常规机器学习分析的文章大家都看了不少了,今天给大家分享一篇基于4种不同中国青少年受欺凌的受害者轨迹,使用常见的随机森林(RF)法构建预测模型。- 针对参与者分布不均衡的问题,使用随机过采样法来平衡数据集。
- 基于每次调查的总受害分数,测试了2~5个组的轨迹模型;
- 通过贝叶斯信息准则(BIC)、赤池信息准则(AIC)和对数似然(LL)确定了最优组数。
数据集被分为70%训练集和30%验证集;
使用多个指标评估模型性能,包括准确性、灵敏度、特异性、阳性预测值(PPV)、阴性预测值(NPV)和ROC的曲线下面积(AUC)。
- 使用"randomForestExplainer"包可视化RF模型中特征的重要性;
- 使用多个指标从不同角度评估特征重要性,包括节点数量、平均最小深度、准确度下降、基尼系数下降、Xj用于分割根节点的频率(times_a_root)以及p值。
据报道,全球约28.9%的13至15岁青少年曾遭受过欺凌。而在中国,欺凌更是造成青少年患精神障碍的首要原因。
随着年龄的增长,部分青少年摆脱欺凌,而部分却继续受到迫害,更有甚者从受害者转变为加害者。因此,研究团队基于不同的受害者轨迹构建预测模型,旨在为不同的受害者量身定制反欺凌干预措施。
11月21日,中国学者在期刊《Journal of Affective Disorders》(医学二区top,IF=4.9)发表了一篇题为:“Predictive analysis of bullying victimization trajectory in a Chinese early adolescent cohort based on machine learning”的研究论文。在该项研究中,研究团队使用组轨迹模型(GBTM)确定了四种不同的受害轨迹,并用机器学习法中的随机森林(RF)法构建一个预测模型,用于预测个体可能遭受的欺凌受害轨迹。如果你需要全文,请公众号后台回复关键词“pdf”。如果你对机器学习感兴趣,千万不要错过本月底的基于R语言的机器学习构建临床预测模型课程!详情可咨询助教,微信号:aq566665
√数据收集
在该项研究中,研究团队从中国安徽省淮北市进行的早期青少年队列研究中招募了1549名完成基线和两年随访评估的中学生(60.4%为男生;平均年龄12.49 ± 0.48岁),时间跨度为2019年至2021年共三年。
使用改编的Olweus欺凌受害者问卷(OBVQ)评估欺凌受害情况:- 问卷通过涵盖身体、言语和社会关系欺凌的六个项目来评估传统形式的受欺凌程度;
- 回答范围从“从未”到“6次或更多”不等,总分在6到24分之间,分数越高表示受欺凌程度越深。
对于数值型的缺失数据,使用中位数进行填充;分类数据,则用众数进行填充。
考虑到参与者分布中的类别不平衡会对模型的性能产生不利影响,研究团队采用随机过采样法( ROSE)来平衡数据集。- 主要通过平滑的自举方法来生成合成数据,从而平衡数据集的类别分布,提高模型的预测性能。
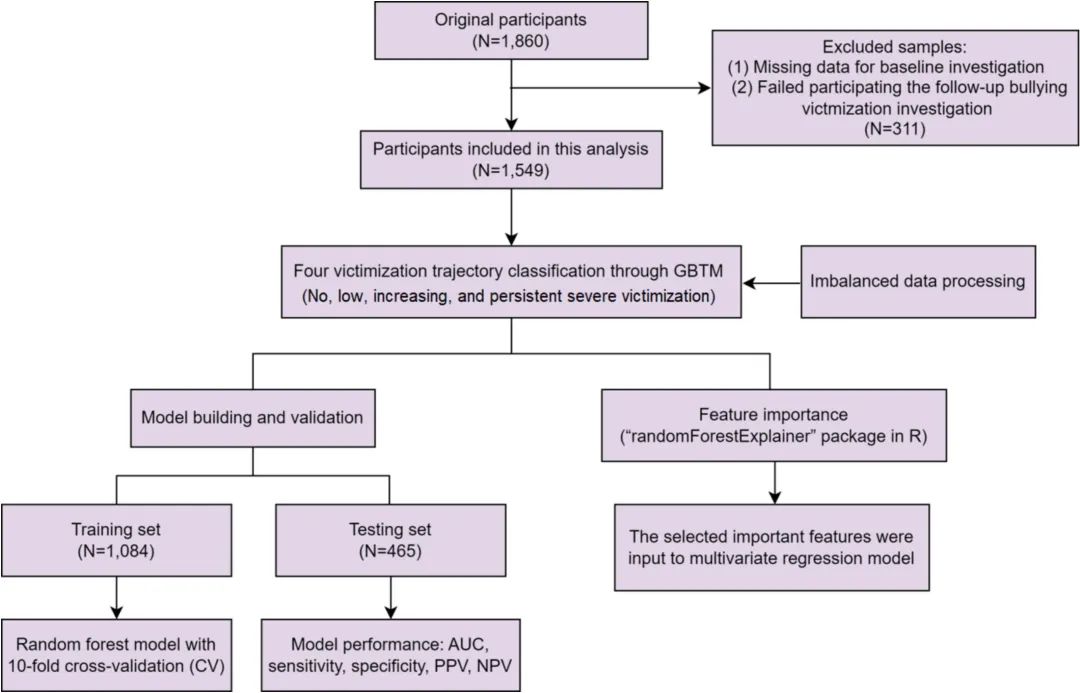
研究团队基于以往的研究实践,纳入2019年至2021年收集的三波数据,使用GBTM识别欺凌受害者轨迹的变化。
研究结果显示,4组的GBTM模型最佳,BIC(-6803.29)最低。
在填补完缺失数据后,数据被随机分为训练集(70%)和验证集(30%)。
研究团队基于随机森林法(RF)构建受害者轨迹的预测模型,并用多个指标评估模型性能。- 评估指标包括准确性、灵敏度、特异性、阳性预测值(PPV)、阴性预测值(NPV)和ROC曲线下面积(AUC)。
研究结果表明,基于RF构建的预测模型在区分不同受害轨迹方面表现出理想的性能,所有组均达到AUC >0.8。
√可视化工具:使用"randomForestExplainer"包可视化RF模型中重要特征。√多维度评估:用多个指标从不同角度评估特征重要性(包括节点数量、平均最小深度、准确度下降、基尼系数下降、Xj用于分割根节点的频率(times_a_root)以及p值)。下图展示了RF模型中最重要的十个特征,其中前五个关键预测因素为敌意、边缘性人格、易怒、在校不良经历和学校满意度。
图3 对于重要的变量,最小深度在森林图中的分布
多向重要性图结合了准确性降低指标和基尼系数降低指标,进一步证实了10个关键预测因子在预测欺凌轨迹方面的重要性。
图4 多向重要性图分析结果(结果可见粉红色圆圈;P< 0.01)
值得一提的是,尽管“randomForestExplamer”包提供了功能交互分析,但在该项研究结果中,我们并未在变量之间观察到显著的交互作用。
研究团队进一步使用多元逻辑回归分析,评估了RF模型识别的关键预测变量对四种欺凌轨迹的贡献。研究结果显示,预测因素在不同的轨迹亚组中表现出不同的影响。
与低受害组相比,持续严重受害组不仅年龄更大,而且边缘性人格特征更显著以及更加易怒,同时他们对学校的满意度相对较低;
相反,同伴满意度的降低则与欺凌受害轨迹的增加负相关;
此外,学校中的不良经历与持续严重欺凌受害之间的关联最为紧密,这些不良经历使得个体遭受持续严重欺凌的可能性增加了约2.7倍。
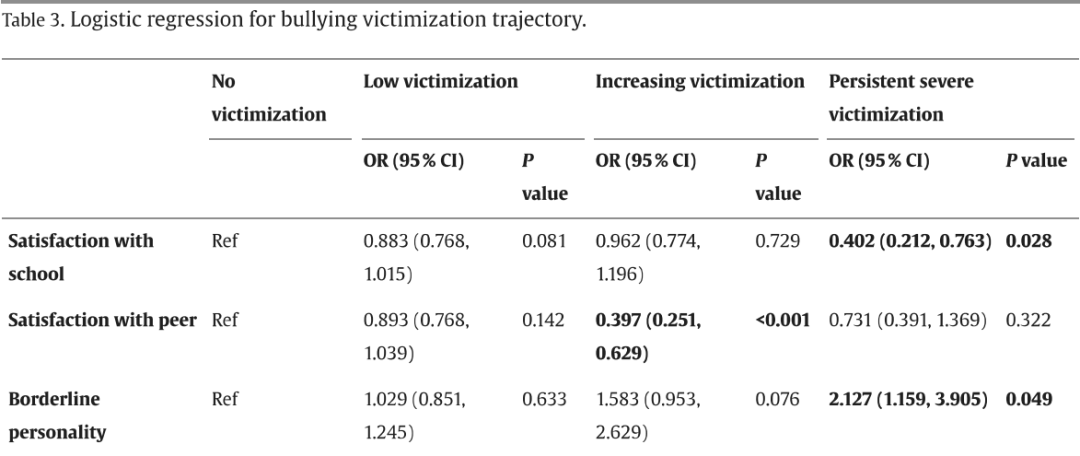
 图5 欺凌受害轨迹的逻辑回归结果
图5 欺凌受害轨迹的逻辑回归结果
综上所述,研究表明,由于欺凌程度发展的差异,其导致的严重后果在个体之间差异很大。此外,某些受害者特征,如不受欢迎和同伴排斥,可能会限制一般干预措施的有效性,因为这些特征降低了接受同伴支持的可能性,并导致持续的受害。研究团队认为,我们仍需要进一步的研究,区分欺凌发展的模式,并确定与每种模式相关的具体风险和保护因素。
说实话,我不是那么苟同这种数据分析的过程,我们构建预测模型的时候,结局一般是金标准或者硬终点才合适。而这项研究的终点就是数据驱动下,利用轨迹模型做出来的,结局的分类就是不可靠的,预测它实在有点牵强。不过,有一点还是可以肯定的,用随机森林的方法去分析,影响轨迹的因素,哪个最重要。并在此基础上,开展logistic回归分析,计算OR值。但问题又来了,随机森林评估哪个因素最重要是以一种非线性的地方式,而logistic是线性分析的结果,两者一致吗?
但是,总的来说,这年头只要你把数据分析玩出花来,文章还真不错。乱花渐欲迷人眼,这两年流行方法机器学习、轨迹模型一结合,虽然看起来四不像,还真的图文并茂,学术研究的探索性魅力,就在于此。公众号后台回复关键词“pdf”,即可获取原文!更多关于临床预测模型与机器学习统计服务,请联系郑老师团队,助教微信:sas555777











