为了满足大家的不同需求,我们提供两种班型
1. 高级研讨班:课程售价 5800元或800美金:
4 个月直播课程训练;
参与开源ChatGLM功能开发,成为Github高星项目参与者;
-
参与多智能体强化学习顶刊项目,获得独特的竞争优势;
完成自己的Latent Diffusion Model文本生成模型
2. 综合实战班,课程售价:8800元或1200美金:

(京东A100-GPU价格实例)
每个方向前30名学员可以获得钉钉与飞书版本GPT-4机器人免费使用权限一年

文本方向重点培养学习者大语言模型(Large Language Model)的知识和技能。学习者将了解大预训练模型(LLM)的原理,包括模型的训练过程、预训练任务和自监督学习方法等。
授课老师:Cassia Goth(郭老师), Henry Wilson
开课时间:October 22, 2023
上课时间:每周日9:00 - 12:00
第一周:大语言模型在自然语言处理中的应用
Self-attention与multi-head多头Transformer的原理详解
GPT模型的原理 GPT-2/3/3.5/4的演化和比较
BERT, RoBERTa, T5, XLnet等模型的对比
目前其他主流语言模型的比较
如何根据业务选择最合适自己的语言模型
第二周:大预言模型的Fine-Tuning,Prompt Engineering
Fine-Tuning的原理,迁移学习的原理以及它与LLM的关系
Pre-Train预训练与Fine-Tuning的工作流
如何解决数据集相关问题
Instruction Learning
Few-Short Leanring 与 Meta-Leanring,few-short leanring在LLM中应用
使用Prompt来完成自定义任务,Prompt的设计与优化方法
Prompt-Tuning技术, Prompt-Tuning与传统Fine-Tunning技术的区别
第三周:基于人类反馈的强化学习训练(RLHF)
LoRa: Learning from Rules and Arguments. 基于规则定义的语言能力增强
人机交互AI系统的工作流与框架(workflow与framework)
PPO算法在ChatGPT中的应用分析如何设计Reward ModelPPO算法在ChatGPT中的算法实践
Off-Policy训练与Importance Sampling
Imitation与Reverse Reinforcement Learning在RLHF中的应用
第四周:大语言模型的部署实践
第五周:基于开源模型的多模态实践
Visual-ChatGPT的原理
如何准备自己的数据集
Finetune ChatGLM
第六周:开源版ChatGPT的待完成任务解析
第一个大项目
:成为开源版ChatGPT -- ChatGLM-Tuning的源代码贡献者
第七周:基于自主知识库的QA助手的实现原理
第八周:Flash Attention, 感知视野扩大
本节课我们将深入探讨如何通过多模态方法扩大模型的感知视野,从而提高模型在各种任务中的性能。
Flash Attention的核心原理:深入研究Flash Attention的工作原理,包括注意力的计算方式和关键词汇的处理
探讨如何调整和优化LLM模型以适应Flash Attention技术
感知视野扩大在实际任务中的应用:学习如何应用多模态模型解决文本、视觉和听觉结合的任务。
第九周:Parameter-Efficient Fine-Tuning (PEFT),并行训练方法
深入了解PEFT技术的工作原理,包括如何通过减少参数来提高训练效率。
学习如何应用PEFT技术,以及如何调整参数以改进模型的训练速度和性能。
训练一个QA模型并尝试使用PEFT来优化模型的性能
如何使用数据并行和GPU并行来加速训练
第十周:Prompt model技术
我们将深入研究Prompt model技术,这是一种强大的自然语言处理(NLP)方法,用于构建智能对话系统和问题解答系统
Prompt model架构:深入了解Prompt model的基本架构,包括输入编码和生成答案的过程
自动Prompt生成:了解如何使用自动方法生成有效的Prompt。
项目实践和总结:学习如何构建智能问答系统并使用Prompt model来提供准确的答案。
第二个大项目:完成基于企业知识库的问答大模型
第十一周:数字人的基本概念和技术
数字人的定义和目标
-
GPT模型的使用:如何使用AI自然语言模型创建高质量的文本内容
数字人的声音与交互
TTS技术简介:文本转语音技术的原理和应用
如何让数字人"说话":接入TTS技术与用户进行声音交互
实践项目:创建一个数字人伙伴,使其能够回答问题并生成语音回应
第十二周:数字人的记忆和数据库
第十三课:数字人的情感与表情
第十四课:强化学习与数字人的自主性
第十五课:多模态AI与数字人的感知
多模态AI简介:了解如何整合多种感知方式,如视觉、听觉和文本
数字人的感知能力:如何使数字人可以理解和回应多种感知输入
实际案例:设计一个数字人伙伴,可以处理来自多种感知模式的输入,并做出相应的反应
总结:以上5周数字人部分涵盖了从基础的文本生成到声音交互、记忆、情感表达、强化学习以及多模态AI的复杂主题。这将使他们能够构建高度智能和多功能的数字人伙伴。

第三个大项目:数字人原理与技术实践
(该项目与图像方向融合,为共有项目)
5.2AIGC大模型-图像视频生成方向

生成式图像/视频已经成为一个热门和前沿的研究领域,它引领了计算机视觉和艺术的新浪潮。该课程旨在深化对生成式图像/视频的理解,通过学习最新的技术和模型来培养实际技能。
授课老师:赵二可, Henry Wilson
开课时间:October 22, 2023
上课时间:每周六9:00 - 12:00
第一周:视觉Transformer(ViT)及视觉AIGC导论
视觉AIGC的学习目标
视觉AIGC方向求职的面试准备与业务学习
ViT的理论介绍与实现原理
ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
DeiT: Training Data-Efficient Image Transformers & Distillation through Attention
TNT: Transformer in Transformer
ConVit、MLP-Mixer、Swin Transformer等混合方案
第二周:ViT的高级方法,DALL-E
Transformer的结构升级
-
视频Transformer:TimeSFormer,VideTransformer
Transformer,GPT与图像生成模型
DALL-E:基于文本生成图像的原理
ViT与计算机视觉专门问题的结合应用:
检测任务(Object Detection)与ViT
分割任务(Semantic Segmentation)与ViT Image Caption
项目一导引:利用 ViT 进行图像分类/物体检测
通过该项目能够掌握 ViT 的理论认识以及上手技能;同时,也能理解 CV 领域一 路走来的发展,无论是技术上从传统 CV 算法,到深度学习(deep learning,也即 DL)卷积神 经网络(Convolutional Neural Network,也即 CNN),再到现阶段 ViT,还是从内容上的分类/检测入手。因而,通过这个项目,能够使同学对 CV 领域的技术与内容,有直观且深入的理 解。同时,由于 Transformer 的天然特性,也对非视觉类数据的处理有了一定的积累。
第三周:对抗生成网络(GAN, Generative Adversarial Network )
第四周:GAN的发展与Wasserstein GAN
GAN存在的问题:Mode Collapse,难以训练
-
以上问题优化的原理与优化目标
Wasserstein GAN (WGAN)与原理, WGAN - GP
Unrolled GAN, Spectral Normalization, Noise Injection, Mixing Regularizationd等其他优化方法
第五周:GAN的高级应用
第六周: GAN的进阶发展
第七周:项目指引课:GAN 在图像矫正领域的应用
GAN 是一类强大的生成类模型,其早于 diffusion model,因而已真实应用于实际场景当中。在这个项目中,我们将利用所学的 GAN 相关知识,进行静态图片与动态视频的矫正工作。切实体会课上所讲的理论知识如何应用在实际工作中,并能够避免很多目前所存在的人云 亦云似的一知半解的讹传,真正做到学以致用。同时,在项目进行中,会介绍大量切实可行 的技巧,这些技巧是普适的,能够被所有架构应用。不仅如此,我们也会介绍一些 CV 领域 底层的思想,使大家的学习工作不仅流于表面,也能够深入到本质。 
第八周:Latent Diffusion 导论
第九周:Diffusion Model 进阶
Diffusion Model 进展:Learnable Diffusion,
Reversible generative model 与 LDM
面向未来的Diffusion: Causal generative modeling, 数据缺失
与强化学习的结合
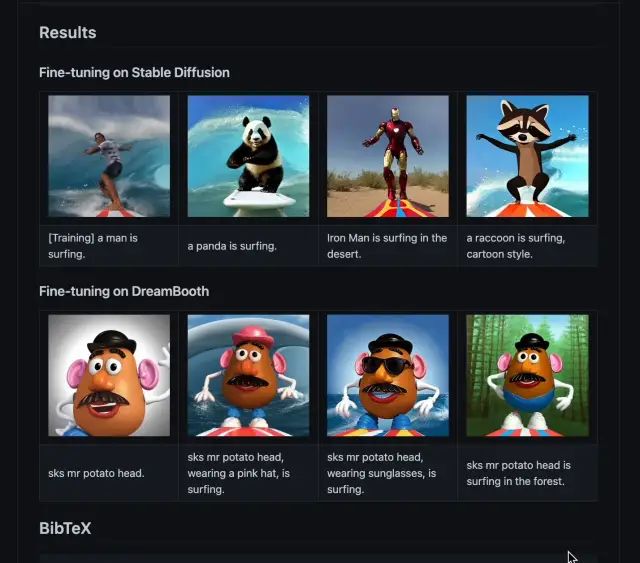
第十周:图像生成大项目:利用 Latent Diffusion Model进行基于文字描述的图像生成
在经过第一个项目(进行 ViT/Transformer 技能储备)以及第二个项目(CV 技能储备)后,我们做好准备准备,得以迎来最激动的项目内容,即进行利用 LDM 的图像生成工作。
LDM 是最新的生成式模型,其内容上的最大特点便是利用语言文字进行图像生成;同时在 技术上,也与 GAN 不同。具有训练相对简单,效果相对较好(当然,通过我们的讲解,GAN 技术同样也可以做到此点)的特点,因而目前热度较高。在这个背景下,我们将带领大家直 观感受 LDM 究竟是如何完成这点的。
第十一周:数字人的基本概念和技术
数字人的定义和目标
GPT模型的使用:如何使用AI自然语言模型创建高质量的文本内容
数字人的声音与交互
TTS技术简介:文本转语音技术的原理和应用
如何让数字人"说话":接入TTS技术与用户进行声音交互
-
实践项目:创建一个数字人伙伴,使其能够回答问题并生成语音回应
第十二周:数字人的记忆和数据库
第十三课:数字人的情感与表情
第十四课:强化学习与数字人的自主性
第十五课:多模态AI与数字人的感知
多模态AI简介:了解如何整合多种感知方式,如视觉、听觉和文本
数字人的感知能力:如何使数字人可以理解和回应多种感知输入
-
实际案例:设计一个数字人伙伴,可以处理来自多种感知模式的输入,并做出相应的反应
第四个大项目:数字人原理与技术实践(该项目与文本方向融合,为共有项目)
5.3 强化学习与智能决策
强化学习是一种研究智能体如何具备决策能力的学习方法,例如下围棋、控制游戏AI、控制机器人、无人机等领域,这些应用背后都展现了强化学习的重要能力。
授课老师:高老师
开课时间:October 21, 2023
上课时间:每周六9:00 - 12:00
第一周: First-Step on RL, Monte-Carlo Methods
本周将为大家带来到底什么是强化学习,并学会我们的第一个重要算法—蒙特卡洛模拟 (Monte-Carlo methods)。大家可以使用该方法训练第一个决策模型“21 点”扑克牌 AI. 你 甚至可以与自己的 AI 进行 PK.在这个过程中,你将对强化学习区别与传统的监督学习和非 监督学习有一个清晰的认识,而且更加能够理解什么是“序列决策”问题。
第二周: Markov Decision Process, The Reinforcement Learning Framework and Paradigm, Dynamic Programming
本章我们将为大家正式定义强化学习问题,以及强化学习的整体框架是什么?动态规划 (dynamic programming)思想是如何应用在强化学习领域的?我们将会为大家带来马尔科夫 问题的定义,如何将一个问题抽象为强化学习问题?我们将会为大家带来 Gym 环境的介绍, 并且我们将会研发新的代码,将该代码适用于多个问题场景。我们将会解决“出租车寻路 Taxi”, “攀登问题 walking cliff”等离散环境的强化学习问题。
第三周: Temporal-Difference Learning, SARSA,Q-Learning
我们已经学习了如何通过蒙特卡洛模拟(MC)来解决问题,但是 MC 方法最大的问题是我们 需要将每一次的环境运行彻底结束(terminated)才可以进行更新。那么,这个对于更新时 间特别长,问题结束需要很久(甚至永远不能解决)的问题就不能解决。在该章节,我们将 为大家带来 Temporal-Difference 方法,所谓 Temporal-Difference 方法,就是在每次迭 代之间模型的策略就进行动态变化。我们将学习两种非常重要的差分学习方法 SARSA 和 Q- Learning。SARSA 可以在线(online)的更新模型,Q-Learning 可以根据未彻底完成的经验 数据进行更新。这两种方法都可以更加快速得进行模型更新。
第四周: From Q-Learning to DeepQ-Learning, Q-NeuralNetwork
在本周我们将学习如何使用深度神经网络来解决强化学习的问题,我们将一起阅读 《Natural》当年发表的关于 DeepQlearning 的文章,从原理上理解。并且,我们将会搭建 第一个深度强化学习网络,通过该网络来解决第一个月遇到的问题。你会发现深度学习在强 化学习中的威力。
项目一:机器人控制或者金融交易策略优化


在本章的项目中,我们将带着大家解决 Utility ML Engine 问题。Utility ML Engine 是一 个更加精细,更加现代化的机器人环境。里边包含了人体、物体、动物等机器人高维度模 型。我们将会使用 PolicyGradient 方法解决机械臂的控制。
或者你可以选择完成基于仿真的高频交易环境进行的金融量化交易模型。我们将为大家提供仿真的交易环境,大家需要设计一个模型,使得该模型在 60 天内的综合收益最大。
第五周: Experience Replay, Fixed-Target, DoubleQ-Learning, Dueling DeepQ-Learning
我们将深入学习 DeepQLearning 中重要的几个方法,Experience Replay 来充分利用训练数 据,使用 Fix-Target 来使得训练更加稳定,模型更加能够收敛。我们还会学习更加细致的 Dueling DeepQling,通过两个网络一起来“竞争”学习,获得更高效的学习结果。
第六周:Imitation Learning, Behavior Colone, Robotics Learning, Inverse Reinforcement Learning.
在机器人控制、工业生产等任务中,强化学习所面临的一个问题是没有足够的训练数据,因 为我们不能在真实环境下就像在模拟环境下生成足够多的观察数据。本周我们将学习如何可 以融合人类的知识、演示到强化学习模型中。我们将学习如何通过专家演示来增加训练数据 的能力。同时,我们将学习如何通过逆向强化学习(Inverse Reinforcement Learning)来 通过专家演示让模型自动学习 rewards.
第七周:Policy Gradient, REINFORCE, Implementation PG on PyTorch
本周我们将学习什么是策略下降(Policy Gradient),PG 方法的数学推导过程,我们将会 掌握第一个基于 PG 的强化学习模型 REINFORCE,以及 PG 方法如何在 PyTorch 上实现。
第八周:Proximal Policy Optimization(PPO), Trust Region Policy Optimization (TRPO)
本周我们将学习更加高效 PG 方法。由于强化学习问题常常涉及到长时间(long-term)的目标 优化,因此其训练任务常常会出现收敛慢甚至不收敛的问题。因此,在 2017 年研究者们提 出了非常重要的“可信更新空间”的方法(Trust Region Policy Optimization),基于该 方法,我们能够保证 PG 训练过程中持续稳定的收敛。基于此,研究者们提出了“近似策略 优化”,这是一种更加高效的可信空间优化方法,既保证了收敛性,又提供了更快的迭代方 法。
第九周:DDPG, Actor-Critic Methods, GAE
为了更进一步的提高模型的训练速度和效率,我们将在本周学习一种新的方法,action- value,不仅有一个模型学习每一步的策略是什么,还有一个模型同步为我们学习出来的策略 进行打分。我们还会引入 advantage 函数,即模型估计的 value 和实际获得 value 的差值, 基于对这个函数的优化,我们的模型能够更加稳定。举个例子,如果两个人,一个人按照其 往常的表现,在这一次考试中应该能得 90 分,最终他的结果是 89 分,另一个人按照其往常 的表现,这一次表现应该是 70 分,但是他得了 80 分。虽然第二个人的结果更差,但是我们 认为在上一次考试和这一次考试之间,第二个人的模型更新是更有效率的。并且我们将会进 一步学习面向未来步骤的一种“泛化”的 Advantage 函数积累方法,各种方法更加能够帮助 进行面向长远问题的预测。
第十周:Self-Playing 自训练学习, The Lesson from AlphaGo and AlphaZero, Self-Play Learning
我们将在本周学习 AlphaGo 和 AlphaZero 的原理,什么是蒙特卡洛搜索(Monte-Carlo Search),什么是自训练学习(self-playing),AlphaZero 具体的实现原理,方法。
第十一周:AlphaZero 项目实战

我们将在本节使用 AlphaZero 的方法,将围棋任务从 19*19 简化为一个相对较为简单的“井 字棋”AI,带领大家完成一个初步的 AlphaZero 训练任务。通过本周的训练,你对 AlphaZero 的原理不仅仅停留在理论上,更是在实战中得到了锻炼!第十二周:基于大模型的强化学习 Large Model & Decision Making
本周我们将学习基于大模型机制(Transformer)的强化学习. 我们将学习两种方式:1. 如果通过训练GPT模型来控制机器人和智能体;2. 如何利用已有的大语言模型来为机器人控制提供更好的控制能力。
第十三周:多智能体强化学习 Multi-Agent Learning, Central Training Decentric Execution, HAPPO, HATRPO
本周我们将学习什么是“多智能体”学习,什么是马尔科夫博弈(Markov Games),为什么 多智能体任务不能简单的用单智能体方法实现,多智能体之间的协作和博弈问题如何处理。以及学习2021 年至 2022 年多智能体方向取得的进展,将学习重要的 CTDE 方法,将 学习多智能版本的 TRPO 和 PPO(HAPPO 和 HATRPO),以及算法上如何实现。
第十四周:项目三:分布式多智能体强化学习框架的构建
本周我们将为大家带来如何使用 Ray 的 RLlib 进行分布式的强化学习任务训练。大家通过分 布式环境对采样 Sampling 和 Updating 进行并行将大大加快训练速度。但同时由于多智能体 的依赖性,我们也将学习如何在 Ray 下进行有依赖关系的更新。我们将会给大家展示如何在 RLlib 上实现 HAPPO 和 HATRPO.
第十五周:VoxPoser, Deicision Transformer, Safe RLHF 等前沿领域, 项目四:基于大模型的智能决策(斯坦福小镇复现)











