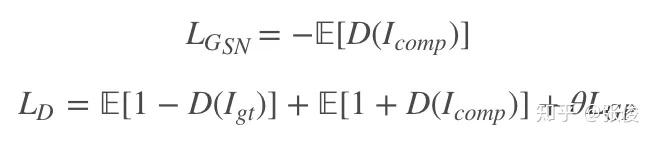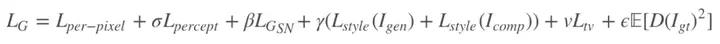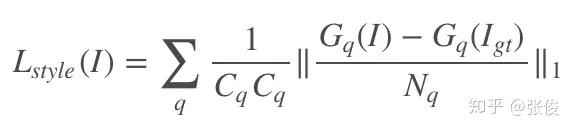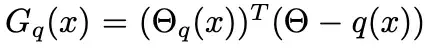不像传统的图像到图像的模型输入是 512 x 512 x 3 的 RGB 输入,这篇论文的输入是尺寸为 512 × 512 × 9 的张量,这个张量是由 5 张图片构成的。
首先是被覆盖残缺的 RGB 图像,也就是我们在图片上勾勾画画的图像,其尺寸为 512 x 512 x 3;其次是提取得到的草图 512 x 512 x 1;图像的颜色域 RGB 图 512 x 512 x 3;掩码图 512 x 512 x 1;最后就是噪声对应的 512 x 512 x 1。按照通道连接的话得到最终的模型输入 512 x 512 x 9。
[1] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang.Free-form image inpainting with gated convolution. arXiv preprint arXiv:1806.03589, 2018. 2, 3, 4, 6, 7
[2] Y. Zhao, B. Price, S. Cohen, and D. Gurari. Guided image inpainting: Replacing an image region by pulling content from another image. arXiv preprint arXiv:1803.08435, 2018. 2
[3] R. Zhang, J.-Y. Zhu, P. Isola, X. Geng, A. S. Lin, T. Yu, and A. A. Efros. Real-time user-guided image colorization with learned deep priors. arXiv preprint arXiv:1705.02999, 2017.2, 3
[4] T. Portenier, Q. Hu, A. Szabo, S. Bigdeli, P. Favaro, and M. Zwicker. Faceshop: Deep sketch-based face image editing. arXiv preprint arXiv:1804.08972, 2018. 2, 3, 4, 6, 7
[5] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing andcomputer-assisted intervention, pages 234–241. Springer,2015. 2, 3, 4
[6] T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196, 2017. 3, 4
[7] S. ”Xie and Z. Tu. Holistically-nested edge detection. In Proceedings of IEEE International Conference on Computer Vision, 2015. 3
[8] Y. Li, S. Liu, J. Yang, and M.-H. Yang. Generative face completion. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), volume 1, page 3, 2017. 1,3, 4