
原文来源:arxiv
作者:Judea Pearl
「雷克世界」编译:嗯~是阿童木呀
可以这样说,目前的机器学习系统几乎完全是以统计模式或无模型模式运行的,这对于其功率和性能来说存在着严格的理论限制。这样的系统不能引发干预和反思,因此不能作为强人工智能的基础。为了达到人类的智力水平,学习机器需要一个现实模型的指导,就类似于在因果推理任务中所使用的模型。为了演示这些模型的基本作用,在本文中,我将对当前机器学习系统所无法实现的7项任务作一个总结,而且这些任务是使用因果建模工具完成的。
科学背景
如果我们检查如今驱动机器学习的信息是什么,我们会发现它几乎完全是统计信息。换句话说,学习机器通过优化来自环境的感官输入流上的参数来改善其性能。这是一个缓慢的过程,在很多方面类似于推动达尔文进化论观点的自然选择过程。它解释了老鹰和蛇这样的物种是如何在数百万年的时间里进化为具有高超的视觉系统的。然而,它并不能解释为什么人类在仅仅一千年的时间里就能制造出眼镜和望远镜这样的超级进化过程。人类所拥有的其他物种所缺乏的是一种心理表征,一种他们可以操纵的环境蓝图,从而他们可以想象另一种假想的环境以进行规划和学习。像N. Harari和S. Mithen这样的人类学家普遍认为,在4万年前,我们的智人祖先(Homo sapiens ancestors)之所以具有实现全球统治的能力,决定性因素在于他们具有这样一种能力,对其环境进行心理表征编排、不断问询该表征、通过想象的心理行为扭曲它、最后回答“如果?”类问题。例如介入性问题:“如果我采取行动,会怎么样?”以及反思性或解释性问题:“如果我采取了不同的行动,结果又会怎么样呢?”今天,没有任何一个学习机器可以回答这样的问题,比如“如果我们禁止吸烟,会怎么样?”除此之外,今天的大多数学习机器都不能从这样的问题中提供一些表征,其中,这些问题的答案是可以推导出来的。
我认为,对于阻碍实现加速学习速度和人类水平性能表现的主要障碍来说,应该通过消除这些障碍并为学习机器配备因果推理工具来克服。其实,这个假设在二十年前,在反事实数学化(mathematization of counterfactuals)之前就已经被推测出来了。但今天的情况不一样了。
图形化和结构化模型的进步使反事实在计算上易于管理,从而使得模型驱动推理成为一个更有前途的研究方向,从而建立强人工智能。
下面,我将使用一个三级层次来描述机器学习系统所面临的障碍,这个三级层次管理因果推理中的推理。

因果关系的层次结构。只有当i级或更高级的信息可用时,i级的问题才能够被回答
我们从上图可以看出,因果推理的逻辑揭示了一个极其有用的见解,即对因果信息的一个清晰分类,就每个类别能够回答的问题类型而言,这个分类形成了一个三层次的层次结构,这意味着只有当j级(j≥i)的信息可用时, i级(i = 1,2,3)上的问题才能被回答。
因果革命中的七大支柱(或者你只能使用因果模型才能做,不使用便不能做的是什么?)考虑以下五个问题:
这些问题的共同特点是它们关心的是因果关系。我们可以通过诸如“防止”、“原因”、“归因于”、“歧视”和“我应该”这样的字眼来识别它们。这些词是常见的日常用语,以及我们的社会不断地要求对这些问题进行回答。然而,直到现在,科学还是没有办法将其表达出来,更不用说回答它们了。与几何、力学、光学或概率规则不同,因果规则早已被否定了数学分析的好处。
哈佛大学教授Golry King从历史的角度给出了这样一种转变:“在过去的几十年里,人们对于因果推断的了解比以前所有历史记录中所学到的事物总和还要多”(Morgan和Winship于2015年提出)。我把这种转变称为“因果革命”(Pearl和Mackenzie于2018年提出),而对于导致它出现的数学框架,我将其称之为“结构性因果模型(SCM)”。SCM部署了三个部分:
1.图形化模型
2.结构化方程
3.反事实和介入逻辑
图形化模型作为一种语言,用以表达我们对世界的了解,反事实有助于我们阐明我们想知道的东西,而结构化方程则是将这两者结合在一起,形成一个坚实的语义。
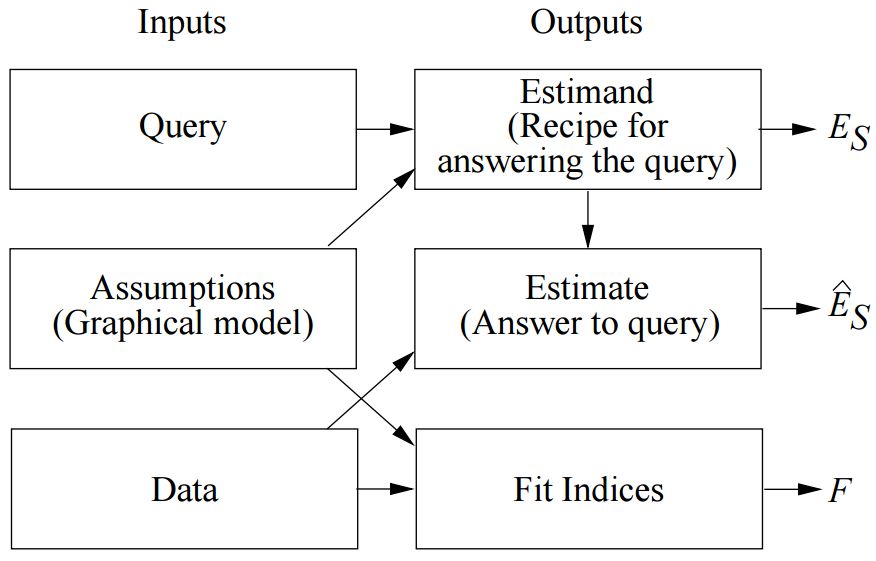
该图展示了,SCM“推理引擎”是如何将数据与因果模型(或假设)结合起来,以生成对有用查询的答案
接下来,我们将对SCM框架的七项成就进行一个概述,并讨论每个支柱为自动推理艺术带来的独特贡献。
支柱1:对因果假设进行编码 ——透明度和可测试性
一旦我们认真对待透明度和可测试性的要求,用一种紧凑的、可用的形式对假设进行编码的任务并不是一件简单的事情。透明度使分析人员能够辨别所编码的假设是否合理(基于科学依据),或者是否有必要进行额外的假设。可测试性使我们(无论是分析师还是机器)能够确定所编码的假设是否与可用数据兼容,如果不能,则确定那些需要修复的假设。
支柱2:做微积分和对混淆的控制
混淆(confounding),或者是存在于两个或更多变量中未被察觉的原因,长期以来一直被认为是从数据中得出因果推断的主要障碍。这一障碍已经通过一个被称为“后门(back-door)”的图形化标准揭开且被“去混乱(deconfounded)”了。特别地,选择一组适当的协变量来控制混淆的任务已经被简化为一个可以通过简单算法(Pearl,1993)进行管理的“路障”难题。
支柱3:反事实的算法化
反事实分析处理的是特定个体的行为,通过一组不同的特征对其进行确定。例如,考虑到乔的薪水是Y = y,并且他读了X = X年大学,那么,如果他再接受一年的教育,他的薪水会是多少。
支柱4:中介分析与直接和间接影响评估
中介分析(Mediation Analysis)涉及的是一个将变更从原因传递到其影响的机制。这种中间机制的识别对于生成解释是必不可少的,而反事实分析必须被调用以促进这种识别。反事实的图形化表示使得我们能够定义直接和间接的影响,并决定何时这些影响该从数据或实验中进行评估(Robins和Greenland于1992、Pearl于2001年、VanderWeele于2015年提出)。通过这种分析可以回答的典型查询是:X对Y的影响有多少是由变量z来调节的。
支柱5:外部有效性和样本选择偏差
每个实验研究的有效性都受到实验和实施设置之间差异的挑战。在环境条件改变的情况下,在一个环境中进行训练的机器不能期望其能够表现良好,除非这些改变是局部的且是可以确定的。这个问题及其各种表现形式已经得到机器学习研究人员的认可,诸如“领域适应”、“迁移学习”、“终身学习”和“具有可解释性的AI”等企业只是研究人员和资助机构确定的一些子任务,试图缓解鲁棒性的通用问题。不幸的是,鲁棒性问题需要一个环境的因果模型,并且不能在关联级别上进行处理,在这个层面上,大多数的补救措施都被尝试过了。而关联还不足以确定受所发生变化影响的机制。上面讨论的do-calculus提供了一个完整的方法以克服由于环境变化造成的偏见。它既可用于重新调整学习政策,以规避环境变化,也可用于控制非典型样本的偏差(Bareinboim和Pearl于2016年提出)。
支柱6:缺失数据
缺失数据的问题困扰着实验科学的每一个分支。受访者不回答问卷中的每个一项,随着环境条件的变化,传感器会逐渐消失,而患者往往因为不明原因从临床研究中退出。关于这个问题的丰富的文献与统计分析的model-blind模式相吻合,因此,它被严重地限制在随机发生的情况下,也就是说,与模型中其他变量所取的值无关。通过使用缺失过程的因果模型,我们现在可以在把因果关系和概率关系从不完整的数据中恢复的情况下,对条件进行形式化,并且只要条件满足,就可以产生对所需关系的一致估计(Mohan和Pearl于2017年提出)。
支柱7:因果发现
上述的d-分离标准使我们能够检测和列举给定因果模型的可测试含义。这就开启了这样一种可能性,即假设一组与数据兼容的模型,并可以很紧凑地对这个集进行表征。系统搜索已经被开发出来,在某些情况下,可以将一组兼容模型显著地裁剪到可以从该集中直接对因果查询进行估计的程度。
结论
哲学家Stephen Toulmin于1961确定了model-based和model-blind的二分法,认为这是理解巴比伦与希腊科学之间古代竞争的关键。根据Toulmin的说法,巴比伦天文学家是黑盒预测的主人,在准确性和一致性方面远远超过了他们的希腊对手。然而科学青睐希腊天文学家的创造性思辨策略,这些天文学家对形而上学的意象充满了狂热:充满火焰的圆形管、小洞通过神圣的火焰可以看到星星、还有骑在龟背上的半球形地球。然而,这种狂热的建模策略,并不是巴比伦的僵化,而是促使Eratosthenes(公元前276 - 194年)早在古代世界就进行了最有创造性的实验之一,并测量了地球的半径。这在巴比伦的曲线钳工身上是绝对不会发生的。
回到强人工智能上,我们已经看到model-blind的方法对它们可以执行的认知任务的内在局限性。我们描述了其中的一些任务,并展示了如何在SCM框架中完成这些任务,以及为什么基于模型的方法对于执行这些任务是必不可少的。我们的总体结论是人类水平的AI不能单纯地从model-blind的学习机器中出现,它需要数据和模型的共生协作。
数据科学只不过是一门科学,它有助于对数据进行解释——一个两体问题,将数据与现实联系起来。而不管数据有多大,以及它们被操纵得多么巧妙,数据本身并不是一门科学。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”












