
过去的十年见证了机器学习在诸多领域(如医疗保健、金融和司法)的巨大进步。然而,近年来的技术进步主要依赖于深度神经网络,这种网络的不透明性阻碍了人们对这些模型的检查能力。此外,一些法律要求正在提议,要求在部署和使用模型之前必须先理解模型。这些因素推动了提高这些模型可解释性和透明度的研究。本论文在这个方向上做出了一些贡献。
首先,我们对当前用于定义和评估模型预测解释的技术进行了简洁而实用的概述。然后,我们观察到各种可解释性概念的定义和评估之间存在一种新颖的对偶性,并提出了一种新的生成解释的方法,研究了这些新解释的属性。接下来,我们详细研究了良好解释的两个基本属性:正确性 - 解释是否反映了模型内部的决策逻辑,以及可理解性 - 人类是否能够准确地从这些解释中推断出更高层次和更普遍的模型行为。对于每个方面,我们都提出了评估方法来评估现有的模型解释方法,并讨论了它们的优缺点。
接下来,我们探讨了解释哪些实例的问题,并将透明度示例观点作为回答这个问题的方法。我们展示了这种方法在揭示图像分类器和机器人控制器的隐藏属性方面的优势。最后,本论文确定了未来研究的方向,并倡导将模型可解释性和透明度更紧密地融入到可信赖机器学习研究的生态系统中,该生态系统还包括公平性、鲁棒性和隐私等方面的努力。
1. 引言
在过去的十年中,机器学习(ML)迅速改变了社会。从谷歌翻译、Facebook好友标记和Snapchat过滤器等日常产品和功能,到医疗诊断、保险承保和贷款审批等专家知识领域,再到自动驾驶、虚拟现实和基因治疗等新兴技术,ML在所有这些领域都发挥了关键作用,人们普遍认为,它的重要性只会越来越重要。尽管如此,ML的广泛应用也带来了独特的挑战。当我们无法手动指定模式时,ML的目标是从数据中自动发现它们。例如,在图像分类中,因为如果有可能的话,编写一个手动规则来分类像素矩阵是看起来更像猫还是狗是极其困难的,我们借助于ML在像素矩阵空间中学习一个决策边界,以将猫的边界和狗的边界分开。当边界具有非常复杂的形状时,就像大多数复杂任务需要的那样,理解它就成为一个严峻的挑战。因此,学习计算这些边界的模型通常由深度神经网络或树集成(例如,随机森林或增强树)表示,通常被称为“黑盒模型”。
但是,为什么我们需要或者想要理解这些模型呢?除了满足一般的好奇心外,了解模型学习的内容还有非常实际的目的。考虑一个基于过去贷款数据训练的模型,以做出新的抵押贷款批准决策。虽然理想情况下我们希望模型根据申请人的财务健康状况和还款可能性进行预测,但它很可能会学会依赖虚假的相关性。例如,在历史上,非裔美国人往往财务不稳定,受到银行的歧视,这导致这种种族与拒绝贷款有很强的相关性。因此,该模型可以学习一个简单的规则,即拒绝非裔美国申请人,而不考虑他们的其他因素,这与训练数据基本一致。对于这个模型,如果我们有强调种族特征对模型预测的重要性的模型解释,我们可以很容易地发现种族偏见。
再举一个例子,假设我们想训练一个神经网络来从x射线图像中检测癌症,其中的数据来自两个来源:综合医院和专业癌症中心。可以预料的是,来自癌症中心的图像包含更多的癌症病例。然而,在渲染x射线图像时,癌症中心在左上角添加了一个小的时间戳水印。由于时间戳与癌症存在强烈相关,模型可以学习使用它进行预测。在这种情况下,虽然该模型可以通过识别时间戳或癌症的真实医学信号来达到非常高的准确性,但前者的操作模式将错过所有没有时间戳水印的癌症阳性图像的检测,例如来自不同医院的图像。因此,如果我们意识到水印确实很重要,那么我们应该丢弃模型,并重新开发数据收集和模型训练流程。
除了这些假设的设置之外,对这些模型的普遍缺乏了解也导致了许多引人注目的失败。例如,谷歌照片中的图像识别系统将深色皮肤的人标记为大猩猩,微软的对话机器人Tay在某些提示下生成仇恨言论。因为我们对模型的行为没有很好的理解,所以很难预测什么图像或什么提示会导致这样的恶劣行为,并主动阻止它们发生。这种担忧导致了值得信任的机器学习领域的发展,广泛地旨在使机器学习系统在部署后可靠和可靠。它包含许多子领域,被广泛研究的子领域包括可解释性、透明性、公平性、鲁棒性和隐私性。本文侧重于前两个,试图通过生成对其预测的解释或研究其各种行为(例如,高置信度失败)来更好地理解黑盒模型。本文将重点放在这两个主题上,因为它们是实现公平、鲁棒性和隐私的“手段”。
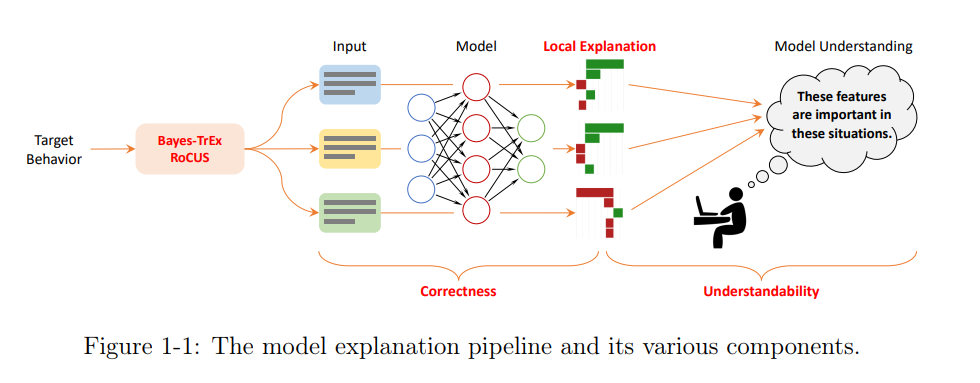
下面,我们对第2章到第7章进行概述,这构成了本文的技术内容。第八章重申了本文的主要观点,并指出了今后的研究方向。
标准的模型理解方法从流程的第二阶段开始,在这个阶段我们已经确定了一些要研究的输入实例。从这里开始,生成局部解释来说明模型对这些输入的推理过程。在本论文中,“模型推理”主要指的是每个特征的重要性。接下来,这些局部解释被人类解释消费者总结为更全局和普遍的模型理解,以便在后续决策中作出相应调整(例如,由于种族歧视而放弃模型)。在简要概述模型可解释性研究的现状之后,我们将在第2章中关注生成和评估局部解释的方法。在第3章中,我们提出了一种生成解释的新范式,并讨论了它的影响。然后,在第4章和第5章中,我们介绍了模型解释的两个关键属性,即正确性和可理解性,并提出了评估这些属性的方法,并讨论了这些发现对未来模型解释研究的影响。最后,本论文还倡导在模型理解流程的更早阶段开始。我们不应从任意或随机的输入实例开始,而应明确考虑每个模型行为,如矛盾预测或高置信度错误,并将它们用于指导解释输入的选择。具体而言,第6章和第7章介绍了Bayes-TrEx和RoCUS框架,以找到符合某种目标模型行为的输入实例。从某种意义上说,这两个框架回答了“解释什么”的问题。


想要了解更多资讯,请扫描下方二维码,关注机器学习研究会

转自:专知










