原标题 | Extreme Event Forecasting with LSTM Autoencoders
作 者 | Marco Cerliani
翻 译 | 黄闯、Dooria、ybNero、肖书忠、邺调Photo by Nur Afni Setiyaningrum on Unsplash
对于每个数据科学家来说,进行极端事件预测是一个经常会遇到的噩梦。寻寻觅觅,我终于发现了处理这个问题非常有趣的资源。就我个人而言,我确实爱上了Uber研究人员发布的方法。在他们的论文https://eng.uber.com/neural-networks/
https://arxiv.org/pdf/1709.01907.pdf,有两个版本
中,他们开发了一个基于机器学习的解决方案,用于预测每日乘客需求。他们的方法以其简洁易懂的解释和易于实施的特点而引起了我的注意。所以我的目的是用python重现他们的发现。我对这个挑战非常满意,并且最终我还提高了自己对回归预测的认识。
这篇文章最重要的收获可以概括为:
1.开发一种稳定的方法来评估和比较keras模型(同时避免权重种子生成器的问题);
2.实现了一个简单而智能的LSTM自编码器,用于新特征的创建;
3.通过简单的技巧提高时间序列的预测性能(参见上面的步骤);
4.处理嵌套数据集,即我们观察到的属于不同实体的问题(例如,不同商店/引擎/人员的时间序列等)。从这个意义上说,我们只为所有人开发一个高性能的模型!
保持镇定,让我们一步一步开始吧。
问题概述
对于Uber来讲,对出行(特别是特殊日期里)的准确预测有许多重要的好处:更有效的驾驶员分配,以减少司机的等待时间,预算和其他相关任务。
为了更准确地预测驾驶员对共享车辆的需求,Uber的研究人员开发了一种用于时间序列预测的高性能模型。他们能够将一个模型与来自不同位置(城市)的不同时间序列相匹配,该过程允许提取相关的时间模式。最后,他们能够针对不同的位置(城市)预测需求,优于传统的预测方法。
对于这个问题,Uber使用了他们的内部数据,即不同城市的出行数据,其包含了一些额外特征:天气信息、城市等级信息。他们的目标是以固定窗口数据(即过去一天)预测第二天的需求。
不幸的是,我们并没有这种优质的数据,不过幸好我们可爱的kaggle粉丝给我挑选了一个优质的数据集:Avocado Prices Dataset (https://www.kaggle.com/neuromusic/avocado-prices)。这个数据展示了两种不同品种的鳄梨的历史价格,和其在美国多个商场的销量。
我们选择这个数据主要是因为我们需要具有时间依赖性的嵌套数据集:我们拥有一共54个商场的鳄梨销售记录,也就是我们所说的时间序列数据,如果算上不同种类(常规和有机),我们就有108个时间序列。Uber的科研人员强调这种数据结构非常重要,因为它可以让我们的模型发现其中重要的隐藏关系。在我们使用LSTM Autoencoder做特征提取的时候,序列间的关系也会为我们模型的效果带来提升。
我们使用了从开始到2017年末为止的售价数据搭建模型,而18年最开始两月的数据我们拿来做测试数据。我们分析时,应该考虑到所有数据的回归曲线,图中显示的频率较弱,所以我们决定:给定一个固定的窗口,即过去四周数据作为训练集,预测即将到来的价格。
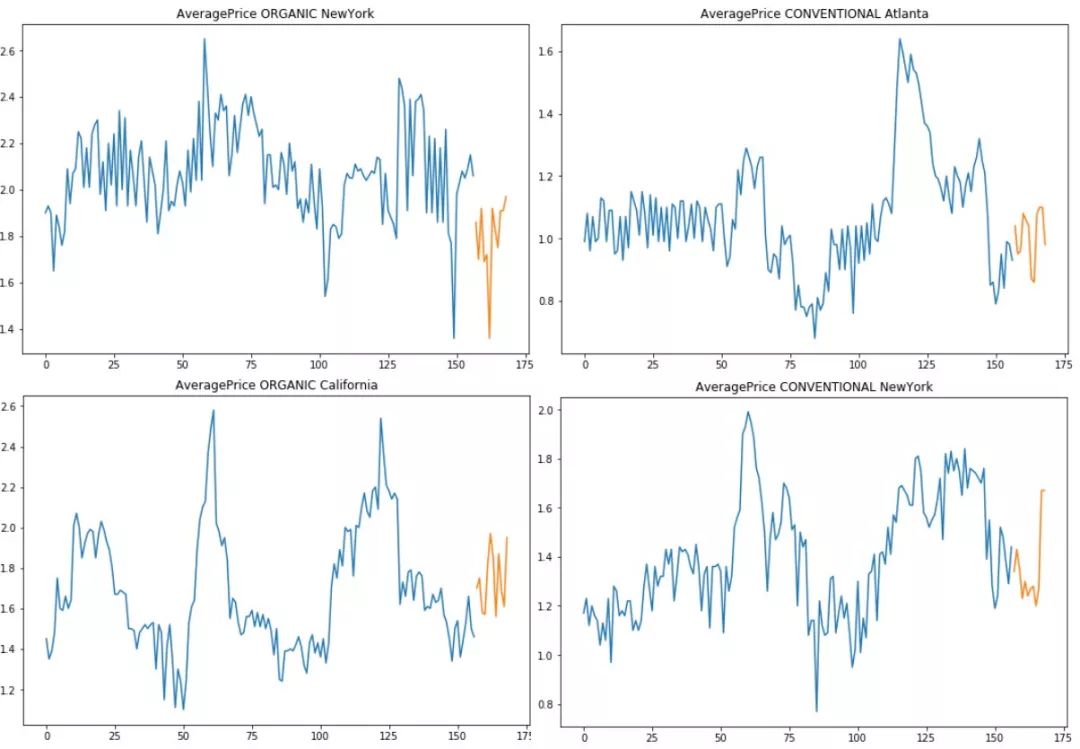
训练数据(蓝色)测试数据(橘色),囊括所有数据
由于缺乏指数增长和交易行为,我们不需要扩展我们的价格序列。
模型
为了解决我们的预测任务,我们复制了Uber的一个新结构模型,它时一个但模型却为我们提供了复杂的预测功能。如下图所示,我们训练LSTM Autoencoder作为我们模型的第一部分:自动特征提取,这对于大量捕获复杂的动态时间序列是很重要的。特征向量通过拼接后作为新的输入传到LSTM Forecaster模块中做预测(autoencoder模块输入的是多个时间序列,这里是拼接好的单一向量)。
我们的forecaster模块的工作流程十分好理解:我们有一个初始的窗口,代表着不同商场的若干周售价数据。我们首先使用这些数据去训练我们LSTM Autoencoder,之后删除encoder模块,并利用它制作特征生成器,最后再去训练我们forecaster模块中的LSTM 模型做预测任务。基于真实/存在的回归值和人造向量我们可以获得的下周的鳄梨预测价格。
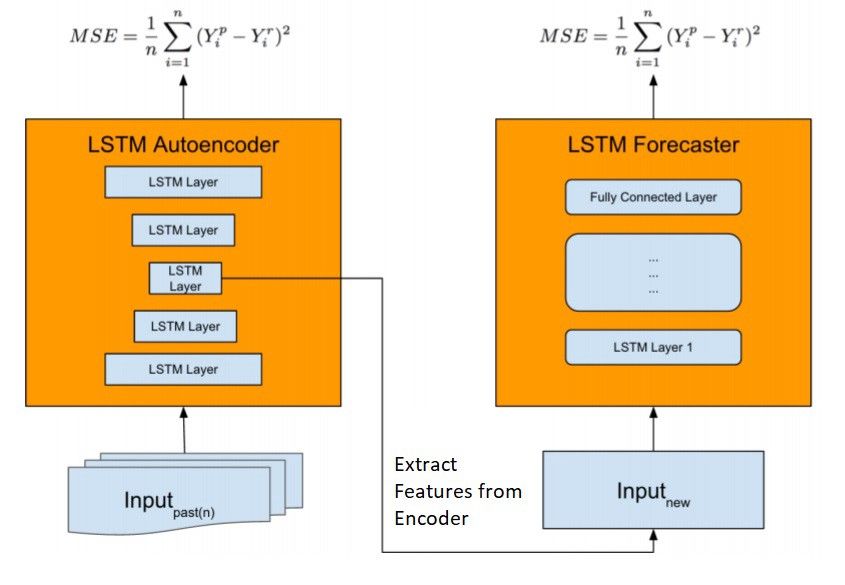
图片来自于Time-series ExtremeEvent Forecasting with Neural Networks at Uber
我们可以很容易地在keras实现这个逻辑。
我们的LSTMAutoencoders模块由简单的LSTM encoder层组成,其余则由LSTM decoder组成,最后还有一层TImeDistribute层,切莫忘了。你将知道在模型验证时添加dropout的好处,相信我,不会害你的。
input_ae= Input(shape = (sequence_length, 1))encode_ae = LSTM(128, return_sequences = True, dropout = 0.3)(input_ae, training = True)decode_ae = LSTM(32, return_sequences = True, dropout = 0.3)(encode_ae, training = True)out_ae = TimeDistributed(Dense(1))(decode_ae)
sequence_autoencoder = Model(input_ae, out_ae)sequence_autoencoder.compile(optimizer='adam', loss='mse', metrics=['mse'])
sequence_autoencoder.fit(X, y, batch_size = 16, epochs = 100, verbose = 2, shuffle=True)
我们会将特征提取部分计算出来并拼接作为其他变量。关于这点我和Uber的解决方案有点偏差:他们建议使用整合技术(例如平均)将特征向量聚合,作为我们特征向量的提取操作。我决定让它们保持原样,因为在我的实验中这样可以给我带来更好的结果。encoder = Model(input_ae, encode_ae)XX = encoder.predict(X)XXF = np.concatenate([XX, F], axis = 2)
最后,预测模型是另一个基于简单LSTM的神经网络。
inputs1 = Input(X_train1.shapw[1], X_train1.shape[2])lstm1 = LSMT(128, return_sequence=True, dropout = 0.3)(inputs1, training = True)lstm1 = LSTM(32, return_sequence=True, dropout = 0.3)(lstm1, training = True)dense1 = Dense(50)(lstm1)out1 = Dense(1)(dense1)
model1 = Model(inputs, out1)model1.compile(loss='mse', optimizer='adam', metrics=['mse'])
model.fit(X_train1, y_train1, epochs=30, batch_size=128, verbose=2, sh
最后,我们已经准备好看一些结果和做预测。最后一步所要做的是,为了进行结果对比,我们需要创建一个对抗模型,制造出一些具有健壮性预测方法的结果。
个人来看,评估两个不同程序的最好方法是尽可能多的重复自身,为了能够让它们能够聚焦在真正需要关注的点上。在这次实践中,我想展示一些LSTM自编码能够作为一个有力的工具,产出对时序数据预测有利的相关特征的证据。在这种层面上去评估我们方法的好处,我决定去开发一个新的预测价格的模型,用之前预测NN同样的结构。

模型1 和模型2 之间不同点在于,它们接收到的特征不一样:
模型1接收编码器输出加上回归结果;
模型2接收历史原始数据加上回归结果。
不确定性估计
在自然中对于事关利益的极端事件时序预测是非常重要的。另外,如果你尝试创建一个基于神经网络的模型,你的结果也将会受制于神经网络初始权重初始化,为了克服这个缺点,有一些现存的方法来应对不确定性估计:从贝叶斯到基于bootstrap理论。
在Uber研究员的工作中,他们融合来bootstrap和贝叶斯方法来创建一个简单、健壮、有确定便捷的、并且易收敛的模型。
这项技术是非常简单并且实用,我们已经部署上来。如下图所示,在神经网络前馈过程中,dropout应用在每一层中,包括编码层和预测网络。结果,编码层随机dropout能够在嵌入空间更聪明的输入,让模型泛化能力增强,而且传播更远通过预测网络。
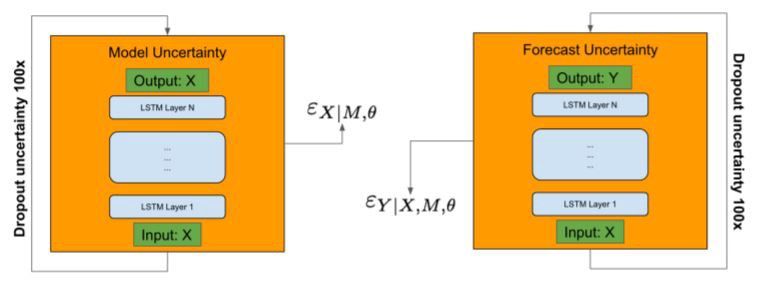
很python的说,在神经网络中我们简单增加一些可训练的dropout层,在预测中我们激活它们(keras预测中去除来dropout),下边是我用过的一些简单功能,简化为:dropout 激活,特征串联,预测所有的数据。

为了最后的评估,我们必须迭代调用上边的函数,存储它们的结果。我也可以计算出在每一次迭代中的预测分值(我选择的是均绝对值误差)。
scores1 = []for i in tqdm.tqdm(range(0,100)): scores1.append(mean_absolute_error(stoc_drop1(0.5), y_test1))
print(np.mean(scores1), np.std(scores1))
我们必须设置超参数,就是迭代次数,dropout比率。存储每一次预测分值之后,我们可以计算均值,标准差,以及相关均方绝对值误差。 预测和结果
我们对我们的“竞争模型”复制了同样的过程,只使用lstm预测网络。在平均得分和计算不确定度后,最终结果为:LSTM自动编码器+LSTM预报员0.118 Mae(0.0012 Mae不确定度),单个LSTM预报员0.124 Mae(0.0015 Mae不确定度)。在不确定性程度相同的情况下,我们的预测精度最终提高了5%。我们可以断言,我们的lstm自动编码器是一个从时间序列中提取重要的未知特征的好武器。下面我还报告了有机鳄梨和传统鳄梨在单一市场上的得分表现。
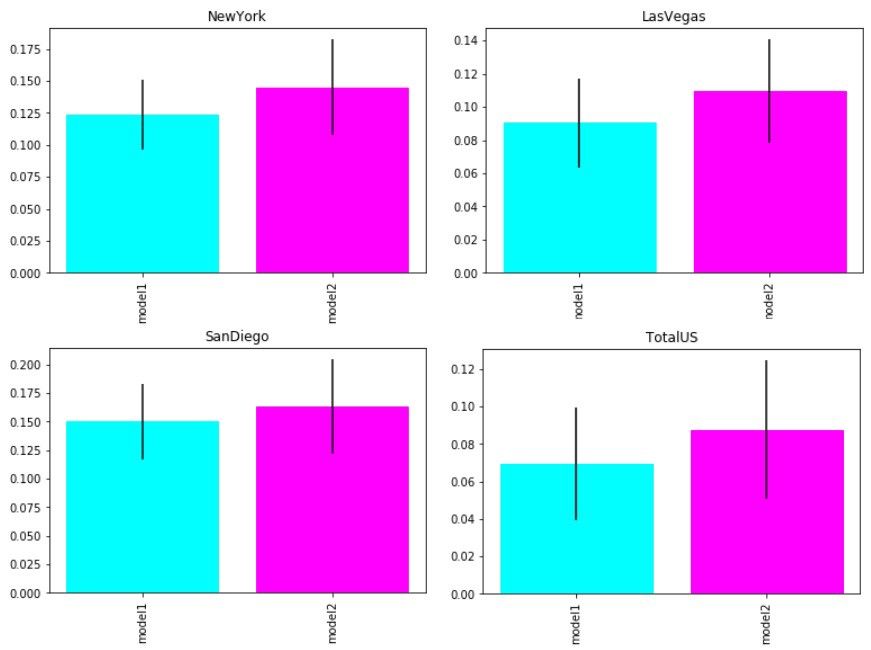
测试数据的性能(mae)比较
在训练期间,我也保留排除整个市场(奥尔巴尼地区)的权利。这是因为我想测试我们的网络在没有训练过的数据上的效果。我们在有机市场和传统市场的表现都有所改善。
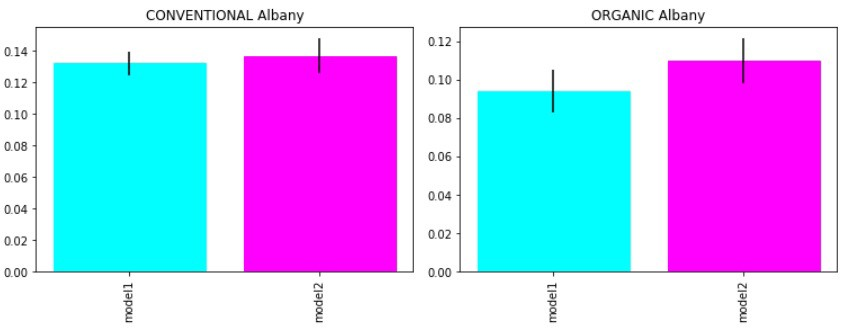
看不见时间序列的性能比较
总结
在本文中,我复制了Uber为特殊事件预测开发的端到端神经网络架构。我想强调的是:lstm自动编码器在特征提取中的作用;该方案的可扩展性,能够很好地推广,避免了为每个时间序列训练多个模型;能够为神经网络的评价提供一种稳定而有益的方法。
我还注意到,当你有足够数量的时间序列共享共同的行为时,这种解决方案非常适合……这些行为不是显而易见的重要,而是自动编码器为我们制造的。
[1] Deep and Confident Prediction for Time Series atUber: Lingxue Zhu, Nikolay Laptev
[2] Time-series ExtremeEvent Forecasting with Neural Networks at Uber: Nikolay Laptev, Jason Yosinski,Li Erran Li, Slawek Smyl
via https://towardsdatascience.com/extreme-event-forecasting-with-lstm-autoencoders-297492485037








