作者 | zone7
责编 | 郭芮
多图预警、多图预警、多图预警。秋招季,毕业也多,跳槽也多。我们的职业发展还是要顺应市场需求,那么各门编程语言在深圳的需求怎么呢?工资待遇怎么样呢?笔者在上次写了《用Python告诉你深圳房租有多高》一文后,想继续用 Python 分析一下当前深圳的求职市场是怎样的,于是便爬取了某钩招聘数据。以下是本次爬虫的样本数据:
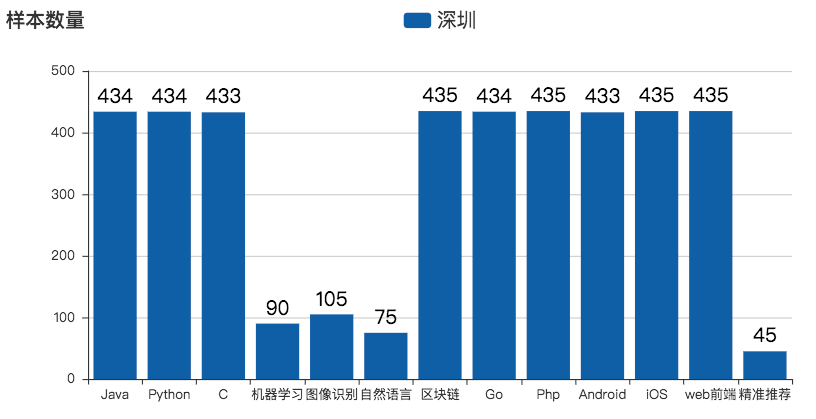
本次统计数据量为 4658 ,其中某拉钩最多能显示 30 页数据,每页 15 条招聘信息,则汇总为 450。首页爬取跳过一页,则为 435 条,故数据基本爬完。其余不够数量的语言为该语言在深圳只有这么多条招聘信息。

统计结果
如下表所示,根据统计,精准推荐、自然语言、机器学习、Go 语言、图像识别这几个平均工资较高。其中比较意外的是,炒得很火的区块链平均薪资并没有那么高,月薪约为 18.84 k。
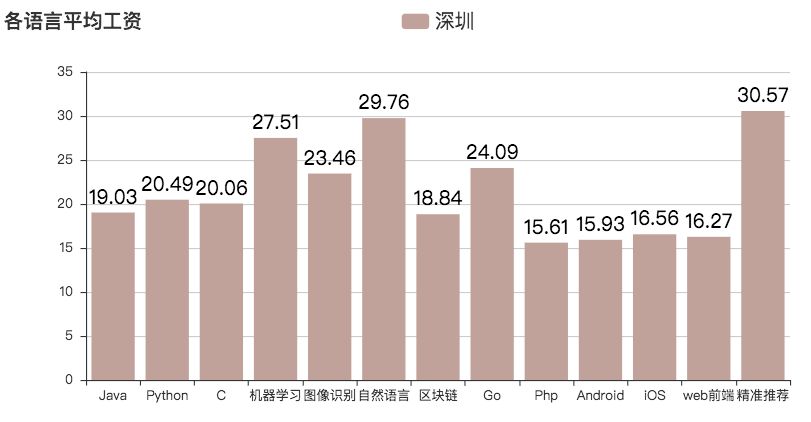
各语言平均薪资
统计完之后笔者发现自己严重拖后腿了......是不是该删库跑路了?
上面的平均工资计算方式如下:
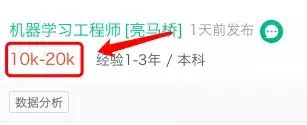
最高值与最低值,求平均数,以上面的薪资为例则为:(10k + 20k)/2 = 15k。最后,再总体求平均数。
公司福利词云:

看福利还是挺丰富的,带薪休假、下午茶、零食、节假日都有。
公司发展级别排行:
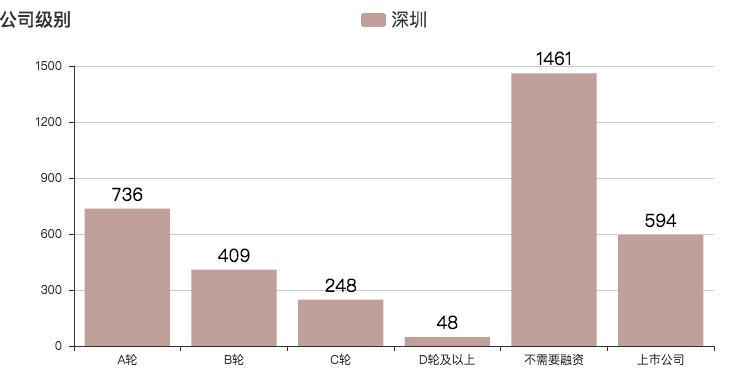
总体由 A 轮向 D 轮缩减,大部分公司不需要融资——估计是拿不到资本融资,但是自家人又有钱的情况。

各语言工作年限要求与学历要求
下面我们来看看各种本命语言的市场需求是怎样的?你又是否达标了呢?总体来看,三至五年的工程师职位需求最多,不怕找不到工作。还有一个趋势是,薪资越高,学历要求越高——学历的重要性不言而喻。
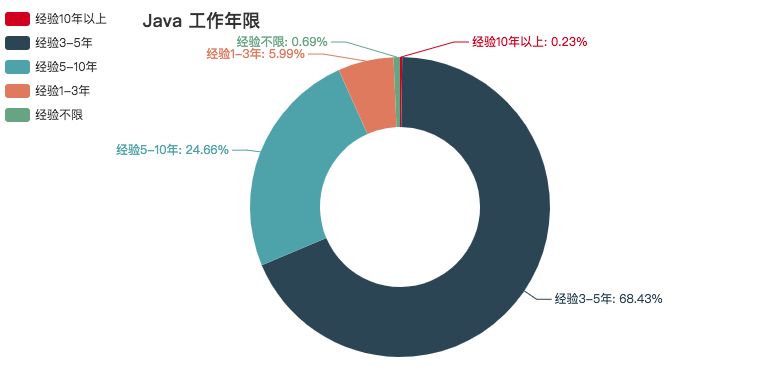
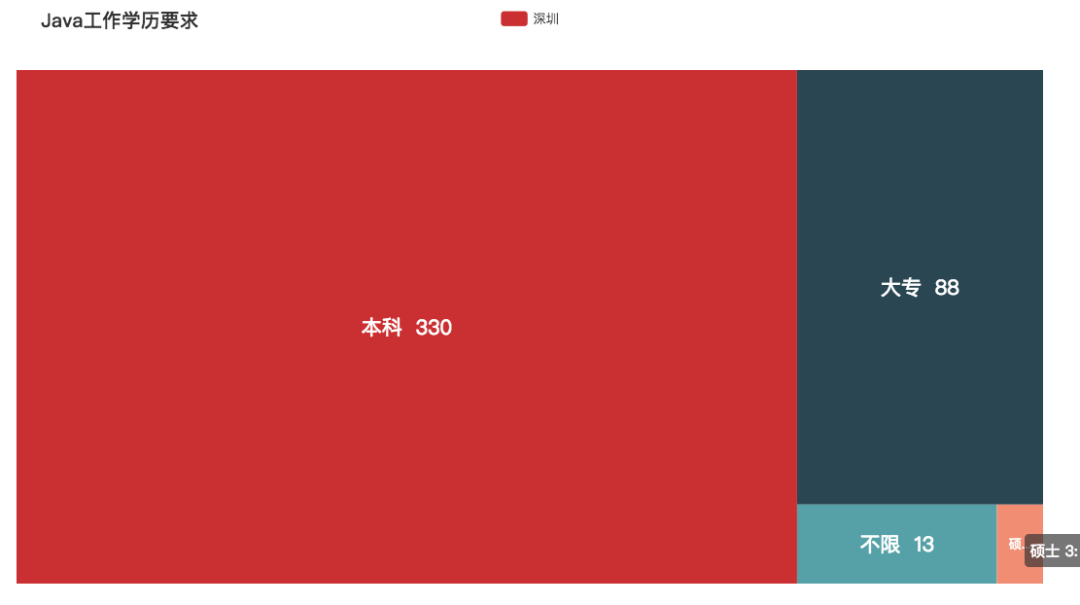
Java
Java 作为一门老牌编程语言,有些要求还是挺高的。为数不多的,有要求 5 - 10 年的。从总体来看,基本与学历没有太大的关联,只要技术到家就行。
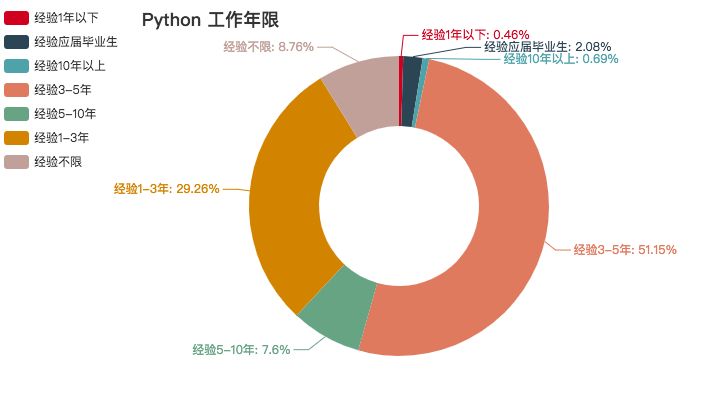
Python
Python 作为近年来备受追捧的语言,发展方向极其之多,AI 、web 后端、运维、爬虫等等都有涉及。其入门要求也不是特别高,基本上本科学历就能胜任多数工作,不过 AI 就要另当别论了。
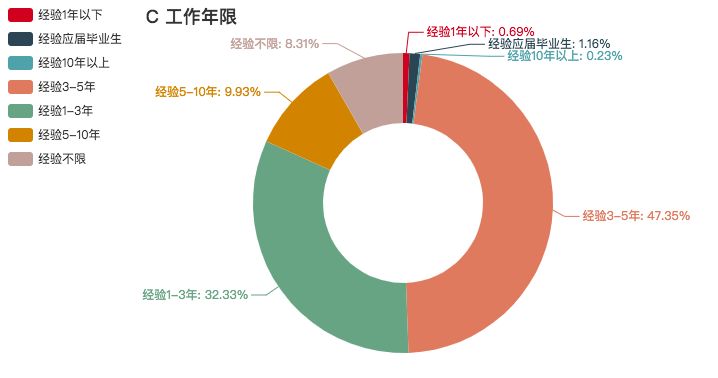
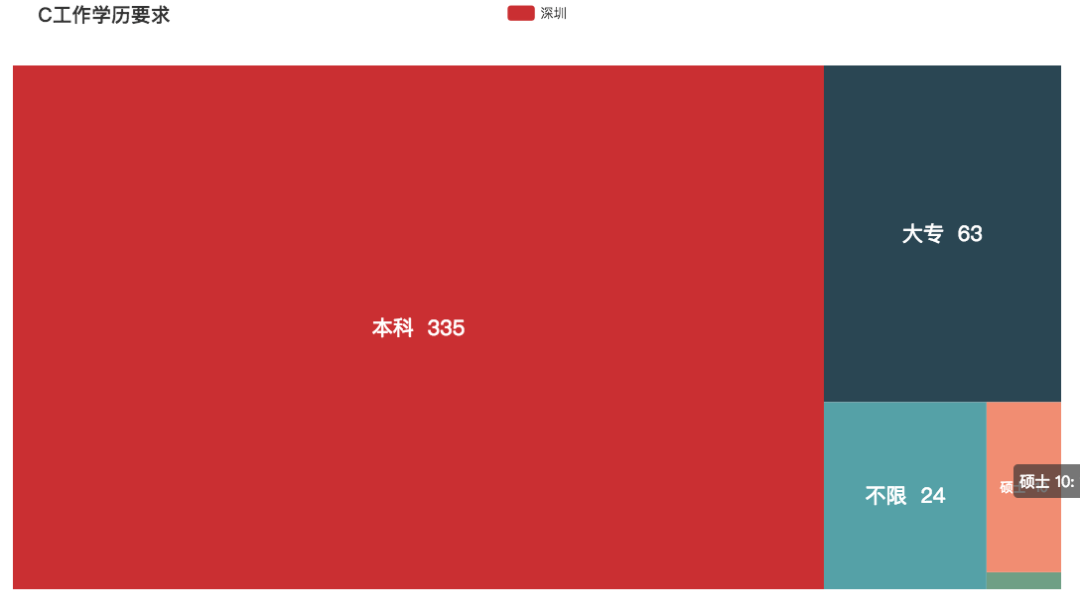
 C 语言
C 语言
同样是老牌编程语言的 C 语言,近年来学的人却似乎越来越少了。
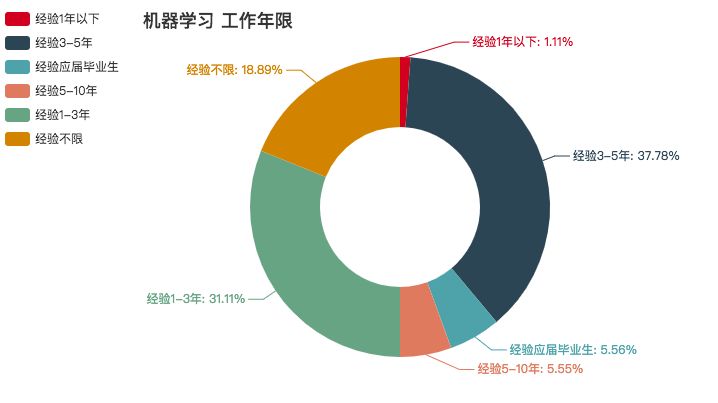
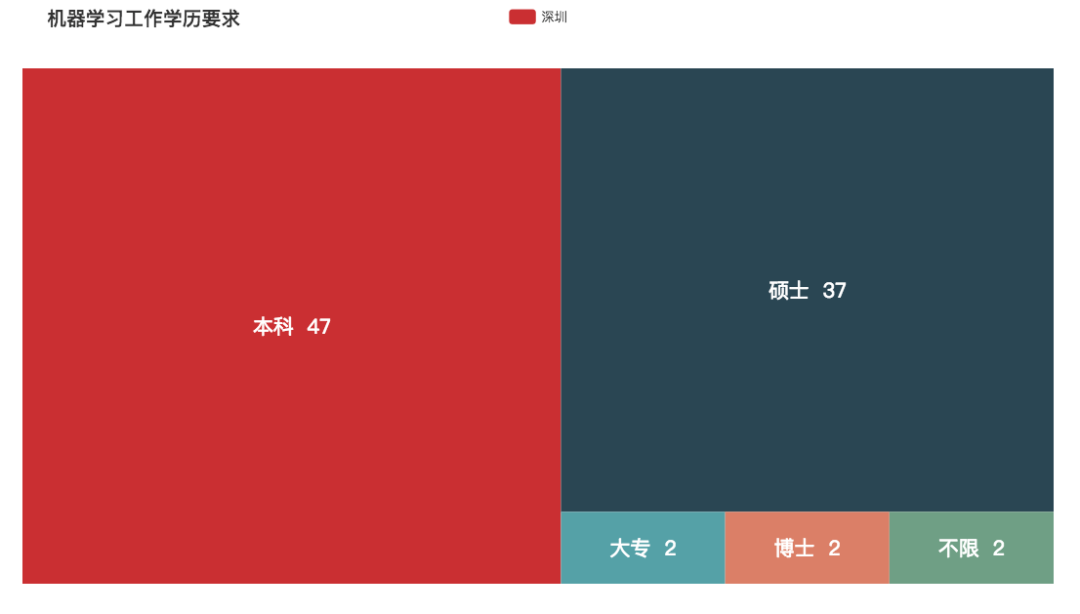
机器学习
是的,这一次感受到了学历的重要性了,硕士要求占了一大半!!我这个渣渣二本是入不了这行了,但工作年限要求没有非常高。
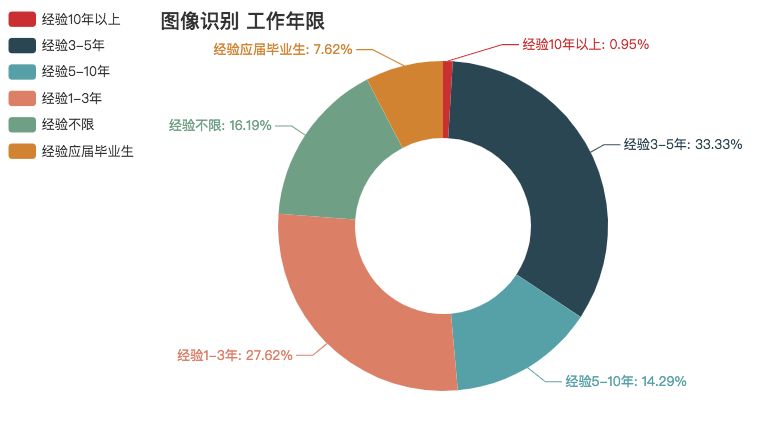
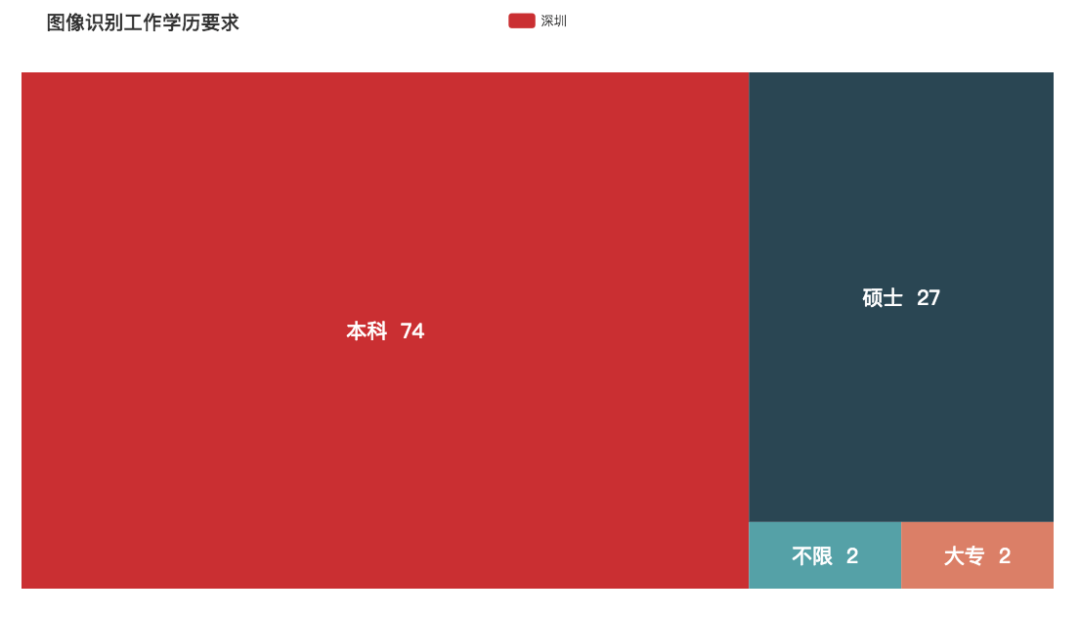
图像识别
图像识别薪资也高,学历要求也相对高一点。
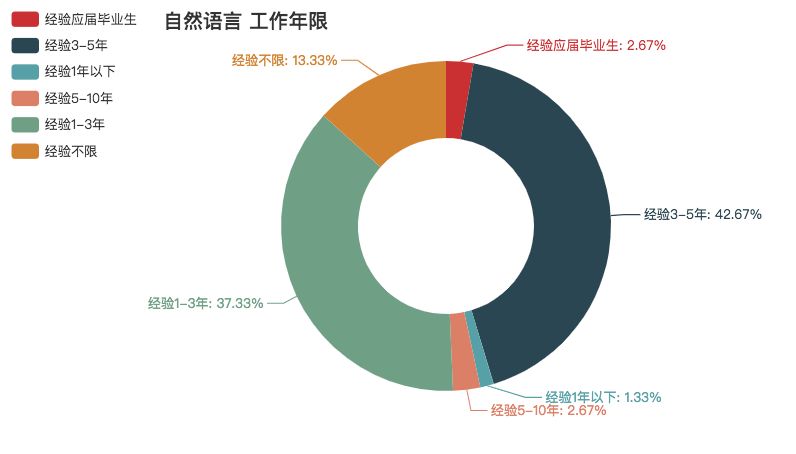
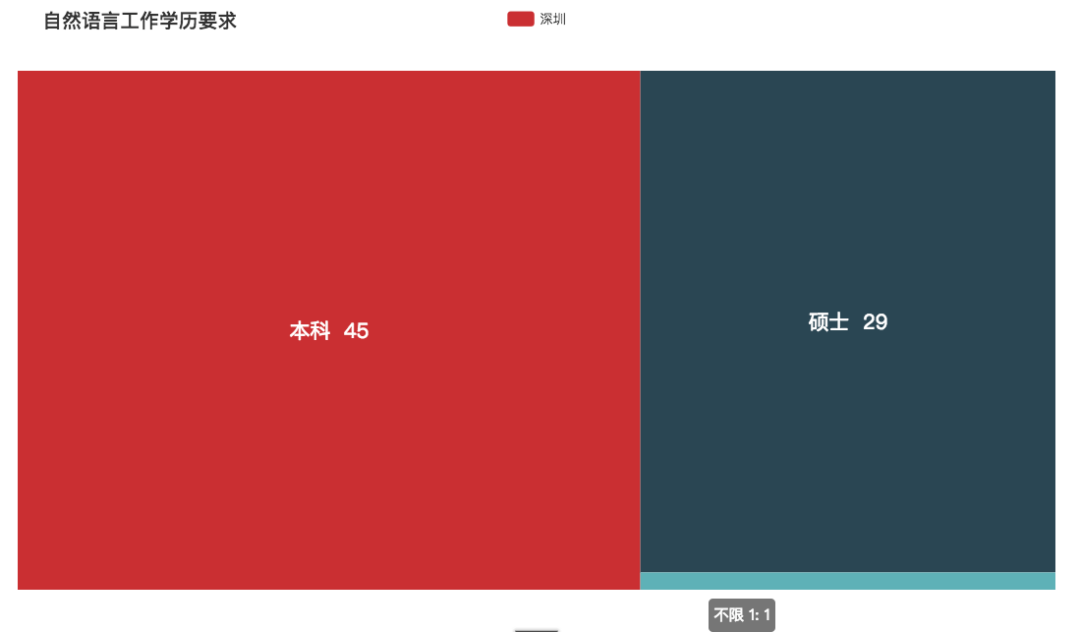
自然语言
果然,稀缺人才薪资都高,但这次它还伴有学历门槛,所以说要时刻都抱着学习的心态呀。
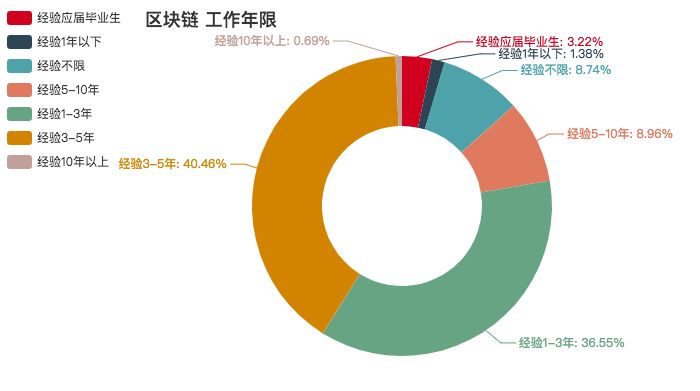
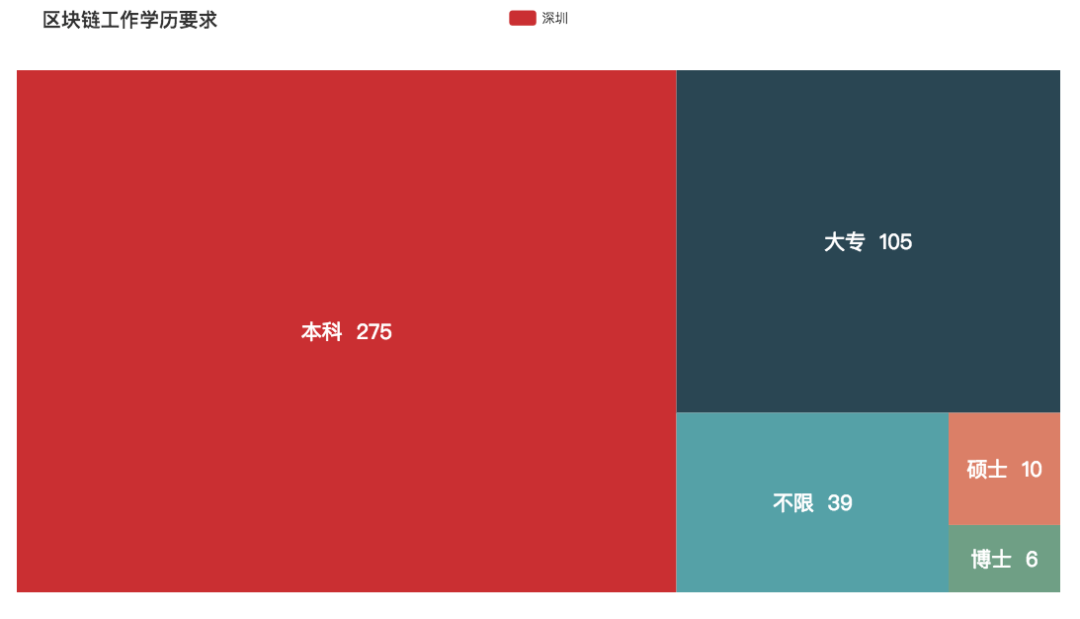
区块链
区块链概念刚火爆的时候,大街小巷都在讨论区块链,网上也随处都能看到区块链的字眼。但是随着一些区块链的暴雷,现在已经有了偃旗息鼓的态势了。从薪资来看,也没有十分之高,但是学历还是有要求的。
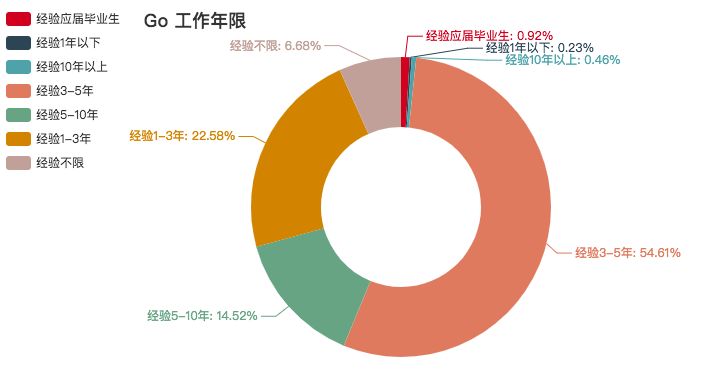
Go 语言

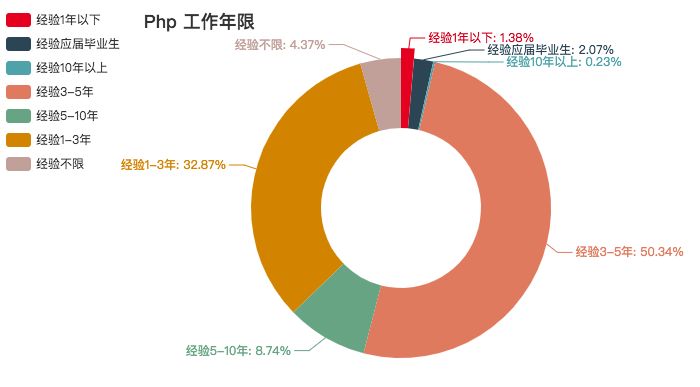
PHP
PHP 是世界上最好的编程语言,不解释。

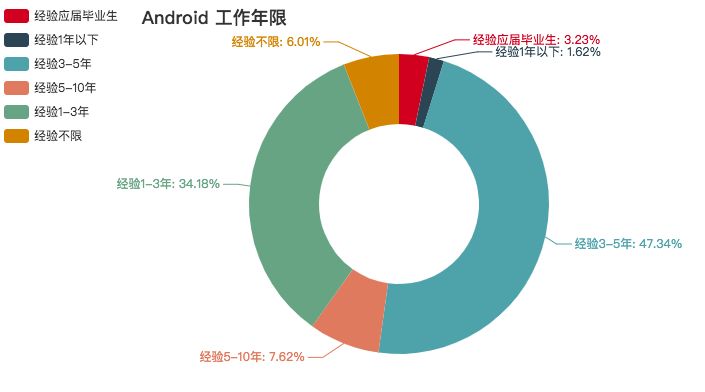
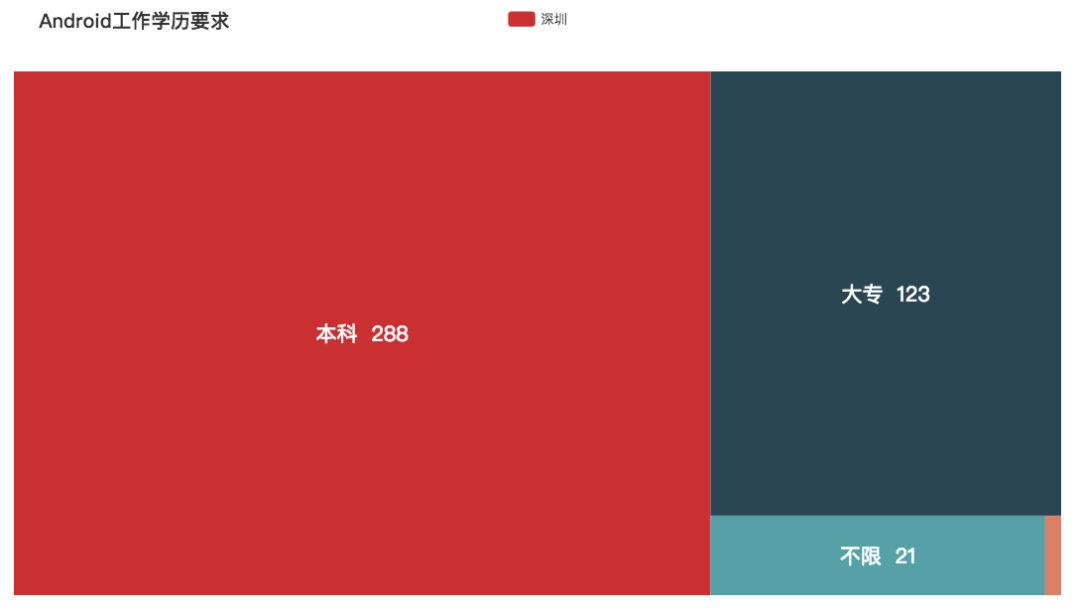
Android
这两年 Android 市场不断趋于饱和,再加上小程序与 H5 的冲击,已经稍微平稳下来了。不过在视频、音频处理方面还是很吃香的。
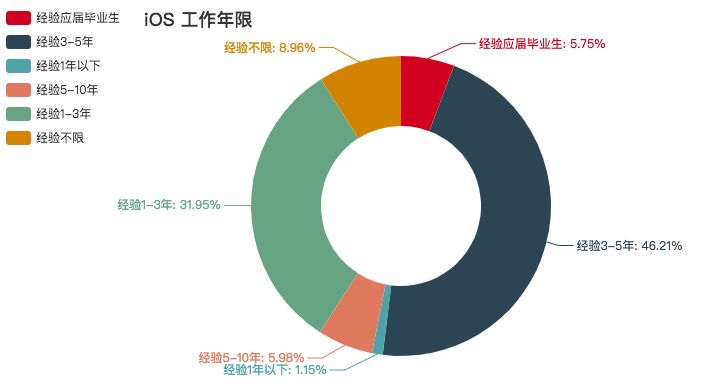
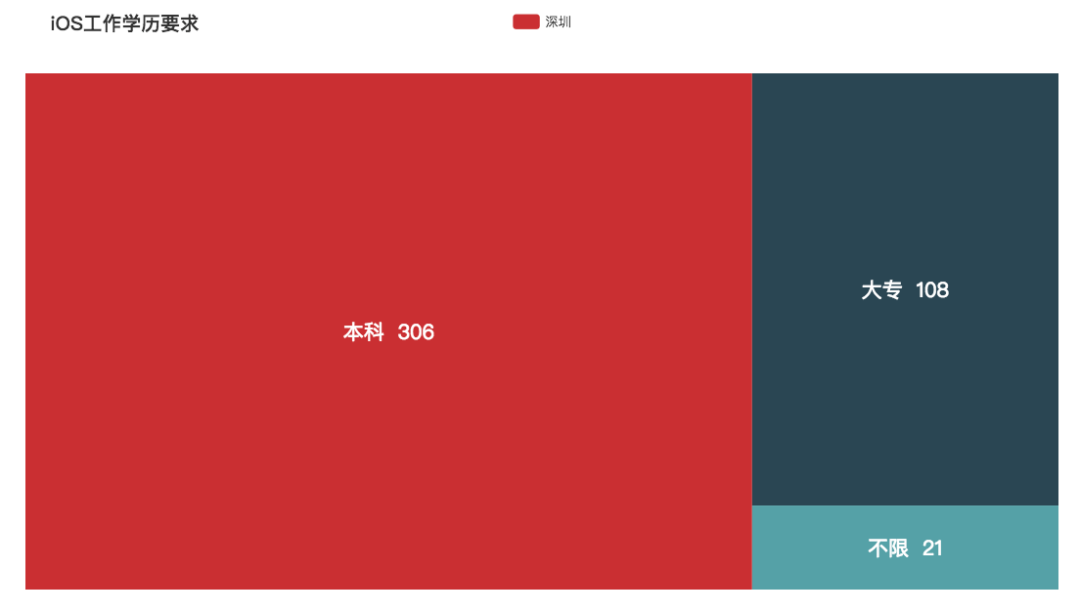
iOS
同 Android 类似,不过比 Android 的饱和程度更高,学历方面要求不高。
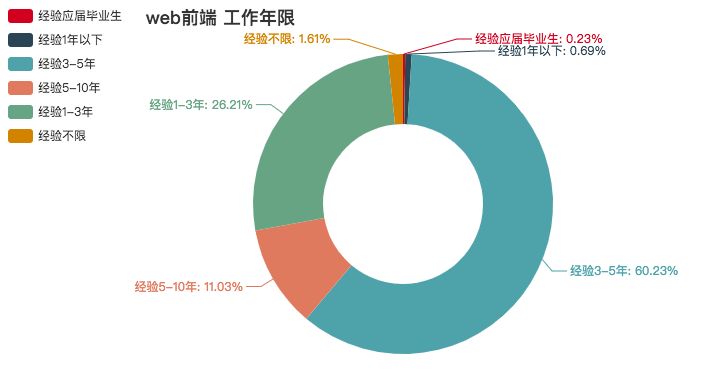
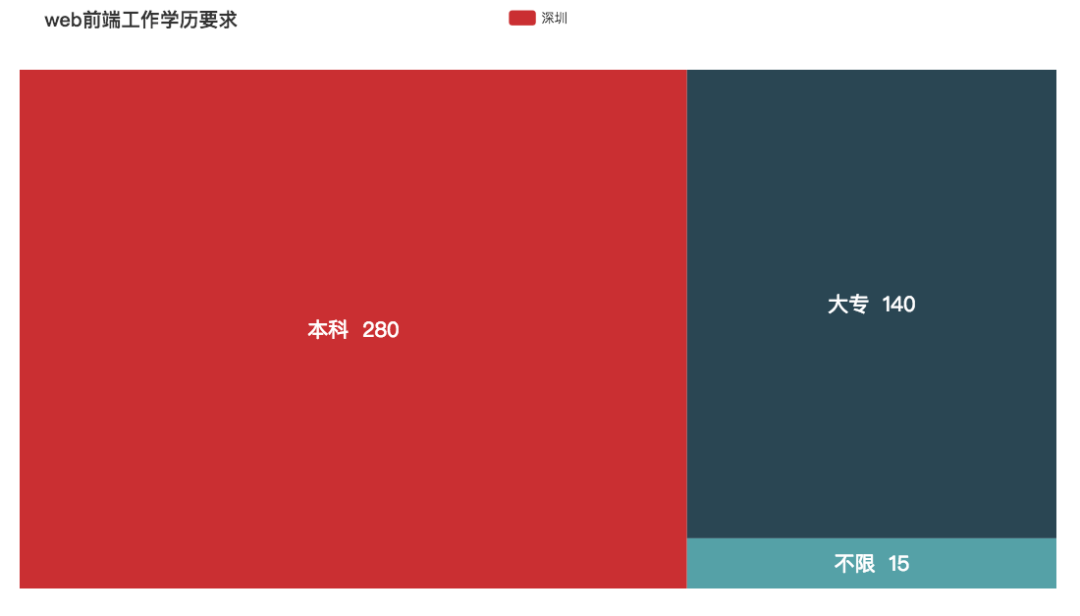
web 前端
web 前端平均工资比预期低,其职位基本本科就能胜任。
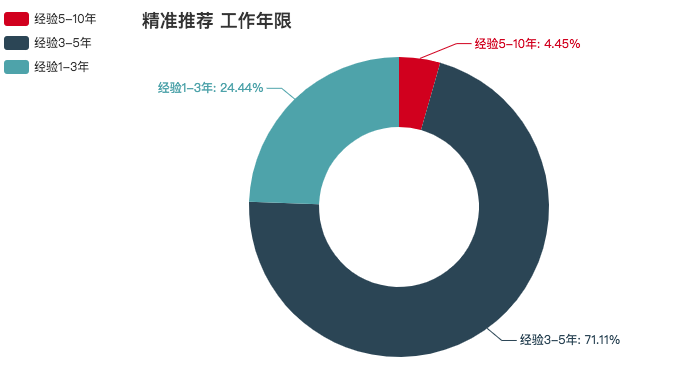
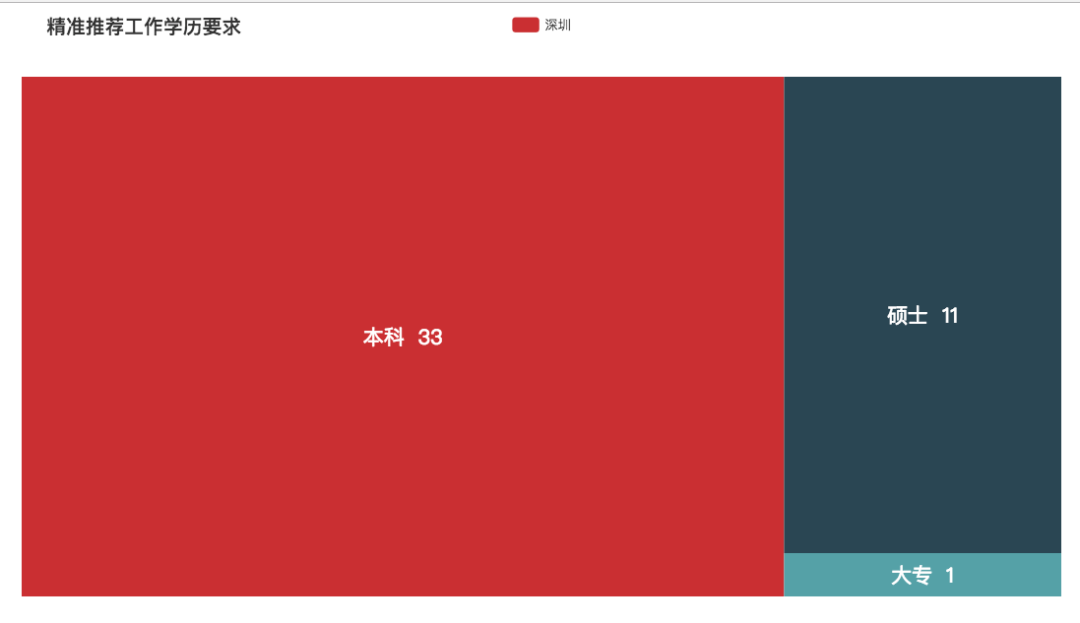
精准推荐
精准推荐薪资特别高,可能是和推荐商品有关。但是,这行业对学历还是有一定要求的。

爬虫技术分析
本次爬取过程中用的的数据工具如下:
看完统计结果之后,有没有跃跃欲试?以下即为代码实现。
首先对网页右击,点击检查,找到一条 item 的数据:
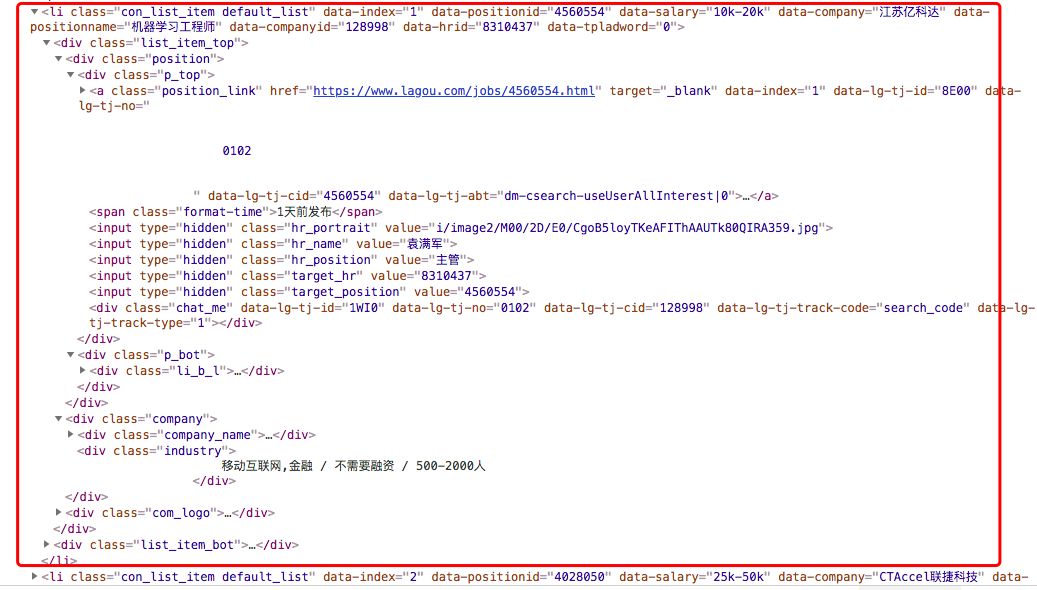
数据库存储结构:
{
"_id" : ObjectId("5b8b89328ffaed60a308bacd"),
"education" : "本科",# 学习要求
"companySize" : "2000人以上",# 公司人数规模
"name" : "python开发工程师",# 职位名称
"welfare" : "“朝九晚五,公司平台大,发展机遇多,六险一金”",# 公司福利
"salaryMid" : 12.5,# 工资上限与工资下限的平均数
"companyType" : "移动互联网",# 公司类型
"salaryMin" : "10",# 工资下限
"salaryMax" : "15",# 工资上限
"experience" : "经验3-5年",# 工作年限
"companyLevel" : "不需要融资",# 公司级别
"company" : "XXX技术有限公司"# 公司名称
}
由于篇幅原因,以下只展示主要代码:
def main(self
, language, city, collectionType):
print(" 当前爬取的语言为 => " + language + " 当前爬取的城市为 => " + city)
url = self.getUrl(language, city)
browser = webdriver.Chrome()
browser.get(url)
browser.implicitly_wait(10)
for i in range(30):
selector = etree.HTML(browser.page_source)
soup = BeautifulSoup(browser.page_source, "html.parser")
span = soup.find("div", attrs={"class": "pager_container"}).find("span", attrs={"action": "next"})
print(
span)
classArr = span['class']
print(classArr)
attr = list(classArr)[0]
attr2 = list(classArr)[1]
if attr2 == "pager_next_disabled":
print("已经爬到最后一页,爬虫结束")
break
else:
print("还有下一页,爬虫继续")
browser.find_element_by_xpath('//*[@id="order"]/li/div[4]/div[2]').click()
time.sleep(5)
print('第{}页抓取完毕'.format(i + 1))
self.getItemData(selector, language, city, collectionType)
browser.close()
爬虫分析实现:
def getLanguageNum
(self):
analycisList = []
for index, language in enumerate(self.getLanguage()):
collection = self.zfdb["z_" + language]
totalNum = collection.aggregate([{'$group': {'_id': '', 'total_num': {'$sum': 1}}}])
totalNum2 = list(totalNum)[0]["total_num"]
analycisList.append(totalNum2)
return (self.getLanguage(), analycisList)
def getLanguageAvgSalary(self):
analycisList = []
for index, language in enumerate(self.getLanguage()):
collection = self.zfdb["z_" + language]
totalSalary = collection.aggregate([{'$group': {'_id': '', 'total_salary': {'$sum': '$salaryMid'}}}])
totalNum = collection.aggregate([{'$group': {'_id': '', 'total_num': {'$sum': 1}}}])
totalNum2 = list(totalNum)[0]["total_num"]
totalSalary2 = list(totalSalary)[0]["total_salary"]
analycisList.append(round(totalSalary2 / totalNum2, 2))
return (self.getLanguage(), analycisList)
def getEducation(self, language):
results = self.zfdb["z_" + language].aggregate([{'$group': {'_id': '$education', 'weight': {'$sum': 1}}}])
educationList = []
weightList = []
for result in results:
educationList.append(result["_id"])
weightList.append(result["weight"])
return (educationList, weightList)
def getExperience(self, language):
results = self.zfdb["z_" + language].aggregate([{'$group': {'_id': '$experience', 'weight': {'$sum': 1}}}])
totalAvgPriceDirList = []
for result in results:
totalAvgPriceDirList.append(
{"value": result["weight"], "name": result["_id"] + " " + str(result["weight"])})
return totalAvgPriceDirList
def getWelfare(self):
content = ''
queryArgs = {}
projectionFields = {'_id': False, 'welfare': True}
for language in self.getLanguage():
collection = self.zfdb["z_" + language]
searchRes = collection.find(queryArgs, projection=projectionFields).limit(1000)
for result in searchRes:
print(result["welfare"])
content += result["welfare"]
return content
def getAllCompanyLevel(self):
levelList = []
weightList = []
newWeightList = []
attrList = ["A轮", "B轮", "C轮", "D轮及以上", "不需要融资", "上市公司"]
for language in self.getLanguage():
collection = self.zfdb["z_" + language]
results = collection.aggregate([{'$group': {'_id': '$companyLevel', 'weight': {'$sum': 1}}}])
for result in results:
levelList.append(result["_id"])
weightList.append(result["weight"])
for index, attr in enumerate(attrList):
newWeight = 0
for index2, level in enumerate(levelList):
if attr == level:
newWeight += weightList[index2]
newWeightList.append(newWeight)
return (attrList, newWeightList)
作者:zone7,一只爱折腾的后端攻城狮,爱写作爱分享。
声明:本文首发于公众号 zone7,作者投稿,版权归对方所有。
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。
————— 推荐阅读 —————