正值火辣的暑假,朋友圈已经被大家的旅行足迹刷屏了,真的十分惊叹于那些把全国所有省基本走遍的朋友们。与此同时,也就萌生了写篇旅行相关的内容,本次数据来源于一个对于爬虫十分友好的旅行攻略类网站:蚂蜂窝。

获得城市编号
蚂蜂窝中的所有城市、景点以及其他的一些信息都有一个专属的5位数字编号,我们第一步要做的就是获取城市(直辖市+地级市)的编号,进行后续的进一步分析。
以上两个页面就是我们的城市编码来源。需要首先从目的地页面获得各省编码,之后进入各省城市列表获得编码。
过程中需要Selenium进行动态数据爬取,部分代码如下:
def find_cat_url(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
req=request.Request(url,headers=headers)
html=urlopen(req)
bsObj=BeautifulSoup(html.read(),"html.parser")
bs = bsObj.find('div',attrs={'class':'hot-list clearfix'}).find_all('dt')
cat_url = []
cat_name = []
for i in range(0,len(bs)):
for j in range(0,len(bs[i].find_all('a'
))):
cat_url.append(bs[i].find_all('a')[j].attrs['href'])
cat_name.append(bs[i].find_all('a')[j].text)
cat_url = ['http://www.mafengwo.cn'+cat_url[i] for i in range(0,len(cat_url))]
return cat_url
def find_city_url(url_list):
city_name_list = []
city_url_list = []
for i in range(0,len(url_list)):
driver = webdriver.Chrome()
driver.maximize_window()
url = url_list[i].replace('travel-scenic-spot/mafengwo','mdd/citylist')
driver.get(url)
while True:
try:
time.sleep(2)
bs = BeautifulSoup(driver.page_source,'html.parser')
url_set = bs.find_all('a',attrs={'data-type':'目的地'})
city_name_list = city_name_list +[url_set[i].text.replace('\n','').split()[0] for i in range(0,len(url_set))]
city_url_list = city_url_list+[url_set[i].attrs['data-id'
] for i in range(0,len(url_set))]
js="var q=document.documentElement.scrollTop=800"
driver.execute_script(js)
time.sleep(2)
driver.find_element_by_class_name('pg-next').click()
except:
break
driver.close()
return city_name_list,city_url_list
url = 'http://www.mafengwo.cn/mdd/'
url_list = find_cat_url(url)
city_name_list,city_url_list=find_city_url(url_list)
city = pd.DataFrame({'city':city_name_list,'id':city_url_list})

获得城市信息
城市数据分别从以下几个页面获取:
(a)小吃页面

(b)景点页面

(c)标签页面

我们将每个城市获取数据的过程封装成函数,每次传入之前获得的城市编码,部分代码如下:
def get_city_info(city_name,city_code):
this_city_base = get_city_base(city_name,city_code)
this_city_jd = get_city_jd(city_name,city_code)
this_city_jd['city_name'] = city_name
this_city_jd['total_city_yj'] = this_city_base['total_city_yj']
try:
this_city_food = get_city_food(city_name,city_code)
this_city_food['city_name'] = city_name
this_city_food['total_city_yj'] = this_city_base['total_city_yj']
except:
this_city_food=pd.DataFrame()
return this_city_base,this_city_food,this_city_jd
def get_city_base(city_name,city_code):
url = 'http://www.mafengwo.cn/xc/'+str(city_code)+'/'
bsObj = get_static_url_content(url)
node = bsObj.find('div',{'class':'m-tags'}).find('div',{'class':'bd'}).find_all('a')
tag = [node[i].text.split()[0] for i in range(0,len(node))]
tag_node = bsObj.find('div'
,{'class':'m-tags'}).find('div',{'class':'bd'}).find_all('em')
tag_count = [int(k.text) for k in tag_node]
par = [k.attrs['href'][1:3] for k in node]
tag_all_count = sum([int(tag_count[i]) for i in range(0
,len(tag_count))])
tag_jd_count = sum([int(tag_count[i]) for i in range(0,len(tag_count)) if par[i]=='jd'])
tag_cy_count = sum([int(tag_count[i]) for i in range(0,len(tag_count)) if par[i]=='cy'])
tag_gw_yl_count = sum([int(tag_count[i]) for i in range(0,len(tag_count)) if par[i] in
['gw','yl']])
url = 'http://www.mafengwo.cn/yj/'+str(city_code)+'/2-0-1.html '
bsObj = get_static_url_content(url)
total_city_yj = int(bsObj.find('span',{'class':'count'}).find_all('span')[1].text)
return {'city_name':city_name,'tag_all_count':tag_all_count,'tag_jd_count':tag_jd_count,
'tag_cy_count':tag_cy_count,'tag_gw_yl_count':tag_gw_yl_count,
'total_city_yj':total_city_yj}
def get_city_food(city_name,city_code):
url = 'http://www.mafengwo.cn/cy/'+str(city_code)+'/gonglve.html'
bsObj = get_static_url_content(url)
food=[k.text for k in bsObj.find('ol',{'class':'list-rank'}).find_all('h3')]
food_count=[int(k.text) for k in bsObj.find('ol',{'class':'list-rank'}).find_all('span',{'class':'trend'})]
return pd.DataFrame({'food':food[0:len(food_count)],'food_count':food_count})
def get_city_jd(city_name,city_code):
url = 'http://www.mafengwo.cn/jd/'+str(city_code)+'/gonglve.html'
bsObj = get_static_url_content(url)
node=bsObj.find('div',{'class':'row-top5'}).find_all('h3')
jd = [k.text.split('\n')[2] for k in node]
node=bsObj.find_all('span',{'class':'rev-total'})
jd_count=[int
(k.text.replace(' 条点评','')) for k in node]
return pd.DataFrame({'jd':jd[0:len(jd_count)],'jd_count':jd_count})

数据分析
PART1:城市数据
首先我们看一下游记数量最多的TOP10城市:
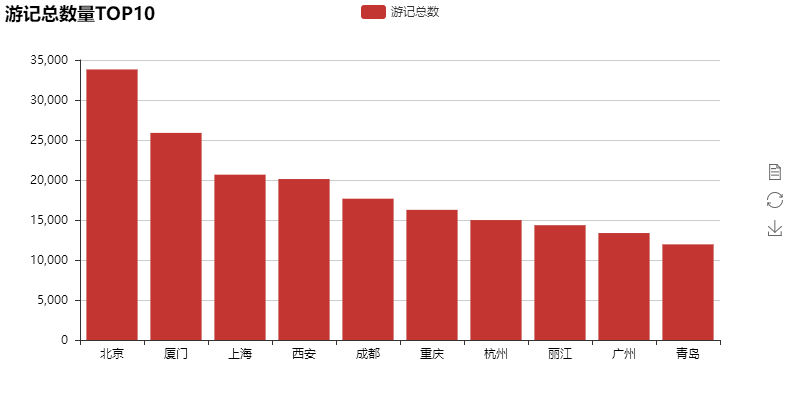
游记数量TOP10数量基本上与我们日常所了解的热门城市相符,我们进一步根据各个城市游记数量获得全国旅行目的地热力图:
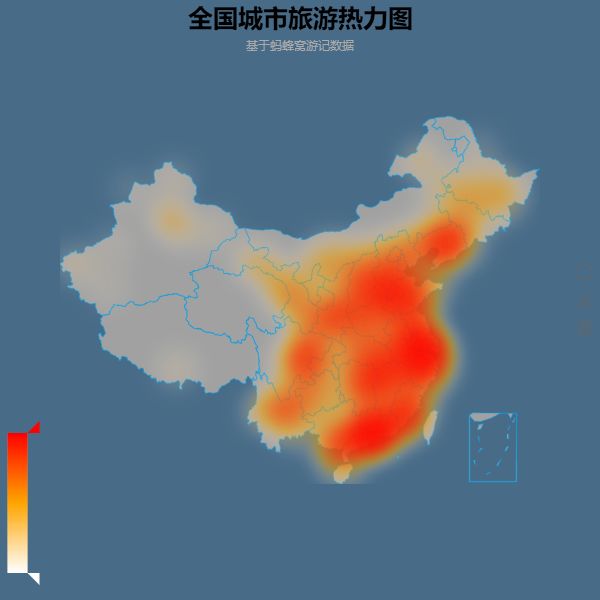
看到这里,是不是有种似曾相识的感觉,如果你在朋友圈晒的足迹图与这幅图很相符,那么说明蚂蜂窝的数据与你不谋而合。
最后我们看一下大家对于各个城市的印象是如何的,方法就是提取标签中的属性,我们将属性分为了休闲、饮食、景点三组,分别看一下每一组属性下大家印象最深的城市:
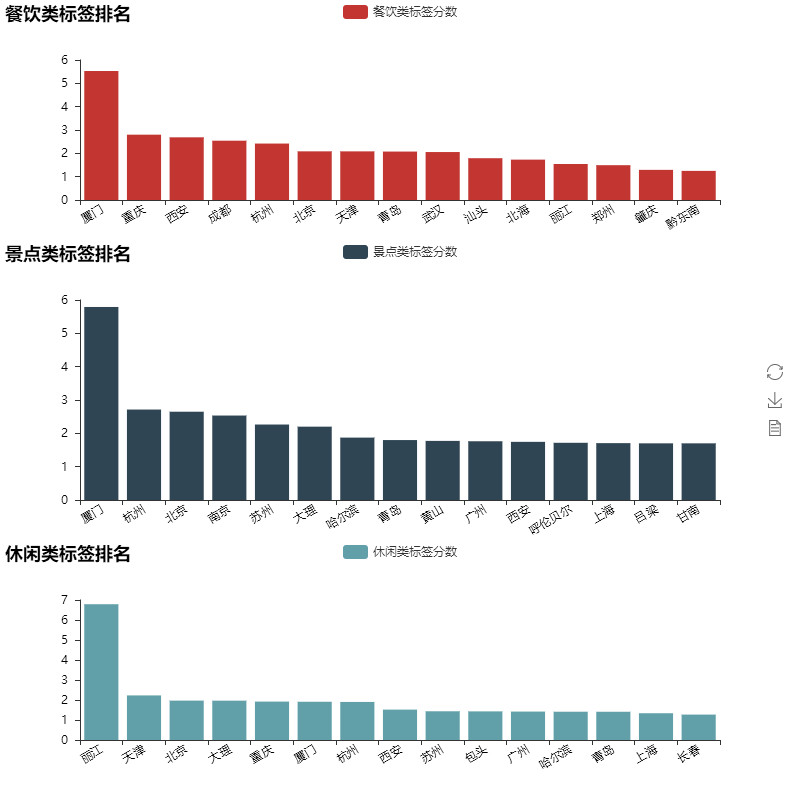
看来对于蚂蜂窝的用户来说,厦门给大家留下的印象是非常深的,不仅游记数量充足,并且能从中提取的有效标签也非常多。重庆、西安、成都也无悬念地给吃货们留下了非常深的印象,部分代码如下:
-
bar1 = Bar("餐饮类标签排名")
bar1.add("餐饮类标签分数", city_aggregate.sort_values('cy_point',0,False)['city_name'][0:15],
city_aggregate.sort_values('cy_point',0,
False)['cy_point'][0:15],
is_splitline_show =False,xaxis_rotate=30)
bar2 = Bar("景点类标签排名",title_top="30%")
bar2.add("景点类标签分数", city_aggregate
.sort_values('jd_point',0,False)['city_name'][0:15],
city_aggregate.sort_values('jd_point',0,False)['jd_point'][0:15],
legend_top="30%",is_splitline_show =False,xaxis_rotate=
30)
bar3 = Bar("休闲类标签排名",title_top="67.5%")
bar3.add("休闲类标签分数", city_aggregate.sort_values('xx_point',0,False)['city_name'][0:15],
city_aggregate.sort_values('xx_point',0,False)['xx_point'][0:15],
legend_top="67.5%",is_splitline_show =False,xaxis_rotate=30)
grid = Grid(height=800
)
grid.add(bar1, grid_bottom="75%")
grid.add(bar2, grid_bottom="37.5%",grid_top="37.5%")
grid.add(bar3, grid_top="75%")
grid.render('城市分类标签.html')
PART2:景点数据
我们提取了各个景点评论数,并与城市游记数量进行对比,分别得到景点评论的绝对值和相对值,并据此计算景点的人气、代表性两个分数,最终排名TOP15的景点如下:
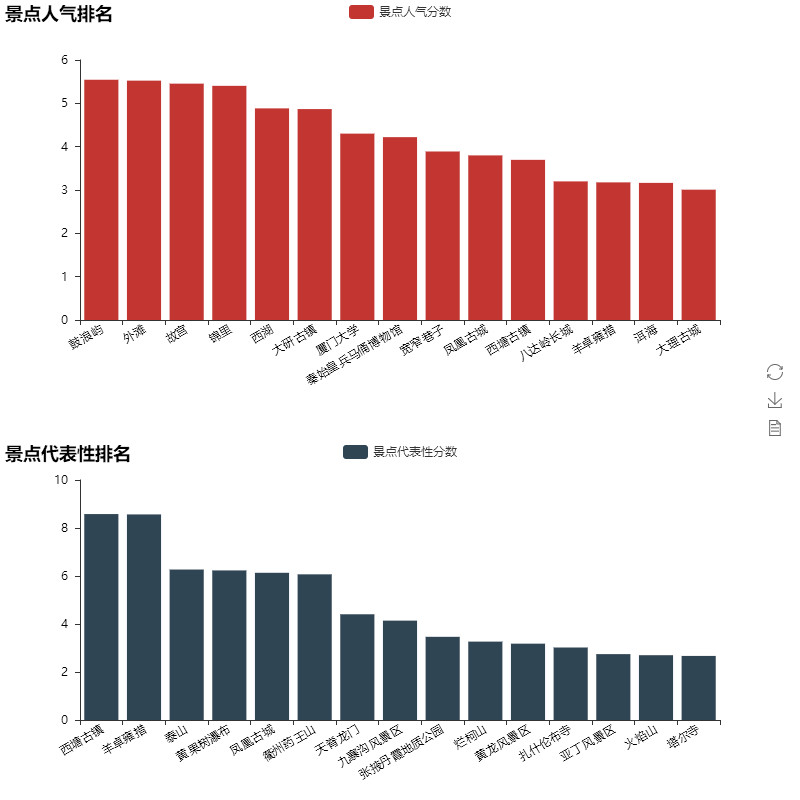
蚂蜂窝网友对于厦门真的是情有独钟,鼓浪屿也成为了最具人气的景点,在城市代表性方面西塘古镇和羊卓雍措位列前茅。暑假之际,如果担心上排的景点人太多,不妨从下排的景点中挖掘那些人少景美的旅游地。
PART3:小吃数据
最后我们看一下大家最关注的的与吃相关的数据,处理方法与PART2景点数据相似,我们分别看一下最具人气和最具城市代表性的小吃。
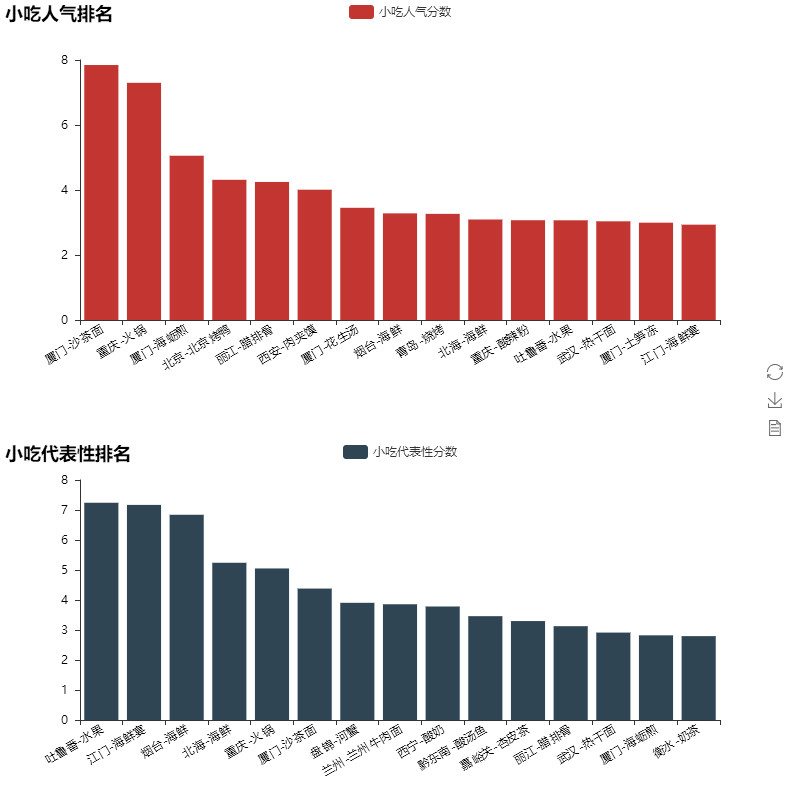
出乎意料,蚂蜂窝网友对厦门果真爱得深沉,让沙茶面得以超过火锅、烤鸭、肉夹馍跻身最具人气的小吃。
在城市代表性方面,海鲜的出场频率非常高,这点与大(ben)家(ren)的认知也不谋而合,PART2与3的部分代码如下:
bar1 = Bar("景点人气排名")
bar1.add("景点人气分数", city_jd_com
.sort_values('rq_point',0,False)['jd'][0:15],
city_jd_com.sort_values('rq_point',0,False)['rq_point'][0:15],
is_splitline_show =False,xaxis_rotate=30)
bar2 = Bar("景点代表性排名",title_top="55%")
bar2.add("景点代表性分数", city_jd_com.sort_values('db_point',0,False)['jd'][0:15],
city_jd_com.sort_values
('db_point',0,False)['db_point'][0:15],
is_splitline_show =False,xaxis_rotate=30,legend_top="55%")
grid=Grid(height=800)
grid
.add(bar1, grid_bottom="60%")
grid.add(bar2, grid_top="60%",grid_bottom="10%")
grid.render('景点排名.html')
文中所有涉及到的代码已经发到Github上了,欢迎大家自取:
https://github.com/shujusenlin/mafengwo_data。
作者:徐麟,知乎同名专栏作者,目前就职于上海唯品会产品技术中心,哥大统计数据狗,从事数据挖掘&分析工作,喜欢用R&Python玩一些不一样的数据。个人公众号:数据森麟(ID:shujusenlin)。
声明:本文为作者投稿,版权归对方所有。
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。
————— 推荐阅读 —————