背景
电子商务行业在近几年发展得极为迅猛,很多在传统行业就业但是薪资不理想的都在网电子商务行业去转。这种趋势造就了越来越多老百姓使用电子商务价值下的产品,不言而喻,比如网购等行为。换句话说,大量的网购会带来的结果就是数据量的增大。面对这种大数据,且时非结构化的数据如商品评论,怎么处理呢?怎么从中提取有用的信息呢?自然语言处理技术给出了答案,从规则提取到统计建模到如今非常火热的深度学习,都能从文本中提取到有用的商业价值,无论时为商家还是买家。本文就某电商平台上AirPods智能耳机产品的售卖情况及相关商品信息进行情感分析与快速词云图搭建。情感分析也是自然语言处理中的一个方向
除了对文本进行挖掘以外,本文还欲搭建一个网页APP。Python是目前比较流行的编程语言,利用Python搭建一个网页APP常用的是Python结合Flask或者Django框架来贯穿前后端来搭建网页。利用这个方法一般需要一定的前端经验,来修改CSS、HTML、JAVASCRIPT这些文件。而对于没有前端经验的coder,读者这里推荐一款友好的全程基于Python的库streamlit,也就是本文所用到的库。利用streamlit可以轻松快速的搭建一个网页APP,再加入文本挖掘功能。这样,就做出了一个小产品。下面,进入正题。
本文采用Anaconda进行Python编译,主要涉及的Python模块:
streamlit
pandas
cnsenti
stylecloud
time
本章分为三部分讲解:
1.数据探索性分析与商品评论文本提取
2.商品评论词云图可视化与情感分析
3.网页结构设计与实现
4.功能整合与效果呈现
本文采取的数据为某宁电商平台上的商品评论数据。数据字段有商品标题、价格、评价内容。其中,价格为近期4月份的实时价格。评价内容是按时间顺序从近到远的展现。下面为前五行的展示:
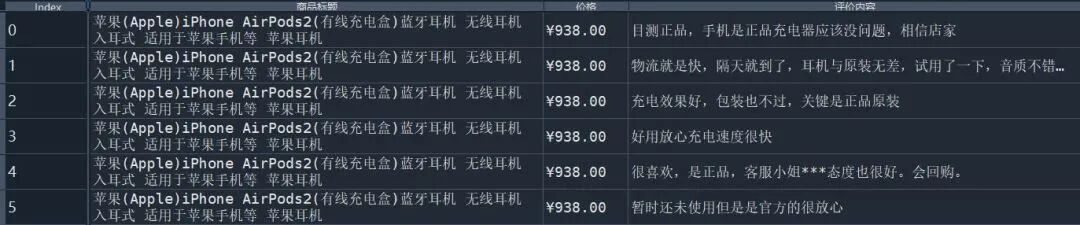
需要注意的是,上面五行显示的是AirPods第2代的商品信息。原因是数据原本分为3张表,每张表的字段都是一样的,总共3个,2个维度字段和1个度量字段(这个在CDA I课程中的数据结构会有提及)。因此,这份数据是3张表通过纵向合并方式对记录进行拼接。最后生成的Index是新表生成的主键。
接着可以对数据进行适当的探索性分析,首先习惯性的观察数据形状、数据类型以及有没有缺失值、异常值、重复值。缺失值利用pandas库的isnull().sum()函数即可查阅。重复值利用duplicated().sum()即可。而重复由于本文探索的是商品评论文本且数据量较少,因此本文忽略不做。下面为各部分结果
数据形状为(1020,3),这很好理解,就是1020条记录行,3个字段。数据类型利用info()函数即可,结果如下:
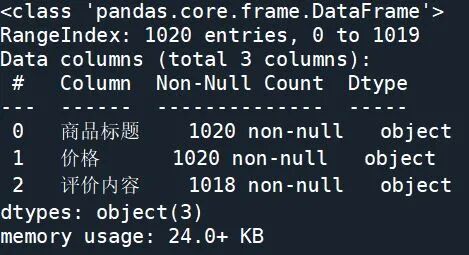
上面结果解析:Non-NULL Count为各个字段的非空数值和。可以看到,评价内容这个维度字段有2个空值。右边Dtype表明三个字段都是字符串object类型。memory usage为这张上商品信息表格的占用字节空间,有24kb。这里额外提醒一下,如果一张表格有5G以上,也就是Excel软件都较难打开时,可以换一种实现方式,使用dask库,是一种分布式的数据处理package。
从上图info信息中可以知道,这张商品信息表的空处有2个,也就是缺失值为2。而重复值计算得到为19个。接下来就是解决缺失值和重复值的方法,考虑到重复值多次出现会影响到后续词频统计的结果,本文考虑将重复值剔除。而缺失值会影响后面对评价内容分词的步骤,因此这里选择用空格进行替换。整段代码如下,刚开始转用Python的小伙伴可以牢记这段代码,这几乎是每次数据分析必用的。
import pandas as pd
df = pd.read_excel('苏宁易购_airpods系列.xlsx')
df.isnull().sum() df.duplicated().sum() df.info() df.dtypes
df['评价内容'] = df['评价内容'].fillna(' ')
df = df.drop_duplicates()
在3个字段中,最需要提取的是评价内容,因为本文的目的是建立一个商品评论文本信息挖掘系统,功能包括情感分析、词云图可视化。而每个用户ID的评价内容都是不一致的,因此,需要去做聚合运算。整合所有评价内容,同时去除停用词,最后形成一句话,虽然这句话是不通顺,但是对后面的词频统计没有影响。
整合评价内容采用Python的内置函数split()完成,首先利用Pandas库中的tolist()函数将评价内容字段的记录变为一个列表,接着将列表转换为字符串,这里需要用到split()函数完成。以空格字符串作为连接符,连接列表里的每一个元素。最终形成的效果截取一部分如下:

之后就是去除停用词,停用词无论是中文NLP任务还是英文NLP任务,都需要用到这一步。这一步不仅可以去除大部分噪音,同时也能节省计算资源,更加高效。去除停用词的算法其实很简单,就是遍历需要做统计挖掘的文本,如果文本中有单词是属于指定的停用词的,就剔除。显然,这里就需要停用词库,停用词库有很多,有百度的停用词表、有哈工大停用词表、有四川大学机器智能实验室停用表等。本文选择哈工大停用词表,因为此表相较于其他表有对电子商务领域较好的单词。读者若是想做一个理想的项目,可以考虑自建电子商务领域的停用词表。
去除停用词具体的代码及做法将在情感分析处讲解。
上一部分我们提取了商品信息表格中的每个ID的商品评价内容,同时对其整合进行去停用词,得到了一份干净的txt数据集。接下来就可以进行文本挖掘的事情了。首先是商品评论词云图构建。
在Python中词云图构建的库有很多,常用的就是Wordcloud标准的词云图可视化库,还有pyecharts的词云图API。前者在构建词云图时,新手使用者往往会出现一大堆问题,比如pip安装失败、编码错误、字体使用错误等,除此之外,其使用难度其实也是蛮大的。而后者则是常用于浏览器上的交互式图表,其以代码量,封装性高所出名,听起来是比较切合本文这个主题的,但是本文却没有考虑,原因是后面所用到的网页开发库streamlit要显示交互式图表通常不用pyecharts。
因此,这里本文引出新兴的词云图可视化库stylecloud,这个库是基于wordcloud的。运用这个库,新手可以以最少的代码量画出各色各样的词云图,支持形状设置。话不多说,直接上代码:
start = time.time()
stop_words = open('哈工大停用词表.txt','r',encoding='utf8').readlines()
stylecloud.gen_stylecloud(text=txt, collocations=True, font_path=r'C:\Windows\Fonts\simkai.ttf', icon_name='fab fa-jedi-order',size=(2000,2000), output_name=r'img\词云图.png', custom_stopwords=stop_words) end = time.time() spend = end-start
代码解析:
首先引入stylecloud库,而后使用.gen_stylecloud()对象来初始化画图对象(类)。
text参数代表着目标文本,即我们已经处理好的商品评论txt文本。
collocations代表为是否包括两个单词的搭配(二字组),默认为True。
font_path为本机自带的字体,默认位置是C:\Windows\Fonts\这个文件夹,使用者可以根据喜好选择这个文件夹里面任何一种字体,也可以额外下载。
icon_name这个参数可以说是stylecloud库的灵魂之处,它可以设置蒙版图的形式。当然,这个参数不能乱写。创作过词云图的朋友都知道,自己设置蒙版图样式是有趣但是会出现分辨率极低的问题。为解决这个问题,Font Awesome实现了绝佳的方案,即构造一套以矢量形式存放图标字体库与CSS框架,供使用者调用。使用者不仅可以调出高清的图标,并且可以自定义其中的CSS文件,加入或者修改到合自己胃口的样式。而stylecloud这个库就是调用这个网站的所用内容,使用者可以在stylecloud\\static文件夹中找到fontawesome.min.cssCSS文件,这里面包含了很多矢量图标。
读者会问,怎么知道这些图标的name?下面提供两个网站:
https://fontawesome.dashgame.com/。这里面就是存放各种矢量图标的名称,使用者可以使用不同类别的图标样式,其中手势相关样式如下图:

除此之外,本文还设置了时间间隔,因为众说周知词云图的刻画需要较长时间,如果文本较长,一分钟也有可能。所以加上时间的概念,对使用者进行数据调入也会友好一些。
这样,我们就构建好了词云图,将在下一部分网页端应用,这里以Airpods第二代举例,先上效果图

词云图构建完以后就是轮到情感分析,对干净的商品评论信息做情感分析是非常有用的。对商家而言可以清楚知道买方使用此产品的感觉与评价,以便后面优化产品,而对想要买此产品的人更加有借鉴。本文将对AirPods商品评论进行情感词正负情感词统计。
利用到的库是cnsenti,这个库是中文情感分析库。在NLP任务领域中,大多库与例子都是英文的,因此这个中文库对于经常对中文文本进行挖掘的人是个好消息!
首先先介绍下这个库把吧,cnsenti模块中分为两大部分,一个是本文用到的情感分析对象Sentiment,另一个是没有用到的情绪分析对象Emotion。情感分析使用的词典是知网Hownet,支持自定义。情绪分析使用的是大连理工大学情感本体库,可以计算文本中的七大情绪词分布。由于本文只使用情感分析对象类,因此感兴趣的读者可以自行学习情绪分析类。
对AirPods商品评论信息进行情感分析,在默认条件下,只用2句代码即可。是的,就是那么方便!
senti = Sentiment()result = senti.sentiment_count(txt)
txt为我们的目标文本,首先需要调用情感分析类Sentiment(),如果不设置任何参数,即表明以默认条件初始化。接着使用sentiment_count()函数计算正负情感词统计,以AirPods第二代举例,实现结果如下:

上面结果说明:总共单词有18128个,句子有625句。积极的情感词语有2221,消极的情感词语有322个。
在情感分析类中,除了sentiment_count()函数,还有sentiment_calculate()函数,有什么区别呢?这个可更加精准的计算文本的情感信息。相比于sentiment_count只统计文本正负情感词个数,sentiment_calculate还考虑了情感词前后是否强度副词去修饰,情感词前后是否有否定词的情感语义反转作用。同样以AirPods产品举例,使用这个函数,得到的结果为

可以看到,识别出来的积极词汇应该是使用了加权的手段将频率升维到数值。
接下来就是网页结构设计,做网页首先就是构造出一个思路图,确定功能是什么,有哪些控件,控件摆放位置如何。对于功能,本文的主题是商品评论信息文本挖掘,先对商品评论初始文本进行整合于去停用词。而后利用stylecloud库进行词云图构建,最后进行情感分析。除此之外,作者还希望完成一下功能:
确定功能就是以上这些了。通过上面的功能,本文可以确定有哪写控件:
文本控件,用来存储简介、正负情感词数值比、词云图构建花费时间second。
图像(graph)控件,用来存储本地存储好的词云图,以在web 端展示。
dataframe控件,用来显示原始表结构类型数据
sidebar侧边栏控件,相当于平时我们在各大网站看到的侧边栏目录一样,不过本文在侧边栏的功能是不一样的。
侧边栏下的文本控件。
selectbox单项下拉选择框控件,存储AirPods各型号,相当于完成分类型分析的功能
radio单选按钮控件,存储显示类型:原表结构数据类型或者文本挖掘结果显示。
按照常规的网页构建,控件位置的空间摆设是一定要设计的。但是对于新手来说,接下来讲的超级web app建设streamlit则不需要考虑了。
streamlit的官方(https://streamlit.io/)简介如下:
以最快的方式建立于分享数据app,将数据显示在可分享的web app上,以python编程语言实现,无需前端经验。Streamlit是第一个专门针对机器学习和数据科学团队的应用程序开发框架,它是开发自定义机器学习工具的最快的方法,可以帮助机器学习工程师快速开发用户交互工具。同时它是基于tornado框架,封装了大量互动组件,同时也支持大量表格、图表、数据表等对象的渲染,并且支持栅格化响应式布局。Streamlit的默认渲染语言就是markdown;除此以外,Streamlit也支持html文本的渲染,这意味着你也可以将任何html代码嵌入到streamlit应用里。
读者可能会疑惑做网站,以为前后端都用Python+streamlit是一件普通的事情。其实不然,在streamlit建立之前,web creator with python一般采用的是前端使用html、css、JavaScript,后端使用python、Flask、Django。如果不用Python,则是前后端都使用D3。
因此,本文所使用的Python+streamlit前后端贯穿创建web app对新手是多么的友好!
接着,先展示streamlit的快速使用方法:
首先pip install streamlit安装这个库,而后在命令行输入streamlit hello。这时会弹出一个窗口,这个是内置的打开帮助文档,里面有各种实例,下面为一部分截图:
首先是,记录着帮助信息的页面,里面存放着各种连接
而后在下拉框选择plotting demo,点击后显示如下:
这是一个加载了记录条的画图程序,可以是交互式的。
综上,就可以发现,运行streamlit不是在anaconda等python编译器里面运行的,而是在命令框cmd中输入streamlit run .py文件来运行程序的。
有兴趣的读者可以多泡一下streamlit的官网,可以学习到很多东西。
最后就是本文的web app构建与功能整合部分。先上代码
import streamlit as stimport pandas as pdfrom cnsenti import Sentimentimport stylecloudimport time
st.title('AirPods智能耳机商品评论分析系统')st.markdown('这个数据分析系统将以可视化形式挖掘某电商公司下苹果三种AirPods型号的商品评论信息')st.markdown('Apple AirPods是苹果品牌的无线耳机。目前有市场上销售主流是3中机型:**AirPods2代**、**Airpods pro**、**AirPods三代**。这款耳机的主要特点是:耳机内置红外传感器能够自动识别耳机是否在耳朵当中进行自动播放,通过双击可以控制Siri控制。带上耳机自动播放音乐,波束的麦克风效果更好,双击耳机开启Siri,充电盒支持长时间续航,连接非常简单,只需要打开就可以让iPhone自动识别。')st.sidebar.title('数据分析系统控件')st.sidebar.markdown('选择一款型号/可视化类型:')
DATA_URL=('苏宁易购_airpods系列.xlsx')
def load_data(): data=pd.read_excel(DATA_URL) return data
df = load_data()df['评价内容'] = df['评价内容'].fillna(' ')
select = st.sidebar.selectbox('选择一款型号',df['商品标题'].unique())
state_data = df[df['商品标题'] == select]
select_status = st.sidebar.radio("可视化类型", ('表结构数据','文本挖掘'))
if select_status == '表结构数据': st.text('该电商公司近期售卖产品的相关数据(以表结构化显示)') st.dataframe(state_data) if select_status == '评论可视化': txt_list = state_data['评价内容'].tolist() txt = ' '.join(txt_list) senti = Sentiment() result = senti.sentiment_count(txt) start = time.time() stop_words = open('哈工大停用词表.txt','r',encoding='utf8').readlines() stylecloud.gen_stylecloud(text=txt, collocations=True, font_path=r'C:\Windows\Fonts\simkai.ttf', icon_name='fab fa-jedi-order',size=(2000,2000), output_name=r'img\词云图.png', custom_stopwords=stop_words) end = time.time() spend = end-start if result['pos'] > result['neg']: st.markdown("#### 该商品的正负情感值比为{}:{},呈积极信号".format(result['pos'],result['neg'])) if result['pos'] < result['neg']: st.markdown("#### 该商品的正负情感值比为{}:{},呈消极信号".format(result['pos'],result['neg'])) st.image(r'img\词云图.png',caption = '词云图') st.text('运行时长:{} s'.format(spend))
代码解析:
首先引入包之后的前五行,是设置这个web app的标题,为AirPods智能耳机商品评论分析系统。然后下面为记录该程序的简要信息作为副标题。同时存储一些AirPods这款苹果公司旗下的智能手机简介与它的功能独特之处。除此之外,st.sidebar()这个函数是将目标从主页面转到侧边栏中,在侧边栏填入需要填入的信息。
之后就是第一部分讲解的加载数据、数据探索性分析,去除重复值,填充缺失值等操作。
select = st.sidebar.selectbox('选择一款型号',df['商品标题'].unique())这句话就是将商品信息表中的去重商品标题,即AirPods三代的机型作为下拉框单选选择的值。选择这个值后,就可以利用pandas进行条件筛选,最后用st.dataframe()函数将这个表结构类型进行显示。
select_status = st.sidebar.radio("可视化类型", ('表结构数据','文本挖掘'))代表的是设置单选选择按钮的值,即主页面显示哪种页面,是表格类型数据,还是文本挖掘结果:词云图与情感分析结果。
if语句的设定如下:根据state_data结果,抽取的数据为为AirPods三代中的一代,那么记下来主页显示的表格数据类型或是情感分析都是基于这一代机型的相关商品信息。接着if语句是判定select_status是表结构数据还是文本挖掘,因为在本文的初始设定中,主页面上是只显示两种可视化的。
而后一个if语句时提供给文本挖掘,也即情感分析用的。在第二部分中有讲到,本文时计算正负情感词的比例。如果正面情感词(积极情感词汇),则运行st.markdown("#### 该商品的正负情感值比为{}:{},呈积极信号".format(result['pos'],result['neg'])),显示积极信号。反之,为消极信号。
这里有一个time模块引用,这个引用时计算词云图构建的时间,大约在30s左右。这种性能测试与评估在工作中也是经常用到,因为工作中的数据可不像本文实例中的大小一般。
词云图构建的代码在第二部分也提及到,这里直接嵌入到里面即可。同时利用st.image函数进行本地图片读取与显示。
除此之外,streamlit还有一个友好的点就是,可以支持写markdown代码,上面的文本控件大部分都是用markdown编写,常使用markdown的读者可以研究一波。
最后以视频方式展示最终的效果,首先在该py文件的相对路径下调出powershell或者cmd命令,按打开streamlit的方式进行打开。











