
©PaperWeekly 原创 · 作者 | 张剑清
我们在 GitHub 上开源了一个个性化联邦学习算法仓库(PFLlib),目前已经获得 1K+ 个 Star 和 200+ 个 Fork,在业内收到了广泛的好评。PFLlib 囊括了 34 个联邦学习算法(其中包含 27 个个性化联邦学习算法)、3 大类数据异质场景、20 个数据集。开源该仓库的主要目的是:1)降低初学者研究个性化联邦学习算法的门槛;2)提供一个统一的实验环境,在多种场景和多个方面对不同个性化联邦学习算法进行评估,为个性化联邦学习算法在具体场景中应用时的选择提供参考;3)为个性化联邦学习算法的研究者们提供一个可以交流的平台,在交流的过程中互相学习,碰撞出新的火花。

PFLlib: Personalized Federated Learning Algorithm Library论文链接:
https://arxiv.org/abs/2312.04992代码链接:
https://github.com/TsingZ0/PFLlib

联邦学习(FL)作为一种新型的分布式机器学习范式,它主要用于训练人工智能(AI)模型。除了传统分布式机器学习的跨设备协同训练 AI 模型的特点之外,联邦学习的特殊性主要体现在保护每个设备上数据隐私的能力。联邦学习实现隐私保护的主要方式是:禁止具有隐私性的数据离开产生该数据的设备。这种限制使得这些设备上的本地数据无法通过传统分布式机器学习中的数据采集、数据清洗、数据分片等操作,来实现每个设备上数据的一致性。由于不同设备所处环境的不同,使得它们各自产生数据、采集数据、处理数据的方式不尽相同。于是,便产生了各个设备之间的数据异质问题,如图 1。在异质的数据上学习得到的本地模型,通过服务器进行了模型参数聚合后生成的全局模型会有表现不佳等问题。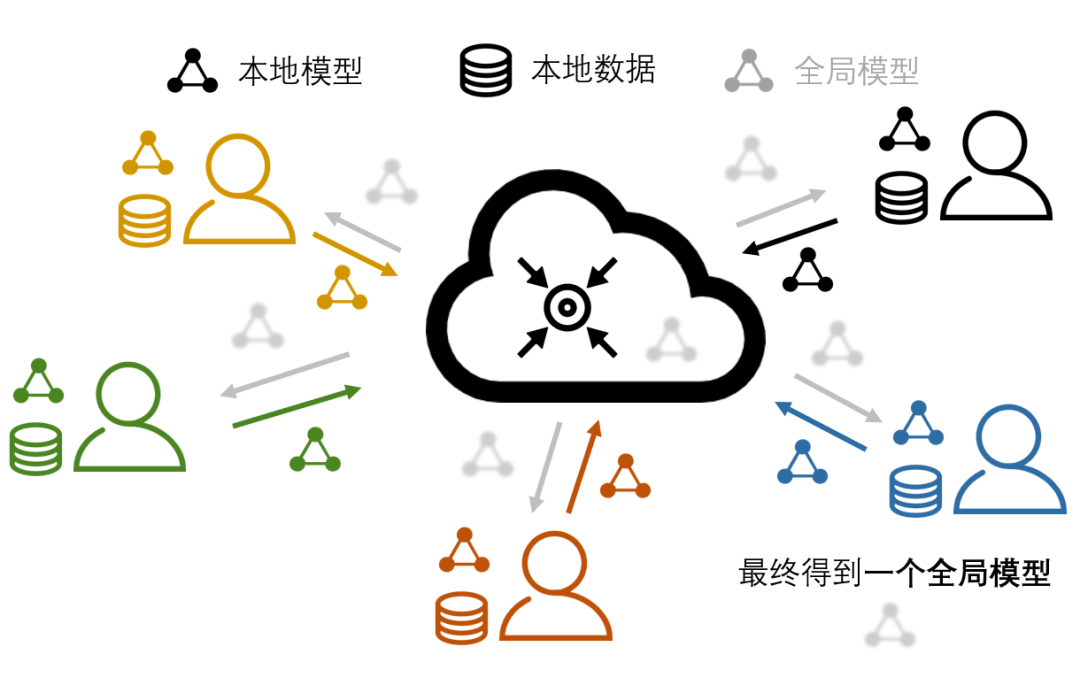
为了应对联邦学习中的数据异质问题,研究者们开始探索在设备参与到联邦学习系统里进行协同训练、聚合得到全局模型的同时,为自己学习适配本地任务的个性化模型的新型联邦学习算法。这类算法被人们称为“个性化联邦学习算法”。在个性化联邦学习的范畴中,生成全局模型不再是最终的目的,而以全局模型为知识共享的载体、用全局模型中蕴含的全局信息来提升本地模型效果才是最终的目标,如图 2 所示。在个性化联邦学习框架之下,每个参与者通过联邦学习过程实现协作,用聚合得到的全局信息弥补了本地数据不足的问题;且每个参与者为自己本地任务训练得到的个性化模型利好参与者自身,无形中激励了各个设备参与联邦学习的热情。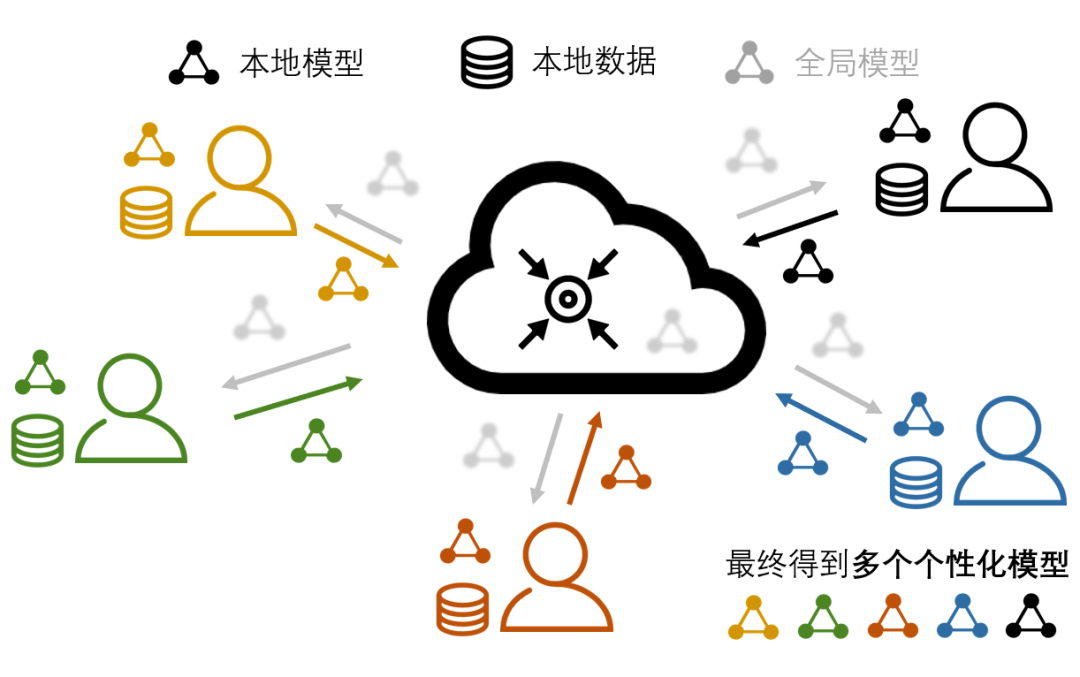
▲ 图2:个性化联邦学习。

2021 年伊始,本人在探索个性化联邦学习算法的过程中发现,由于不同论文的实验设置(如数据集、模型结构、数据异质种类、客户机数量、超参数设定等)不同,导致论文中的大部分实验数据不能复用。同时,有相当一部分的论文,其代码并不开源,使得我们无法通过在新场景下运行代码来获得实验数据。此外,在 PFL 领域逐渐火热起来后,对比实验往往需要比较十几个相关方法,即使每个方法有自己的开源代码,为这些具有不同风格、结构、规范的代码进行新实验设置的适配需要花费大量的精力和时间,使得刚入门 PFL 的研究者无法关注在 PFL 本身的研究上。当时,我在探索后来发表在 AAAI 2023 的 FedALA [1](PFLlib 包含该算法)过程中,感觉自己写的用来进行对比实验的代码框架相对简单易懂。出于开源精神,我便对其进行了开源。之后,随着我在 PFL 领域逐步深入,越来越多的PFL方法出现,我后续也持续地加入了不少算法,才有了如今的规模。▲ 图3:PFLlib 中实现 FedAvg 的例子。总的来说,PFLlib 拥有以下几个特性:
代码结构简单,易于入手和阅读,易于添加新算法。工具函数存放在utils文件夹中。基础的设备和服务器操作分别存放在clientbase.py和serverbase.py中。如图 3,以在 MNIST 数据集上实现最基础的 FedAvg [2] 算法为例,我们只需要编写generate_MNIST.py来生成实验场景,然后编写clientavg.py和serveravg.py来实现 FedAvg 训练流程,再将 FedAvg 在main.py配置一下,即可通过命令行运行 FedAvg 算法。
- 提供了较为全面的联邦学习算法仓库和实验环境。PFLlib 总共拥有 34 个联邦学习算法(其中包含 27 个个性化联邦学习算法)、3 大类数据异质场景、20 个数据集。
- GPU 资源需求较少。使用实验中最常用的 4 层 CNN 网络,可以在 NVIDIA GeForce RTX 3090 GPU 上,仅用 5.08GB 显存模拟 500 个设备同步训练的场景。
提供了一种基于 DLG [3] 的隐私攻击和隐私泄露度量指标,用于度量多数论文中没提及的 PFL 算法的隐私保护能力。
34个联邦学习算法
根据联邦学习算法中用到的技术,我们对 34 个 PFL 算法进行了分类,具体分类结果见表 1。
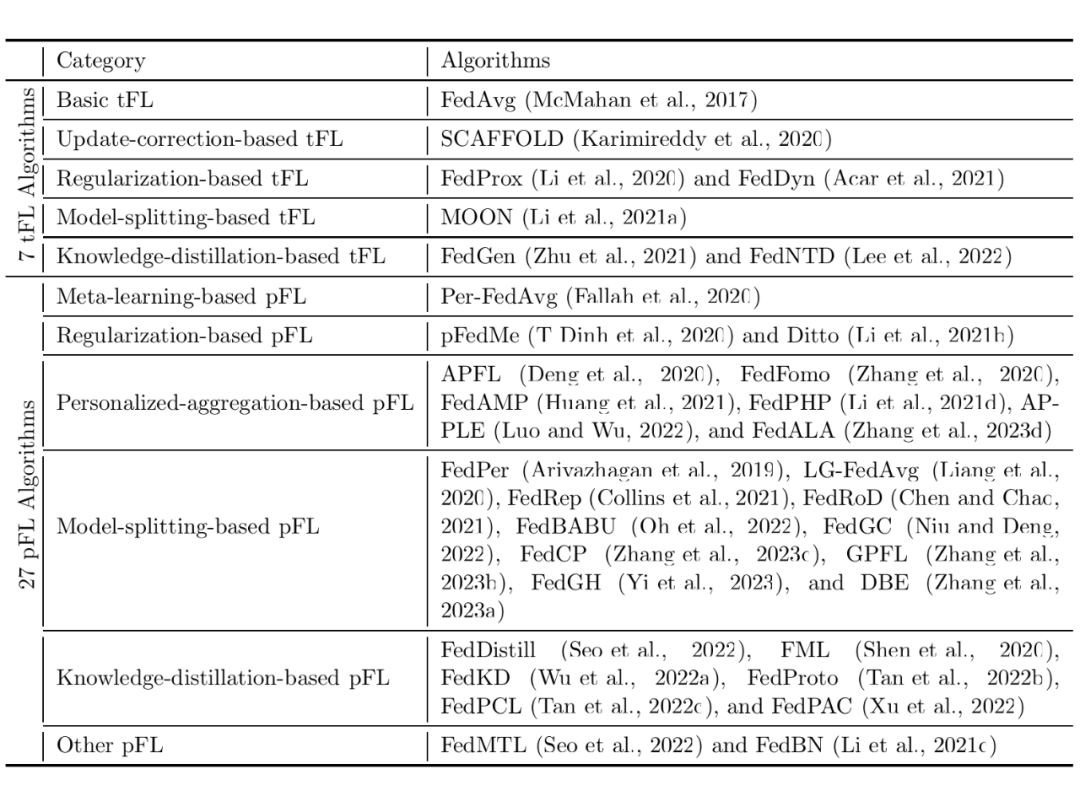
▲ 表1:PFLlib 中联邦学习算法的分类。

3个场景和20个数据集
联邦学习的数据异质场景主要分为四大类:不平衡性(unbalance)、标签倾斜(label skew)、特征漂移(feature shift)、真实世界(real-world)。其中不平衡性指的是不同设备上数据量不同;标签倾斜主要指的是不同设备上的数据特征相似但类别(标签)不同;特征漂移则与标签倾斜恰好相反,指的是不同设备上的数据标签相同但特征不同;真实世界指的是不同设备上的数据是真实采集到的,可能同时包含以上三种情况。由于不平衡性与标签倾斜和特征漂移都不冲突,PFLlib 将不平衡性融入了标签倾斜和特征漂移之中。PFLlib 为标签倾斜(含不平衡性)、特征漂移(含不平衡性)、真实世界三个场景分别提供了适用于各自场景的数据集。标签倾斜:该场景是在联邦学习领域探索的最多的场景,也是现实情况下最容易遇到的场景。该场景进一步还分为病态的非独立同分布(pathological non-IID)和真实的非独立同分布(practical non-IID)两个子场景。总共有 14 个数据集用于标签倾斜场景:MNIST、EMNIST、Fashion-MNIST、Cifar10、Cifar100、AG News、Sogou News、Tiny-ImageNet、Country211、Flowers102、GTSRB、Shakespeare、Stanford Cars。它们都支持以上两个子场景。特征漂移:在这个场景中,PFLlib 主要采用了 3 个数据集,分别是:Amazon Review、Digit5、DomainNet。真实世界:PFLlib 采用的是 IoT(Internet of Things)数据集,它们分别是:Omniglot(20 个设备, 50 个标签)、HAR(Human Activity Recognition)(30 个设备, 6 个标签)、PAMAP2(9 个设备,12 个标签)。每个数据集中含有多个子数据集,每个子数据集是从某个具体的设备(例如传感器、陀螺仪等)上采集得到的真实数据。这类数据集有利于 PFL 算法在实际场景落地问题的研究。正如 GPFL [4](PFLlib 包含该算法)中的实验表明,在模拟场景(标签倾斜和特征漂移等)表现较好的算法,在真实世界场景中不一定具有良好表现。部分实验结果
出于验证 PFLlib 中附带实验平台的可用性,根据 GPFL 中的默认实验设置,我们对部分算法在部分常见场景中的表现进行了展示,如下表所示(实验结果仅供参考)。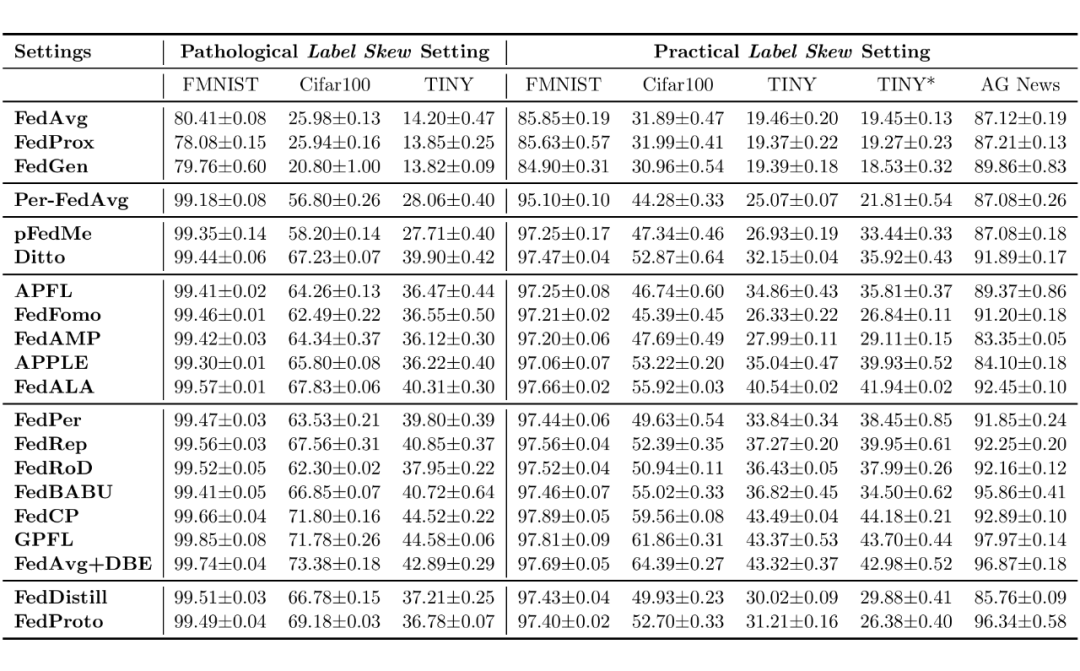
▲ 表2:PFLlib 中部分联邦学习算法在部分场景中测试集上的分类准确率。
最后,感谢大家对 PFLlib 项目的支持,也欢迎刚了解到 PFLlib 的朋友们一起参与到 PFLlib 项目的建设中来!
[1] Zhang, Jianqing, et al. "Fedala: Adaptive local aggregation for personalized federated learning." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 37. No. 9. 2023.
[2] McMahan, Brendan, et al. "Communication-efficient learning of deep networks from decentralized data." Artificial intelligence and statistics. PMLR, 2017.
[3] Zhu, Ligeng, Zhijian Liu, and Song Han. "Deep leakage from gradients." Advances in neural information processing systems 32 (2019).
[4] Zhang, Jianqing, et al. "Gpfl: Simultaneously learning global and personalized feature information for personalized federated learning." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.


如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧











