公众号后台回复“面试”,获取精品学习资料

扫描下方海报了解专栏详情


本文来源:杨建荣的学习笔记
《Java工程师面试突击(第3季)》重磅升级,由原来的70讲增至160讲,内容扩充一倍多,升级部分内容请参见文末
千万级大表如何优化,这是一个很有技术含量的问题,通常我们的直觉思维都会跳转到拆分或者数据分区,在此我想做一些补充和梳理,想和大家做一些这方面的经验总结,也欢迎大家提出建议。
图片来自 Pexels
从一开始脑海里火光四现,到不断的自我批评,后来也参考了一些团队的经验,我整理了下面的大纲内容。
既然要吃透这个问题,我们势必要回到本源,我把这个问题分为三部分:“千万级”,“大表”,“优化”,也分别对应我们在图中标识的“数据量”,“对象”和“目标”。
我来逐步展开说明一下,从而给出一系列的解决方案。
千万级其实只是一个感官的数字,就是我们印象中的数据量大。
这里我们需要把这个概念细化,因为随着业务和时间的变化,数据量也会有变化,我们应该是带着一种动态思维来审视这个指标,从而对于不同的场景我们应该有不同的处理策略。
①数据量为千万级,可能达到亿级或者更高
通常是一些数据流水,日志记录的业务,里面的数据随着时间的增长会逐步增多,超过千万门槛是很容易的一件事情。
②数据量为千万级,是一个相对稳定的数据量
如果数据量相对稳定,通常是在一些偏向于状态的数据,比如有 1000 万用户,那么这些用户的信息在表中都有相应的一行数据记录,随着业务的增长,这个量级相对是比较稳定的。
③数据量为千万级,不应该有这么多的数据
这种情况是我们被动发现的居多,通常发现的时候已经晚了,比如你看到一个配置表,数据量上千万;或者说一些表里的数据已经存储了很久,99% 的数据都属于过期数据或者垃圾数据。
数据量是一个整体的认识,我们需要对数据做更近一层的理解,这就可以引出第二个部分的内容。
数据操作的过程就好比数据库中存在着多条管道,这些管道中都流淌着要处理的数据,这些数据的用处和归属是不一样的。
一般根据业务类型把数据分为三种:
①流水型数据
流水型数据是无状态的,多笔业务之间没有关联,每次业务过来的时候都会产生新的单据。
比如交易流水、支付流水,只要能插入新单据就能完成业务,特点是后面的数据不依赖前面的数据,所有的数据按时间流水进入数据库。
②状态型数据
状态型数据是有状态的,多笔业务之间依赖于有状态的数据,而且要保证该数据的准确性,比如充值时必须要拿到原来的余额,才能支付成功。
③配置型数据
此类型数据数据量较小,而且结构简单,一般为静态数据,变化频率很低。
至此,我们可以对整体的背景有一个认识了,如果要做优化,其实要面对的是这样的 3*3 的矩阵,如果要考虑表的读写比例(读多写少,读少写多...),那么就会是 3*3*4=24 种,显然做穷举是不显示的,而且也完全没有必要,可以针对不同的数据存储特性和业务特点来指定不同的业务策略。
对此我们采取抓住重点的方式,把常见的一些优化思路梳理出来,尤其是里面的核心思想,也是我们整个优化设计的一把尺子,而难度决定了我们做这件事情的动力和风险。

而对于优化方案,我想采用面向业务的维度来进行阐述。
在这个阶段,我们要说优化的方案了,总结的有点多,相对来说是比较全了。整体分为五个部分:
其实我们通常所说的分库分表等方案只是其中的一小部分,如果展开之后就比较丰富了。不难理解,我们要支撑的表数据量是千万级别,相对来说是比较大了,DBA 要维护的表肯定不止一张,如何能够更好的管理,同时在业务发展中能够支撑扩展,同时保证性能,这是摆在我们面前的几座大山。
我们分别来说一下这五类改进方案:
在此我们先提到的是规范设计,而不是其他高大上的设计方案。
黑格尔说:秩序是自由的第一条件。在分工协作的工作场景中尤其重要,否则团队之间互相牵制太多,问题多多。
我想提到如下的几个规范,其实只是属于开发规范的一部分内容,可以作为参考。
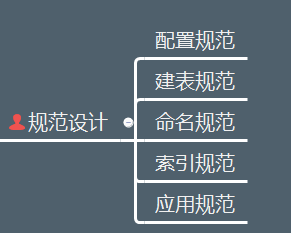
规范的本质不是解决问题,而是有效杜绝一些潜在问题,对于千万级大表要遵守的规范,我梳理了如下的一些细则,基本可以涵盖我们常见的一些设计和使用问题。
比如表的字段设计不管三七二十一,都是 varchar(500),其实是很不规范的一种实现方式,我们来展开说一下这几个规范。
配置规范:
MySQL 数据库默认使用 InnoDB 存储引擎。
保证字符集设置统一,MySQL 数据库相关系统、数据库、表的字符集都使用 UTF8,应用程序连接、展示等可以设置字符集的地方也都统一设置为 UTF8 字符集。
注:UTF8 格式是存储不了表情类数据,需要使用 UTF8MB4,可在 MySQL 字符集里面设置。在 8.0 中已经默认为 UTF8MB4,可以根据公司的业务情况进行统一或者定制化设置。
MySQL 数据库的事务隔离级别默认为 RR(Repeatable-Read),建议初始化时统一设置为 RC(Read-Committed),对于 OLTP 业务更适合。
数据库中的表要合理规划,控制单表数据量,对于 MySQL 数据库来说,建议单表记录数控制在 2000W 以内。
MySQL 实例下,数据库、表数量尽可能少;数据库一般不超过 50 个,每个数据库下,数据表数量一般不超过 500 个(包括分区表)。
建表规范:
InnoDB 禁止使用外键约束,可以通过程序层面保证。
存储精确浮点数必须使用 DECIMAL 替代 FLOAT 和 DOUBLE。
整型定义中无需定义显示宽度,比如:使用 INT,而不是 INT(4)。
不建议使用 ENUM 类型,可使用 TINYINT 来代替。
尽可能不使用 TEXT、BLOB 类型,如果必须使用,建议将过大字段或是不常用的描述型较大字段拆分到其他表中;另外,禁止用数据库存储图片或文件。
存储年时使用 YEAR(4),不使用 YEAR(2)。
建议字段定义为 NOT NULL。
建议 DBA 提供 SQL 审核工具,建表规范性需要通过审核工具审核后。
命名规范:
对于对象命名规范的一个简要总结如下表所示,供参考:
命名列表
索引规范:
索引建议命名规则:idx_col1_col2[_colN]、uniq_col1_col2[_colN](如果字段过长建议采用缩写)。
索引中的字段数建议不超过 5 个。
单张表的索引个数控制在 5 个以内。
InnoDB 表一般都建议有主键列,尤其在高可用集群方案中是作为必须项的。
建立复合索引时,优先将选择性高的字段放在前面。
UPDATE、DELETE 语句需要根据 WHERE 条件添加索引。
不建议使用 % 前缀模糊查询,例如 LIKE “%weibo”,无法用到索引,会导致全表扫描。
合理利用覆盖索引,例如:SELECT email,uid FROM user_email WHERE uid=xx,如果 uid 不是主键,可以创建覆盖索引 idx_uid_email(uid,email)来提高查询效率。
避免在索引字段上使用函数,否则会导致查询时索引失效。
确认索引是否需要变更时要联系 DBA。
应用规范:
避免使用存储过程、触发器、自定义函数等,容易将业务逻辑和DB耦合在一起,后期做分布式方案时会成为瓶颈。
考虑使用 UNION ALL,减少使用 UNION,因为 UNION ALL 不去重,而少了排序操作,速度相对比 UNION 要快,如果没有去重的需求,优先使用 UNION ALL。
考虑使用 limit N,少用 limit M,N,特别是大表或 M 比较大的时候。
减少或避免排序,如:group by 语句中如果不需要排序,可以增加 order by null。
统计表中记录数时使用 COUNT(*),而不是 COUNT(primary_key) 和 COUNT(1)。
InnoDB 表避免使用 COUNT(*) 操作,计数统计实时要求较强可以使用 Memcache 或者 Redis,非实时统计可以使用单独统计表,定时更新。
做字段变更操作(modify column/change column)的时候必须加上原有的注释属性,否则修改后,注释会丢失。
使用 prepared statement 可以提高性能并且避免 SQL 注入。
SQL 语句中 IN 包含的值不应过多。
UPDATE、DELETE 语句一定要有明确的 WHERE 条件。
WHERE 条件中的字段值需要符合该字段的数据类型,避免 MySQL 进行隐式类型转化。
SELECT、INSERT 语句必须显式的指明字段名称,禁止使用 SELECT * 或是 INSERT INTO table_name values()。
INSERT 语句使用 batch 提交(INSERT INTO table_name VALUES(),(),()……),values 的个数不应过多。
业务层优化应该是收益最高的优化方式了,而且对于业务层完全可见,主要有业务拆分,数据拆分和两类常见的优化场景(读多写少,读少写多)!
①业务拆分
业务拆分分为如下两个方面:
业务拆分其实是把一个混合的业务剥离成为更加清晰的独立业务,这样业务 1,业务 2......独立的业务使得业务总量依旧很大,但是每个部分都是相对独立的,可靠性依然有保证。
对于状态和历史数据分离,我可以举一个例子来说明。
例如:我们有一张表 Account,假设用户余额为 100。我们需要在发生数据变更后,能够追溯数据变更的历史信息,如果对账户更新状态数据,增加 100 的余额,这样余额为 200。
这个过程可能对应一条 update 语句,一条 insert 语句。对此我们可以改造为两个不同的数据源,account 和 account_hist。
在 account_hist 中就会是两条 insert 记录,如下:而在 account 中则是一条 update 语句,如下:这也是一种很基础的冷热分离,可以大大减少维护的复杂度,提高业务响应效率。
②数据拆分
按照日期拆分:这种使用方式比较普遍,尤其是按照日期维度的拆分,其实在程序层面的改动很小,但是扩展性方面的收益很大。
数据按照日期维度拆分,如 test_20191021。
数据按照周月为维度拆分,如 test_201910。
数据按照季度,年维度拆分,如 test_2019。
采用分区模式:分区模式也是常见的使用方式,采用 hash,range 等方式会多一些。
在 MySQL 中我是不大建议使用分区表的使用方式,因为随着存储容量的增长,数据虽然做了垂直拆分,但是归根结底,数据其实难以实现水平扩展,在 MySQL 中是有更好的扩展方式。
采用缓存,采用 Redis 技术,将读请求打在缓存层面,这样可以大大降低 MySQL 层面的热点数据查询压力。
对于业务数据,比如积分类,相比于金额来说业务优先级略低的场景,如果数据的更新过于频繁,可以适度调整数据更新的范围(比如从原来的每分钟调整为 10 分钟)来减少更新的频率。
例如:更新状态数据,积分为 200,如下图所示:

可以改造为,如下图所示:

如果业务数据在短时间内更新过于频繁,比如 1 分钟更新 100 次,积分从 100 到 10000,则可以根据时间频率批量提交。
例如:更新状态数据,积分为 100,如下图所示:

无需生成 100 个事务(200 条 SQL 语句)可以改造为 2 条 SQL 语句,如下图所示:

对于业务指标,比如更新频率细节信息,可以根据具体业务场景来讨论决定。
架构层优化其实就是我们认为的那种技术含量很高的工作,我们需要根据业务场景在架构层面引入一些新的花样来。

采用中间件技术:可以实现数据路由,水平扩展,常见的中间件有 MyCAT,ShardingSphere,ProxySQL 等。
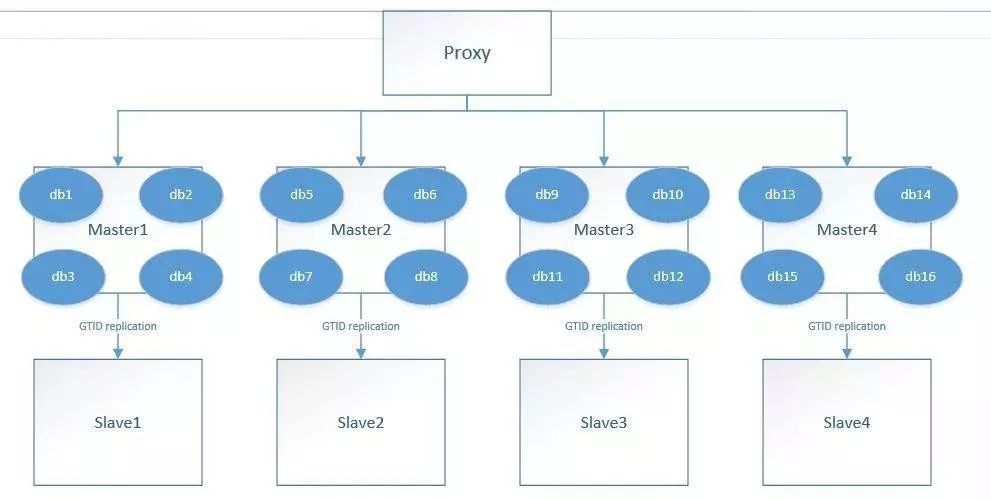
采用读写分离技术:这是针对读需求的扩展,更侧重于状态表,在允许一定延迟的情况下,可以采用多副本的模式实现读需求的水平扩展,也可以采用中间件来实现,如 MyCAT,ProxySQL,MaxScale,MySQL Router 等。
采用负载均衡技术:常见的有 LVS 技术或者基于域名服务的 Consul 技术等。
可以采用 NewSQL,优先兼容 MySQL 协议的 HTAP 技术栈,如 TiDB。
数据库优化,其实可打的牌也不少,但是相对来说空间没有那么大了,我们来逐个说一下。
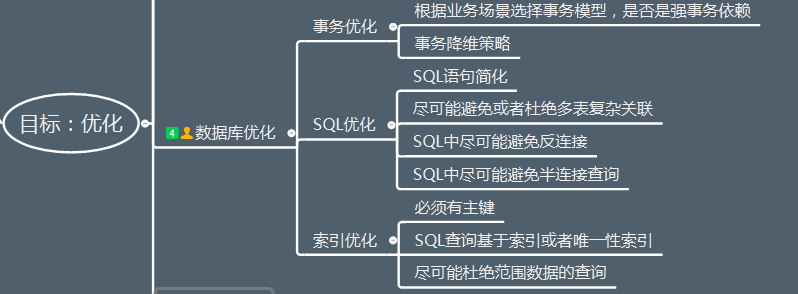
根据业务场景选择事务模型,是否是强事务依赖。对于事务降维策略,我们来举出几个小例子来。
降维策略 1:存储过程调用转换为透明的 SQL 调用
对于新业务而言,使用存储过程显然不是一个好主意,MySQL 的存储过程和其他商业数据库相比,功能和性能都有待验证,而且在目前轻量化的业务处理中,存储过程的处理方式太“重”了。
有些应用架构看起来是按照分布式部署的,但在数据库层的调用方式是基于存储过程,因为存储过程封装了大量的逻辑,难以调试,而且移植性不高。
这样业务逻辑和性能压力都在数据库层面了,使得数据库层很容易成为瓶颈,而且难以实现真正的分布式。
所以有一个明确的改进方向就是对于存储过程的改造,把它改造为 SQL 调用的方式,可以极大地提高业务的处理效率,在数据库的接口调用上足够简单而且清晰可控。
有些业务经常会有一种紧急需求,总是需要给一个表添加字段,搞得 DBA 和业务同学都挺累,可以想象一个表有上百个字段,而且基本都是 name1,name2……name100,这种设计本身就是有问题的,更不用考虑性能了。
究其原因,是因为业务的需求动态变化,比如一个游戏装备有 20 个属性,可能过了一个月之后就增加到了 40 个属性,这样一来,所有的装备都有 40 个属性,不管用没用到,而且这种方式也存在诸多的冗余。
我们在设计规范里面也提到了一些设计的基本要素,在这些基础上需要补充的是,保持有限的字段,如果要实现这些功能的扩展,其实完全可以通过配置化的方式来实现,比如把一些动态添加的字段转换为一些配置信息。
配置信息可以通过 DML 的方式进行修改和补充,对于数据入口也可以更加动态、易扩展。
有些业务需要定期来清理一些周期性数据,比如表里的数据只保留一个月,那么超出时间范围的数据就要清理掉了。而如果表的量级比较大的情况下,这种 Delete 操作的代价实在太高,我们可以有两类解决方案来把 Delete 操作转换为更为高效的方式。
第一种是根据业务建立周期表,比如按照月表、周表、日表等维度来设计,这样数据的清理就是一个相对可控而且高效的方式了。
第二种方案是使用 MySQL rename 的操作方式,比如一张 2 千万的大表要清理 99% 的数据,那么需要保留的 1% 的数据我们可以很快根据条件过滤补录,实现“移形换位”。
其实相对来说需要的极简的设计,很多点都在规范设计里面了,如果遵守规范,八九不离十的问题都会杜绝掉。
SQL 语句简化,简化是 SQL 优化的一大利器,因为简单,所以优越。
尽可能避免或者杜绝多表复杂关联,大表关联是大表处理的噩梦,一旦打开了这个口子,越来越多的需求需要关联,性能优化就没有回头路了,更何况大表关联是 MySQL 的弱项,尽管 Hash Join 才推出,不要像掌握了绝对大杀器一样,在商业数据库中早就存在,问题照样层出不穷。
SQL 中尽可能避免反连接,避免半连接,这是优化器做得薄弱的一方面,什么是反连接,半连接?
其实比较好理解,举个例子:not in,not exists 就是反连接,in,exists 就是半连接,在千万级大表中出现这种问题,性能是几个数量级的差异。
首先必须有主键,规范设计中第一条就是,此处不接收反驳。
其次,SQL 查询基于索引或者唯一性索引,使得查询模型尽可能简单。
最后,尽可能杜绝范围数据的查询,范围扫描在千万级大表情况下还是尽可能减少。
这部分应该是在所有的解决方案中最容易被忽视的部分了,我放在最后,在此也向运维同事致敬,总是为很多认为本应该正常的问题尽职尽责(背锅)。千万级大表的数据清理一般来说是比较耗时的,在此建议在设计中需要完善冷热数据分离的策略,可能听起来比较拗口,我来举一个例子,把大表的 Drop 操作转换为可逆的 DDL 操作。
Drop 操作是默认提交的,而且是不可逆的,在数据库操作中都是跑路的代名词,MySQL 层面目前没有相应的 Drop 操作恢复功能,除非通过备份来恢复,但是我们可以考虑将 Drop 操作转换为一种可逆的 DDL 操作。
MySQL 中默认每个表有一个对应的 ibd 文件,其实可以把 Drop 操作转换为一个 rename 操作,即把文件从 testdb 迁移到 testdb_arch 下面。
从权限上来说,testdb_arch 是业务不可见的,rename 操作可以平滑的实现这个删除功能,如果在一定时间后确认可以清理,则数据清理对于已有的业务流程是不可见的,如下图所示:
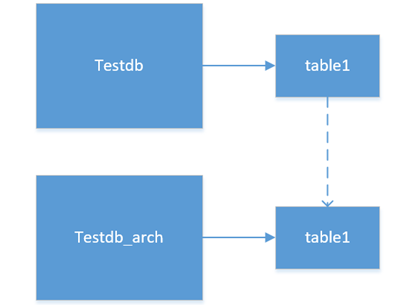
此外,还有两个额外建议,一个是对于大表变更,尽可能考虑低峰时段的在线变更,比如使用 pt-osc 工具或者是维护时段的变更,就不再赘述了。最后总结一下,其实就是一句话:千万级大表的优化是根据业务场景,以成本为代价进行优化的,绝对不是孤立的一个层面的优化。END
《Java工程师面试突击第三季》加餐部分大纲:(注:1-66讲的大纲请扫描文末二维码,在课程详情页获取)



详细的课程内容,大家可以扫描下方二维码了解:








