总结:
RecIS是一个专为超大规模稀疏-稠密计算设计的统一架构深度学习开源框架,由爱橙科技智能引擎团队与淘天集团算法技术、阿里妈妈技术团队联合推出。该框架基于 PyTorch 开源生态构建,为推荐模型训练,或推荐结合多模态/大模型训练提供了完整的解决方案,已在阿里巴巴广告、推荐、搜索等场景广泛应用。
Github地址:https://github.com/alibaba/recis
技术报告:http://arxiv.org/abs/2509.20883
1. 背景目标
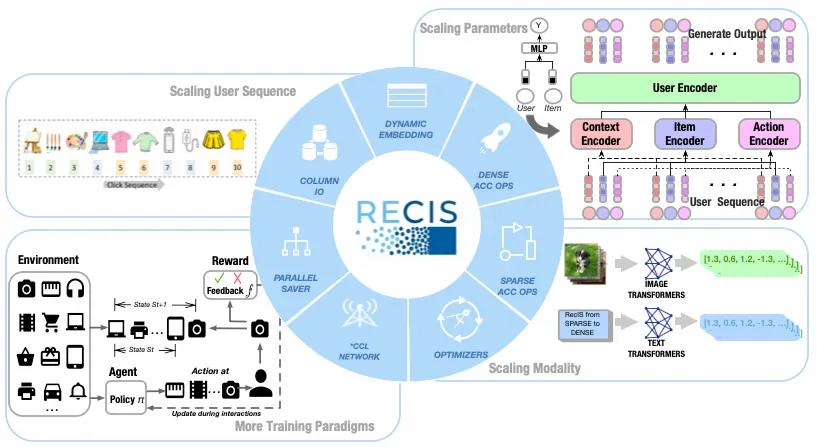
现代推荐系统正经历一场由 “ScalingUp” 趋势驱动的范式转变,转变体现在数据量和计算能力两个维度。在数据层面,规模化不仅意味着延长用户行为序列的长度,还要求显著增加训练样本的总量。在计算层面,算法正逐渐从传统的多层感知机(MLP)架构转向基于 Transformer 的模型;后者因其卓越的可扩展性以及对大规模序列数据更强的表征能力,已成为新一代推荐系统的核心架构选择。
这种算法架构的变化,正在推动推荐架构演变为一种稀疏-稠密混合模式:稀疏部分负责大规模特征处理和Embedding计算,构建基础表征;稠密部分是处理Embedding表征的深度神经网络,如Transformer或其他复杂计算结构。
系统上,工业级推荐系统长期依赖于 TensorFlow,它在稀疏部分的功能和性能优化有较多的工作积累,以及生产稳定性有着成熟的支持;但在易用性上有明显的不足。学术界越来越倾向于 PyTorch,尤其是AI领域内已形成 Pytorch 主导的生态闭环。然而,PyTorch 生态在对生产大规模稀疏训练的功能支持,以及性能方面,尚未完善。
针对以上背景,我们开发了RecIS(
Recommendation Intelligence System),目标:
统一框架,基于PyTorch生态形成统一的稀疏-稠密训练框架,满足工业级推荐模型结合多模态、大模型的模型训练需求。
系统优化,稀疏部分面向访存优化,超越基于Tensorflow的推荐模型性能。稠密部分借助现有的Pytorch生态的优化技术。
2. 系统设计
以下从算法框架和系统优化两个方面,介绍具体的设计方案。
2.1 算法框架
在框架层面,为了支持工业级稀疏训练,满足超大规模Embedding等算法需求,我们迁移了XDL上的训练组件;这部分迁移同时也保留了一定的兼容性:之前基于Tensorflow训练的模型参数,以及超参配置可以被新的迭代继承。
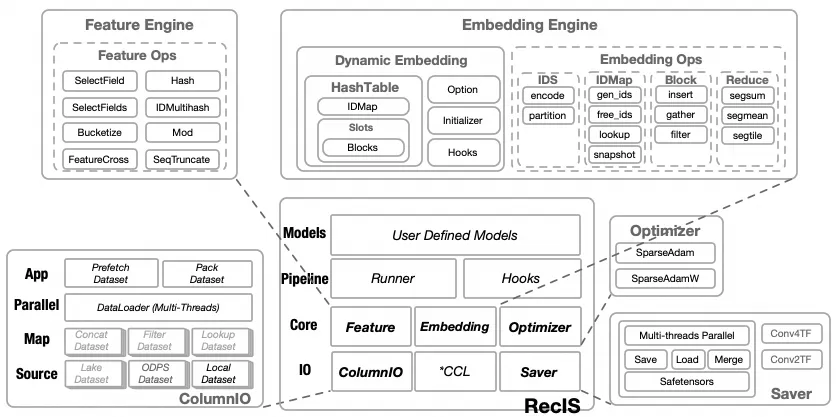
1) ColumnIO
数据读取和预处理;在分布式训练任务中,每张 GPU 负责处理一部分数据。ColumnIO 组件能够从分布式文件系统中,按分片高效地读取多列样本。它在数据读取阶段完成简单的预计算,并将样本组装成 PyTorch Tensor,以供后续的训练使用。
数据类型与结构: 支持基础类型Double Float Bigint String
,基于基础类型的嵌套List处理单值、多值和序列特征。同时,支持平铺特征以及按特定维度(如用户 ID)聚合的特征。
数据源: 支持多种表类型,包括天级批处理的静态表和秒级实时处理的动态流样本。此外,还支持多模态特征的点查连接(Point-lookup Join)。
生产环境支持: 在阿里云生产环境中,ColumnIO 可直接读取阿里云分布式文件系统(DFS)的数据,包括直读集团数据湖,通过OpenAPI高效直读ODPS数据表,或通过ALake Proxy 或 ODPS Tunnel在多云环境中读取。
2) Feature Engine
该组件支持在训练阶段对特征进行预处理,为特征工程提供一定的灵活性。
特征转换: 将字符串特征通过哈希转换为 ID 类型。
3) Embedding Engine
该组件管理所有特征对应的embedding结构,底层提供了一个无冲突、可扩展的 KV 存储方式的 Embedding 表(Hashtable)。
此外,它还支持在持续训练过程中淘汰过期的特征,并为稀疏存储的 Embedding 提供高效的计算操作和对应的优化器更新。
4) Optimizer
Hashtable的优化器实现,包括SparseAdam和SparseAdamW,保持了和Tensorflow上的兼容性。
5) Saver
与稀疏部分相关的模型参数都以 SafeTensors 标准格式进行加载和存储,同时也以此格式作为在线推理服务的交付格式。Saver主要是进行了并行的分片优化,极大提升了超大规模稀疏、稠密参数的读写性能。
6) Pipelines
该组件串联起上述多个组件,对训练流程进行封装。它支持多阶段(训练与测试交错)、分窗口在线学习和多目标训练等复杂的训练流程。
| 功能 | XDL(Tensorflow) | TorchRec(pytorch) | RecIS |
|---|
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
2.2 系统优化
稀疏+稠密混合训练会遇到三堵"墙";由于训练范式变化,导致其训练的性能瓶颈,往往最后才是计算,而由于推荐引入的IO和访存往往更先成为利用硬件计算性能的阻碍。
IO Wall:推荐模型需要不断学习大量的数据,来拟合数据的分布变化,以及优化冷启动问题。对于电商的推荐任务,每天需要消费多达百亿的样本,这对系统的IO和样本处理能力是一个巨大的挑战。只有充分优化IO,训练才能获得充足的数据供给,而有机会充分使用硬件。
Memory Wall:稀疏部分(Embedding),是典型的访存密集型(Memory-bound)计算。从特征处理,到ID去重,从Embedding查询,到Embedding计算,所有的处理都依赖高效访存。我们用MBU(Model Bandwidth Utilization)来衡量稀疏部分的性能。
-
Computation Wall:稠密部分(例如大模型),一般是计算密集型的,其性能一般取决于硬件的计算性能。由于Pytorch在大模型上优化的积累,这一部分一般是被充分优化的,可以复用现有的大模型技术。一般用MFU(Model FLOPS Utilization)来衡量稠密部分的性能。
1) IO优化
读样本(IO)阶段,预期是样本能够充分供给GPU训练计算,读样本的延迟能够被训练延迟掩盖。具体而言有多个优化目标:a. 样本存储压缩率高;b. 读样本数据吞吐尽量高;c. 处理样本效率高。这主要包括以下优化:
【存储layout - 列存】
列存样本是按列顺序优先存储,由于训练本身就是各列组装成多个Tensor 进行批量计算的,列存样本节省了组装过程从行中拷贝的工作,而且可以通过存储端"选列",无代价的满足筛选特征的需求,非常适合作为推荐模型的存储结构。另外按列存储有更好的压缩比,一方面释放了更大的容量空间,一方面也减轻了网络带宽的压力。
【高并发&异步】
在训练进程内部,通过多线程高并发读取分片数据,压榨分布式存储性能;相比torch的python多进程dataloader,C++多线程的性能更高,对GPU Lauch的影响也更小;我们通过异步化,使IO和训练同时进行,隐藏读样本的延迟。
【内存layout - CSR】
和Tensorflow的SparseTensor(COO)相比,RaggedTensor(CSR)的存储表达更高效,特别是对于超长序列特征。
【GPU打Batch】
在一些对IO性能要求极致的场景,我们还提供GPU组装Batch的能力,一方面充分利用GPU访存,一方面可以在多线程中提前进行高效的CPU->GPU拷贝。
2) 访存优化
推荐模型的稀疏部分通常是典型的访存密集型(Memory-bound)场景,我们必须对关键路径上的访存效率进行深入优化。这主要包含以下几个核心策略:
【GPU Hashtable】
过去,我们曾采用一种异构计算架构:仅将模型的稠密部分计算和Embedding 计算放在 GPU 上,而将样本解析和 Embedding 参数存取等任务留在 CPU 上。
这种设计当时主要基于两点考量:
显存节省: 推荐模型庞大的 Embedding 参数量会消耗大量显存,将它们放在 CPU 上可以为 GPU 腾出更多显存,供稠密计算使用。
-
异构并行: 这种架构能够利用 CPU 和 GPU 的并行性,例如让样本读取与模型训练并行,或让 CPU 上的 Embedding 存取与 GPU 上的计算并行。
然而,在当前的硬件发展趋势下,这种架构已显得过时。随着GPU本身硬件发展,以及单机多卡(8 卡或更多)成为主流配置,GPU 的访存带宽相较于 CPU 已是两个数量级的提升。同时,GPU 的显存容量也在持续增加。如下图GPU/CPU卡均带宽所示。
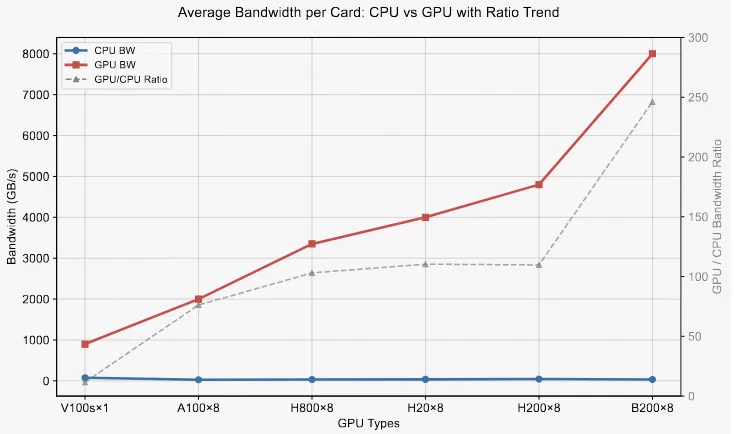
因此,为了充分利用这些新硬件的性能潜力,我们必须转变策略:尽可能将所有高访存需求的任务都迁移到 GPU 上,以最大化利用其巨大的带宽优势。
RecIS 框架通过一种两级存储架构实现了高效的动态嵌入(HashTable):
IDMap:作为第一级存储,它以特征 ID 作为键(key),以偏移量(offset)作为值(value)。
Blocks:作为第二级存储,它是一组连续分片的内存块,用于存储嵌入参数(如 float 类型)及其对应的优化器状态。Blocks 支持动态分片,可实现灵活扩展。
工作流程:
前向计算: 模型通过一次 IDMap 查询(lookup),根据特征 ID 快速定位到 Blocks 中的对应偏移量。随后,根据该偏移量直接读取相应的嵌入向量。
反向更新: 在反向传播时,系统会根据计算得到的嵌入梯度和前向计算中保留的偏移量,直接更新 Blocks 中对应的优化器状态和参数值。
offload策略:
当前主流的多卡训练环境下,GPU 显存通常比较充足。在这种情况下, IDMap 和 Blocks 都可以存放在 GPU 显存中,充分利用 GPU 的高带宽优势,从而显著提升性能。
然而,在显存受限的场景下,为了节省 GPU 显存,可以灵活地将 IDMap 或 Blocks 回退到 CPU 内存进行存储。这种设计确保了框架在不同硬件配置下的灵活性和普适性。
【负载均衡】
在推荐系统中,人工特征工程是提升模型效果的关键。在阿里巴巴的电商场景中,模型的特征列多达上千个,每个特征都对应着庞大的稀疏 Embedding 参数。为了防止性能热点,这些稀疏参数必须在空间存储和访问量两个维度上实现均匀分布。
为此,RecIS 采用了聚合与全切分(aggregation and full sharding)的策略:
参数聚合与分片: 在模型加载阶段,我们会将具有相同维度(embedding dimension)的参数合并成一个大的逻辑表(table),并将其均匀地分发到多张 GPU 卡上进行存储。
请求合并与全切分: 在前向计算时,我们同样会合并相同维度的 Embedding 请求。在去重(unique)处理的同时,这些请求也会根据其 ID 进行分片。随后,通过集合通信(collective communication)中的 All-to-All 算子,每一张卡都能从其他卡高效地获取所需的 Embedding 向量。
梯度更新: 在反向传播时,我们同样利用 All-to-All 通信,在不同卡上同步更新 Embedding 参数和优化器状态。
这种设计的核心优势在于,当合并后的去重 ID 数量非常大时,根据大数定律,它们的哈希分桶结果趋向于均匀分布。这种固有的均匀性,从根本上确保了稀疏参数在多卡上的负载均衡,从而显著提升了训练效率和性能。
【最大化MBU】
为了使稀疏训练的整体性能逼近访存瓶颈,我们必须确保关键路径上的每一个算子都能最大化其访存利用率。我们的优化主要集中在以下四个方面:
稀疏计算并发优化
推荐模型因其稀疏性和复杂的特征工程,导致样本输入、特征处理以及 Embedding 计算往往包含数百个大小不一的特征列。其中,有的列可能为空,而有的则包含多达十万个特征 ID。这种巨大的规模差异带来了双重挑战:
过多的 Python 操作:每个独立的小算子都对应着一次 Python 调用,导致大量的开销。
低效的 GPU 并行:GPU 难以高效地并行执行如此多、且大小不一的计算核(kernels)。
为此,RecIS 采取了算子融合(kernel fusion)策略,从水平和垂直两个维度进行优化。我们根据计算类型和维度对算子进行分类,并将前后可融合的算子进行打包。通过这一系列操作,我们将模型中成千上万个小算子成功融合为十几个大型算子。这不仅有效减少了启动开销,还显著提升了 GPU 的并行效率。
Embedding 合并访存
除了合并稀疏计算,Embedding 的访存也可以融合。实践中我们观察到,绝大多数特征通常使用相同的 Embedding 维度(如 8、16、32 、64或128)。基于这一特性,Embedding Engine 会自动对维度相同的 Embedding 进行合并优化。这一机制显著减少了模型所需的独立访存操作次数,并大幅提升了内存空间的利用效率,从而有效降低了整体计算和存储成本。
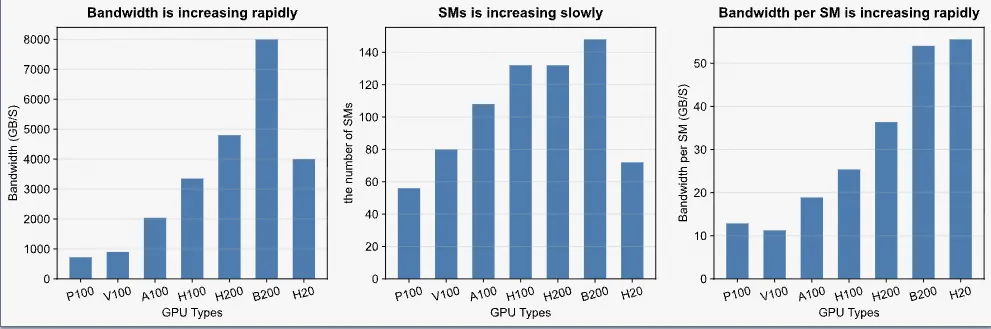
向量化访存
随着硬件的不断发展,GPU 的显存带宽持续提升,而每个流多处理器(SM)的带宽增速更为显著。这意味着,在新的架构上,若要充分利用显存带宽,每个 SM 必须处理更多数据。例如,相较于 H100,H20 需要更高的 "bytes-in-flight" 才能打满显存带宽,这一需求与 B200 基本持平。
因此,我们的访存策略必须适应这些新硬件的特点,通过向量化等技术提高数据加载的并行度,确保每个 SM 都能高效地从显存中读取数据,从而最大化整体的访存吞吐量。
在推荐模型中,多处涉及 Sparse Reduction 操作。例如,在 Embedding 计算中,多值特征对应的 Embedding 向量通常会通过 Sum 或 Mean 等操作进行池化(pooling),形成一个稠密张量以供后续网络计算。
由于稀疏张量固有的变长特性,这类 Reduction 操作难以进行高效合并。因此,开发者通常会直接采用 atomic_add 等原子操作。然而,这会引发内存碰撞(collision),导致访存效率低下。
为解决这一问题,我们发现,在 Sparse Reduction 中,相邻的 Embedding 向量更有可能进行 Reduction。基于这一观察,RecIS 采取了新的优化方案:通过Warp 级别合并,结合向量化访存,来减少原子操作的碰撞,从而提升访存效率。
3)大模型优化
在推荐系统与大模型结合的训练中,大模型部分通常是计算密集型。为充分发挥计算单元的利用率,我们主要借力于当前 PyTorch 生态中成熟的大模型优化技术,包括但不限于以下几点:
-
混合精度计算(Mixed Precision Training):一般对稀疏计算部分使用FP32精度,对稠密Attention部分使用FP16/BF16精度,在保证模型收敛精度的前提下,显著提升训练速度并减少显存占用。
融合算子(Fused Kernels):如FlashAttention 以及 FusedSoftmaxCrossEntropy等。
ZeRO: 通过对稠密部分模型状态(如参数、梯度和优化器状态)进行分片,显著降低每张卡的显存消耗,从而支持更大模型的训练。
3. 性能测试
3.1 算子性能
RecIS利用算子融合,向量化访存,原子操作优化等技术提升Sparse计算中的计算效率。下表展示了几个标志性算子分别在 Tensorflow, Pytorch 和 RecIS 框架下,H20上的表现。我们采用MBU指标来评价算子整个执行时间的效率。
1)算子融合
-
Bucketize / Mod:在稀疏模型中会出现几十甚至上百个同类型的这类算子。顺序的执行这些算子会带来严重的GPU调度开销。RecIS将多个同样类型的算子融合成一个来提高GPU的效率。我们的实验中模拟了100路含有10000个值的特征作为输入进行比较。相比于TF和Pytorch,RecIS虽然达到了更高的MBU,但是实际的带宽利用率仍然很低,这也是RecIS在后续需要解决的问题。
Ids Partition:在稀疏查表计算中,需要将ID做去重和切分操作。RecIS实现了一个融合算子一次性完成两个步骤,而在Pytorch中需要用多个算子进行组合才能完成。
2) 聚合操作
RecIS提供了Sum,Mean 以及Tile的聚合方式,以满足不同场景下的embedding聚合需求。我们以1M x 16dim的数据进行了这部分的实验。
Reduce Sum / Mean:由于数据的变长特征,聚合算子会遇到聚合计算带来的原子操作,以及数据稀疏性带来的gpu计算资源浪费的问题。因此我们针对不同场景,提供了自动处理的策略。在输入数据稀疏度较高,聚合冲突低时(reduce easy),我们采用更好利用gpu资源的计算方式;在稀疏度较低,聚合冲突高时(reduce hard),我们采用Warp级别的聚合策略,减少原子操作。
Sequence Tile:RecIS提供了tile聚合方式,支持以concat的方式聚合embedding。
3)Embedding操作
RecIS通过向量化访存提升Embedding操作的访存带宽。我们以1M x 16dim的数据进行了这部分的实验。
-
Gather:从Embedding表中查找对应Index的值。
Scatter:向Embedding表中更新对应位置的参数值。
Operators' MBU for 3 Systems
| Tensorflow | Pytorch | RecIS |
|---|
|
| | 0.88% |
| | | 1.68% |
| | | 55.10% |
|
| | 18.25% |
| | | 2.25% |
| | | 13.75% |
|
| | 47.50% |
| | | 58.00% |
3.2 模型表现
1)搜索模型(MSE)
【模型结构】
搜索模型的输入由600多个特征构成,输入的特征经过 Hash,Bucketize 等特征处理后进入模型查找Embedding,进入 Dense 模型计算。Dense 模型由 Cross Attention,Fully Connect 等结构构成,最终输出Sigmoid结果作为模型输出,表示点击概率。
【实验表现】
我们分别用 Tensorflow,Pytorch 框架,在32张 H20 上进行实验对比效果。RecIS框架下的整体运行时间是 TF 的 33%,Pytorch 的80%;Sparse 部分的运行时间是 TF 的30%,Pytorch 的 72%。MSE 模型中有大量的特征输入,这些特征的处理会引发严重的 GPU 调度开销。在 RecIS 的算子融合策略下,600多特征转换算子被融合成3个,减少了这部分的开销时间,显著提高了模型性能。
2)展示广告模型(LMA)
【模型结构】
LMA 的输入包含100k用户行为序列,其中包含多模态特征和400多个 ID 类特征。 输入的特征会经过 Sequential Truncate,Hash,FeatureCross 等特征转换过程。LMA 会将100k用户历史行为序列和目标商品通过多模态信息进行过滤,筛选出50个相关性最高的历史序列。这50个历史行为序列特征会分别查找embedding,传入 Dense 部分进行计算。Dense 模型部分由 DIN(ID特征部分) 和 SimTierMSKE(多模态部分) 结构构成。
【实验表现】
由于目前torchrec还不支持无冲突Embedding,所以我们仅在 Tensorflow 和 RecIS 上部署了 LMA 模型,我们在下表列出了两个平台上64张H20的实验表现。
LMA(16k) 输入序列截断到16k,以batch size=1000进行。RecIS 的整体运行时间是 TF 的73%,Sparse 的运行时间时 TF 的67%。
LMA(100k) 输入序列截断到100k,以batch size=1000进行。此时Tensorflow已经无法正确运行。
E2E performance for 3 Systems
| Tensorflow | | Pytorch | | RecIS | |
|---|
|
| sparse | overall | sparse | overall | sparse | overall |
| | | | |
764ms | 1050ms |
| | | | | 1009ms | 1372ms |
| | |
| | 218ms | 337ms |
4. 生产应用
以下分三个方向,介绍目前推荐+大模型的迭代路线,以及具体基于RecIS的算法应用。
4.1 Scaling Dense Parameter
生成式排序模型在多场景、多类型内容推荐中展现出强大潜力,其核心挑战在于模型稠密和稀疏参数量大、模型计算复杂度高、训练推理耦合紧密、且需支持灵活的业务扩展。传统框架在应对大规模HashTable、稠密计算层及强化学习(RL)联合优化时面临诸多瓶颈:TensorFlow 1.x灵活性不足,原生PyTorch对大规模稀疏参数支持差,开源TorchRec在多机扩展上性能下降明显。
为此,我们基于RecIS框架构建生成式排序系统,基于多业务粗排输出的候选集合,生成有序用户曝光结果。RecIS在多层Attention结构的生成式主模型结构上,支持灵活的生成式解码逻辑,并深度融合RL训练范式,并针对大规模HashTable实现分层存储与分布式优化,显著降低单机内存需求,实现无限特征存储扩展。
通过系统性效率优化,RecIS相对于 torchrec,模型单机训练batch size提升200%,训练周期缩短70%,并在大规模多机多卡训练时可以基本实现速度线性扩展。目前dense参数50M的生成式排序模型已在首猜核心推荐场景上线AB实验,实现了用户点击和成交指标双提升。
4.2 Scaling User Sequence
终身用户行为建模对于提升推荐系统的准确性至关重要。虽然当前最先进的方法可以处理长度达 10^3 的行为序列,但要扩展到更长的序列(高达 10^6),则会在特征I/O、Embedding查询和计算方面引入较大挑战:
高密度IO:长度为 10^6 的序列会显著增大样本大小,并在训练期间消耗大量的网络带宽。例如,一个batch的内存大小可以高达 6 GB;假设一个batch需要 2 秒进行训练,仅网络吞吐量可达到 24 GB/s。同时,由于多次内存读写,峰值访存带宽甚至可以飙升至 100-200 GB/s。这些巨大的带宽需求对主流硬件构成了严峻挑战。无论是 CX7 级别的网络接口带宽,还是 16 通道 DDR 内存带宽,都无法完全满足如此庞大的数据吞吐量。通过使用 ORC 压缩 和 GPU 样本组装 技术,我们成功地将训练瓶颈从 I/O 带宽转移,确保了高效的训练。
高负载Embedding:长序列不可避免地包含海量历史物品(例如,已下架的商品),这会使得嵌入表规模膨胀,并降低查询效率。例如,对于一个单独的批次,嵌入访问量可以达到 10亿次(1B)的键值(KV)查询,以及 1TB 的嵌入访存。通过使用 GPU Unique 和 GPU Hashtable 技术,我们分别将嵌入查询性能提高了 10倍。
传统框架的限制:TensorFlow 1.x 中的Tensor形状限制(batchsize × seqlen × embdim ≤ 2^31-1)阻碍了使用超长序列进行训练。然而,在新框架下,处理大Tenor已成为标准实践。为了进一步优化这一挑战,我们利用了 PyTorch 生态系统中成熟的技术来节省显存并提升效率。
通过RecIS在以上问题的优化,我们成功在生产环境中部署了长度为1M的用户行为序列模型,这比此前的技术水平提升了100倍。相比10k序列长度,CTR提升4.8%。训练成本降低了 50%。
4.3 Scaling Modality
与传统通过扩大稠密参数规模或序列长度来提升推荐模型能力的方法不同,我们探索了一种新的扩展路径——模态扩展(scaling modality)。该范式不再局限于“模型变大”,而是追求“能力变强”,通过将通用基础模型与轻量化的任务专属专家模块相结合,实现对多样化输入模态的深度融合与高效表达。
这一架构设计将通用知识的学习与特定场景的适配过程解耦,在保障模型表达力的同时,有效缓解了高并发、低延迟流式服务场景下的计算压力,提升了系统的可部署性。其中,核心的知识迁移机制是目标感知嵌入(target-aware embeddings)——通过上下文感知的方式动态调制特征表示,使通用模型的能力能够精准服务于下游任务。
在实际应用中,这类基础模型需要同时刻画单一模态内的语义信息以及跨模态之间的复杂关联,面临两大关键挑战:
如何在一个统一框架下,高效建模多种模态信号,包括大规模稀疏 ID 嵌入、图像、文本等稠密语义特征;
如何在保证系统可扩展性的前提下,通过稠密计算实现多模态 embedding 的有效融合与知识提炼。
基于 RecIS 框架——一个专为大规模稀疏与稠密计算协同优化而设计的推荐系统基础框架——我们从以用户为中心和以物品为导向两个视角出发,验证了该架构在真实推荐场景中的有效性。全面的离线评估与在线 A/B 实验结果表明,该方法在多个业务指标上均取得了显著且可衡量的性能提升,展现出强大的落地价值。
▐ 欢迎关注
RecIS已在GitHub上线,并在持续迭代,后续我们将提供更多搭建推荐,以及大模型的易用性优化。
作为一个年轻的开源项目,我们期待与社区探索更多技术可能性,欢迎大家关注和参与共建!

关注「淘天集团算法技术」,一起成长~











