

在我们爬取网页过程中,经常发现我们想要获得的数据并不能简单的通过解析HTML代码获取,这些数据是通过AJAX异步加载方式或经过JS渲染后才呈现在页面上显示出来。
selenuim是一种自动化测试工具,它支持多种浏览器。而在爬虫中,我们可以使用它来模拟浏览器浏览页面,进而解决JavaScript渲染的问题。
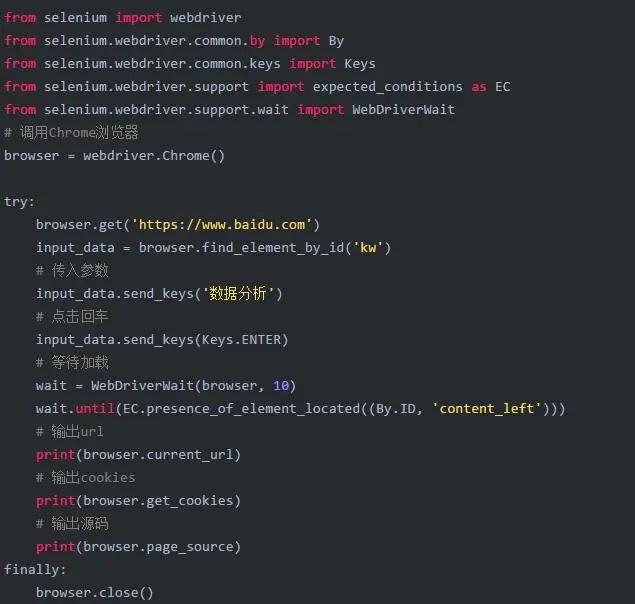
1. 使用示例
2. 详细介绍
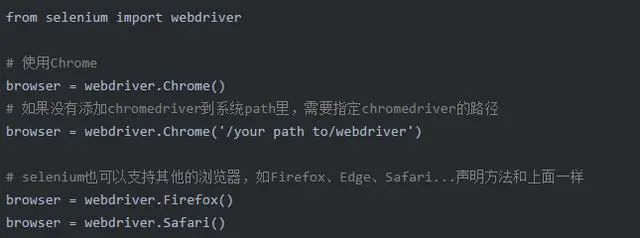
2.1 声明浏览器对象
即告诉程序,应该使用哪个浏览器进行操作
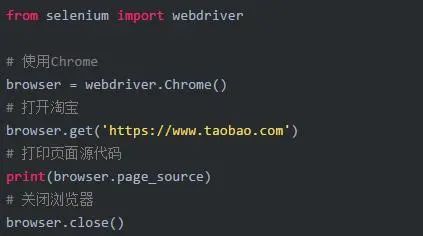
2.2 访问页面
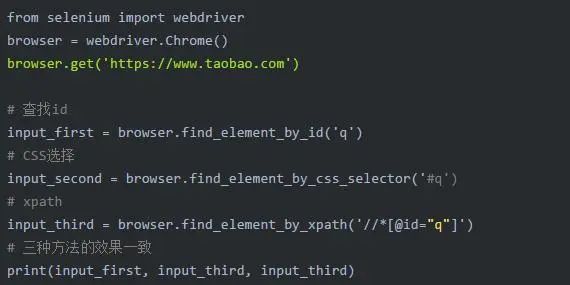
2.3 查找元素
成功访问网页后,我们可能需要进行一些操作,比如找到搜索框然后输入关键字再敲击回车键。
因此,就需要在selenium中查找元素。
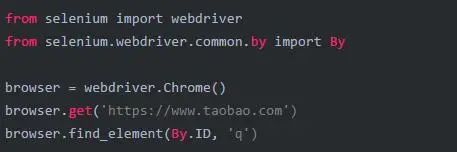
2.3.1 单个元素
selenium查找元素有两种方法。
第一种,是指定使用哪种方法去查找元素,比如指定依照CSS选择或者依照xpath去进行查找
下面是详细的元素查找方法
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
第二种,是直接使用find_element(),传入的第一个参数为需要使用的元素查找方法
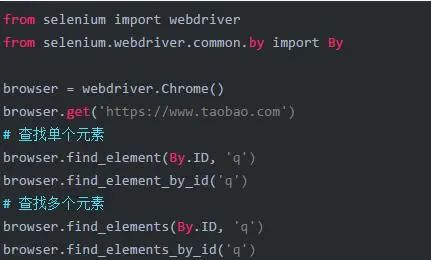
2.3.2 多个元素
查找多个元素和查找单个元素的方法基本一致(只需要将查找单个元素的func里加一个s)。
查找多个元素返回的是一个list。
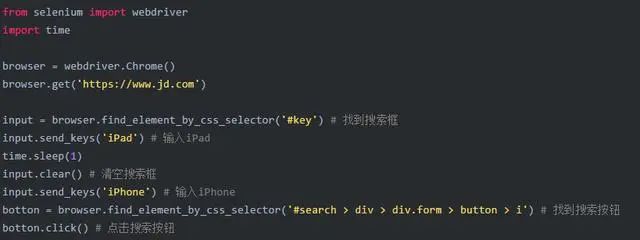
2.4 元素交互操作
元素交互是先获取一个元素,然后对获取的元素调用交互方法。
比如说在搜索框内输入文字:
2.5 交互动作
交互动作是将动作附加到交互链中串行执行,需要使用到ActionChains。
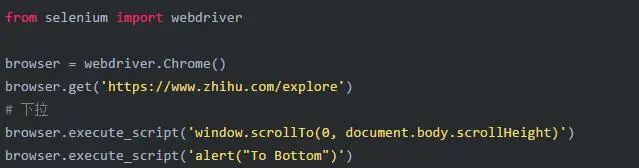
2.6 执行JavaScript
比如拖拽下拉
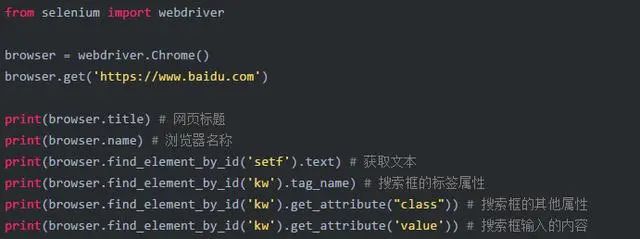
2.7 获取元素信息
已经通过元素查找获取到元素后,可能还需要获取这个元素的属性、文本
2.7.1 获取属性
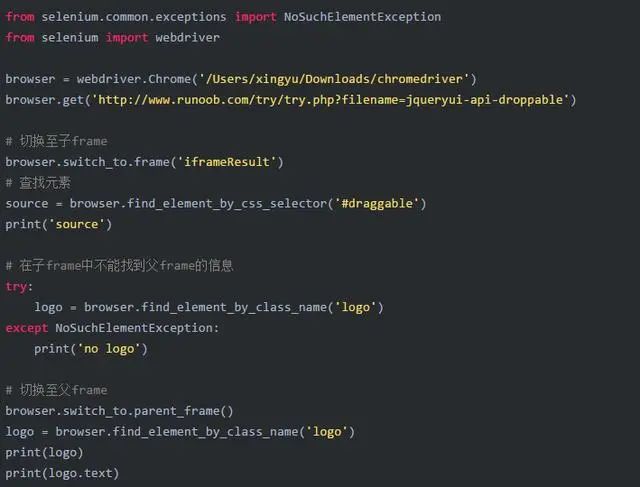
2.8 Frame
如果定位到父frame,是无法查找到子frame的信息的,因此需要切换到子frame再进行查找。同理,在子frame也无法查找到父frame的信息
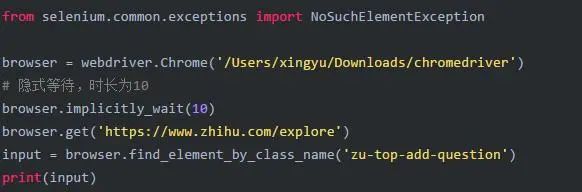
2.9 等待
请求网页时,可能会存在AJAX异步加载的情况。而selenium只会加载主网页,并不会考虑到AJAX的情况。因此,使用时需要等待一些时间,让网页加载完全后再进行操作。
2.9.1 隐式等待
使用隐式等待时,如果webdriver没有找到指定的元素,将继续等待。超出规定时间后,如果还是没又找到指定元素则抛出找不到元素的异常。默认等待时间为0。
隐式等待是对整个页面进行等待。
需要特别说明的是:隐性等待对整个driver的周期都起作用,所以只要设置一次即可。
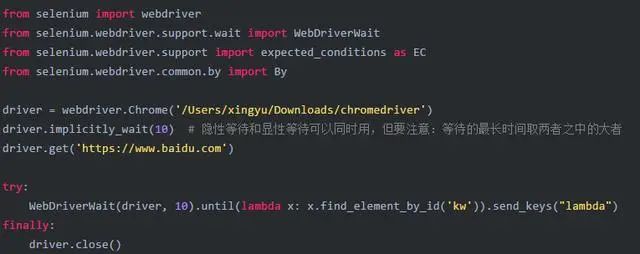
2.9.2 显式等待
显示等待包含了等待条件和等待时间。
首先判定等待条件是否成立,如果成立,则直接返回;如果条件不成立,则等待最长时间为等待时间,如果超过等待时间后仍然没有满足等待等待条件,则抛出异常。
显式等待是对指定的元素进行等待。
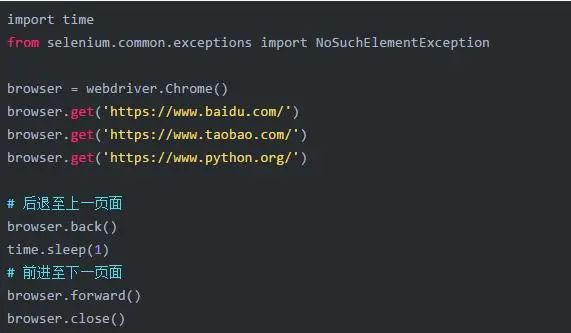
2.10 浏览器的前进/后退
back实现回到前一页面,forward实现前往下一页面
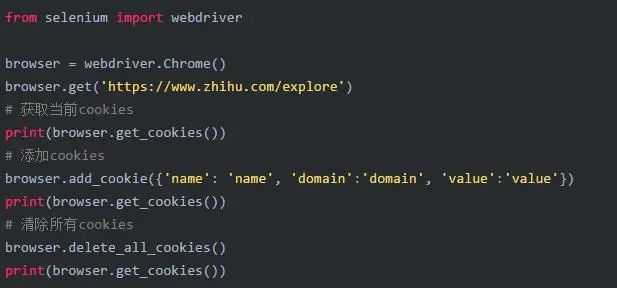
2.11 对Cookies进行操作
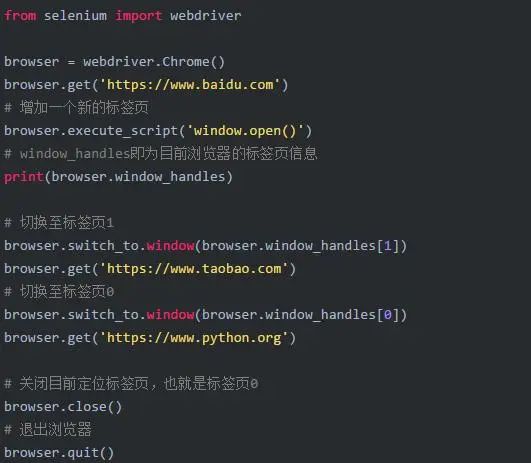
2.12 选项卡管理
选项卡管理就是浏览器的标签。有些时候我们需要在浏览器里增加一个新标签页或者删除一个标签页,就可以使用selenium来实现。
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
觉得不错,点个“在看”然后转发出去










