
作者 | 刘早起
来源 | 早起Python
上个月电影《阿凡达》重新登陆中国院线,重映第二天,票房即破5090万人民币,全球票房突破27.98亿美元,重登全球影史票房冠军,一场十多年前的电影再次引发观影热潮。
阿凡达我一直没有看过,当时的我还在读高中,只知道有一部很牛的电影上映了,十年间阿凡达也频频被好友安利,我也去电影院去看了一下,电影途中总疑惑十年前的电影技术就有这么强了么,回来后忍不住用Python爬了点评论分析一波。
01
数据爬取
本文选择的数据为豆瓣网,关于 Python 爬取豆瓣电影的技术分析网上有非常多的案例,甚至很多读者朋友都是从「Python爬取豆瓣TOP250 电影」入坑爬虫的,下面就简单介绍,不做详细分析。
首先打开阿凡达对应的影评页面,可以看到该页的全部评论都在 class = review-list 的 div 标签中,并且每条评论都很整齐的在 20 个子 div 标签中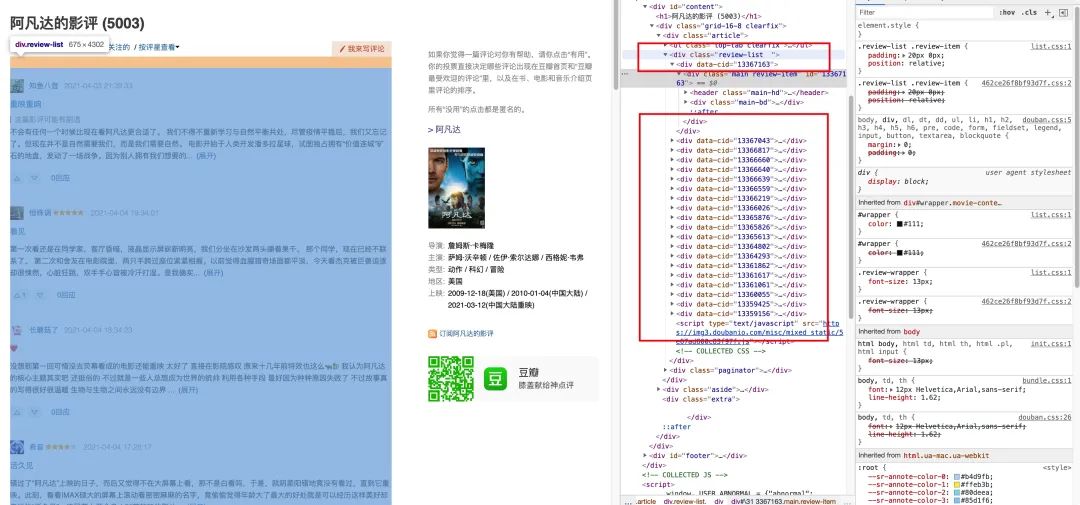
所以可以直接用 requests 构造请求+bs4 解析数据 +pandas 存储即可,相关代码如下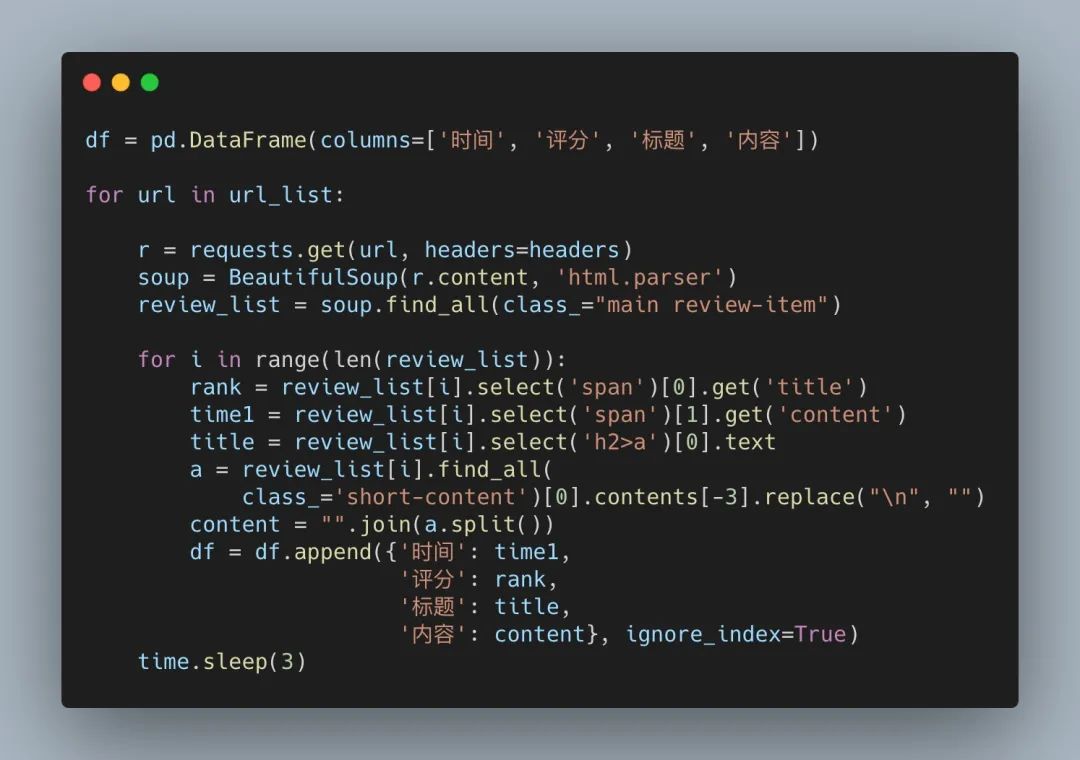
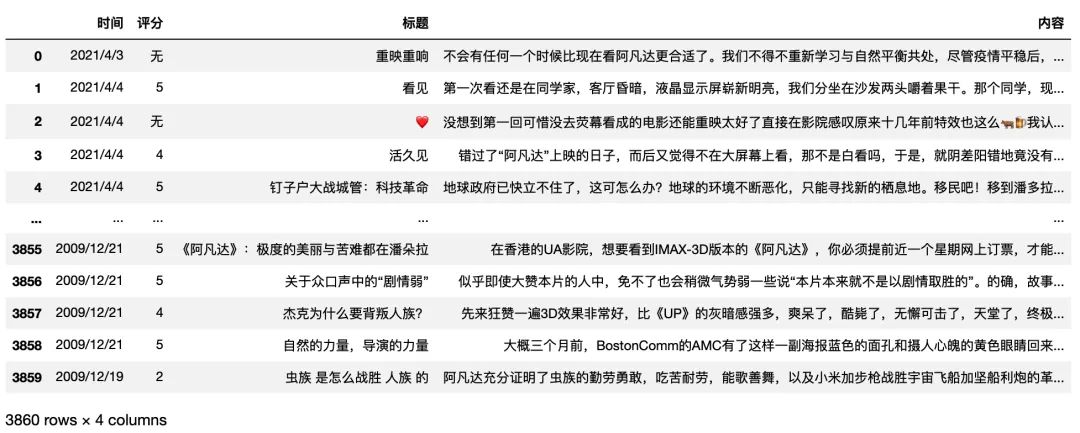
关于反爬,豆瓣好像一直没有什么特别复杂的反爬措施,控制频率并使用随机 ua+ 代理 ip 即可拿下大部分数据,可以看到一共取回了近 4000 条评论数据包含 「时间、评分、标题、内容」 四个字段
02
评星分析
先来看十年间阿凡达整体的评星分布,使用 matplotlib 对数据进行可视化如下
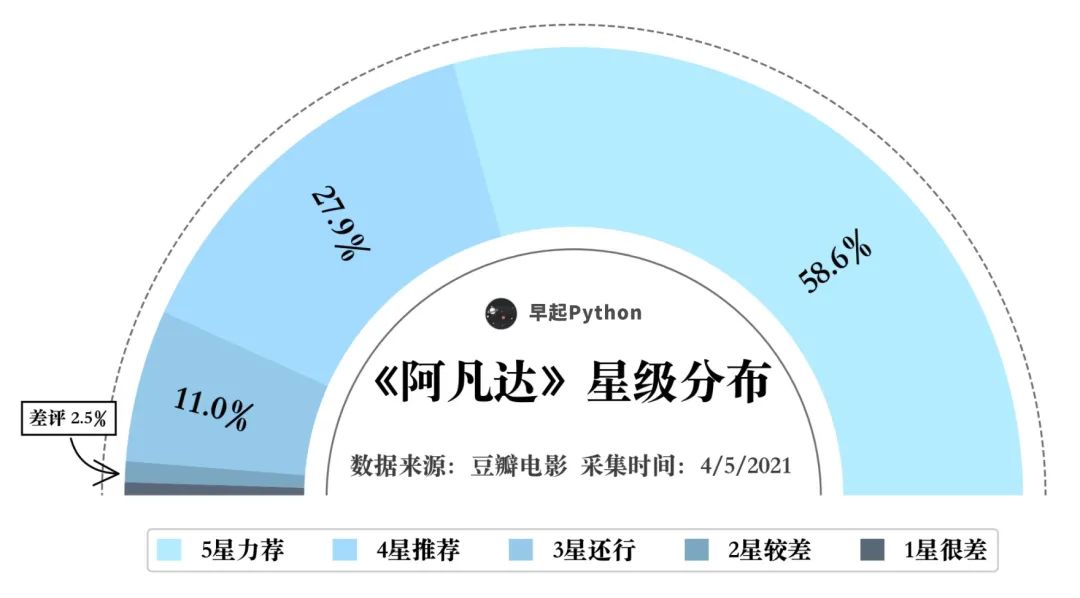
可以看到,五星好评的人数超过了一半,给出五星+四星的用户达到了 86.5%,而仅有 2.5% 的用户给到了差评。
那么除了豆瓣,阿凡达在其他平台表现怎么样?本文选取其他两家国内影视巨头猫眼、淘票票以及国外影评网站烂番茄、IMDB 的评分进行对比如下
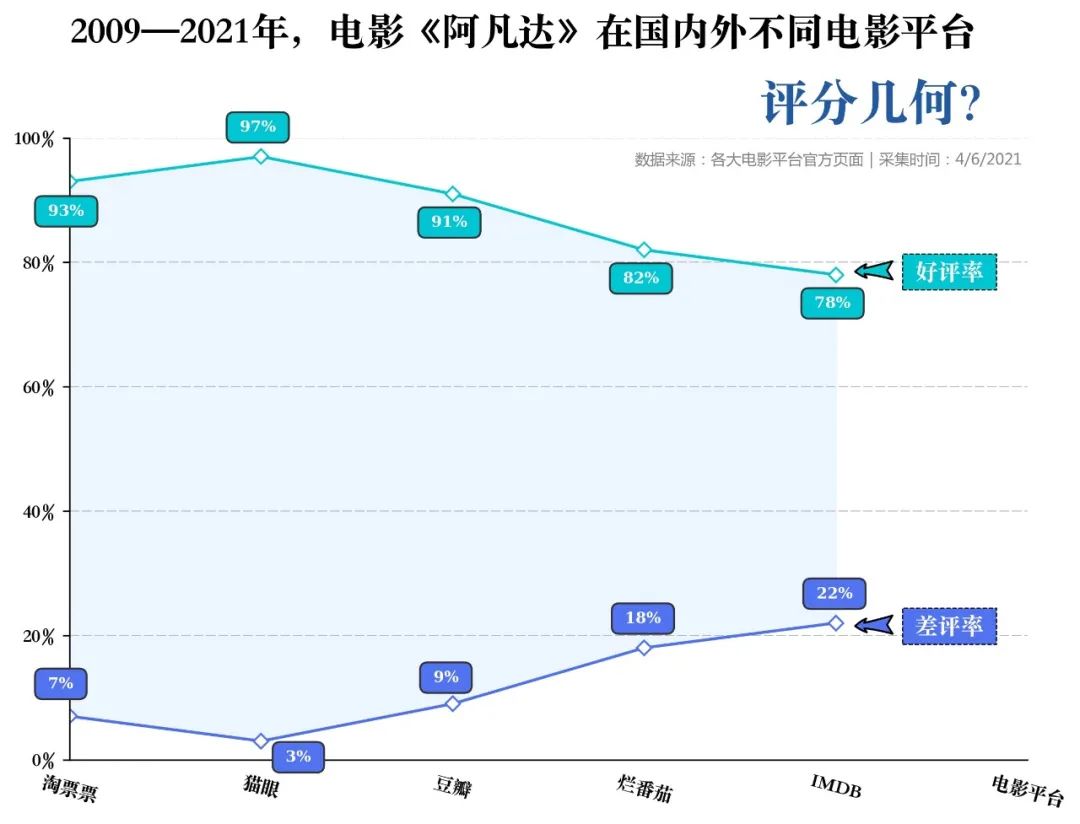
不难发现,阿凡达在国内的评分均高于国外平台,其中在淘票票给出好评的人数高达 97%(此处好评并非为电影主页显示的评分,而是在评价汇总中,根据给出好评的评价数量计算而来),而在 IMDB 网上仅得到 78% 的好评。
上面的分析是针对现有的全部数据得到,因为我们爬取的数据包含时间信息,下面对十年前后的打分进行对比
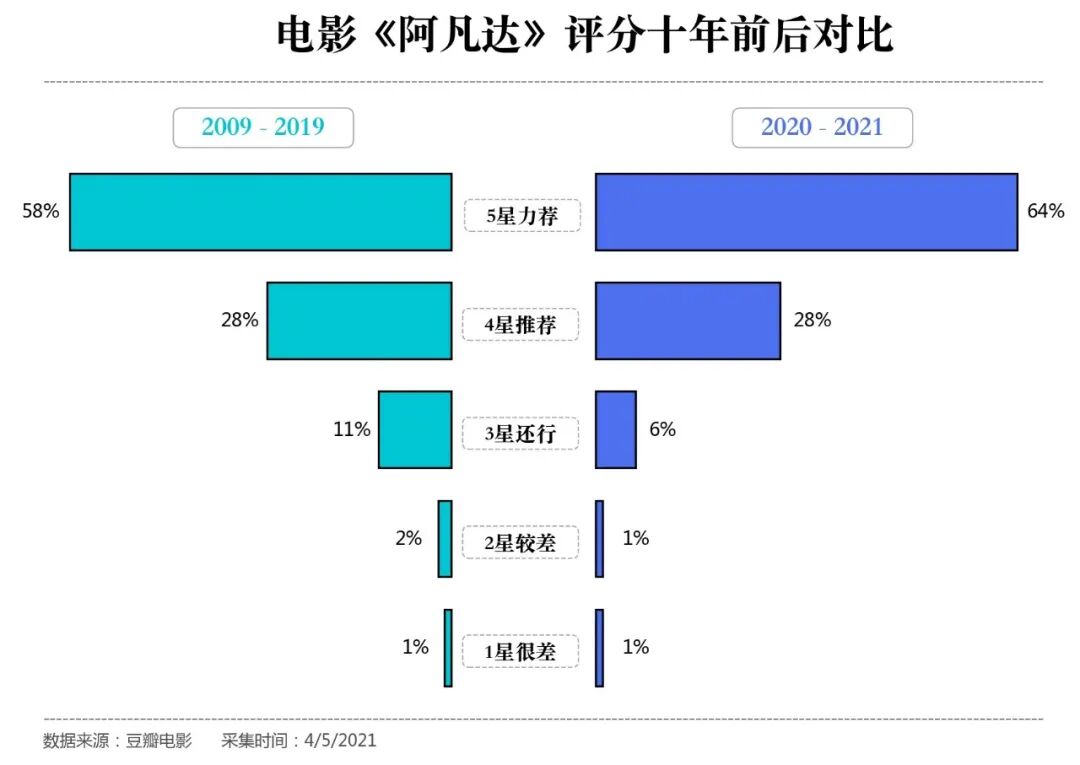
可以看到,最近一年来的好评比 2009—2019 十年间的比例要多,差评比例要少,果然十年之后,阿凡达依旧很能打,接下来让我们将目光放在具体的评论内容上。
03
内容分析
本节对具体的评论内容进行分析,主要是词频分析与词云制作,在 Python 中可以使用 jieba 进行分词,并使用 collections 对返回的分词结果进行统计,相关代码如下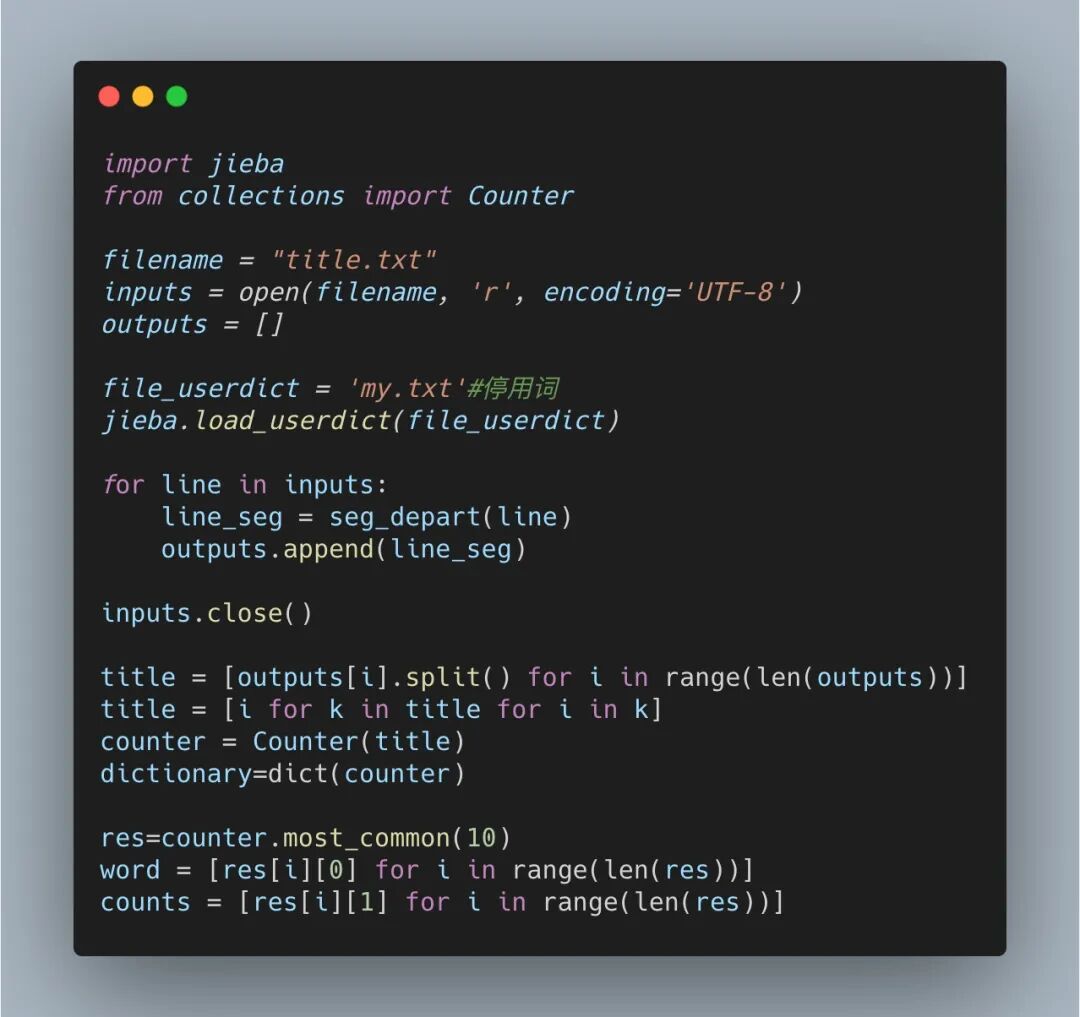
对标题内容进行词频分析得到标题中出现频率最高的十个词如下
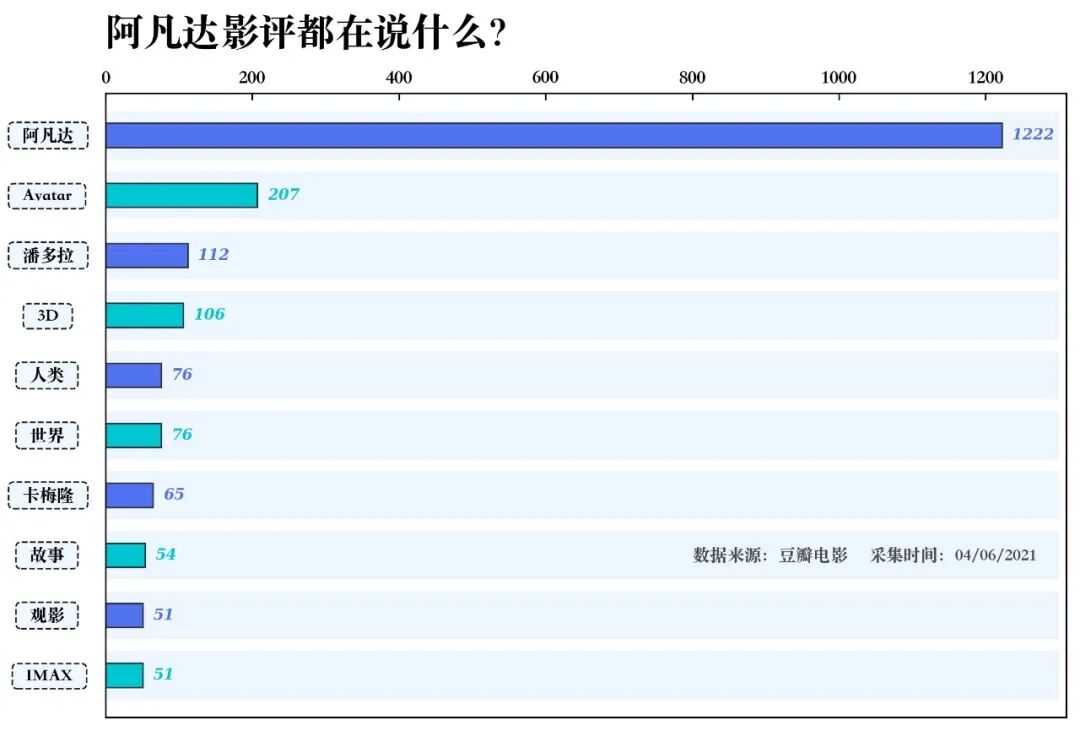
可以看到出现最多的词当然是主角阿凡达(TOP1)和 Avatar (TOP2),以及对应的 潘多拉星球(TOP3) ,其次有 3D(TOP4)、观影(TOP9)、IMAX (TOP10) 等观影体验上的单词频繁出现,还有 人类(TOP5)、世界(TOP6)、故事(TOP8) 等与剧情相关的吐槽,值得注意的是导演 卡梅隆(TOP7) 也被用户频频提起。
最后再将具体评论内容中根据好评(评分 4、5)和差评(评分 1、2)进行拆分,并制作词云图如下

可以看到,好评除了在说剧情外,大多与观影体验有关,比如特效、震撼等,而差评则聚焦于具体的主线故事,大多数差评用户在吐槽剧情、逻辑、文化等比直观的观影体验更深刻的思考。
本文的分享就到这里,不知道大家有没有看过阿凡达,是在十年前还是今年看的,是用电脑还是在影院看的,可以在留言区和我交流。










