导读
这是一篇关于度量学习损失函数的综述。
检索网络对于搜索和索引是必不可少的。深度学习利用各种排名损失来学习一个对象的嵌入 —— 来自同一类的对象的嵌入比来自不同类的对象的嵌入更接近。本文比较了各种著名的排名损失的公式和应用。
深度学习的检索正式的说法为度量学习(ML)。在这个学习范式中,神经网络学习一个嵌 入—— 比如一个128维的向量。这样的嵌入量化了不同对象之间的相似性,如下图所示。学习后的嵌入可以进行搜索、最近邻检索、索引等。
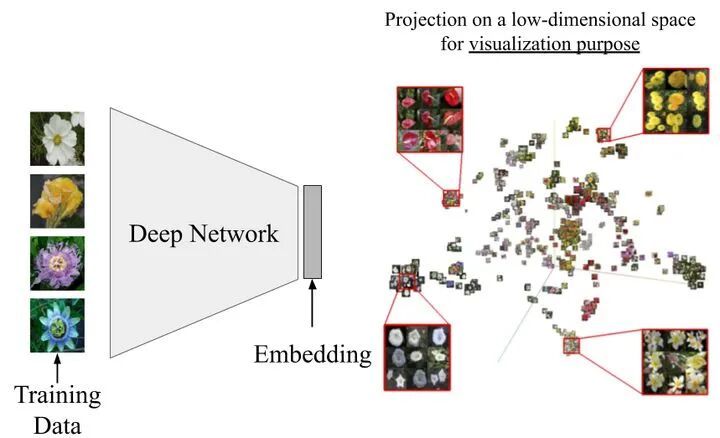
用排序损失训练的深度网络,使搜索和索引成为可能
这个综述比较了各种损失的公式和应用。综述分为两部分。第一部分对对比损失和三元组损失进行了对比。第二部分将介绍N-pairs损失和Angular损失。
对比损失
最古老,最简单的排序损失。这种损失使相似点和不同点之间的欧氏距离分别达到最小和最大。相似的点和不同的点被分成正样本对和负样本对。下图给出了它的公式,使用了一对点的嵌入(x_i,x_j)。当(x_i,x_j)嵌入属于同一个类时,y=0。在这种情况下,第一项使欧几里得距离D(x_i,x_j)最小,而第二项是无效的,即等于零。当嵌入项(x_i,x_j)属于不同类别时,y=1,第二项使点之间的距离最大,而第一项为零。第二项中的max(0,m-D)确保不同的嵌入间隔一定的距离,即有限的距离。在训练过程中,这一margin确保了神经网络的梯度忽略大量的远(容易)的负样本对,而利用稀缺的近(难)的负样本对。
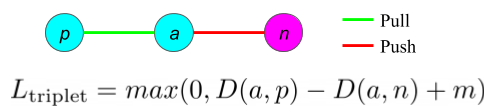 对比损失
对比损失尽管它很受欢迎,但在大多数检索任务(通常用作基线)中,这种对比性损失的表现很不起眼。大多数高级损失需要一个三元组(x_i,x_j,x_k),其中(x_i,x_j)属于同一类,(x_i,x_k)属于不同类。这种三元组样本在无监督学习中很难获得。因此,尽管对比损失在检索方面的表现不佳,但在无监督学习和自我监督学习文献中仍普遍使用。
三元组损失
最常见的排序损失是三元组损失。它解决了对比损失的一个重要限制。如果两个点是不同的,对比损失将两个点推向相反的方向。如果其中一个点已经位于集群的中心,那么这个解决方案就不是最优的。三元组损失使用三元组而不是样本对来解决这个限制。三元组(x_i,x_j,x_k)通常被称为(锚,正样本,负样本),即(a,p,n)。三元组损失将锚和正样本拉在一起,同时将锚和负样本推离彼此。
三元组损失与对比损失类似,三元组损失也用到了margin。_max_和margin _m_确保不同的点在距离>_m_的时候不会产生损失。在人脸识别、行人重识别和特征嵌入等检索应用中,三元组损失通常优于对比损失。然而,对比损失在无监督学习中仍然占主导地位。因为很难从未标记的数据中抽取有意义的三元组。三元组损失对噪声数据很敏感,因此随机负采样会影响其性能。
三元组损失的性能很大程度上依赖于三元组采样策略。因此,存在大量的三元组损失的变体。这些变体采用相同的三元组损失函数,但是具有不同的三元组抽样策略。在原始的三元组损失中,从训练数据集中随机抽取三元组样本。随机抽样的收敛速度很慢。因此,大量的论文已经研究了困难样本挖掘来寻找有用的三元组和加速收敛。接下来的段落比较了两种著名的困难样本挖掘策略:困难采样策略和半困难采样策略。
在这两种策略中,每个训练小批包含K*P个随机抽样的训练样本,每个样本来自K个类,每个类有P个样本。例如,如果训练批的大小是B=32和P=4,那么批将包含来自K=8个不同类的样本,每个类P=4个实例。现在,每个锚都有(P-1=3)可能的正样本实例和(K-1)*P=28个可能的负样本实例。
在困难采样中,只使用最远的正样本和最近的负样本。在下一个图中,n_3是锚a最近的负样本。因此,假设p是最远的正样本,损失将使用三元组(a,p,n_3)计算。这种策略的收敛速度更快,因为在训练过程中,它利用了最难的样本。然而,训练超参数(例如,学习率和批大小)需要仔细调整,以避免模式坍塌。当所有的嵌入都相同,即f(x)=0时,就会发生模式坍塌。
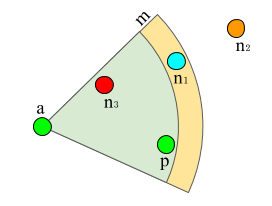 三元组损失元组(锚,正样本,负样本)和margin m,hard,semi-hard和easy的负样本分别用红色、青色和橙色突出显示
三元组损失元组(锚,正样本,负样本)和margin m,hard,semi-hard和easy的负样本分别用红色、青色和橙色突出显示为了避免困难样本的训练不稳定性,半困难将每个锚点与每个正样本点配对。在下一个图中,锚点(a)将与所有五个正样本配对。对于每一个正样本,将选择一个负样本,使其离正样本较远,但在禁止范围_m_内。因此,对(a, p_2)将利用橙色边框内的红色负样本。这种抽样策略对模型崩溃具有更强的鲁棒性,但收敛速度比困难样本挖掘策略慢。
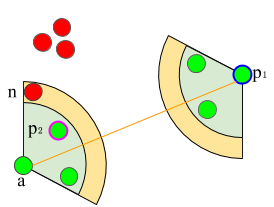 困难样本采样通过选择最远的正样本和最近的负样本(a, p1, n)来提升嵌入的能力。半困难样本采样选择(a, p2, n)并避免任何n位于a和p之间的元组(a, p, n)。
困难样本采样通过选择最远的正样本和最近的负样本(a, p1, n)来提升嵌入的能力。半困难样本采样选择(a, p2, n)并避免任何n位于a和p之间的元组(a, p, n)。三元组损失的采样策略在最近的文献中得到了大量的研究。需要一篇专门的文章来涵盖所有提出的变体。前面提到的两种策略都是Tensorflow库所支持的。大多数深度学习框架都提供了对比损失和三元组损失的api。
N-Pairs Loss
对比损失和三元组损失都利用欧氏距离来量化点之间的相似性。此外,训练小批中的每个锚点都与一个单个负样本配对。N-Pairs损失改变了这两个假设。首先,利用余弦相似度来量化点之间的相似度。因此,N-pairs损失使用两个向量之间的角度来比较嵌入,而不是范数。这并不是很大的变化,所以它的表达方式仍然类似于单个三元组(a,p,n)的三元组,如下所示: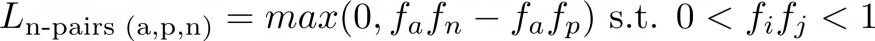
N-pairs的公式为单个三元组(a,p,n)使用余弦相似度。相同的嵌入的余弦相似性为1,不同的嵌入的余弦相似性为0。
但是,N-pairs损失的核心思想是为每个锚都配对一个正样本,同时配对所有的负样本。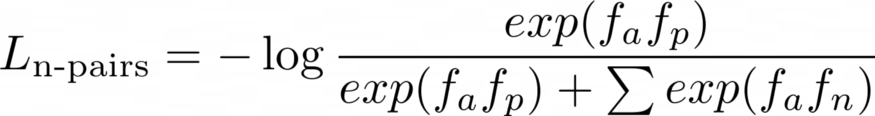
N-pairs公式将每个锚f_a与batch中的一个正样本f_p和所有的负样本f_n配对。
对于N-pairs,一个训练batch包含来自每个类的单个正样本对。因此,一个大小为B的batch将有B//2对正样本对,每个锚都与(B-2)个负样本配对,如下图所示。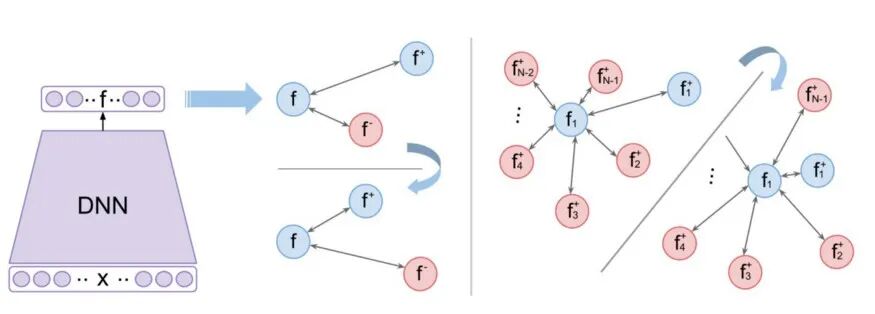
N-pairs的直觉是利用batch中的所有负样本来指导梯度更新,从而加速收敛。N-pairs损失通常优于三元组损失,而且没什么要注意的东西。训练batch的大小的上限是由训练类的数量决定的,因为每个类只允许有一个正样本对。相比之下,三元组损失和对比损失batch的大小仅受GPU内存的限制。此外,N-pairs损失学习了一个没有归一化的嵌入。这有两个结果:(1)不同类之间的边界是用角度来定义的,(2)可以避免退化的嵌入增长到无限大,一个正则化器,来约束嵌入空间,是必需的。
Angular Loss
Angular loss解决了三元组损失的两个限制。首先,三元组损失假设在不同类别之间有固定的margin m。固定的margin是不可取的,因为不同的类有不同的类内变化,如下图所示: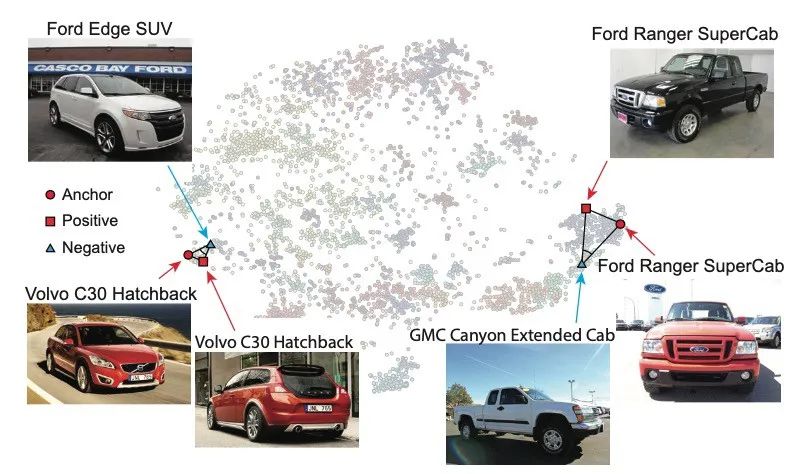
第二个限制是三元组损失是如何产生负样本的梯度的。下图显示了为什么负梯度的方向可能不是最佳的,也就是说,不能保证远离正样本的类中心。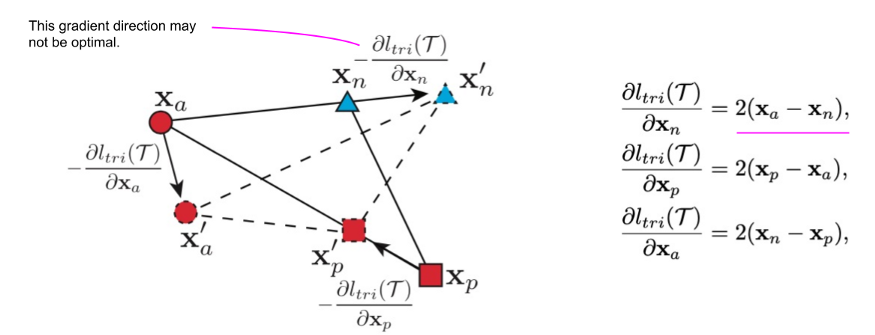
为了解决这两个限制,作者建议使用n的角度代替margin m,并在负样本点x_n处纠正梯度。不是基于距离把点往远处推,目标是最小化角度n,即,使三角形a-n-b在n点处的角度更小。下一个图说明angular loss的公式将负样本点x_n推离xc,xc为由x_a和x_p定义的局部簇的中心。另外,锚点x_a和正样本点x_p被彼此拖向对方。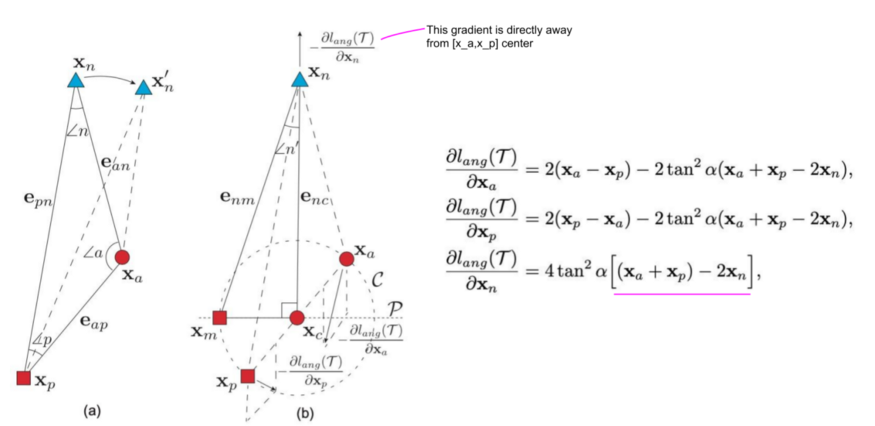
与原来的三元组损耗只依赖于两点(例如grad = x_a - x_n)相比, angular loss的梯度要稳健得多,因为它们同时考虑了所有三点。另外,请注意,与基于距离的度量相比,操纵角度n '不仅是旋转不变的,而且本质上也是尺度不变的。我的一些建议:N-pairs和Angular loss通常优于原始的三元组损失。然而,在比较这些方法时,需要考虑一些重要的参数。
- 用于训练三元组损失的采样策略会导致显著的性能差异。如果避免了模型崩溃,困难样本挖掘是有效的,并且收敛速度更快。
- 训练数据集的性质是另一个重要因素。当进行行人重识别或人脸聚类时,我们可以假设每个类由单个簇表示,即具有小的类内变化的单一模式。然而,一些检索数据集,如CUB-200-2011和Stanford Online Products有很多类内变化。根据经验,hard triplet loss在人/人脸再识别任务中工作得更好,而N-pairs和 Angular losses在CUB-200和Stanford Online Product数据集上工作得更好。
- 当使用一个新的检索任务和调整一个新的训练数据集的超参数(学习率和batch_size)时,我发现semi-hard三元组损失是最稳定的。它没有达到最好的性能,但它是最不可能退化的。
英文原文:https://ahmdtaha.medium.com/retrieval-with-deep-learning-a-ranking-loss-survey-part-2-
想要了解更多资讯,请扫描下方二维码,关注机器学习研究会

转自:极市平台








