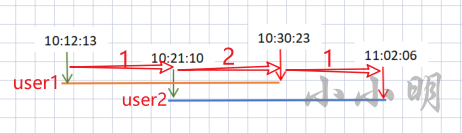
有了上图,我们应该就秒懂了这题的解题思路,先将所有的时间点排序,按顺序分配得到每个时间分区,绿色为进入起始时间点,红色为结束时间点,我们进入起始点时+1,进入结束时间点时-1,这样就可以得到每个区间的在线人数了。当然假如user3也从10:21:10进去,则这个时间点位置+2,后续的时间片段内在线人数就是累加后的值。
理解了思路,我们就可以开始编码了:
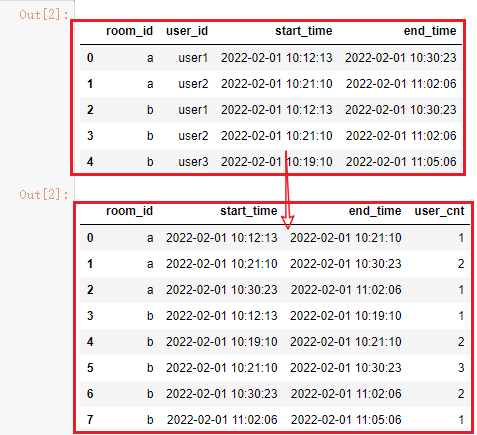
pandas处理代码
最终完整处理代码为:
import pandas as pd
df = pd.DataFrame([
["a", "user1", "2022-02-01 10:12:13", "2022-02-01 10:30:23"],
["a", "user2", "2022-02-01 10:21:10", "2022-02-01 11:02:06"],
["b", "user1", "2022-02-01 10:12:13", "2022-02-01 10:30:23"],
["b", "user2", "2022-02-01 10:21:10", "2022-02-01 11:02:06"],
["b", "user3", "2022-02-01 10:19:10", "2022-02-01 11:05:06"],
], columns=["room_id", "user_id", "start_time", "end_time"])
df
def func(df):
times = pd.concat([df.start_time.value_counts(),
-df.end_time.value_counts()]).sort_index()
times.index.name = "start_time"
r = times.cumsum().to_frame("user_cnt").reset_index()
r.insert(1, "end_time", r.start_time.shift(-1))
r.insert(0, "room_id", df.room_id.iat[0])
return r.query("user_cnt>0")
df.groupby("room_id", as_index=False).apply(func).reset_index(drop=True)
结果:
注意:使用如下代码即可设置一个单元格可以显示全部输出()
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
默认是输出结尾表达式:
from IPython.core.interactiveshell import InteractiveShell
print(InteractiveShell.ast_node_interactivity.default_value)
print(InteractiveShell.ast_node_interactivity.values)
last_expr
['all', 'last', 'last_expr', 'none',
'last_expr_or_assign']
MySQL处理代码
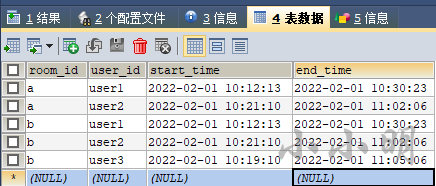
首先我们创建表并插入数据:
CREATE TABLE `t1` (
`room_id` VARCHAR(20),
`user_id` VARCHAR(20),
`start_time` DATETIME,
`end_time` DATETIME
);
INSERT INTO `t1`(`room_id`,`user_id`,`start_time`,`end_time`) VALUES ('a','user1','2022-02-01 10:12:13','2022-02-01 10:30:23');
INSERT INTO `t1`(`room_id`,`user_id`,`start_time`,`end_time`) VALUES ('a','user2','2022-02-01 10:21:10','2022-02-01 11:02:06');
INSERT INTO `t1`(`room_id`,`user_id`,`start_time`,`end_time`) VALUES ('b','user1','2022-02-01 10:12:13','2022-02-01 10:30:23');
INSERT INTO `t1`(`room_id`,`user_id`,`start_time`,`end_time`) VALUES ('b','user2','2022-02-01 10:21:10','2022-02-01 11:02:06');
INSERT INTO `t1`(`room_id`,`user_id`,`start_time`,`end_time`) VALUES ('b','user3','2022-02-01 10:19:10','2022-02-01 11:05:06');
然后编写SQL:
SELECT
room_id, start_time, end_time, user_cnt
FROM(
SELECT
room_id, start_time,
lead(start_time) over(PARTITION BY room_id ORDER BY start_time) end_time,
SUM(i) over(PARTITION BY room_id ORDER BY start_time) user_cnt
FROM(
SELECT room_id, start_time, COUNT(1) AS i
FROM t1 GROUP BY room_id, start_time
UNION ALL
SELECT room_id, end_time, -COUNT(1) AS i
FROM t1 GROUP BY room_id, end_time
) a
) b
WHERE user_cnt>0;
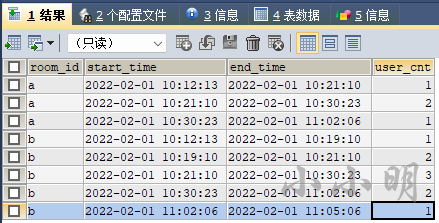 OK,问题解决。若读者有更优的解决方案欢迎评论区分享!
OK,问题解决。若读者有更优的解决方案欢迎评论区分享!











