
经常听到别人说“世界那么大,我想去看看”。在有机会走出国门之前,还是先把祖国走一圈吧。都知道中国地广人不稀,旅游资源非常丰富,古文化遗址、抗战遗址、山川、河流等等,在选择目的地的时候,不少人都会非常纠结,不知道去哪更好。为了以后不再纠结,笔者打算深度解析全国的旅游景点分布。

以下进入正题。

数据抓取
去哪儿网有着非常丰富的旅游信息,不但几乎涵盖了全国所有景点,而且使用去哪儿网购买景区门票的人也非常多,所以笔者将爬取去哪儿网全国 32 个省市的所有景点数据。(没有抓取香港和澳门的数据,这边的景点并没有分 5A、4A)
去哪儿网的门票服务中暂时还没有开通 API 服务,所以只能对网页解析爬取。要抓取的数据有:景点名、景区等级、地点、景区简述、价格、销量以及热度。
将需要的数据进行定位,一层一层解析,就可以把所需的全部内容抓取下来了。但并不是每一个景点的信息都是全的,所以笔者加了一个 try/except 进去,虽然代码有变长,但是整个程序变得更加健壮。最终,一共抓取了 41611 条景点信息。
for i in s:
inf = {}
try:
inf['level'] = i.find('span', class_='level').text[0]
except Exception as e:
inf['level'] = '0'
try:
inf['price'] = i.find('span', class_='sight_item_price').find('em'
).text
except Exception as e:
inf['price'] = ''
try:
inf['name'] = i.find('a', class_='name').text
except Exception as e:
inf['name'] = ''
try:
inf['num'] = i.find('span', class_='hot_num').text
except Exception as e:
inf['num'] = ''
try:
inf['add_pro'] = i.find('span', class_='area').find('a').text.split('·')[0]
inf['add_city'] = i.find('span', class_='area').find('a').text.split('·')[1]
except
Exception as e:
inf['add_pro'] = i.find('span', class_='area').find('a').text
inf['add_city'] = i.find('span', class_='area').find('a').text
try:
inf['hot'] = i.find('span', class_='product_star_level').find('em').get('title').split(':')[1]
except Exception as e:
inf['hot'] = ''
try:
inf['descri'] = i.find('div', class_='intro color999').text
except Exception as e:
inf['descri'] = ''

数据分析
5A 级景区
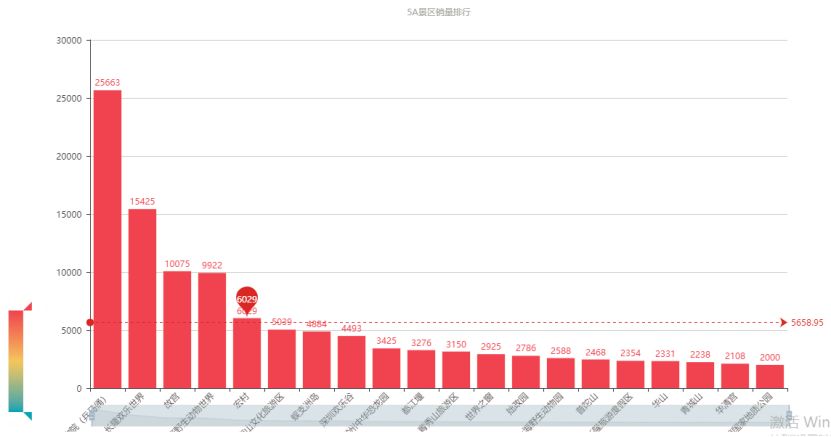
上图为 5A 景区的销量排行,可以看出秦始皇兵马俑遥遥领先,是第二名长隆欢乐世界的 5/3 倍。让笔者没有想到的是欢乐谷游乐园等在前二十名中占了六个席位,所以对于那些想发展旅游业但是没有美丽风景或者历史古迹的城市而言,大力发展游乐园行业是一个不错的选择。广州长隆就是一个鲜活的例子。
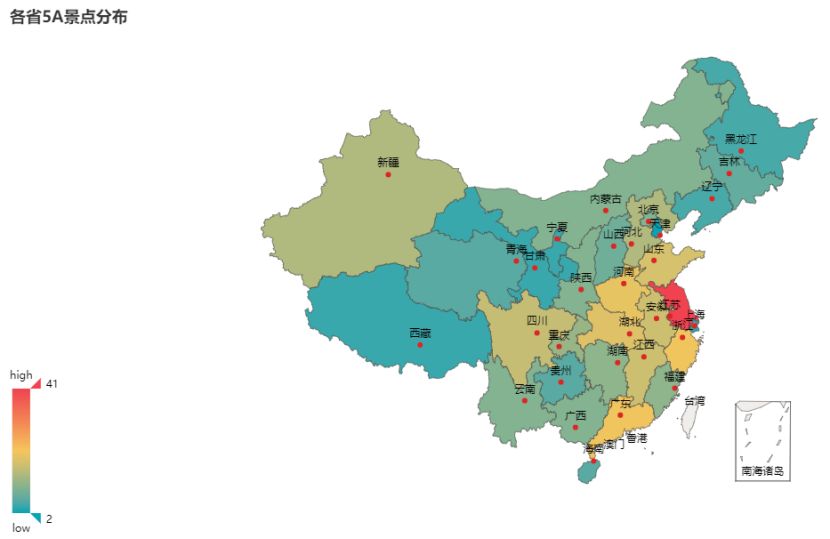
江苏省是全国 5A 级景区最多的一个省,有 41 个之多;其次是浙江省和广东省有 21 个。总体而言,东部地区的 5A 景区数量是远高于西部的,虽然西部的美景非常多,但是整体经济不行,对景区的开发力度不够,拉了不少后退。
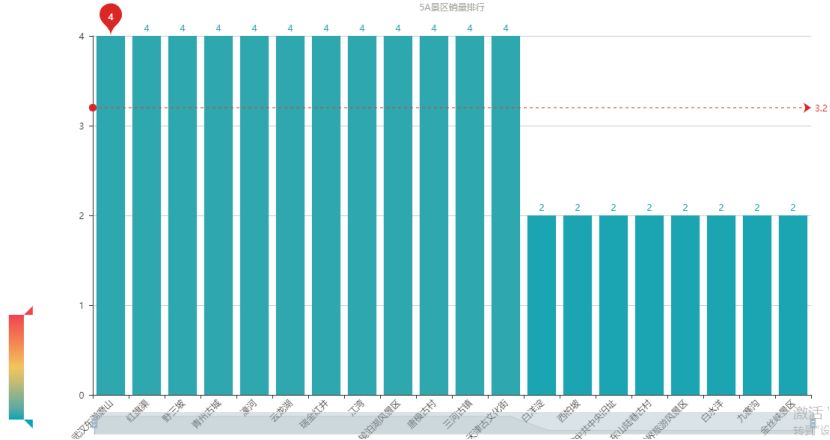
如果大家想去人少景美的地方,可以参考上图。比如武汉的东湖磨山、红旗渠、野三坡等等(其实笔者都没有听过。)虽然它们的销量低,但好歹也是 AAAAA 级风景区。
def huati(name,num,k):
kk=[]
for i in range(len(name)):
if not numpy.isnan(num[i]):
q = []
q.append(name[i])
q.append(num[i])
kk.append(q)
hh=sorted(kk,key=lambda i:i[1],reverse=True)
page=Page()
att,val=[],[]
for i in hh[:20]:
att.append(i[0])
val.append(i[1])
bar1 = Bar("", k+"A景区销量排行", title_pos="center", width=1200, height=600)
bar1.add("",att,val, is_visualmap=True, visual_text_color='#fff'
, mark_point=["average"],
mark_line=["average"],
is_more_utils=True, is_label_show=True, is_datazoom_show=True, xaxis_rotate=45)
page.add_chart(bar1)
att, val = [], []
for i in hh[-20:]:
att.append(i[0])
val.append(i[1])
bar2 = Bar("", k+"A景区销量排行", title_pos="center", width=1200, height=600)
bar2.add("", att, val, is_visualmap=True, visual_text_color='#fff', mark_point=["average"],
mark_line=["average"],
is_more_utils=True, is_label_show=True, is_datazoom_show=True, xaxis_rotate=45)
page.add_chart(bar2)
page.render(k+"A景区销量bar.html")
def sum_pro(pro,k):#每个省有多少个景点
p=[]
c=[]
for
i in set(pro):
'''
q={}
q[i]=pro.count(i)
p.append(q)'''
p.append(i)
c.append(pro.count(i))
map= Map('各省'+k+'A景点分布', width=1200, height=600)
map.add("", p,c, is_visualmap=True, visual_range=[min(c), max(c)],
visual_text_color='#000', is_map_symbol_show=True, is_label_show=True)
map.render( '各省'+k+'A景点分布.html')
4A 景区
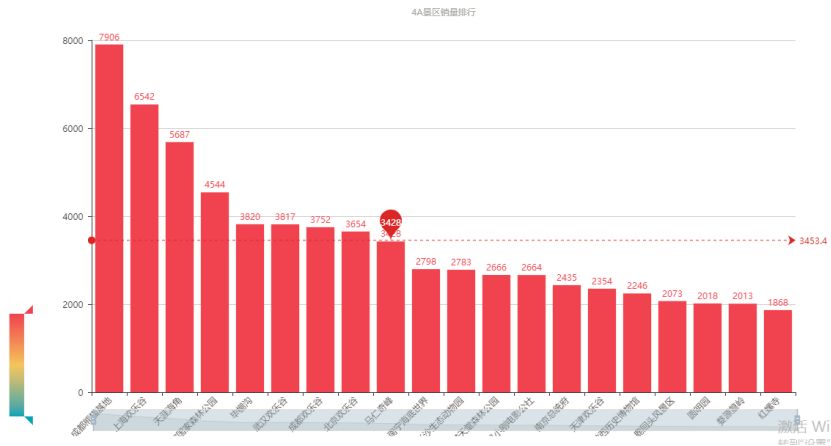
在 4A 景区里,成都熊猫基地的销量是最高的,大熊猫最为国宝,这吸引力真是杠杠的。和 5A 景区一样,欢乐谷游乐园等占了四成,我想这也是南京虽然是六朝古都,又是中华民国的首都,可是景区无论销量还是人气都不高的原因吧,希望在南京可以多造几个大型游乐园!
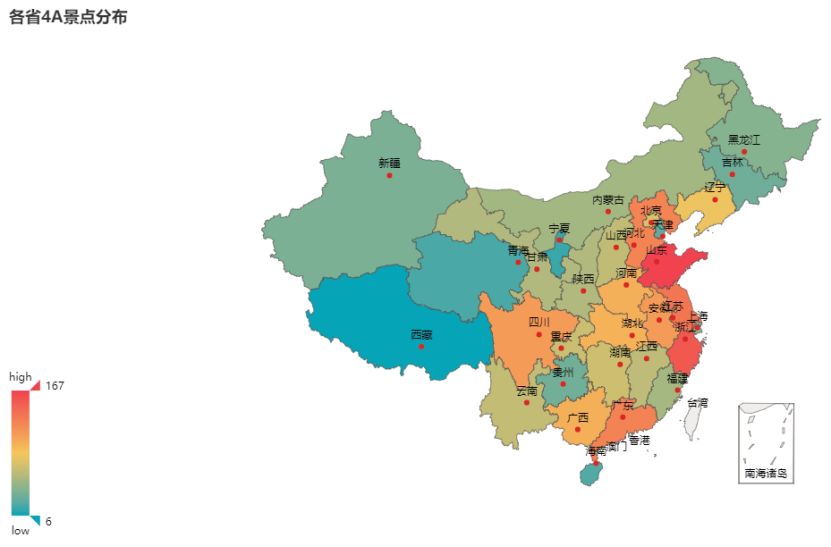
在上图中可以看到山东省是 4A 景区最多的省,有 167 个之多。而浙江省、江苏省、广东省、河北省、四川省、安徽省的 4A 景区数量均超过了 100。4A 景区最少的省是西藏,只有 6 个。
3A 景区
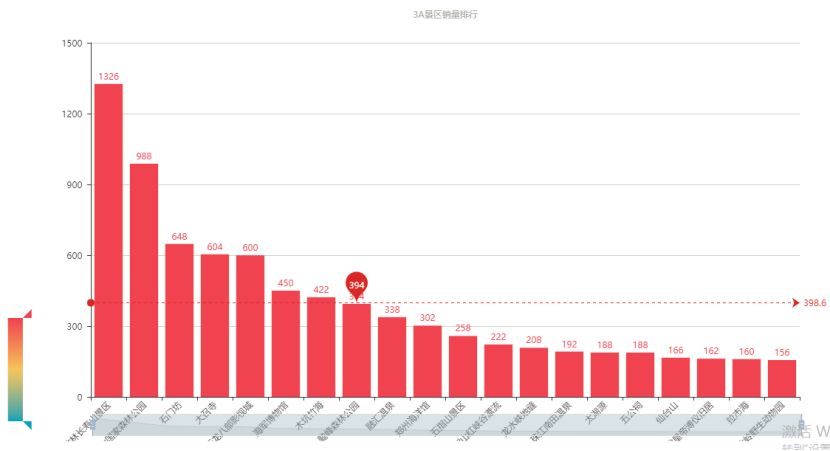
3A 景区销量最高的是竹林长寿山景区,但也只有 1326,在 4A 景区的中上游。
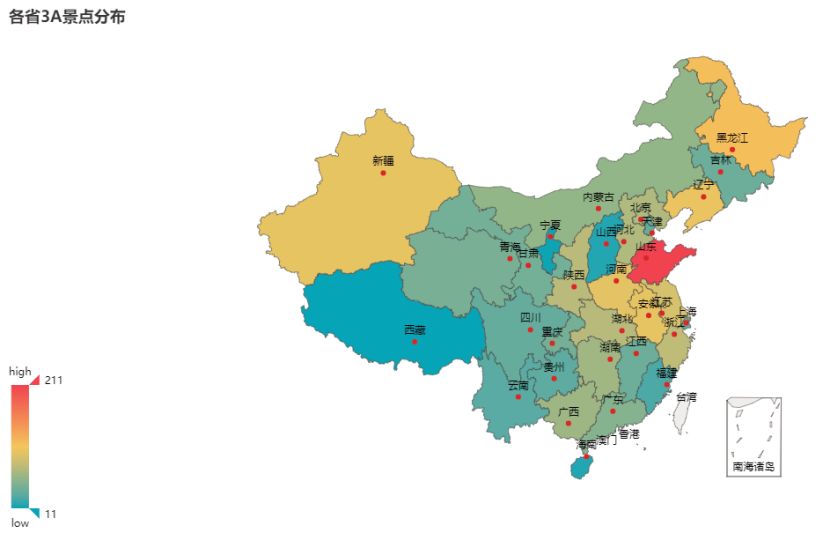
山东省的 3A 景区数量全国第一,高达 211 个,而河南省、安徽省、辽宁省、黑龙江省、新疆省 3A 景区均在 100 个以上。
综合对比
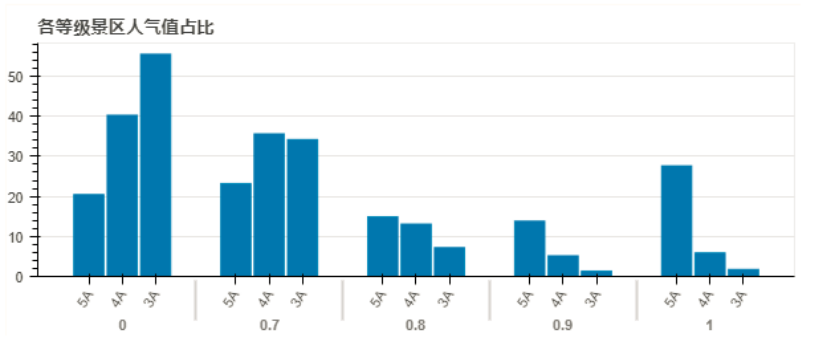
从各等级景区人气值可以看出,人气值为 1 的 5A 景区占了将近三成,而 4A 和 3A 景区连一成都没有;相反,人气值为 0 的 3A 景区差不多有六成,看来这个 3A 景区不是一点点水呢?5A 景区也并非每一个都称得上 5A 这个名号,不然也不会有近两成人气值为 0。
def hottt(fivhot,fouhot,thrhot):
fiv, fou, th = [], [], []
atts = ['0', '0.7', '0.8', '0.9', '1']
for i in zip(fivhot,fouhot,thrhot):
fiv.append(round(i[0], 1))
fou.append(round(i[1], 1))
th.append(round(i[2], 1))
levels = ['5A', '4A', '3A']
data = {}
data['att'] = atts
data['5A'], data['4A'], data['3A'] = [], [], []
for i in range(len(atts)):
data['5A'].append(round(fiv.count(float(atts[i])) / len(fiv) * 100, 3))
data['4A'].append(round(fou.count(float(atts[i])) / len(fou) * 100
, 3))
data['3A'].append(round(th.count(float(atts[i])) / len(th) * 100, 3))
print(data)
output_file("bars.html") # 输出文件名
x = [(att, level) for att in atts for level in levels]
counts = sum(zip(data['5A'], data['4A'], data['3A']), ())
source = ColumnDataSource(data=dict(x=x, counts=counts))
p = figure(x_range=FactorRange(*x), plot_height=250, title="各等级景区人气值占比",
toolbar_location=None, tools="")
p.vbar(x='x', top='counts', width=0.9, source=source)
show(p)
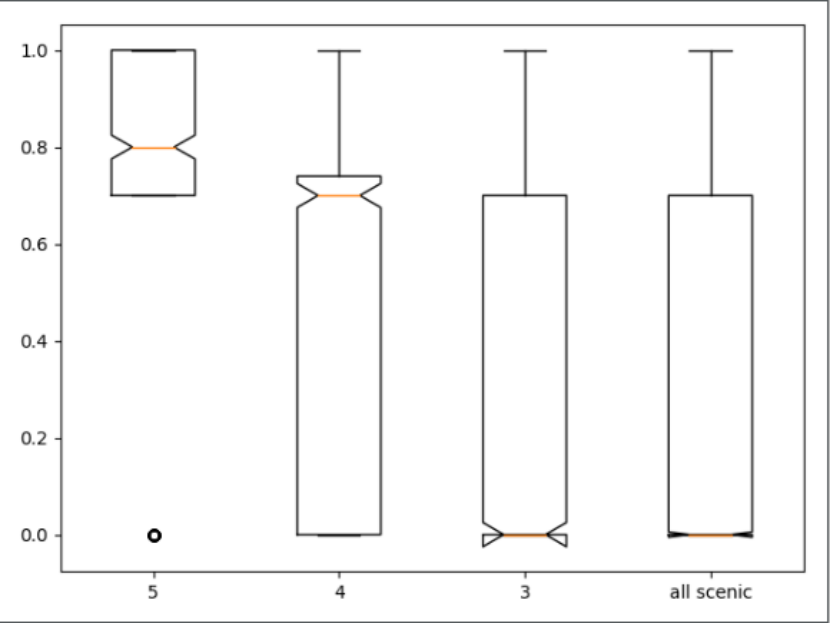
从各级景点的箱型图可以看出,5A 景区人气值是遥遥领先的,整体在 0.7 以上。4A 景区人气均值中位数在 0.7 左右,不过高于 0.7 的景区实在太少了。3A 景区就更不用说,整体人气值非常低。
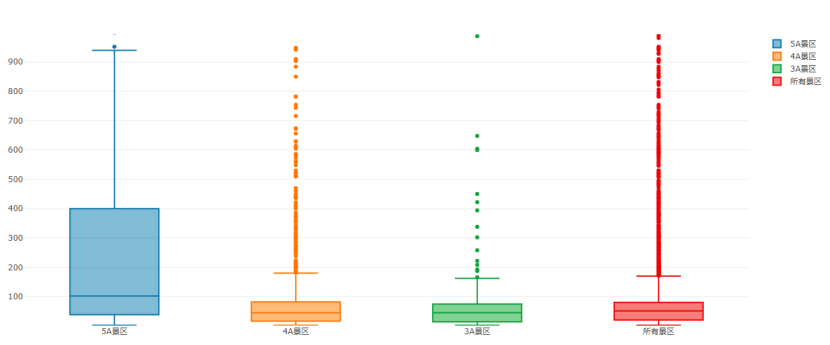
从景区销量箱型图可以看到:5A 景区的销量是远超过了 4A 和 3A 景区,5A 景区的 3/4 分为点达到了 400,而 4A 景区的仅为 82;而 4A 景区的箱型图和 3A 的非常类似;看来大家对 4A 景区和对 3A 景区兴趣都一致的不大。
def box(q,w,e,l):
a = go.Box(y=q, name='5A景区')
b = go.Box(y=w, name='4A景区')
c = go.Box(y=e, name='3A景区')
g = go.Box(y=l, name='所有景区')
data = [a, b, c,g]
layout = go.Layout(legend=dict(font=dict(size=16)), orientation=270)
fig = go.Figure(data=data, layout=layout)
plotly.offline.plot(data)

将所有景点的概述用 R 生成了一个词云图:位于,文化,休闲,旅游,体验,景区,公园,历史,娱乐等等这些词是不是很熟悉呢。看来商家对景区的概括都差不多。
对比完各级景点,下面来给各位看官排排雷。
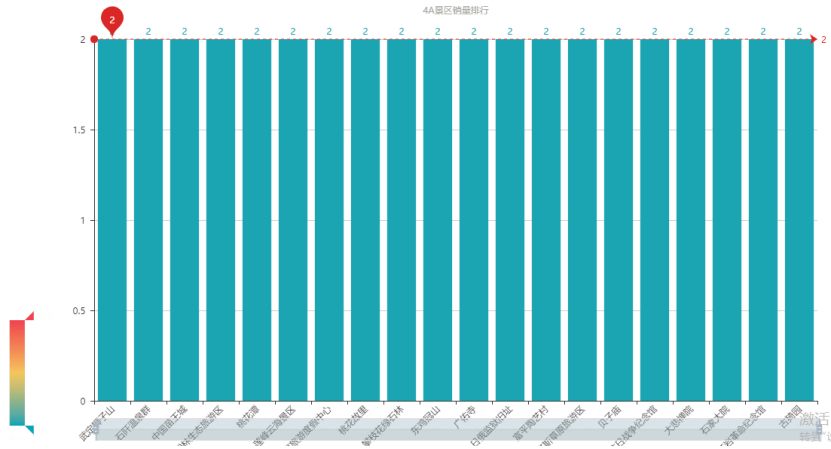
上图是 4A 级景区销量排名的最后 20 位,全中国有 2193 个 4A 级景区,这 20 个还排在最后,在对比一下大家对 4A 级景区的人气评分,想想还是不要去了。
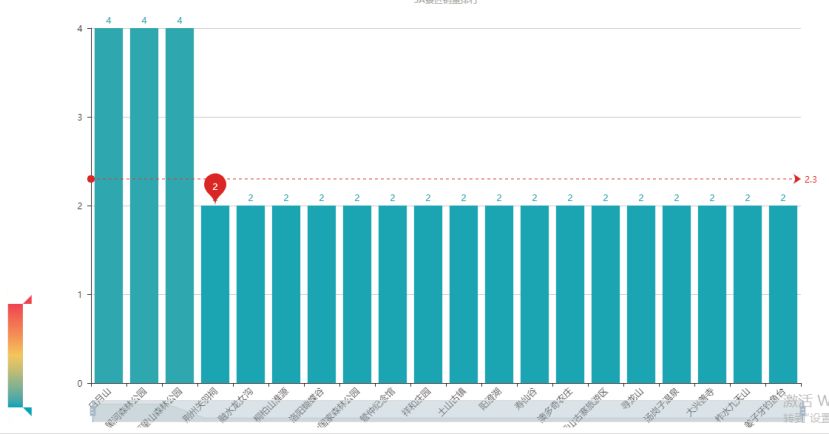
首先,如果说 3A 级景区不太推荐大家去游玩,因为人气值实在低的可怕;那上面列出的这 20 个景点那就是完全不建议游玩了。全国一共 1933 个 AAA 级景区,这 20 个排在最后,可想而知去了会多么震惊了。
高德地图可视化
高德地图的 API 真的非常好,它提供各种和地图有关的功能。其中有一项是 WEB 服务里的地理/逆地理编码。将去哪儿爬取到的景点地址数据通过地理编码转变为对应的经纬度。比如:北京市方恒国际中心 A 座将它经过地理编码后其经纬度为 116.480656,39.989677。它的 URL:
https://restapi.amap.com/v3/geocode/geo?address=地址&output=XML&key=&city=城市
其中 output 是输出个格式,一共有两种,XML 和 JSON;address 是要地理编码的地址,city 是所在的城市。

Word is cheap,show me the code!
def trans(city,name,pro,level):
for i in range(len(name)):
x = pandas.DataFrame()
t={}
add = name[i]
chengshi=city[i]
parameters = { 'address': add, 'key': '','city':chengshi }
html = requests.get('https://restapi.amap.com/v3/geocode/geo',
params=parameters).json()
try:
t['jingwei'] = html['geocodes'][0]['location']
except IndexError:
t['jingwei']='0,0'
finally:
t['n'] = name[i]
t['level']=level[i]
t['pro']=pro[i]
t['city']=city[i]
x = x.append(t, ignore_index=True)
x.to_csv('55543.csv', encoding='utf-8', index=False, mode='a', header=False)
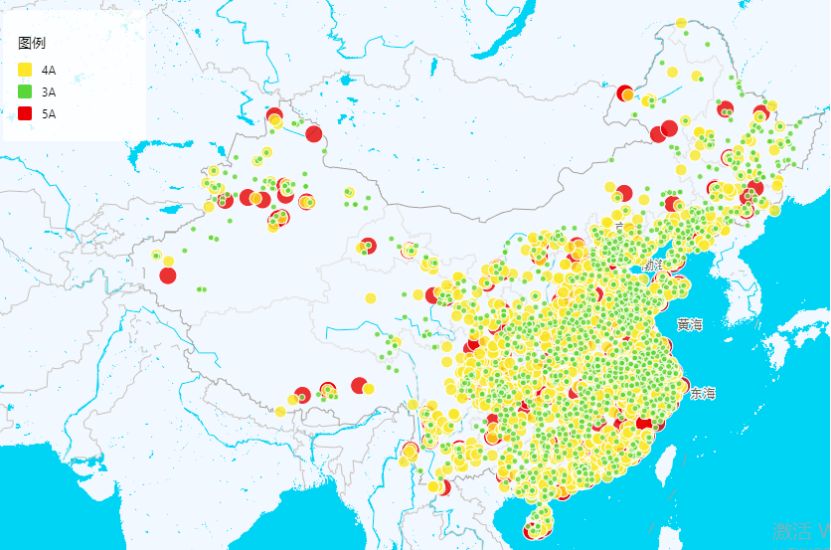
全国各级景区分布图
全国各级景区分布六边形热力图
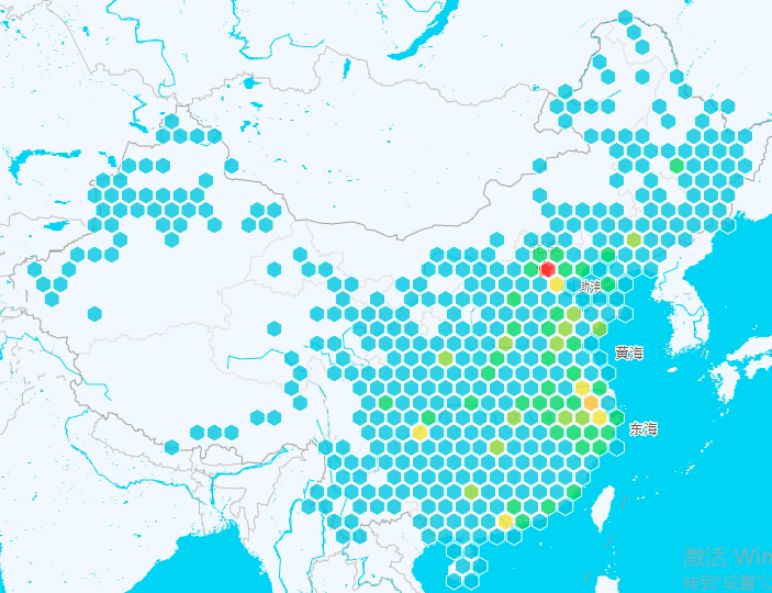
在六边形热力图中可以看到,北京是一个旅游资源及其丰富的城市,如果大家只想去一个城市转一转,可以优先选择北京。重庆、广州、天津、苏州等也是不错的选择。
全国景区分布热力图
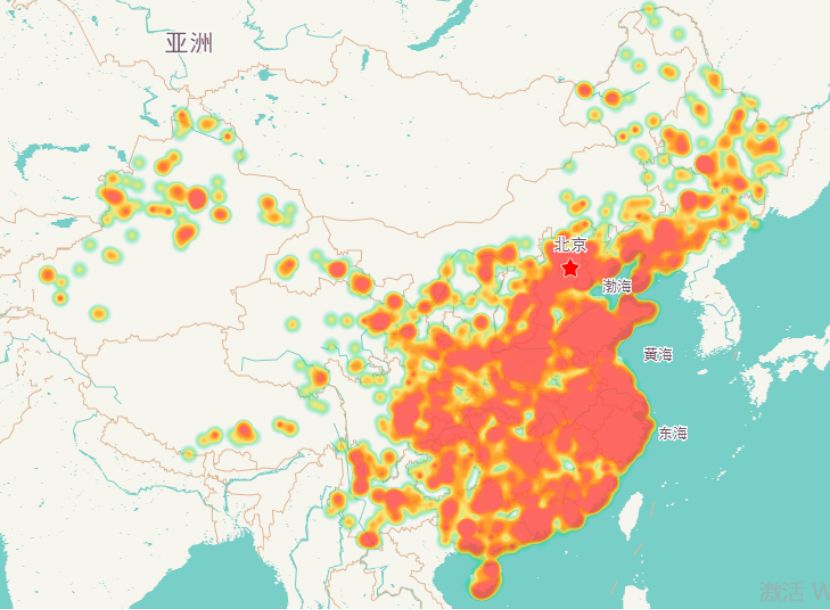
笔者做了一个全国旅游景点分布轨迹的动画,链接如下:
lbs.amap.com/dev/mapdata/share/7b986430c10e197fcb5babbddd510c67
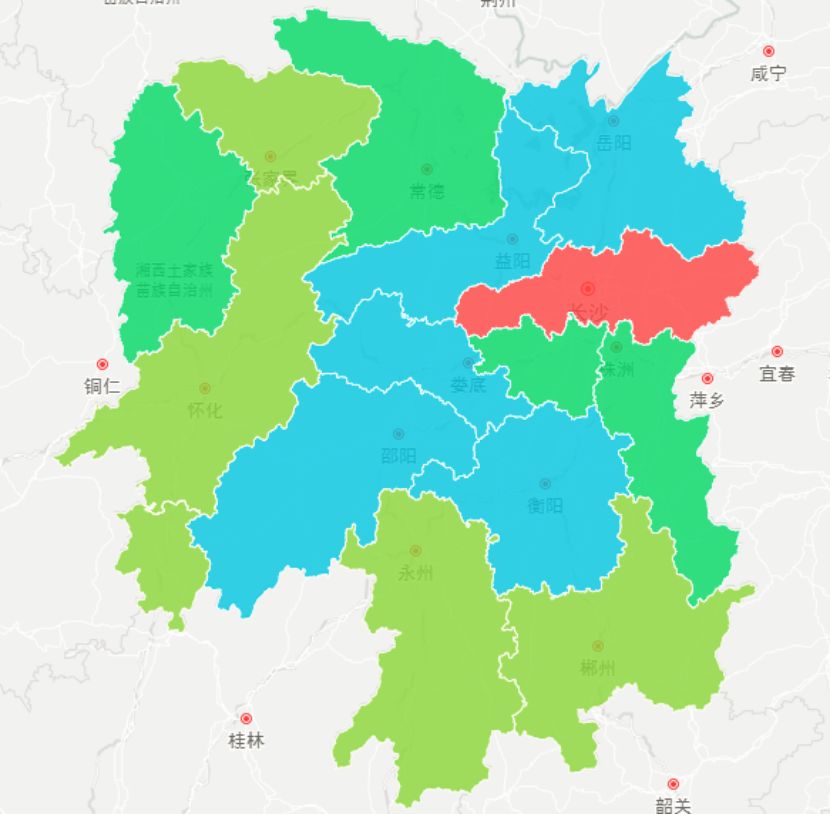
最后来看看笔者的家乡,湖南。如果大家去湖南游玩的话,长沙一定要去!其次张家界、永州、怀化和郴州也值得一去。
相关代码和数据已经上传到GitHub:https://github.com/zuobangbang/qunaer
声明:本文为作者投稿,文章仅用于学习交流,不得用于其他途径。
作者:左伊雅,目前在南京某 211 大学读研二,喜欢数据挖掘和爬虫。
--End--
微信改版了,
想快速看到CSDN的热乎文章,
赶快把CSDN公众号设为星标吧,
打开公众号,点击“设为星标”就可以啦!

CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。
推荐阅读:











