CLIP(Contrastive Language-Image Pretraining)作为视觉-语言模型的代表,通过大规模图像-文本对比学习成功将图像和文本映射到共同的嵌入空间,在零样本学习(Zero-Shot Learning, ZSL)任务中表现出色。然而,当CLIP应用于小样本学习(Few-Shot Learning, FSL)时,其预测的logits存在严重的类间混淆(Inter-class Confusion)问题,导致分类准确率下降。😏
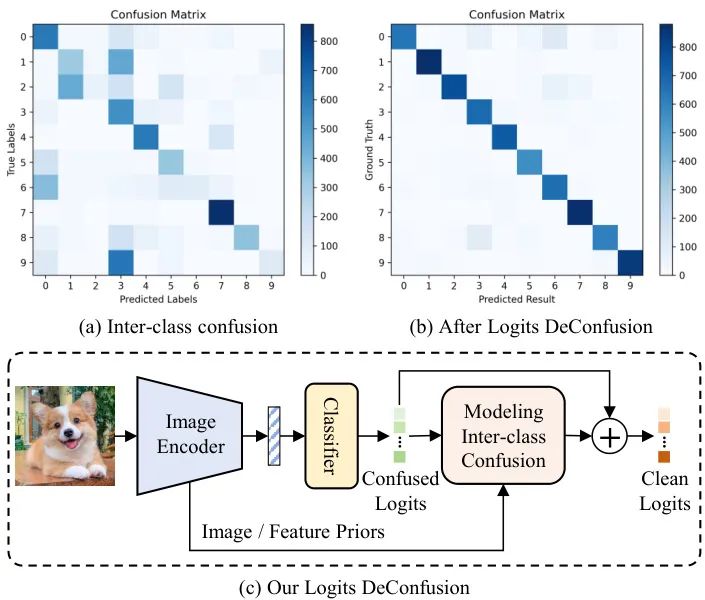
西安电子科技大学的研究团队提出了Logits DeConfusion(LDC)方法,通过多级适配器融合模块(MAF)和类间去混淆模块(ICD)的联合设计,有效缓解了CLIP在小样本学习中的类间混淆问题。该方法不仅保留了CLIP丰富的特征表达能力,还显著提升了分类性能。
CLIP通过对比学习在大规模图像-文本对上预训练,而非直接优化分类边界,这使得其在零样本学习中表现出色。然而,当应用于小样本学习时,由于下游数据与预训练数据的领域差异,以及类别间相似性较高的情况,CLIP的logits会出现明显的类间混淆现象。
类间混淆的表现:不同类别的预测值难以准确区分,特别是在类别相似度较高时更为明显。
主要原因:CLIP的预训练策略未直接优化分类边界,导致在分类任务中区分能力不足。
Logits DeConfusion方法:如何消除类间混淆?
LDC方法的核心思想是通过可学习模块建模并消除logits中的类间混淆。具体来说,该方法假设logits中的类间混淆可以表示为一个额外的噪声项Δs:
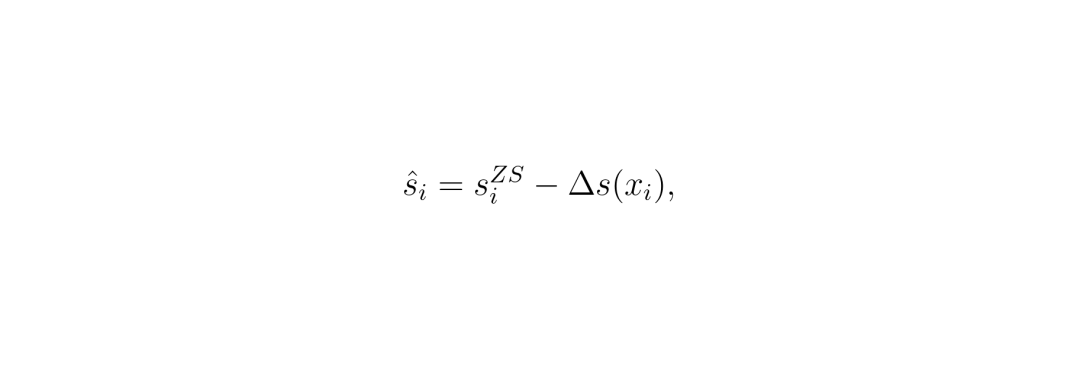
其中噪声项Δs通过一个可学习模块EΔ从零样本logits和图像特征中学习得到。
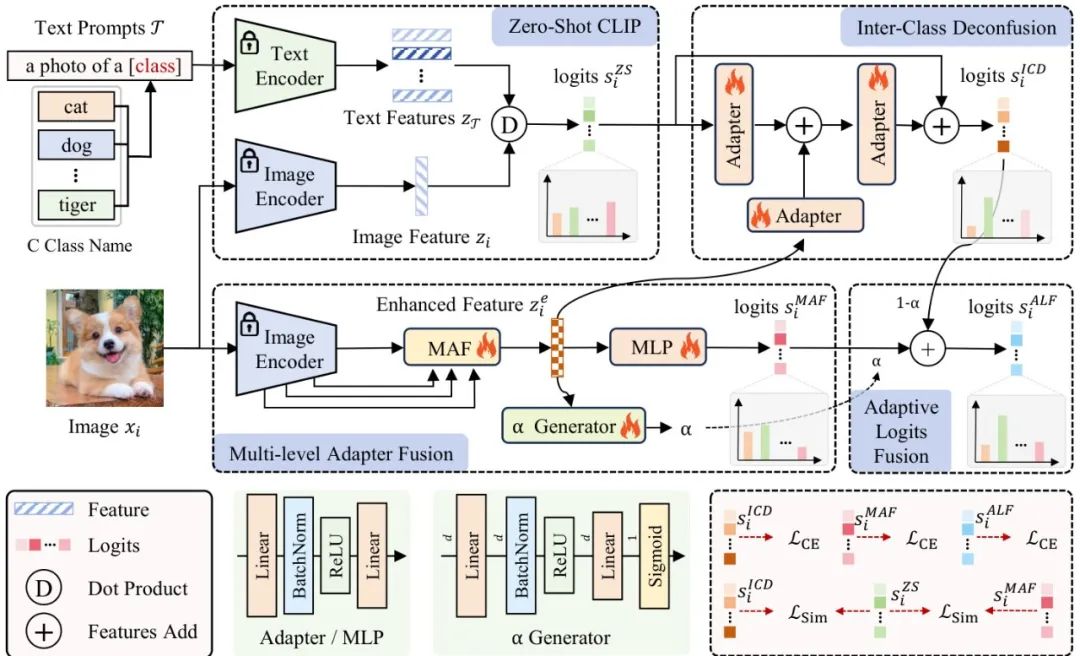
ICD模块:通过残差结构学习和消除类间混淆模式,同时引入增强特征作为先验指导。
ALF模块:自适应地融合ICD logits和MAF logits,生成更鲁棒和准确的最终logits。
MAF模块旨在充分利用CLIP图像编码器不同层次特征的多样性,通过转换和融合不同层次的特征,构建统一的特征表示。MAF包含多个侧边适配器、融合机制和投影器。
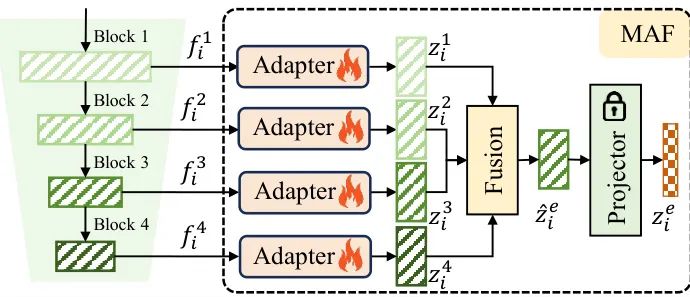
特征提取:从图像编码器EI获取四个不同层次的特征f1i,f2i,f3i和f4i。
特征转换:通过不同的适配器将这四个特征转换为新的特征z1i,z2i,z3i和z4i。
特征融合:通过融合机制将这些特征融合为一个融合特征ẑei,最终通过冻结的投影器得到增强特征zei。
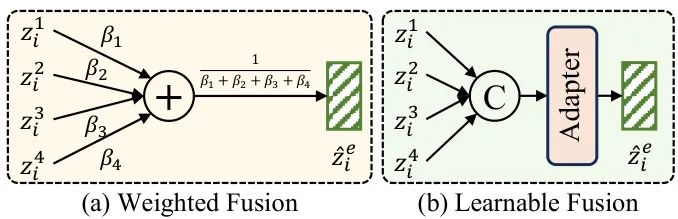
MAF提出了两种不同的融合机制:加权融合(WF)和可学习融合(LF)。实验表明,加权融合(β1=0.1,β2=0.2,β3=0.3,β4=0.4)取得了最佳效果。
ICD模块的设计灵感来源于一个简单但深刻的观察:CLIP的logits混淆本质上是可预测的噪声。就像老式电视机信号干扰有特定模式,不同类别间的混淆也存在固定规律。😮
残差去噪结构:ICD将原始logits看作"干净信号+噪声"的组合:
其中Δs就是需要学习的类间混淆噪声。这个设计妙在:即使噪声预测有偏差,残差结构也能保证结果不会比原始logits更差。
双路信息融合:ICD不是闭着眼睛猜噪声,而是同时分析两类线索:
1. logits自身模式:通过Adapter分析原始logits的分布规律
2. 视觉特征引导:用MAF提取的增强特征作为先验知识
最终三个Adapter的输出通过残差连接实现噪声消除:
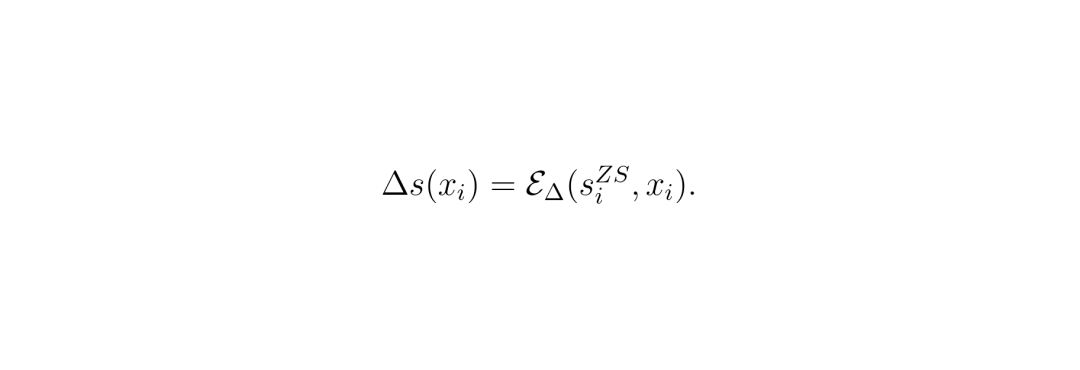
在11个主流数据集上的测试表明,LDC方法在小样本场景全面碾压现有方案。当每类只有16个样本时:
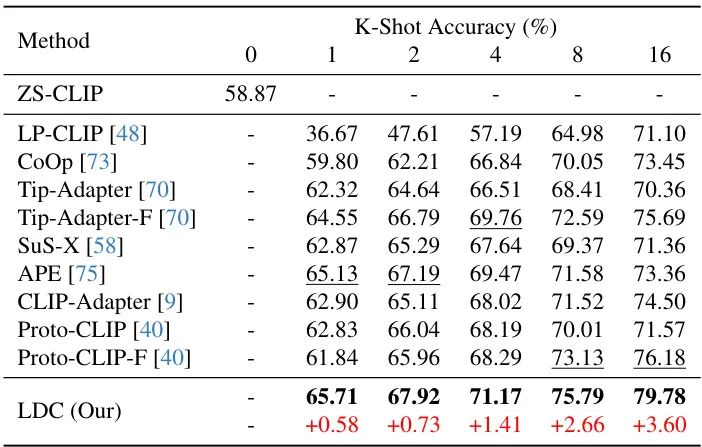 LDC以79.78%的平均准确率刷新纪录,比第二名Tip-Adapter-F高出3.6个百分点。更惊人的是在StanfordCars细粒度分类数据集上,相对优势达5.2%!🚗
LDC以79.78%的平均准确率刷新纪录,比第二名Tip-Adapter-F高出3.6个百分点。更惊人的是在StanfordCars细粒度分类数据集上,相对优势达5.2%!🚗
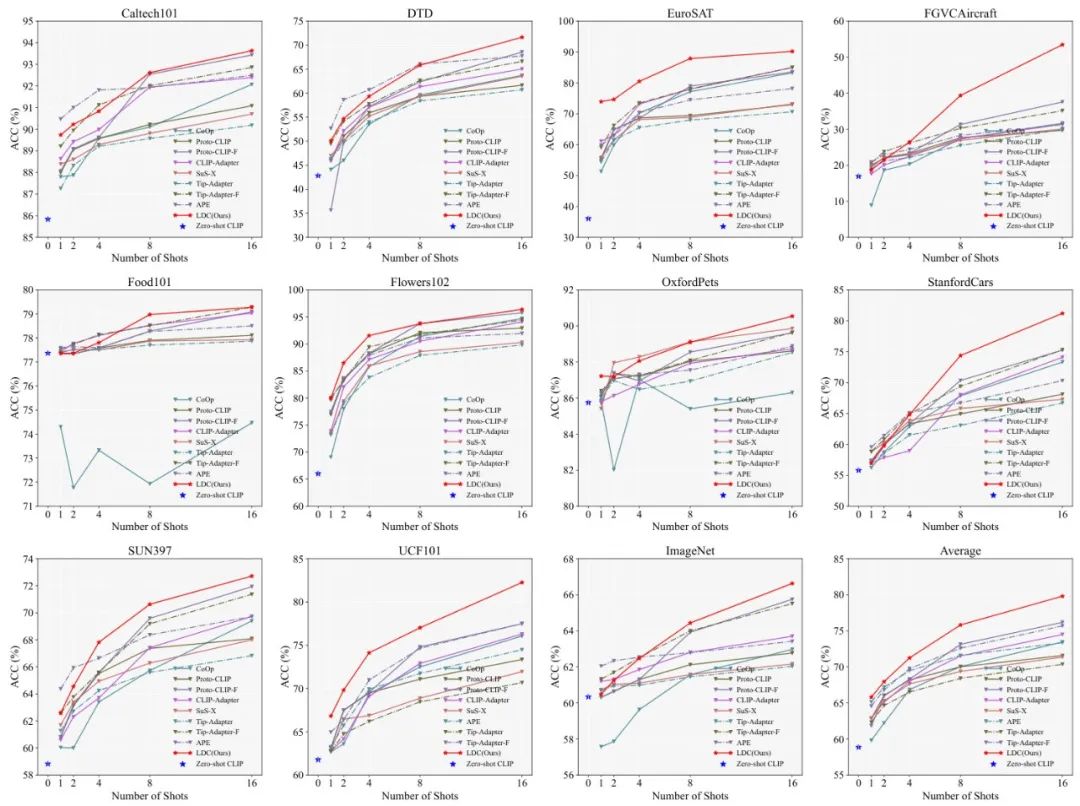
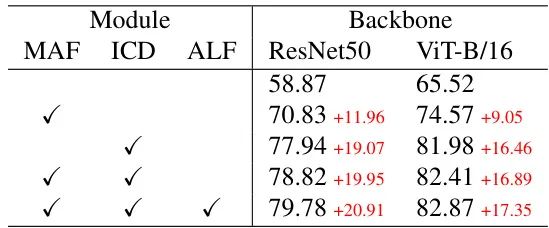 仅ICD模块就让ResNet-50 backbone性能飙升19.07%,证明去混淆机制是小样本学习的关键突破点。
仅ICD模块就让ResNet-50 backbone性能飙升19.07%,证明去混淆机制是小样本学习的关键突破点。
领域泛化挑战:但在ImageNet-Sketch上的测试暴露了局限:
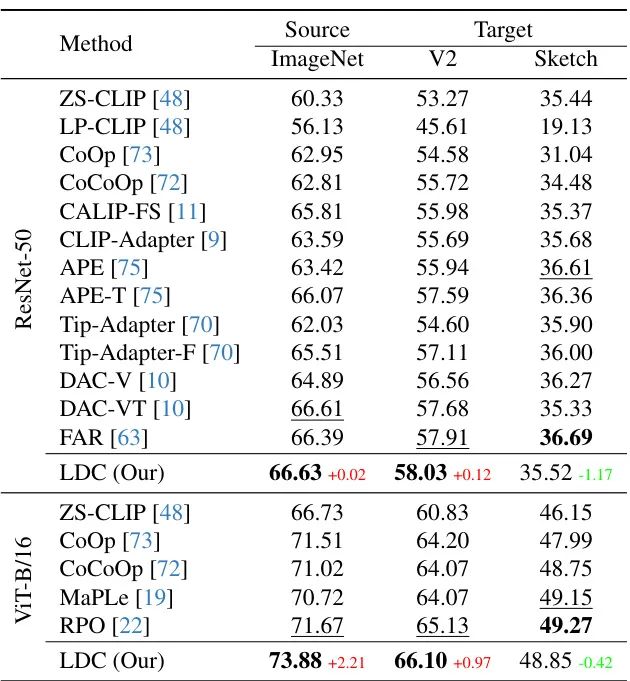 当测试数据与训练集差异过大时(如素描图像),性能下降1.17%。这说明模型仍过度依赖视觉纹理特征,对结构特征理解不足。🎨
当测试数据与训练集差异过大时(如素描图像),性能下降1.17%。这说明模型仍过度依赖视觉纹理特征,对结构特征理解不足。🎨
未来展望:Logits DeConfusion的潜在应用与发展方向
医疗影像诊断:针对罕见病的小样本识别,可解决不同病症CT影像的相似性混淆问题
工业质检:适应新产品缺陷样本不足的场景,精准区分表面划痕与材质纹理
跨模态检索:提升图文匹配精度,解决"沙滩与沙漠"等易混淆场景
动态噪声建模:当前混淆模式学习是静态的,可引入时序建模适应数据漂移
多模态增强:融合文本描述信息辅助混淆判断,比如利用"企鹅不会飞"的常识约束
轻量化部署:将适配器参数量压缩90%+,适配移动端设备
为什么传统方法解决不了类间混淆?CLIP的对比学习预训练没有显式优化分类边界,就像用渔网捞鱼,类别间隙处的"漏网之鱼"特别多。本文首次提出将混淆建模为可学习的噪声模式。
残差结构有什么妙处?即使噪声预测不准,最差情况也只是Δs=0,结果退回原始logits,相当于内置了性能保障机制,避免越优化越差的风险。
实际部署需要多少资源?在NVIDIA GTX 4090D上训练16-shot任务仅需37分钟,推理阶段增加的MAF和ICD模块计算量不足CLIP主干的3%,适合实时应用。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~
论文创新性分数:★★★★☆
首次将logits混淆建模为可学习噪声,残差设计体现工程智慧
实验合理度:★★★★★
11个数据集+OOD测试,消融实验完整覆盖所有模块
学术研究价值:★★★★☆
开辟CLIP微调新方向,启发性大于实用性
稳定性:★★★☆☆
在领域差异大的场景波动明显,需结合领域自适应技术
适应性及泛化能力:★★★★☆
在细粒度分类场景表现突出,但艺术类数据较弱
硬件需求及成本:★★★★★
仅增加0.3M参数,推理速度媲美原版CLIP
复现难度:★★★★★
代码已开源,提供完整训练脚本和预训练模型
可能的问题:未探索混淆模式的可解释性,论文中混淆矩阵可视化不足,难以分析哪些类别容易相互混淆
[1] Radford A, et al. Learning transferable visual models from natural language supervision. ICML 2021.
[2] Zhang R, et al. Tipadapter: Training-free adaption of clip for few-shot classification. ECCV 2022.
[3] Zhou K, et al. Learning to prompt for vision-language models. IJCV 2022.
[4] Wu G, et al. Feature adaptation with clip for few-shot classification. ACM MM Asia 2023.
恭喜你!你又跟着龙哥读完了一篇人工智能领域的前沿论文,棒棒哒!
 *本文仅代表个人理解及观点。想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文"查看更多原论文细节哦!
*本文仅代表个人理解及观点。想了解更多原文细节的小伙伴,可以点击左下角的"阅读原文"查看更多原论文细节哦!

龙哥带你飞,论文轻松读!如果觉得对你有帮助,请积极关注、推荐(点小心心)或者转发哦~

更多算法或者行业讨论,欢迎加入龙哥读论文粉丝群,扫描上方二维码,或者添加龙哥助手微信号加群:kangjinlonghelper, 一定要备注:研究方向+地点+学校/公司+昵称(如 图像处理+上海+清华+龙哥),根据格式备注,可更快被通过通过且邀请进群: 1478篇去噪、调光、大语言模型等前沿论文原文免费送!








