本文内容整理自医咖会《机器学习在医学研究中的应用案例实战教学》专栏,小咖针对其中的机器学习建模流程相关内容进行了整理,可点击左下角“阅读原文”查看完整视频。
推荐以下五个维度来获取选题灵感:临床实践、同行交流、文献阅读、理论支撑、基金指南(政策导向),也可以从研究设计,也就是PI(E)COS的五个角度帮助寻找创新性的选题。
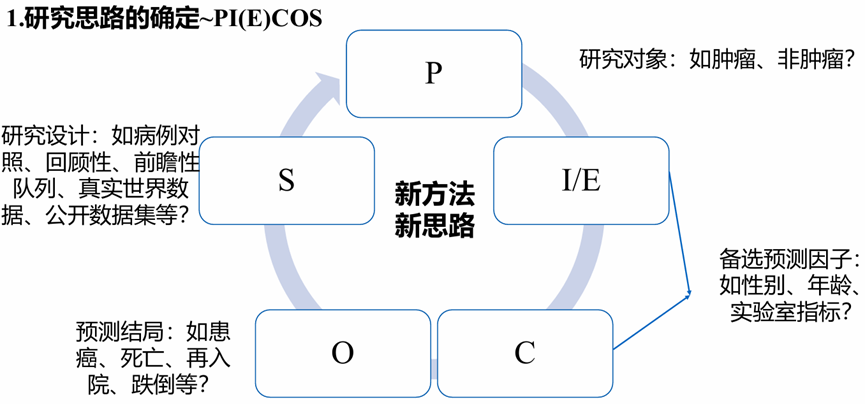
图. PI(E)COS
当前临床预测模型的建模分为两大类:
诊断模型:预测当前患某病的风险,往往用横断面研究和病例对照研究;
预后模型:预测未来一段时间内发生特定预后事件的风险,往往用队列研究和回顾性、前瞻性研究。
数据采集有五种方法:
A.自行设计问卷,开展调查,收集数据;
B.查阅病案,批量查找和导出数据;
C. 其他信息系统测量的数据,如ICU监护仪,可穿戴设备等
D. 申请临床公开数据库、大型专病队列,数据竞赛网站公开数据集。
 图.各领域的国内外数据库
图.各领域的国内外数据库
拿到数据后需要对数据进行预处理,一般需要进行变量转换、缺失值处理和异常值检测。推荐大家收集原始数据时尽量收集连续型数据,可以灵活转化为多分类和二分类变量。
预处理之后,需要进行变量筛选,比较常规的筛选方法有:单因素筛选、多因素逐步回归、LASSO回归、其他机器学习算法(如随机森林的变量重要性排序)。
机器学习较传统回归的一个不同之处是需要做超参数的调优,如随机森林有两个超参数, ntree(要建立多少树模型进行预测)和mtry(一个树模型从变量值中随机抽取几个变量来建立决策树),而调优后需要使用调优指标评估,选取最优的超参数,比如分类模型可以使用AUC和分类准确率。
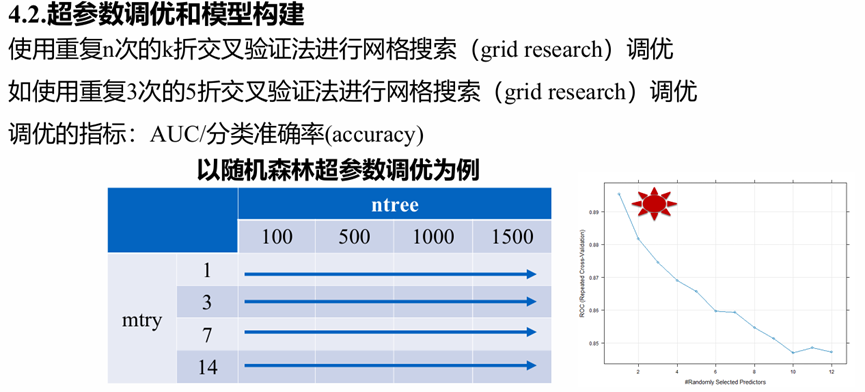
图.超参数的调优
模型评价、验证和比较指标包括:
区分度:AUC和ROC曲线,也可以包括灵敏度、特异度、分类正确率等指标;
校准度:Brier评分和校准曲线;
临床实用性:DCA曲线。

图例.模型评价、验证和比较指标
可以考虑多种方式进行模型的呈现:
A.OR/HR/B或森林图
 图例.Logistic回归模型的森林图
图例.Logistic回归模型的森林图
B. 评分表(根据OR/HR/β进行打分,四舍五入取整数,或者X5\X10翻倍)
C. 列线图(也是一种更直观的评分表)
 图例.列线图
图例.列线图
D. 网页计算器(便于在线应用)
 图例. 网页计算器
图例. 网页计算器
E. 决策树等(也非常直观)
 图例.决策树
图例.决策树
还有一些集成模型,比如随机森林不可能将每一棵树的决策过程都呈现出来,一般会对树的结果进行整合,根据变量重要性进行排序(左图)。对于黑箱模型这类无法解释的模型,支持向量机比较抽象,可以采取一些新的可解释的技术,如SHAP、LIME等,右图利用LIME进行解释,第一行为平均风险,下面为变量特异性取值时的风险。
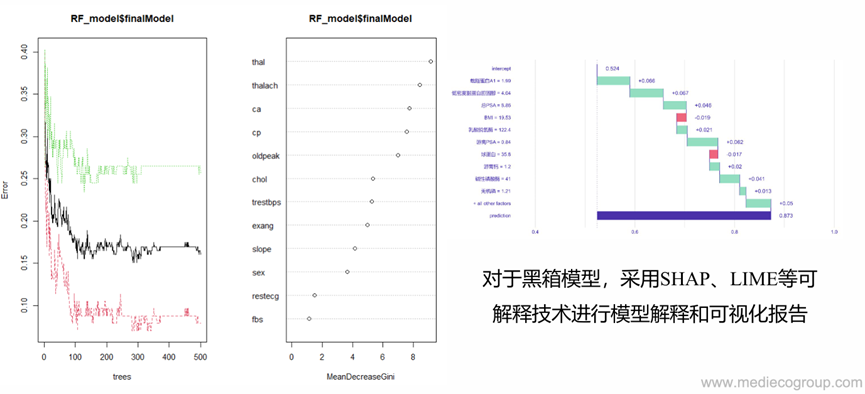
图.随机森林变量重要性排序(左)和LIME解释黑箱模型(右)
上文内容摘自医咖会专栏课程《机器学习在医学研究中的应用案例实战教学》,请点击左下方的“阅读原文”,观看完整视频内容。











