点击上方“CSDN”,选择“置顶公众号”
关键时刻,第一时间送达!
CSDN编者友情提示:完成本篇阅读至少需要消耗一周能量,请提前收藏~~~

图片来源于网络
通常来讲,我打开Google翻译的次数是Facebook的两倍,对我来说即时翻译不再是“赛博朋克”专属的情节,它已经成为我们现实生活的一部分。很难想象,经过一个世纪的努力机器翻译的算法竟得以实现,期间甚至有一半的时间我们都觉察不到这项科技的发展。
从搜索引擎到如今语音控制的微波炉,机器翻译是所有现代语言处理系统的基础,本文将介绍机器翻译的详细发展历程,以及在线翻译的演变过程与结构。
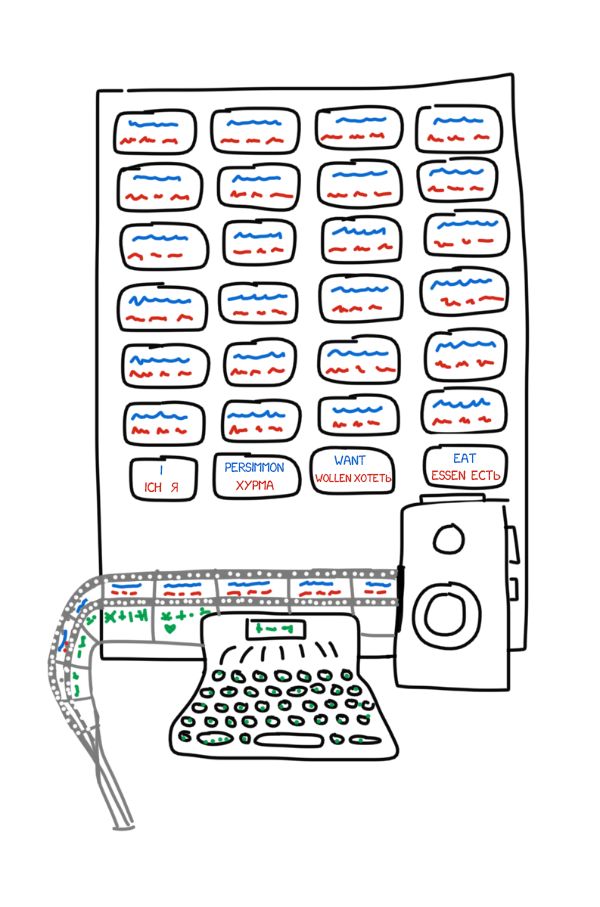
图:P.P. Troyanskii机器翻译,根据描述文字画插画,可惜没有照片流传
开篇
故事源自1933年。
前苏联科学家 Peter Troyanskii 向苏联科学院提交了一篇《双语翻译时用于选择和打印文字的机器》的论文。这项发明非常简单,包括有4种语言的卡片、一部打字机、以及一部旧式的胶卷照相机。
操作人员从文本中拿出第一个单词,找到相应的卡片,然后拍张照片,并在打字机上打出词态,如名词,复数,所有格等。这部打字机的按键构成了一种特征编码。然后利用胶带和照相机的胶卷制作出一帧帧的单词与形态特征的组合。
尽管如此,这项发明被认作“无用”,这种事情在前苏联习以为常。Troyanskii为完成此项发明努力了20年,直到他死于心绞痛。世上无一人知道这个机器,直到1956年两位前苏联科学家发现了他的专利。
而当时冷战爆发了。
1954年1月7日,在IBM纽约总部,Georgetown-IBM实验启动了。IBM的701型计算机将60个俄语句子自动翻译成英语,这是历史上首次的机器翻译。
“一位不懂俄语的女孩在IBM的卡片上打出了俄语信息。‘电脑’以每秒2.5行的惊人速度,在自动打印机上迅速完成了英语的翻译。”——IBM报道说。

IBM 701
然而,这份洋洋得意的头条却隐藏了一个小细节。它并未提到翻译所用到的例子是经过了精心的挑选和测试,并排除了任何歧义。这个系统实际上无外乎形同一本常用语手册。然而,包括加拿大、德国、法国、尤其是日本,各国间就此展开了竞争,所有人都加入了机器翻译的比拼。
机器翻译的比拼
改善机器翻译的无用功持续了40年。
1966年,美国的自动处理咨询委员会(Automatic Language Processing Advisory Committee:ALPAC),在一篇著名的报道中宣称机器翻译昂贵、不准确、且没有希望。他们建议应该更注重词典的开发,这导致了美国研发人员退出了机器翻译竞赛将近10年之久。
即便如此,科学家们还是通过不断的尝试、研究和开发奠定了现代自然语言处理的基础。如今所有的搜索引擎、垃圾邮件过滤器、以及个人助手都要归功于那些年国家间相互的比拼。
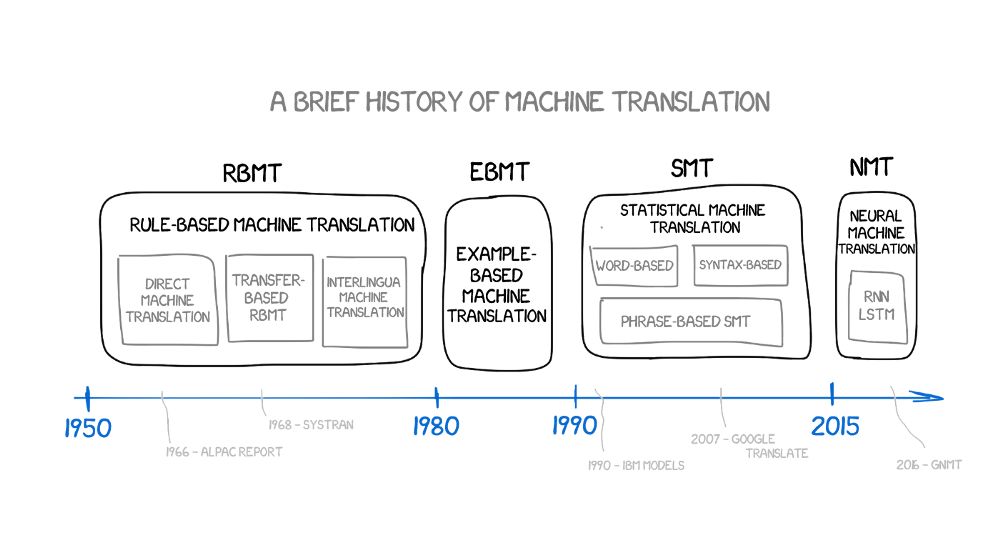
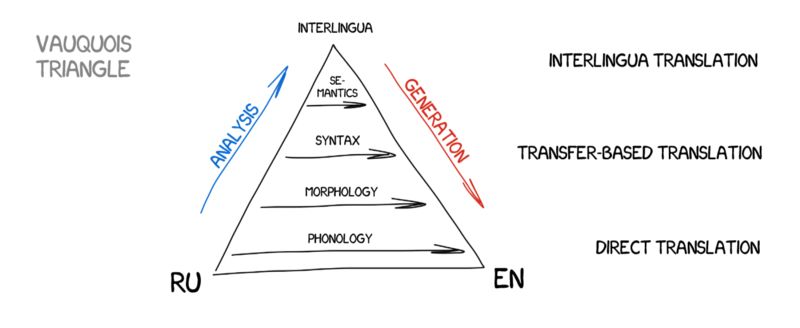
一、基于规则的机器翻译
(Rule-basedmachine translation:RBMT)
基于规则的机器翻译的想法第一次出现是在70年代。科学家根据对翻译者工作的观察,试图驱使巨大笨重的计算机重复翻译行为。这些系统的组成部分包括:
如此而已。如果有必要,系统还可以补充各种技巧性的规则,如名字、拼写纠正、以及音译词等。
PROMPT和Systran是RBMT系统中最有名的例子。看一眼Aliexpress 就能感受到那个黄金时代的气息。
但是它们还有一些细微的差别和变体。
直接翻译法
这种机器翻译最直白。它把文本划分成单词,进行翻译,然后进行轻微的形态调整,再润色语法,让整句话听起来像回事儿。多少个日日夜夜,训练有素的语言学家为每个单词写规则。
输出即为翻译后的句子。通常,翻译的句子听起来都有点蹩脚。似乎语言学家白白浪费了他们的时间。
现代语言系统不再使用这样的方法,所以语言学家可以松口气了。
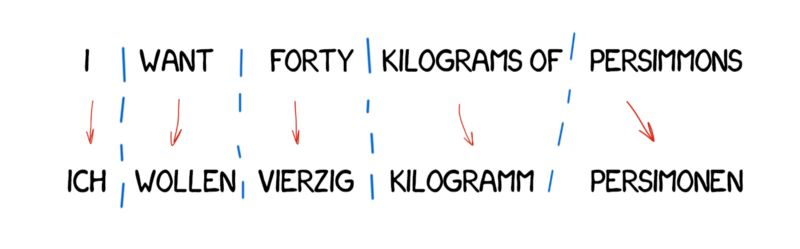
转换翻译法
这种翻译方法与直接翻译大相径庭,首先我们决定句子的语法结构,就像我们在学校里学到的一样。然后我们调整句子的整体结构,而不是单词。这一步可以帮助我们获得十分合理的单词顺序。至少理论上是这样的。
但是在实践中,这种系统依然依赖逐词的翻译和墨守成规的语言学家。一方面,它引入了简化的一般语法规则。但另一方面,词汇结构的数量与单个单词相比大幅度增加,从而导致翻译更加复杂。
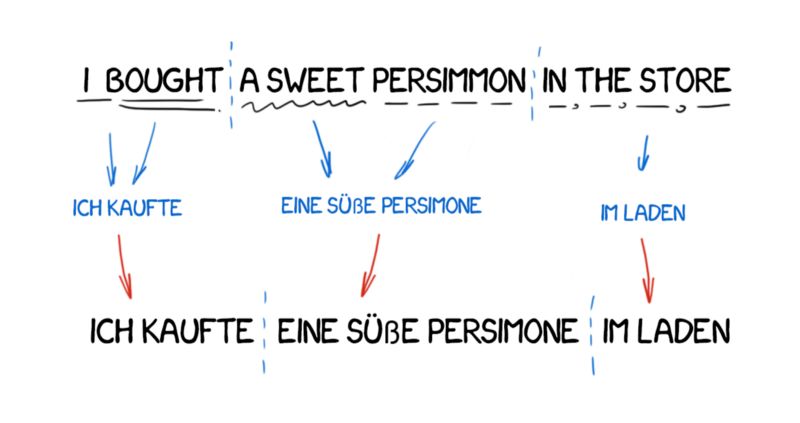
中间语言法
这个方法将源文本转变成全世界统一的一种中间语言(Interlingua)表达形式。这正是笛卡尔梦想的中间语言:一种元语言,遵循通用规则,并可以将翻译转化为简单的“来回”的任务。下一步,中间语言可以转换成任何目标语言,是不是很神奇?
因为都涉及转换,所以中间语言法通常与转换翻译法的系统相混淆。中间语言法的不同之处在于语言规则针对每种语言和中间语言,而与互译的语言对无关。这意味着我们可以在中间语言系统中添加第三种语言,并且可以在所有三种语言之间互相翻译。但是转换翻译法做不到这一点。
这个理论听起来似乎很完美,但是现实却并非如此。创建这样一种中间语言难度极其高,乃至很多科学家毕生都在为此而奋斗。虽然没有成功,但是他们的辛劳为我们带来了今天的形态、语法、以及语义等表现层次。仅仅是意义文本理论本身就需要耗费巨资!
中间语言法迟早会回来的,让我们翘首以待。
如你所见,所有的RBMT都很蠢笨和可怕,所以我们仅在特殊场合使用它们,比如天气预报翻译等等。人们经常提到的RBMT的优点包括它的精准的形态(不会给单词带来歧义)、可重复的结果(所有翻译器都可以得到相同的结果)、以及可以调节到特定主题的功能(比如教经济学家编程专用术语)。
即便有人成功地创建了理想的RBMT,并且语言学家用所有的拼写规则强化它,我们也总是会遇到一些例外:英语中的非规则动词,德语中可分离的前缀,俄语中的后缀,以及人们在表达的时候会有些许的差异。如果要解决这些所有的细微差别,将耗费巨大的人力。
还有同音异义词。相同的单词在不同的上下文环境里有不同的意思,这也会影响翻译的变化。看看下面这句话可以理解为几个意思:I saw a man on a hill with telescope? 比如可以翻译成:我看到山上有个男人拿着望远镜;也可以翻译成:我站在山上透过望远镜看到一个男人;还可以翻译成:我透过望远镜看到山上站着一个男人;此外saw还可以翻译成“锯”(动词)等等。
语言不是根据固定的一套规则发展而来的,尽管语言学家很喜欢规则。过去的300年中,语言在很大程度上受到了侵略史的影响。你又如何向一台机器解释呢?
40年的冷战未能帮助我们找到最终的解决方案。
RBMT已死。
二、基于实例的机器翻译
(Example-BasedMachine Translation:EBMT)
日本尤其对机器翻译感兴趣。日本虽没有冷战,但是当时懂英语的日本人很少。这对于即将到来的全球化是个很大的问题,所以日本人非常有动力,想要找到机器翻译的方法。
基于规则的英译日非常复杂。日语的语法结构完全不同,所有的单词必须重新排列,并追加新单词。
1984年京都大学的长尾真提出“使用准备好的短语代替重复翻译”的想法。
想象一下,如果要翻译一个简单的句子:“I’m going to the cinema。” 如果已经翻译过另外一个类似的句子:“I’m going to the theater”,而且可以从词典中找到“cinema”这个单词。
那么所要做的是找出两个句子的不同之处,然后翻译这个有差异的单词,但不要破坏句子的结构。拥有的例子越多,翻译效果越佳。
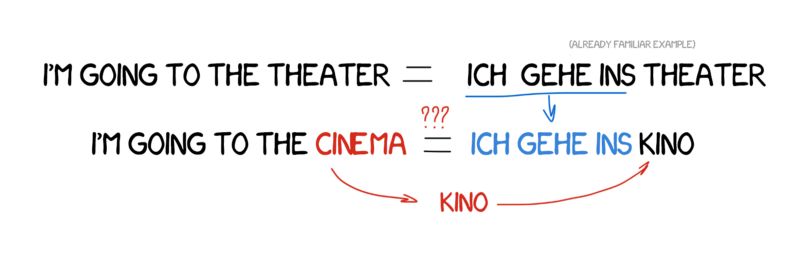
我可以用同样的方法写出了完全不懂的另一种语言的句子。
EBMT的方法给全世界的科学家带来了一丝曙光:事实证明,可以通过向机器输入已有的翻译实现机器翻译,而无需花费多年的时间建立规则和例外。这个方法虽然不算是一次彻底的变革,但显然是向前迈进了一大步。仅在5年后,革命性的发明——统计型机器翻译出现了。
三、统计型机器翻译系统
(StatisticalMachine Translation:SMT)
在1990年早期,IBM研究中心的一台机器翻译系统首次问世。它并不了解整体的规则和语言学,而是分析两种语言中的相似文本,并试图理解其中的模式。
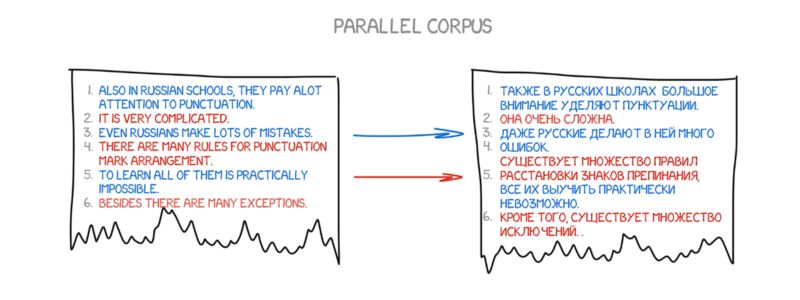
这个想法很简单却很出色。相同的一个句子用两种语言分割成单词,然后相互匹配。将这种操作重复大约5亿次,并对每个单词的匹配结果进行计数,如统计单词“Das Haus”被翻译成“house”、“building”、“construction”的次数。
如果大多数时候被翻译成了“house”,那么机器就会采用这个翻译。请注意我们并没有设置任何规则,也没有用到任何词典,所有的结论都是机器根据统计以及“如果大家这么翻译,那我也这么翻译”的逻辑得出的 。于是统计型机器翻译诞生了。
这种方法比之前的方法更高效且准确,而且还不需要语言学家。使用的文本越多,翻译效果就越佳。
图:Google的统计翻译内幕,会统计概率,也会反向统计
但这个方法还有一个问题:机器如何或什么时候才会将单词“Das Haus”与单词“building”关联到一起?而我们又如何知道这是正确的翻译呢?
答案是我们并不知道。最初,机器假定单词“Das Haus”与翻译后的句子中的其他词的关联性都相同。接下来,当“DasHaus”出现在别的句子里,与“house”一词的关联性就会+1。这就是大学机器学习中的经典任务:“单词对齐算法”。
这种机器需要两种语言提供数百万的句子,以便收集每个单词的相关性统计数据。那我们怎样才能拿到这些数据呢?我们从欧洲国会以及联合国安理会会议(他们提供所有成员国的语言翻译,你可以点击这里下载:https://catalog.ldc.upenn.edu/LDC2013T06,http://www.statmt.org/europarl/)截取了一部分。
基于单词的SMT
最初,第一个统计性翻译系统将句子分割成单词,因为这种方法最直观且最有逻辑性。IBM的首个统计性翻译模型称之为Model 1。听起来很高雅,是不是?猜猜看他们会如何命名第二个系统呢?
Model1:“词袋”
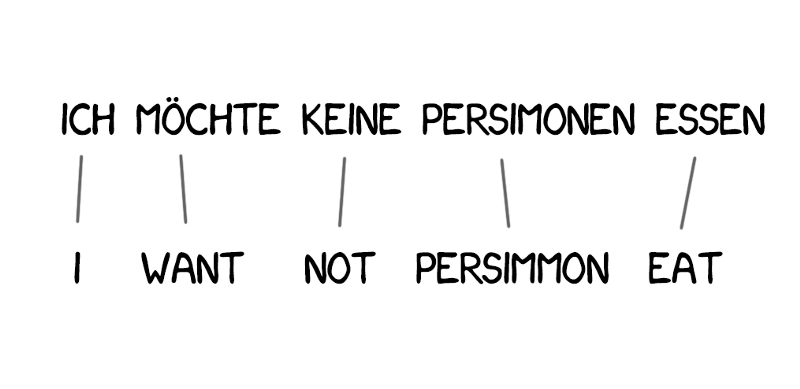
Model 1使用了最经典的方式:将句子分割成单词,然后计数统计。其中并没有考虑单词的顺序。最棘手的问题在于有时可以将多个字(或词)翻译成一个字(或词)。例如,“吃饭”可以翻译成“eat”,但这并不意味着反之亦然(“eat”只能翻译成“吃”)。
点击这里查看用Python实现的几个简单例子:https://github.com/shawa/IBM-Model-1
Model2:在句子中考虑单词的顺序
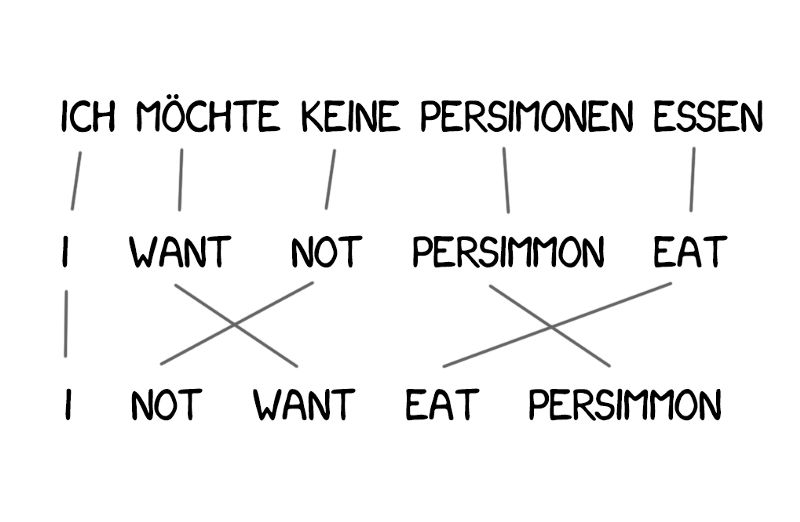
Model 1的问题在于缺乏对单词顺序的理解,并且在有些场合这是十分重要的问题。
Model 2解决了这个问题:它记住了单词在输出句子中通常所处的位置,并在中间步骤重新排列单词,让句子听上去更加自然。情况有所好转,但是最后的翻译结果依然有点蹩脚。
Model3:额外的处理
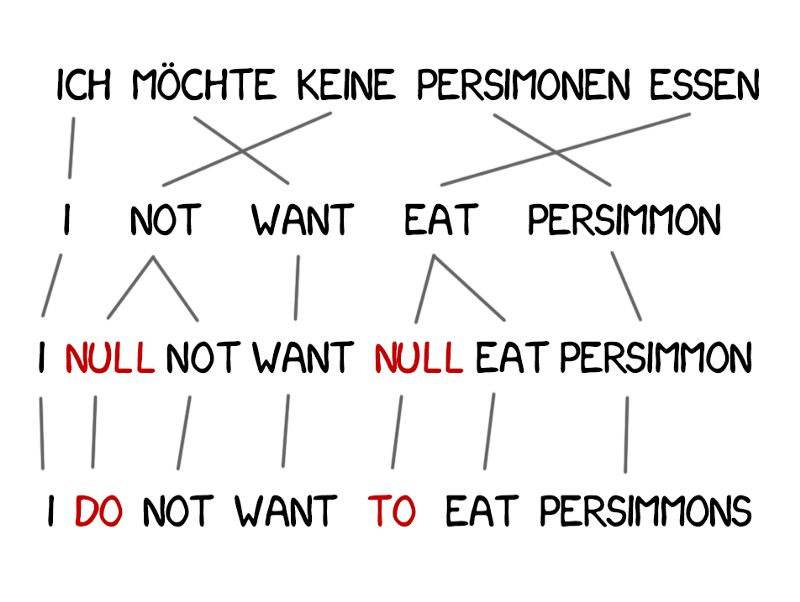
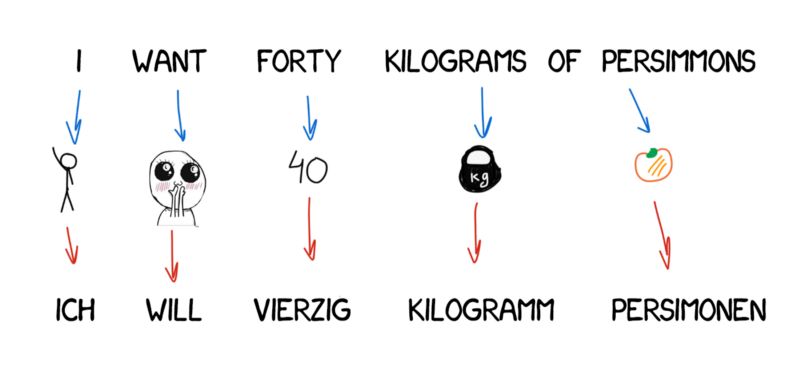
有些单词在翻译中出现得非常频繁,例如德语中的冠词或英语否定句中的“do”。“Ich will keine Persimonen” → “I do notwant Persimmons.” 为了处理这种情况,需要向Model 3中增加额外的两步。
Model4:单词对齐
Model 2也考虑了单词的对齐,但是却不懂得重新排序。举例来说,形容词通常都需要与名词交换位置,并且不管它记住了多好的顺序,都无法改善输出的结果。因此,Model 4引入了被人称之为“相对顺序”的概念,即该模型学习了两个单词是否经常互换位置。
Model5:修正bug
Model 5在功能上没有创新,只是为学习增加了更多参数,并修正了单词位置冲突的问题。
尽管基于单词的系统为机器翻译带来了革命性的创新,但是它们依然无法处理大小写、性别以及同音异意词。每个单词都由机器进行单一的看似正确的方法进行翻译。如今我们已经看不到这样的系统了,他们已经被更先进的基于短语的方法所取代了。
基于短语的SMT
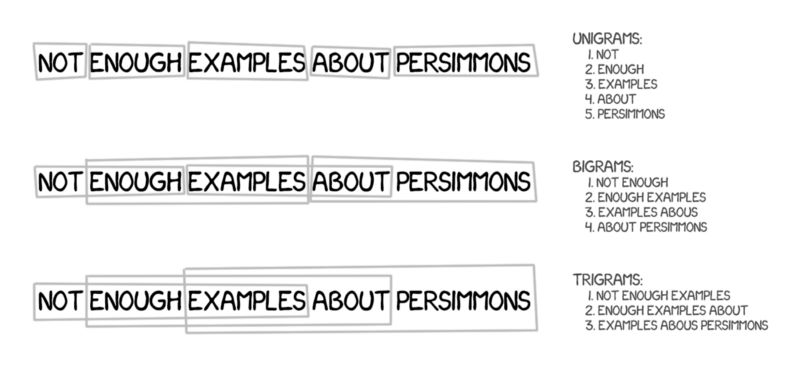
这个方法继承了所有基于单词的翻译原则:统计、重新排序以及词汇的修改。但是,这种方法将文本分解成短语,而非单词。这个方法是源于n元语法,即文本中连续出现的n个语词。
因此,机器学习翻译多个词出现的稳定组合,极大地提高了翻译的精度。
这个方法的难点在于:不是所有的短语都拥有如此简单的语法结构,如果有人懂得语言学以及句子的结构,对其进行干涉,那么翻译的质量会大幅下降。计算机语言学的大师,Frederick Jelinek开玩笑说:“每当我炒掉一个语言学家,演讲翻译机的性能就会有所提升。”
除了精度的提高,这种基于短语的翻译还为双语文本的学习提供了更多方式与途径。对于基于单词的翻译,元文本的精确匹配非常关键,所以任何文学或免费的翻译都被排斥在外。而基于短语的翻译没有这样的问题。为了提高翻译,研究人员甚至为此尝试解析不同的语言新闻网站。
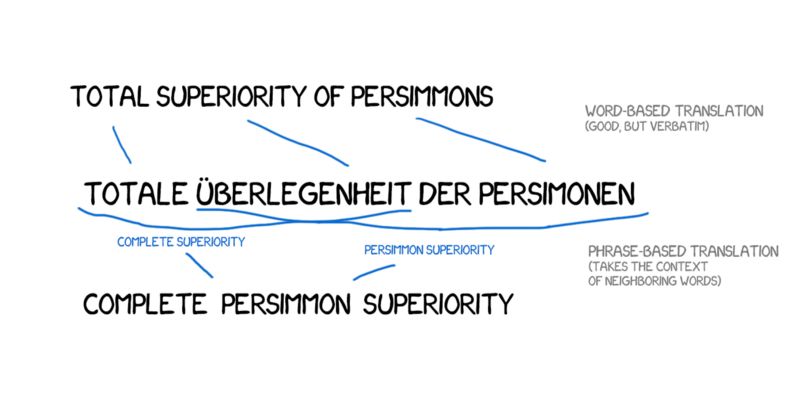
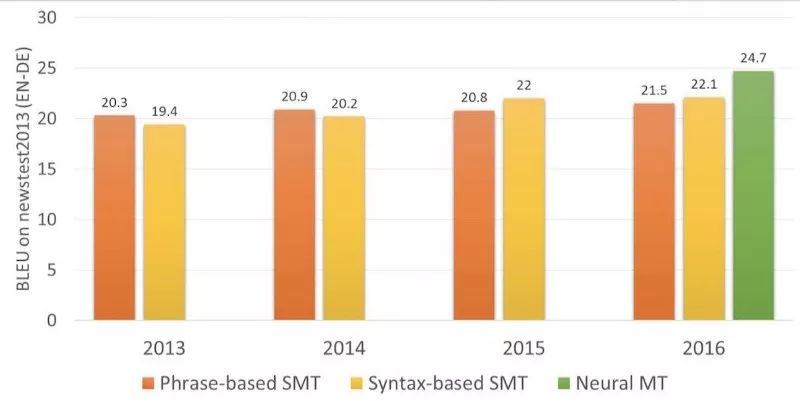
2006年起,所有人都开始用这种方法。截止到2016年,市场上涌现了Google翻译、Yandex(一家俄罗斯互联网企业,旗下的搜索引擎在俄国内拥有逾60%的市场占有率)、Bing(一款由微软公司推出的网络搜索引擎)、以及其他基于短语的高端在线翻译。可能有人记得当时有一段时间,Google的翻译时而呈现完美的句子翻译,时而翻译得狗屁不通。那些完全讲不通的翻译就来自基于短语的翻译。
旧时的基于规则的方法可以稳定地提供可预测却很糟糕的结果。而统计方法令人惊讶却又很神秘莫测。Google翻译毫不犹豫地将“three hundred”翻译成“300”。这就是所谓的统计偏差。
基于短语的翻译变得非常流行,所以现在人们说“统计方式的机器翻译”实际上指的就是基于短语的翻译。直到2016年,所有研究均称赞以基于短语的翻译是最先进的翻译。但是却没人想到Google已经点燃了导火索,准备改变我们对机器翻译的整体理解了。
基于语法的SMT
需要简单介绍下这个方法。在神经网络出现之前的很多年,基于语法的翻译被看作是“机器翻译的未来”,但是这个想法却未能成真。
基于语法的翻译的支持者认为,可以尝试将其与基于规则的方法合并。有必要对句子进行非常精确的语法分析——确定主语、谓语以及其他部分,然后创建句子树形结构。通过这个树形结构,机器可以学习在语言之间进行语法单元的转换,并通过但与或短语翻译其余部分。这将彻底解决单词对齐的问题。
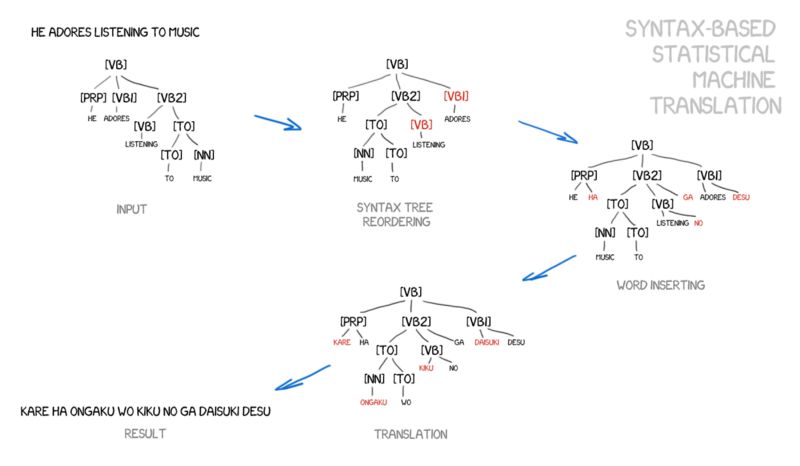
图:从Yamada与Knight的论文及幻灯片中摘取的例子
但是问题在于,语法分析的进行非常糟糕,尽管我们以为它在很早以前就得到了解决(因为我们有很多现成的语言库)。我尝试用语法树来解决比解析主语和谓语更复杂的问题时,每次都以失败告终。
四、神经网络机器翻译
(NeuralMachine Translation:NMT)
2014年出现了一篇非常有趣(https://arxiv.org/abs/1406.1078)的关于将神经网络用于机器翻译的论文。互联网圈压根没注意到论文的发表,除了Google。于是,他们前赴后继地开始挖掘。两年之后,2016年11月,Google发表了一项颠覆性的声明。
这种翻译方法近似于图片的风格转换。还记得Prisma等应用吗?它们可以将图片转换成某位著名的艺术家风格。这并不是魔法。训练有素的神经网络可以识别艺术家的作品。然后,将神经网络中最后的一层决策层删除。由此输出的经过处理的图片只是神经网络获得的中间图片。这正是该网络的强大之处,通过这种方法处理的图片很美。
既然我们可以对图片进行风格上的转换,那么如果我们尝试用另一种语言处理原文呢?原文相当于“艺术家的风格”,而我们需要将它进行转换,同时保证图片的本质,也就是文本的本质。
例如,我这样描述我的狗狗——中等个头、尖尖的鼻子,短尾巴,经常叫。如果我给你一些狗狗的特征,并且描述得足够精确,你就可以画出来,尽管你从未见过我的狗狗。
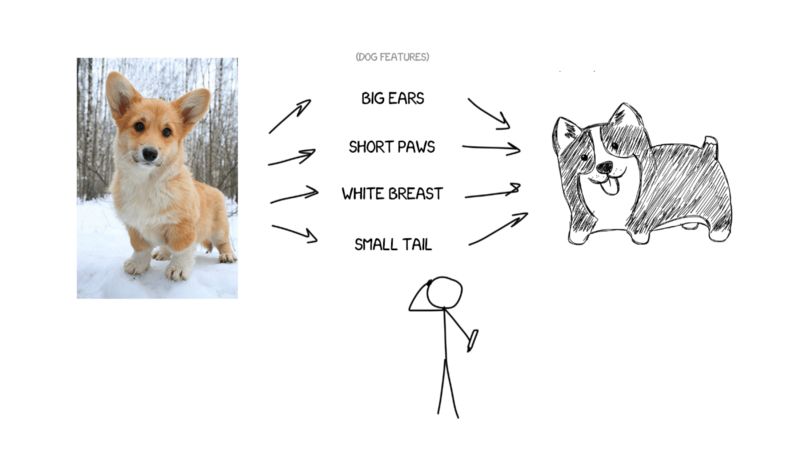
现在,假定原文是一组具体的特征。基本上,你可以将它进行编码,然后让其他神经网络通过解码将其还原成文本,但是要用另外一种语言。解码器只知道自己的语言,它并不知道原本的特征,但是它可以用西班牙语等其他语言进行表述。还是用画狗狗的比喻,怎样画出狗狗并不重要,无论你用蜡笔、水彩还是手指头,你可以用喜欢的方式画出来。
再说一遍:一个神经网络只负责将句子编码成具体的一套特征,而由另一个神经网络将这些特征解码还原回文本。两个神经网络之间并没有交流,它们只知道各自的语言。熟悉吗?中间语言回来了。鼓掌!
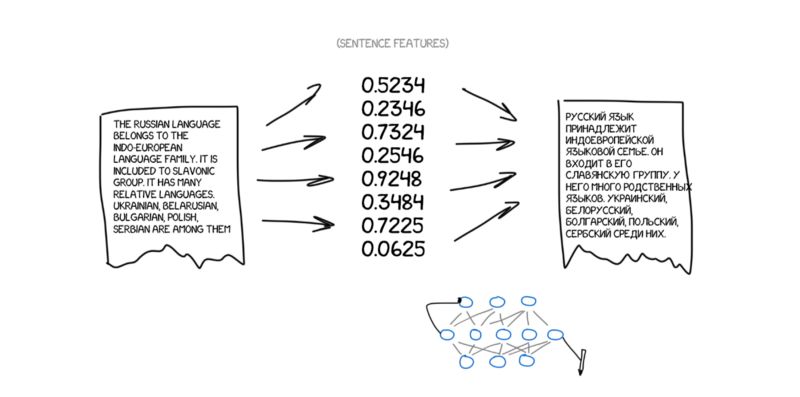
问题在于,我们怎样才能找到这些特征呢?狗狗的特征很明显,但是怎么处理文本呢?30年前科学家已经尝试创建国际语了,但是统统以失败告终。
然而,现在我们有了深度学习。而这正是它所擅长的。深度学习与传统的神经网络的主要区别在于,深度学习可以搜索那些特定的特征,而不需要了解其特性。如果神经网络足够大,且装备了几千个显卡,那么它可以在文本中找到那些特征。
从理论上讲,我们可以将从神经网络上得到的特征发给语言学家,让他们为自己开启勇敢的新视野。
问题是,什么类型的神经网络可以用于编码和解码呢?卷积神经网络(CNN)非常适合图片处理,因为它们使用独立的像素块。
但是文本中没有独立的块,每个单词都依赖于上下文环境。文本、语音和音乐的情况一样。因此,回归神经网络(RNN)是最佳选择,因为该网络可以记住之前的结果,对文本来说即为之前的单词。
目前RNN广泛地用于各处,比如Siri的语音识别(它可以解析声音的顺序,下一个取决于前一个)、键盘的提示(记住之前的输入,猜测下一个)、音乐的生成、乃至聊天机器人。
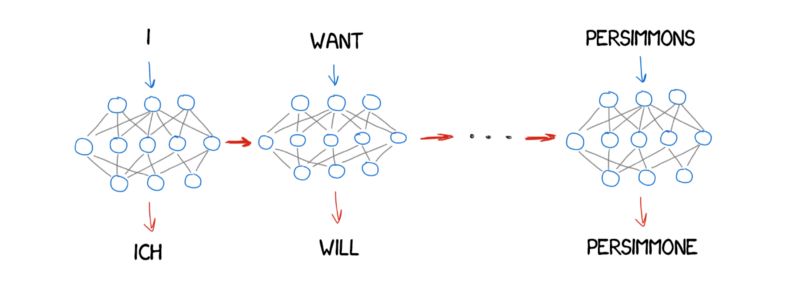
与我一样的人请看过来:实际上,神经网络翻译的体系结构差异很大。
最初大家使用常规的RNN,后来升级到双向的RNN,该机器翻译不仅考虑之前的单词,还考虑下一个单词。这样可以很大地提高效率。接下来是带有LSTM单元的核心多层RNN,以便长期存储翻译的上下文。
最近两年来,神经网络翻译已经超越了过去20年所有的翻译方式。神经网络翻译的单词顺序错误降低了50%,词汇错误降低了17%,语法错误降低了19%。神经网络甚至学会了用不同的语言来调整性别与大小写。且没有人教它们这样做。
在那些直接翻译法从未触及的领域,神经网络翻译带来了巨大的进步。统计方式的机器翻译常常将英语作为主要语言。因此在将俄语翻译成德语时,机器首先需要将文本翻译成英语,再将英语翻译成德语,这期间会造成双重的损失。
神经网络翻译不需要经过英语,它只需要一个解码器。从而首次实现了没有词典可查的语言间的翻译。
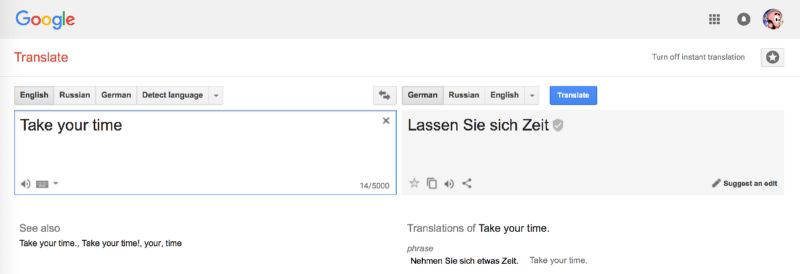
Google翻译(始于2016年)
2016年,Google通过神经网络翻译提供9国语言的互译。他们开发的系统名为Google神经网络翻译系统(Google Neural Machine Translation:GNMT)。其中RNN层包含了8个编码器和解码器,并与解码器网络进行连接。
他们不仅划分句子,还划分单词。通过这个方法他们解决了NMT主要难题之一:稀有词。当无法在词典中找到某个单词比如“Vas3k”时,NMT就无法处理。我很怀疑是否有人教会了神经网络翻译我的昵称。这种情况下,GMNT会将待翻译的文本分割成单词,然后进行翻译。很聪明,是不是?
提示:在浏览器中进行网站翻译时,Google翻译仍然使用旧的基于短语的算法。不知何故,Google并没有对其进行升级,与在线翻译相比,差异相当明显。
Google的在线翻译使用众包机制。用户可以选择他们认为最正确的版本,并且如果很多用户喜欢一种翻译,那么Google会沿用这个短语的翻译,并给其注上一个特殊的标记。这种方式对于日常短语非常有效,比如,“Let’s go to the cinema”或“I’m waiting foryou.”,Google的英语口语比我好。
微软的Bing采用与Google翻译同样的方式。但是Yandex却有所不同。
Yandex翻译(始于2017年)
Yandex在2017年发行了自己的神经网络翻译系统。据其所称,主要功能在于混杂性。Yandex在句子翻译中结合了神经网络与统计方式,然后由其最钟爱的CatBoost算法选择最佳的翻译结果。
原因在于,神经网络需要根据上下文选择合适的单词,因此在翻译短语时经常会失败。再比如,如果训练数据中一个单词出现的次数非常少,那么就很难翻译。在这些情况下,简单的统计翻译方式可以快速而简单地找到正确的词语。
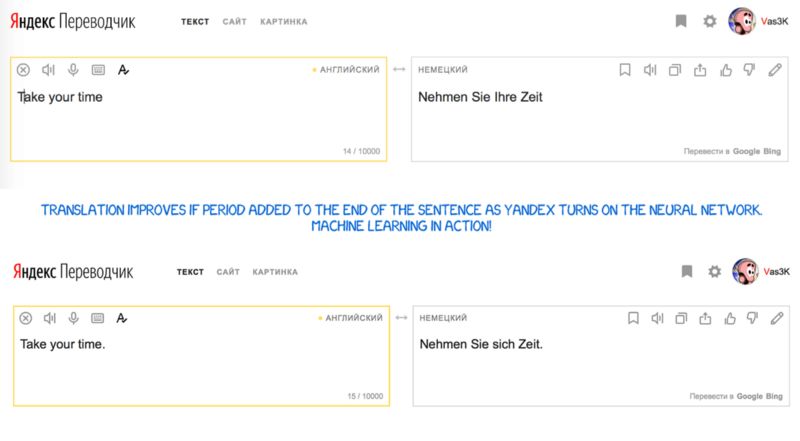
Yandex没有分享技术细节。但是它通过营销新闻稿吸引了我们:https://yandex.com/company/blog/one-model-is-better-than-two-yu-yandex-translate-launches-a-hybrid-machine-translation-system/
看起来Google在翻译词语和短语时使用了SMT。他们没有在任何文章中提过这一点,但仔细观察下短语和长句的翻译结果就能注意到。而且,在显示词频统计时也会使用SMT。
总结与将来
每个人都对“Babel fish”(一款由雅虎公司提供的在线免费翻译软件,包括即时的语音翻译)这个想法非常感兴趣。Google已经通过Pixel Buds向前迈进了一大步,但事实上,它仍然不足以满足我们梦寐以求的翻译。即时语音翻译与普通的翻译有所不同。你需要知道什么时候开始翻译,而什么需要安静倾听。我还没有看到合适的方案可以解决这个问题。除非,或许,Skype可以……
机器翻译还有一块空白区域:所有的机器学习仅限于一组并列的文本块,即源语言和目标语言之间,一句话一句话需要对应起来。最深的神经网络也仍然在并列的文本中学习。没有资源,我们无法训练神经网络。相反,人们可以通过阅读数据或文章来补充他们的词汇量,即便没有将这些词翻译成母语。
从理论上来说,如果人们可以做到,神经网络也可以做到。我发现有一种原型(https://arxiv.org/abs/1710.04087)在尝试鼓励其已掌握一种语言的神经网络,用另外一种语言来阅读文本,从而获得这方面的经验。我自己也会做尝试,但是我不够聪明。好了,就到这里吧。
这个故事最初是用俄文写的,然后Vasily Zubarev在Vas3k.com上翻译成了英文。他是我的笔友,他的文章应该得到广泛流传。
参考链接:
Philipp Koehn的著作:Statistical Machine Translation。最完整的统计机器翻译方法的介绍。
Moses(http://www.statmt.org/moses/):统计机器翻译最流行的代码库。
-
OpenNMT(http://opennmt.net/):神经网络翻译最流行的代码库。
一篇我最喜欢的文章(http://colah.github.io/posts/2015-08-Understanding-LSTMs/):介绍RNN与LSTM。
一个视频短片(https://www.youtube.com/watch?v=nRBnh4qbPHI):介绍如何创建机器翻译。很有意思的小伙子,讲解很清晰,但是内容不够充实。
TensorFlow提供的指南(https://www.tensorflow.org/tutorials/seq2seq):提供了更多实例。
原文:https://medium.freecodecamp.org/a-history-of-machine-translation-from-the-cold-war-to-deep-learning-f1d335ce8b5
作者:IlyaPestov
译者:马晶慧
责编:琥珀
————— 推荐阅读 —————
点击图片即可阅读
















