

作者 | 初一
责编 | 郭芮
之前风靡朋友圈的“skr”流行语把中国新说唱这一节目带上了热议高峰,本文就来分析下,如何用Python爬取大受欢迎的说唱歌曲。
首先登录https://music.163.com/ 网易云音乐搜索新说唱,打开Chrome的开发工具工具选择Network并重新加载页面,找到与评论数据相关的请求即name为web?csrf_token=的POST请求,如下图所示:
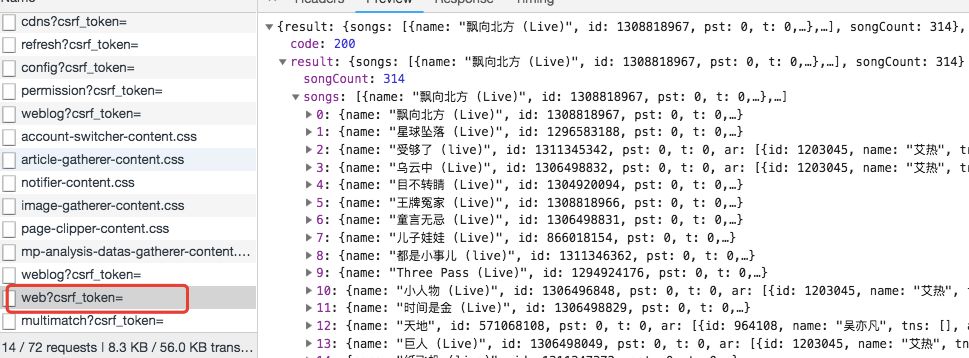
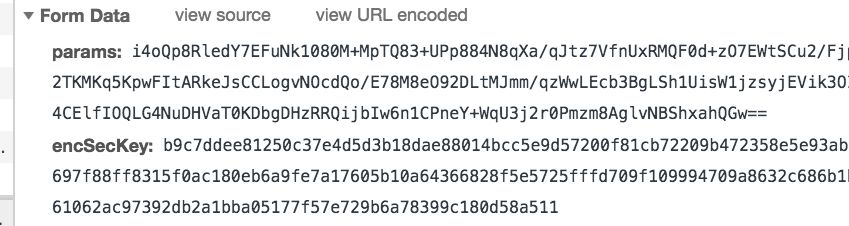
查看该请求的headers我们发现formData包含了两个参数:params、encSecKey。显然这两个参数是经过JS加密的,这就是网易云反爬虫的一种策略。如下图:
我们再来看一下请求的Initiator有个core 2ab1b2b..js。因此我们需要分析一下这个JS,找出formData加密的规则即可。
将JS文件进行格式化,全局搜索params或者encSecKey:

params和encSecKey是从bSC8u这个对象中取的:
k8c.cE9v({
params: bSC8u.encText,
encSecKey: bSC8u.encSecKey
})
而这个对象是由windows.asrsea() 这个方法获得的,定位到该方法。如下图所示:
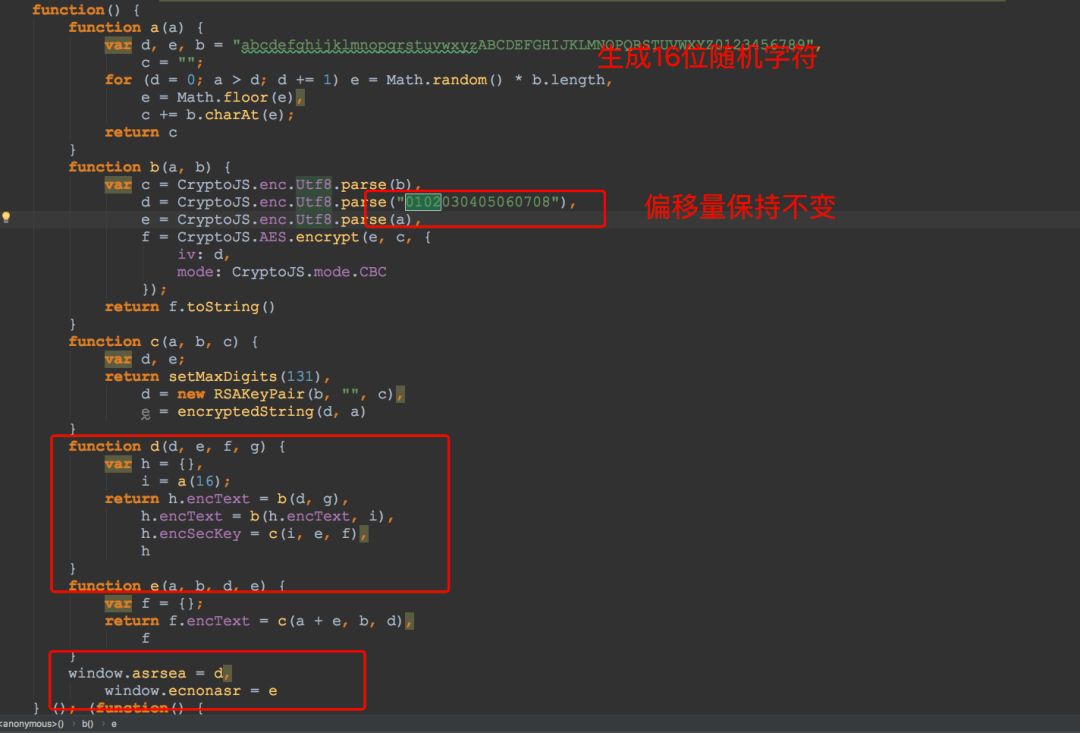
通过分析代码我们发现d函数才是最终的出口。分析d函数:
通过a(16)函数生成一个长度为16的随机字符串;
encText这个参数通过两次调用b(a,b) 函数完成,这个函数的作用为AES加密;
调用 c(i, e, f)得到encSecKey,这个函数的作用是进行RSA加密。
AES加密:AES(Advanced Encryption Standard)对称加密算法是一种高级数据加密标准,是美国联邦政府采用的一种区块加密标准,可有效抵制针对DES的攻击算法。特点是,密钥建立时间短、灵敏性好、内存需求低、安全性高。
RSA加密:RSA加密算法是一种非对称加密算法。在公开密钥加密和电子商业中RSA被广泛使用。到目前为止,世界上还没有任何可靠的攻击RSA算法的方式。只要其钥匙的长度足够长,用RSA加密的信息实际上是不能被解破的。
通过上面分析,除了 i 是一个随机字符串,我们只需要知道d、e、f、g这四个参数就可以构造请求进行后续操作了。接下来我们进行JS断点调试。
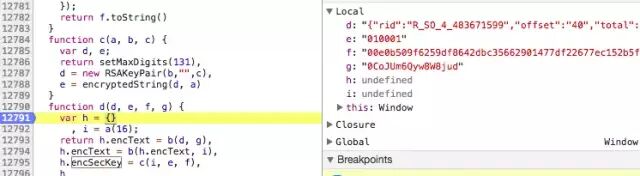
经过多次调试,我们发现e、f、g这三个值是不变的,唯一改变的是d。再结合上文分析,encSecKey由函数c(i, e, f)得到的,那是不是就意味着encSeckey这个值是不变的呢?
然而,经过代码测试并不是这样,要保证encSecKey和params中的随机字符串(也就是i的值)是一样的才可以。
首先我们先实现函数a,即生成16位的随机字符:
#生成随机长度为16的字符串的二进制编码
def random_b():
seed = "1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
sa = []
for i in range(16):
sa.append(random.choice(seed))
salt = ''.join(sa)
return bytes(salt, 'utf-8')
# 更简单的做法
# return bytes(''.join(random.sample('1234567890DeepDarkFantasy', 16)), 'utf-8')
其次来实现加密参数的生成(说白了就是翻译JS代码为Python代码):
#第二参数,rsa公匙组成
pub_key = "010001"
#第三参数,rsa公匙组成
modulus = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
#第四参数,aes密匙
secret_key = b'0CoJUm6Qyw8W8jud'
"""
AES 加密
"""
def aes_encrypt(text, key):
# 偏移量
iv = b'0102030405060708'
# 对长度不是16倍数的字符串进行补全,然后在转为bytes数据
pad = 16 - len(text) % 16
try:
# 如果接到bytes数据(如第一次aes加密得到的密文)要解码再进行补全
text = text.decode()
except:
pass
text = text + pad * chr(pad)
try:
text = text.encode()
except:
pass
encryptor = AES.new(key, AES.MODE_CBC, iv)
ciphertext = encryptor.encrypt(text)
ciphertext = base64.b64encode(ciphertext).decode('utf-8') # 得到的密文还要进行base64编码
return ciphertext
"""
RSA 加密
"""
def rsa_encrypt(random_char):
text = random_char[::-1]#明文处理,反序并hex编码
rsa = int(binascii.hexlify(text), 16) ** int(pub_key, 16) % int(modulus, 16)
return format(rsa, 'x').zfill(256)
"""
构造params
"""
def aes_param(data):
text = json.dumps(data)
random_char = random_b()
params = aes_encrypt(text, secret_key)#两次aes加密
params = aes_encrypt(params, random_char)
enc_sec_key = rsa_encrypt(random_char)
data = {
'params': params,
'encSecKey': enc_sec_key
}
return data
最后参数构造完毕,就可以开始咱们的爬虫了。
由于RSA是非对称加密,无法通过encSecKey解密出i,没有i也就无法解密params,所以也就只能对每个接口进行断点调试,观察请求的构造。
搜索歌曲的data为:
data = {"hlpretag": "",
"hlposttag": "",
"s": "中国新说唱",
"type": "1",
"offset": "0",
"total": "true", #仅在页码为0时为true
"limit": "30",
"csrf_token": ""
}
查询歌曲信息的data:
{
"id": song_id,#歌曲id
"lv": -1,
"tv": -1,
"csrf_token": ""
}
接下来就可以开始写爬虫了。分析网页请求我们发现搜索歌曲的时候响应是在https://music.163.com/weapi/cloudsearch/get/web?csrf_token= 这个请求里响应的:

歌词信息由 https://music.163.com/weapi/song/lyric?csrf_token=这个请求响应的:

万事俱备,开始Coding!
"""
请求头
在这里不能将Referer固定写死
因为在搜索歌曲的时候请求的Referer为:https://music.163.com/search/
而查看歌词的时候请求的Referer为:'https://music.163.com/song?id=歌曲id
"""
headers = {
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Host': 'music.163.com',
'Origin': 'https://music.163.com',
}
"""
通过歌曲id爬歌词内容
"""
def find_song_word(song_id):
referer = 'https://music.163.com/song?id=' + song_id
headers['Referer'] = referer
url = 'https://music.163.com/weapi/song/lyric?csrf_token='
param = {"id": song_id, "lv": -1, "tv": -1, "csrf_token": ""}
data = aes_param(param)
result = requests.post(url, data=data, headers=headers)
result = result.json()
return result['lrc']['lyric']
# mongo服务
client = pymongo.MongoClient('mongodb://127.0.0.1:27017/')
# song数据库
db = client.song
# song_detail表,没有自动创建
detail_db = db.song_detail
if __name__ == '__main__':
# 搜索歌曲url
query_url = 'https://music.163.com/weapi/cloudsearch/get/web?csrf_token='
data = {"hlpretag": "",
"hlposttag": "",
"s": "中国新说唱",
"type": "1",
"offset": "0",
"total"
: "true",
"limit": "30",
"csrf_token": ""
}
data = aes_param(data)
referer = 'https://music.163.com/search/'
headers['Referer'] = referer
result = requests.post(query_url, data=data, headers=headers)
result = result.json()
songs = result['result']['songs']
for i in songs:
songer = []
# 歌曲id
song_id = i['id']
# 歌词
song_content = find_song_word(str(song_id))
# 歌曲名
song_name = i['name']
song_arr = i['ar']
# 一首歌可能多人唱, 是个列表 需要遍历
for k in song_arr:
song_dict = {'id': k['id'], 'name': k['name']}
songer.append(song_dict)
# 存入mongodb
detail_db.insert({'song_id': song_id, 'name': song_name, 'songer'
: songer, 'content': song_content})
运行之后查看数据库:
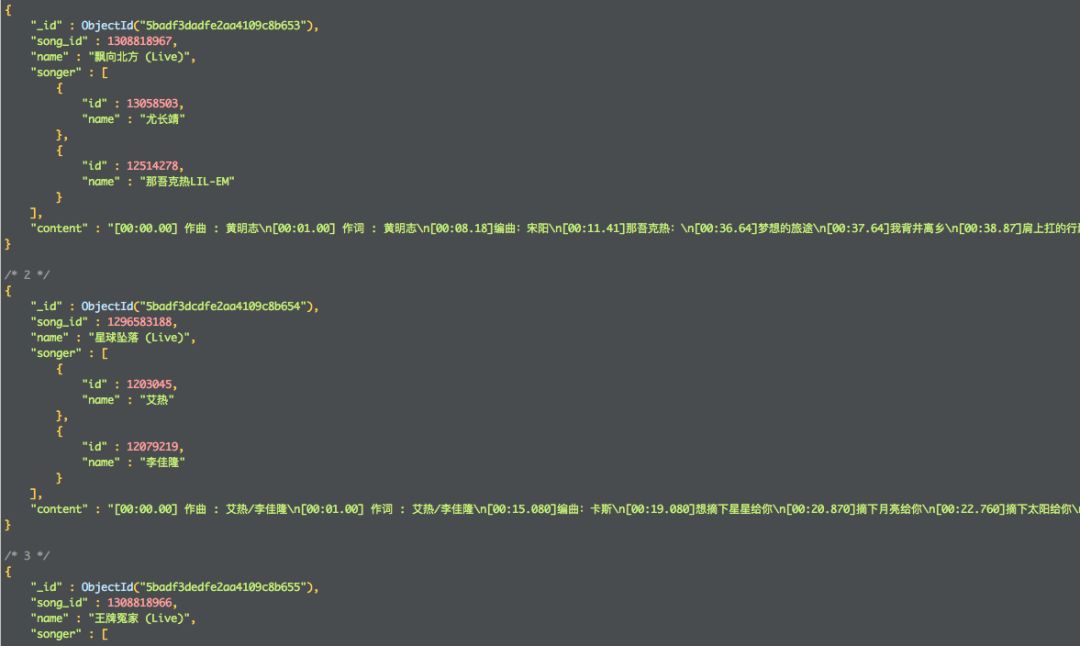
现在我们有了Rap歌手的id,从全网爬他们的说唱歌曲还不是so easy?
作者:初一,曾在知名互联网公司担任java研发一职,项目带头人。18年中旬转行Python,热爱爬虫喜欢折腾新东西。coding与乐趣同在。Talk is cheap,Show me the code.
声明:本文为作者投稿,版权归其个人所有。
苹果手机的微信改版了,
想快速看到CSDN的热乎文章,
赶快把CSDN公众号设为星标吧,
打开公众号,点击“设为星标”就可以啦!
安卓手机的用户,
点击公众号右上角小人,就可以置顶啦。
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。
推荐阅读:
2018 AI开发者大会首轮重磅嘉宾及深度议题现已火热出炉,扫码抢“鲜”看。国庆特惠,购票立享 5 折优惠!

点击“阅读原文”,也可立即报名。










