import
random
import json
def get_one_page(url):
response = requests.get(url=url)
if response.status_code == 200:
return response.text
return None
def parse_one_page(html):
data = json.loads(html)['cmts']
for item in data:
yield{
'date':item['time'].split(' ')[0],
'nickname':item['nickName'],
'city':item['cityName'],
'rate':item['score'],
'conment':item['content']
}
def save_to_txt():
for i in range(1,1001):
print("开始保存第%d页" % i)
url = 'http://m.maoyan.com/mmdb/comments/movie/1175253.json?_v_=yes&offset=' + str(i)
html = get_one_page(url)
for item in parse_one_page(html):
with open('爱情公寓.txt','a',encoding='utf-8') as f:
f.write(item['date'] + ','+item[
'nickname'] +','+item['city'] +','
+str(item['rate']) +',' +item['conment']+'\n')
time.sleep(2)
def delete_repeat(old,new):
oldfile = open(old,'r',encoding='utf-8')
newfile = open(new,'w',encoding='utf-8')
content_list = oldfile.readlines()
content_alread = []
for line in content_list:
if line not in content_alread:
newfile.write(line+'\n')
content_alread.append(line)
if __name__ == '__main__':
save_to_txt()
delete_repeat(r'爱情公寓_old.txt',r'爱情公寓_new.txt')

数据分析可视化
我们将用 Python 的两个模块 Pandas 与 pyecharts:
pyecharts 是一个用于生成 Echarts 图表的类库。Echarts 是百度开源的一个数据可视化 JS 库。用 Echarts 生成的图可视化效果非常棒,pyecharts 是为了与 Python 进行对接,方便在 Python 中直接使用数据生成图。(详情请看:http://pyecharts.org/)
Pandas 是基于 NumPy 的一个非常好用的库,正如名字一样,人见人爱。之所以如此,就在于不论是读取、处理数据,用它都非常简单。Pandas 有两种自己独有的基本数据结构。要使用 pandas,首先就得熟悉它的两个主要数据结构:Series 和 DataFrame。其中 Series 的性质和 Python 中原生的 dict 差不多,一个 key 对应一个 vaule,而且 key 必须是唯一的;DataFrame(以下简称 df)的性质则和 SQL 中的 table 差不多(详情请看:http://pandas.pydata.org/)。
真可谓电影界的“拼多多”。
我们把城市打分情况投射到地图中,可以看出:
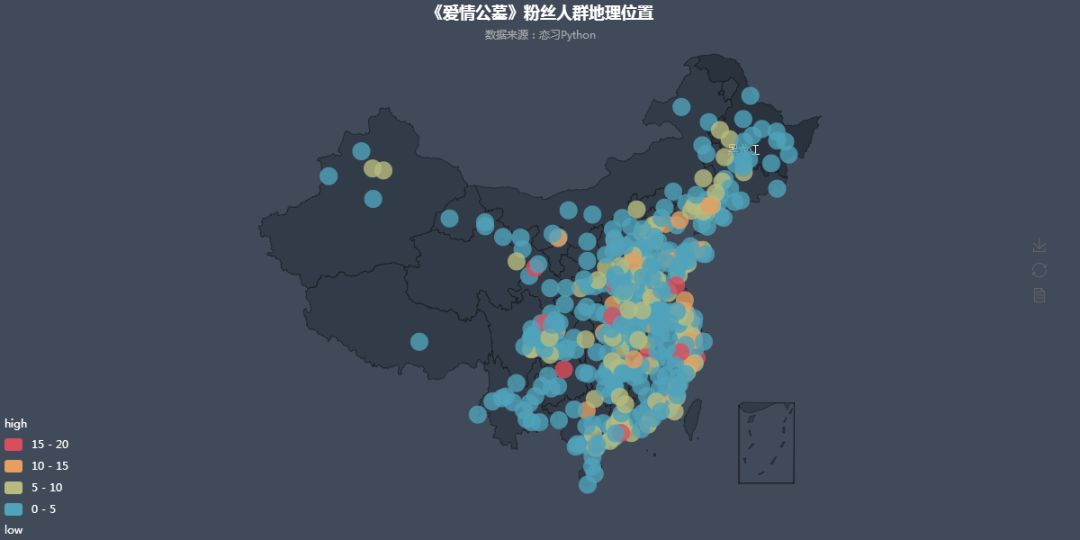
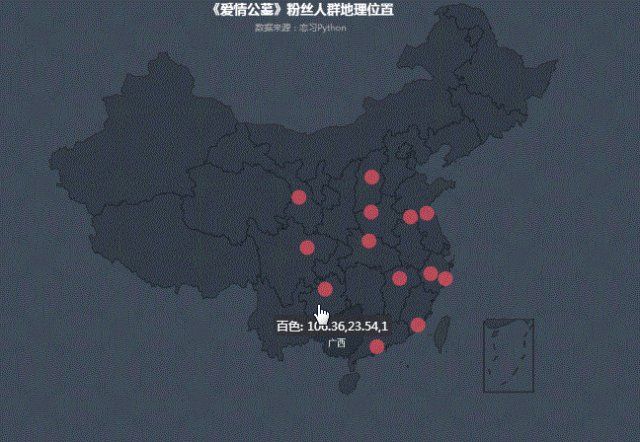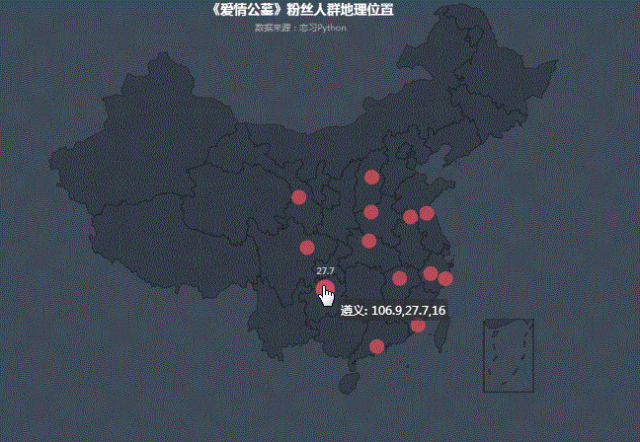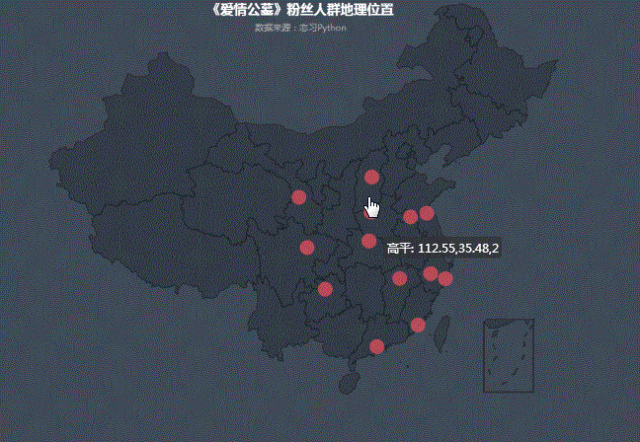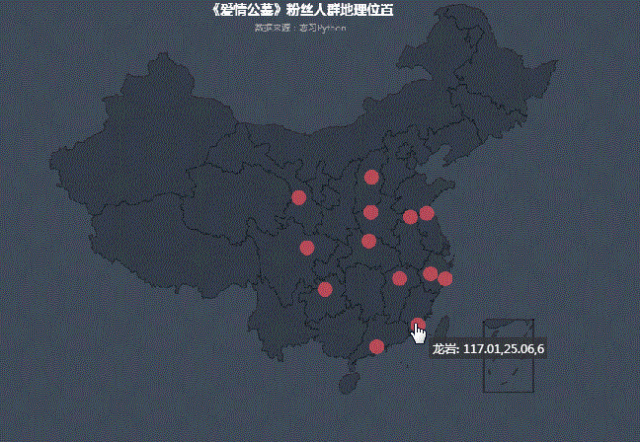
在热力图中,白银、绵阳、遵义等三四线城市热度相对高点,也可看出随着人们消费水平的升级,去电影院看电影是娱乐首选。在满足普通人民精神娱乐需求方面,但也不能挂羊头卖狗肉,电影内容和《爱情公寓》故事主线毫无关系。这难道不是电影界的拼多多么?
评分清一色,均为 3 星级
图为主要城市的评论数量与打分情况:
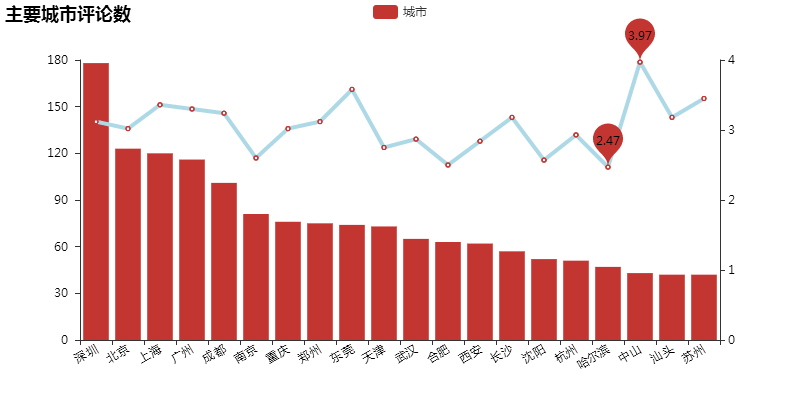
由图中可看出,各大城市观众打分均为 3 星级左右,这与猫眼评分 6.6 基本吻合;打出最高分与最低分分别是哈尔滨与中山。同时也能看出,一二线城市观众对此很失望。
有些人的良心被狗吃了?
看过了评分,我们看一下评论生成的词云图:

由词云图可以看出,爱情公寓、盗墓电影二词显目在列,整部电影就 30 秒和《爱情公寓》有关,所谓的集齐原班人马回归也只是个幌子,《爱情公寓》大电影完全是一部盗墓笔记,真正毁了《爱情公寓》这个 IP,也毁了《盗墓笔记》这个 IP。
但即便是在这样观众一致认为彻底失望的情况之下,依然有一波忠实的『粉丝们』坚守阵地。他们的手中依然紧握着情怀牌,打分也是一水的五星。
对于这些水军以及说《爱情公寓》好看的人,大家可以绝交了;作为观众,任何的关注都是助长《爱情公寓》的嚣张气焰,我们也有责任自发抵制烂片,决不让诈骗电影多赚一分钱。
以上信息具体代码为:
from wordcloud import WordCloud,STOPWORDS
import pandas as pd
import jieba
import matplotlib.pyplot as plt
from pyecharts import Geo,Style,Line,Bar,Overlap
f = open('爱情公寓_new.txt',encoding='utf-8')
data = pd.read_csv(f,sep=',',header=None,encoding='utf-8',names=['date','nickname','city','rate','comment'])
city = data.groupby(['city'])
rate_group = city['rate']
city_com = city['rate'].agg(['mean','count'])
city_com.reset_index(inplace=True)
city_com['mean'] = round(city_com['mean'],2)
data_map = [(city_com['city'][i],city_com['count'][i]) for i in range(0,city_com.shape[0])]
style = Style(title_color="#fff",title_pos = "center",
width = 1200,height = 600,background_color = "#404a59")
geo = Geo("《爱情公墓》粉丝人群地理位置","数据来源:恋习Python",**style.init_style)
while True:
try:
attr,val = geo.cast(data_map)
geo.add("",attr,val,visual_range=[0,20],
visual_text_color="#fff",symbol_size=20,
is_visualmap=True,is_piecewise=True,
visual_split_number=4)
except ValueError as e:
e = str(e)
e = e.split("No coordinate is specified for ")[1]
for i in range(0,len(data_map)):
if e in data_map[i]:
data_map.pop[i]
break
else:
break
geo.render('爱情公墓.html')
city_main = city_com.sort_values('count'
,ascending=False)[0:20]
attr = city_main['city']
v1 = city_main['count']
v2 = city_main['mean']
line = Line("主要城市评分")
line.add("城市",attr,v2,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
mark_point=['min','max'],xaxis_interval=0,line_color='lightblue',
line_width=4,mark_point_textcolor='black',mark_point_color='lightblue',
is_splitline_show=False)
bar = Bar("主要城市评论数")
bar.add("城市",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
xaxis_interval=0,is_splitline_show=False)
overlap = Overlap()
overlap.add(bar)
overlap.add(line,yaxis_index=1,is_add_yaxis=True)
overlap.render('主要城市评论数_平均分.html')
comment = jieba.cut(str(data['comment']),cut_all=False)
wl_space_split = " ".join(comment)
backgroud_Image = plt.imread('lan.jpg')
stopwords = STOPWORDS.copy()
wc = WordCloud(width=1024,height=768,background_color='white',
mask=backgroud_Image,font_path="C:\simhei.ttf",
stopwords=stopwords,max_font_size=400,
random_state=50)
wc.generate_from_text(wl_space_split)
plt.imshow(wc)
plt.axis('off')
plt.show()
wc.to_file(r'laji.jpg')
最后,作为《爱情公寓》之前的铁粉,只想评价一个字:烂。
烂在哪里?并不是烂在盗墓剧情,也不烂在演员特效。烂在它消费粉丝热情和爱戴,玩弄观众。
2.4 分我想更多是对韦正和汪远的评价。为了赚钱,上映前吹嘘夸大,不设点映;为了赚钱,宣传片预告片 MV 大量回忆杀,关谷展博无限出镜;为了赚钱,藏着掖着不见光不露脸,以 9.9 分的保票“催”着粉丝买预售票。上映第一天 3 亿。赚的盆满钵满。
反过来看观众,哭着脸走出影院的,多数是被结尾彩蛋感动,彩蛋才真正传达了“爱情公寓精神”。主演们对着镜头的自白,说出了我们最想听到的几段话,才真正唤起了我们脑海里对爱情公寓的美好回忆。
电影结尾的彩蛋,小姨妈呼唤关谷的那一段,算是爱情公寓最感人的地方了吧。

但是,一个彩蛋真的配 3 亿票房吗?
用近乎做作的犹抱琵琶半遮面的营销手段,让大家对它憧憬,希望它能给我们的记忆画上一个圆满的句号,可却用一部近乎玩笑的垃圾影片嘲笑我们对它的喜爱。
打着情怀的旗号,将一个个剧版粉丝骗进电影院,将电影票钱装进自己的腰包。
这就是它最烂的地方。
声明:本文为作者投稿,版权归对方所有。作者独立观点,不代表 CSDN 立场。
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。
————— 推荐阅读 —————