作者:Kavita Ganesan 翻译:陈雨琳 校对:丁楠雅
本文4800字,建议阅读20分钟。
本文将介绍自然语言处理和机器学习中常见的文本预处理方法。
标签:
https://www.kdnuggets.com/tag/data-preprocessing
https://www.kdnuggets.com/tag/machine-learning
https://www.kdnuggets.com/tag/nlp
https://www.kdnuggets.com/tag/python
https://www.kdnuggets.com/tag/text-analysis
https://www.kdnuggets.com/tag/text-mining
本文全面介绍了文本预处理,涵盖了不同的技术,包括词干提取,词形还原,噪声消除,规范化,以及何时应该使用它们的示例和解释。
By Kavita Ganesan, Data Scientist.
http://kavita-ganesan.com/
通过最近的一些交流对话,我意识到文本预处理是一个被严重忽视的话题。我接触过的一些人提到他们的NLP应用程序的结果不一致,最后意识到他们只是没有预处理文本或者他们使用了错误的文本预处理方法。
考虑到这一点,我想到要使大家了解文本预处理的真正含义,文本预处理的不同方法,以及估计可能需要多少预处理的方法。对于那些感兴趣的人,我也为你做了一些文本预处理代码片段。现在,让我们开始吧
文本预处理代码片段
https://github.com/kavgan/nlp-text-mining-working-examples/tree/master/text-pre-processing
什么是文本预处理?
预处理文本指的是将文本转换为可预测且可分析的任务形式。这里的任务是方法和域的结合。例如,从推文(域)中使用TF-IDF(方法)提取顶级关键字。
任务=方法+域
一项任务的理想预处理可能成为另一项任务中最糟糕的噩梦。所以请注意:文本预处理不能直接从任务转移到任务。
让我们举一个非常简单的例子,假设你试图发现新闻数据集中常用的单词。如果你的预处理步骤包括删除停用词,因为其他任务中做过这一步,那么你可能会错过一些常用词,因为你已经将其删除了。实际上,这不是一种通用的方法。
停用词
http://kavita-ganesan.com/what-are-stop-words/
几种文本预处理技术
文本预处理有不同的方法。以下是一些你需要了解的方法,并且我会强调每一个方法的重要性。
转换为小写
尽管把所有文本数据转换为小写这一点通常被忽略,但它是文本预处理中最简单,最有效的形式之一。它适用于大多数文本挖掘和NLP问题,并且可以在数据集不是很大时提供帮助,同时为预期输出一致性带来巨大帮助。
最近,我的一位博客读者为相似性查找任务训练了一个嵌入单词的模型。他发现有着不同大小写变化方式(比如“Canada”和“canada”)的输入产生了不同类型的输出,或者根本没有输出。这可能是因为数据集中出现了“Canada”这个词的混合情况,并且没有足够的证据让神经网络能够有效地学习不常见版本的权重。当你的数据集相当小时,这种类型的问题肯定会发生,而小写是处理文本稀少问题的好方法。
嵌入单词的模型
http://kavita-ganesan.com/gensim-word2vec-tutorial-starter-code/
以下是一个小写预处理解决文本稀少问题的例子,同一个单词的不同大小写变化都映射到同一个小写形式。

同一个单词的不同大小写变化都映射到同一个小写形式
另一种小写转换非常管用的情况是,想象一下,你在查找含有“usa”的文档,然而,查找结果为空因为“usa”被索引为“USA”。现在我们该怪谁呢?是设计界面的用户界面设计师还是设置搜索索引的工程师呢?
虽然转换为小写应该作为标准操作,我也同样经历过保留大写非常重要的情况。比如,当我们在预测源代码文件的编程语言的时候。Java的语言系统跟Python很不一样。小写转换使得两者相同,导致分类器失去了重要的预测特征。虽然小写转换通常都很有帮助,它也并不适用于所有的任务。
词干提取
词干提取是将词语中的屈折变化(比如 troubled,troubles)减少到词根(比如trouble)的过程。在这种情况下,“根”可能不是真正的词根,而只是原始词的规范形式。
词干提取使用粗略的启发式过程来切掉单词的末尾,以期正确地将单词转换为其根形式。 因此,“trouble”, “troubled” 和 “troubles”实际上可能会被转化为“troubl”而不是“trouble”,因为两端都被切掉了(呃,多么粗暴!)。
词干提取有不同的算法。最常见的算法,经验上也对英语很有效的,是Porters算法。以下是Porter Stemmer进行词干提取的一个例子:
Porters算法
https://tartarus.org/martin/PorterStemmer/

对有屈折变化的词进行词干提取的作用
词干对于处理文本稀少问题以及词汇标准化非常有用。尤其是在搜索应用程序中取得了成功。其本质在于,假设你正在寻找“deep learning classes”,你想要搜索到提到“deep learning class”以及“deep learn classes”的文件,尽管后者听起来不对。但是你的要求恰好是我们的目标。你希望匹配单词的所有变体以显示最相关的文档。
然而,在我之前的大多数文本分类工作中,词干提取仅仅略微提高了分类准确性,而不是使用更好的工程特征和文本丰富方法,例如使用单词嵌入。
词形还原
表面上的词形还原与词干还原非常相似,其目标是删除变形并将单词映射到其根形式。唯一的区别是,词形还原试图以正确的方式去做。它不只是切断单词,它实际上将单词转换为实际的根。例如,“better”这个词会映射到“good”。它可以使用诸如WordNet的字典或一些基于规则的特殊方法来进行映射。以下是使用基于WordNet的方法实现的词形还原的示例:
WordNet
https://www.nltk.org/_modules/nltk/stem/wordnet.html
基于规则的特殊方法
https://www.semanticscholar.org/paper/A-Rule-based-Approach-to-Word-Lemmatization-Plisson-Lavrac/5319539616e81b02637b1bf90fb667ca2066cf14

使用WordNet实现的词形还原的作用
根据我的经验,在搜索和文本分类方面,词形还原与词干还原相比没有明显的优势。实际上,因为你选择的算法,与使用非常基本的词干分析器相比,它可能要慢得多,你可能必须知道相关单词的词性才能得到正确的词干。本文发现,词形还原对神经结构文本分类的准确性没有显著影响。
本文
https://arxiv.org/pdf/1707.01780.pdf
就我个人而言,我会保守地使用词形还原。额外的开销是否值得很难说。但你可以随时尝试查看它对你的效果指标的影响。
删除停用词
停用词是一种语言中常用的词汇。英语中的停用词的例子是“a”,“the”,“is”,“are”等。使用停用词背后的直觉是,通过从文本中删除低信息词,我们可以专注于重要的词。
例如,在搜索系统的上下文中,如果你的搜索查询是“什么是文本预处理?”,你希望搜索系统专注于呈现谈论文本预处理的文档,而不是谈论“什么是“。这可以通过对所有在停用词列表中的单词停止分析来完成。停用词通常应用于搜索系统,文本分类应用程序,主题建模,主题提取等。
根据我的经验,删除停用词虽然在搜索和主题提取系统中有效,但在分类系统中显示为非关键。但是,它确实有助于减少所考虑的特征数量,这有助于保持一个较小的模型。
以下是一个删除停用词的示例。所有的停用词都被一个哑字符“W“代替了。
原句= this is a text full of content and we need to clean it up
删除停用词后的句子=W W W text full W content W W W W clean W W
停止词列表可以来自预先建立的集合,也可以为你的域创建自定义单词列表。某些库(例如sklearn)允许你删除一定比例文档中都出现的单词,这也可以为你提供删除停止词效果。
停止词列表
http://kavita-ganesan.com/what-are-stop-words/
自定义单词列表
http://kavita-ganesan.com/tips-for-constructing-custom-stop-word-lists/
规范化
一个被高度忽视的预处理步骤是文本规范化。文本规范化是将文本转换为规范(标准)形式的过程。例如,“gooood”和“gud”这两个词可以转换为“good”,即其规范形式。另一个例子是将近似相同的单词(例如“stopwords”,“stop-words”和“stop words”)映射到“stopwords”。
文本规范化对于噪声多的文本非常重要,例如社交媒体评论,短信和对博客文章的评论,其中缩写,拼写错误和使用标准词汇以外的词(out-of-vocabulary words)很普遍。这篇文章通过对推文进行文本规范化处理的例子证明该方法能够将情绪分类准确度提高约4%。
这篇文章
https://sentic.net/microtext-normalization.pdf
这是规范化之前和之后的单词示例:
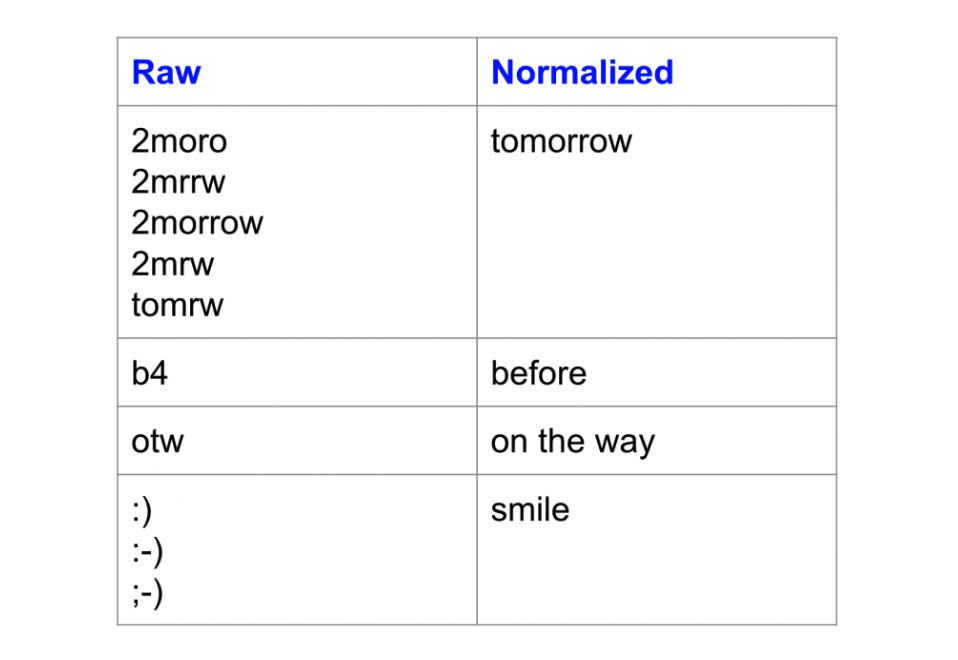 文本规范化的效果
文本规范化的效果
请注意变体如何映射到相同的规范形式。
根据我的经验,文本规范化甚至可以有效地分析高度非结构化的临床文本,因为医生的笔记总是没有规范的。我还发现它对于主题提取很有用,其中近似同义词和拼写差异十分常见(例如topic modelling, topic modeling, topic-modeling, topic-modelling)。
高度非结构化的临床文本
http://kavita-ganesan.com/general-supervised-approach-segmentation-clinical-texts/
主题提取
https://githubengineering.com/topics/
不幸的是,与词干和词形还原不同,没有一种标准的文本规范化方法。它通常随任务不同而不同。例如,你将临床文本规范化的方式可能与你对短信文本消息的规范化方式有所不同。
文本规范化的一些常用方法包括字典映射(最简单),统计机器翻译(SMT)和基于拼写校正的方法。这篇有趣的文章比较了使用基于字典的方法和SMT方法来规范化文本消息。
这篇有趣的文章
https://nlp.stanford.edu/courses/cs224n/2009/fp/27.pdf
噪音消除
噪声消除是指删除可能干扰文本分析的字符数字和文本。噪声消除是最基本的文本预处理步骤之一。它也是高度依赖域的。
例如,在推文中,噪声可能是除了主题标签之外的所有特殊字符,因为它表示可以描述推文的概念。噪音的问题在于它会在下游任务中产生不一致的结果。我们来看下面的例子:
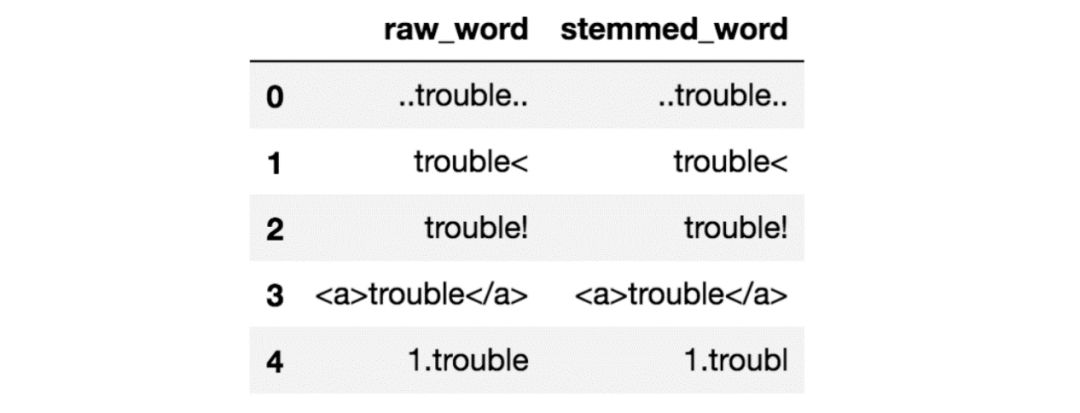
没有去除噪音的词干提取
请注意,上面的所有原始单词都有一些周围的噪音。如果你对这些词进行词干提取,你会发现结果看起来不太漂亮。他们都没有正确的词干。但是,通过这个笔记本中写的一些噪音清除,结果现在看起来好多了:
这个笔记本
https://github.com/kavgan/nlp-text-mining-working-examples/blob/master/text-pre-processing/Text%20Pre-Processing%20Examples.ipynb
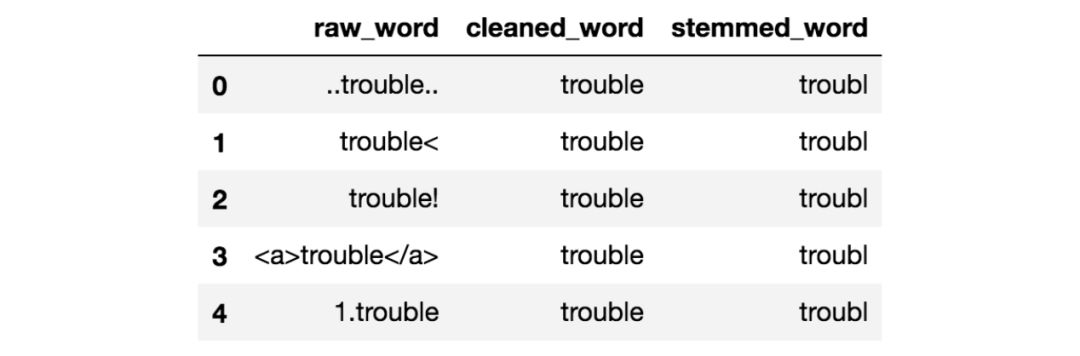
除噪后的词干提取
在文本挖掘和NLP中,噪声消除是你应该首先考虑的事情之一。有各种方法可以消除噪音。这包括删除标点符号,删除特殊字符,删除数字,删除html格式,删除特定域的关键字(例如转发的“RT”),删除源代码,删除标题等。这一切都取决于你的工作域以及什么文本为你的任务带来的噪音。我的笔记本中的代码片段显示了如何进行一些基本的噪音消除。
我的笔记本中的代码片段
https://github.com/kavgan/nlp-text-mining-working-examples/tree/master/text-pre-processing
文字丰富/增强
文本丰富涉及使用你以前没有的信息来扩充原始文本数据。文本丰富为原始文本提供了更多语义,从而提高了预测能力以及可以对数据执行的分析深度。
在信息检索示例中,扩展用户的查询以改进关键字的匹配是一种增强形式。像文本挖掘这样的查询可以成为文本文档挖掘分析。虽然这对一个人没有意义,但它可以帮助获取更相关的文档。
丰富文本的方式多种多样。你可以使用词性标注来获取有关文本中单词的更详细信息。
词性标注
https://en.wikipedia.org/wiki/Part-of-speech_tagging
例如,在文档分类问题中,单词“book“作为名词和动词会导致不同的分类,因为前者用于表示阅读含义的上下文中,而后者用于表示保存含义的上下文中。本文讨论了如何结合使用名词和动词作为输入特征来改进中文文本分类。
本文
http://www.iapr-tc11.org/archive/icdar2011/fileup/PDF/4520a920.pdf
然而,由于大量文本的可用性,人们开始使用嵌入来丰富单词,短语和句子的含义,以便进行分类,搜索,总结和文本生成。在基于深度学习的NLP方法中尤其如此,其中字级嵌入层非常常见。你可以从预先建立的嵌入开始,也可以创建自己的嵌入并在下游任务中使用它。
嵌入
https://en.wikipedia.org/wiki/Word_embedding
字级嵌入层
https://keras.io/layers/embeddings/
预先建立的嵌入
https://blog.keras.io/using-pre-trained-word-embeddings-in-a-keras-model.html
丰富文本数据的其他方法包括短语提取,你可以将复合词识别为一个整体(也称为分块),使用同义词和依赖词解析进行扩展。
同义词
http://aclweb.org/anthology/R09-1073
依赖词解析
http://www.cs.virginia.edu/~kc2wc/teaching/NLP16/slides/15-DP.pdf
是不是所有的预处理都是必要的?

并不是,但如果你想获得良好、一致的结果,你必须采用其中的一些方法。为了让你了解最低限度应该是什么,我把它分解为必须做,应该做和任务依赖型。在决定你确实需要之前,所有依赖于任务的步骤都可以进行定量或定性测试。
请记住,少即是多,应该尽可能保持你的方法简洁。你添加的越多,遇到问题时你将需要剥离的层数越多。
必须做:
应该做:
任务依赖:
高级规范化(例如,解决词汇外单词)
删除停用单词
词干/词形还原
文本丰富/增强
因此,对于任何任务,你应该做的最小值是尝试将文本转换为小写并消除噪音。什么样的文本包含噪音取决于你的域(请参阅噪音消除部分)。你还可以执行一些基本的规范化步骤以获得更高的一致性,然后根据需要系统地添加其他层。
一般经验法则
并非所有任务都需要相同级别的预处理。对于某些任务,你可以尽量减少。但是,对于其他任务来说,数据集是如此嘈杂,如果你没有进行足够的预处理,最终结果将跟原始输入同样糟糕。
这是一般的经验法则。这并不总是成立,但适用于大多数情况。如果你在一个相当普通的域有大量行文规范流畅的文本,那么预处理并不是非常关键,你可以使用最低限度(例如,使用所有维基百科文本或路透社新闻文章训练单词嵌入模型)。
但是,如果你在一个非常狭窄的域进行工作(例如关于健康食品的推文)并且数据稀少且嘈杂,你可以从更多的预处理层中受益,尽管你添加的每个层(例如,删除停用词,词干提取,文本规范化)都需要被定量或定性地验证为有意义的层。这是一个表格,总结了你应该对文本数据执行多少预处理。
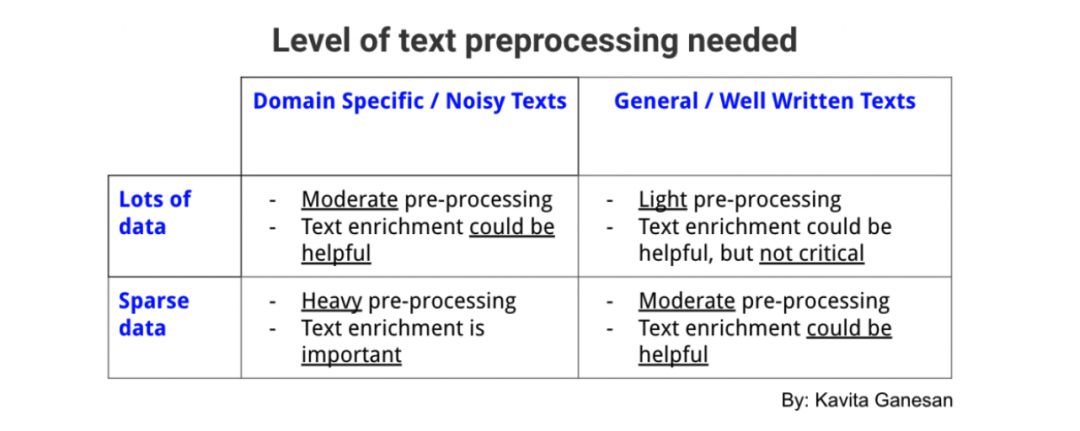
需要的不同级别文本预处理:

我希望这里的想法可以引导你为项目选择正确的预处理步骤。记住,少即是多。我的一位朋友曾经向我提到他是如何通过抛弃不必要的预处理层来使大型电子商务搜索系统更高效,错误更少。
资源
https://github.com/kavgan/nlp-text-mining-working-examples/blob/master/text-pre-processing/Text%20Preprocessing%20Examples.ipynb
http://kavita-ganesan.com/tips-for-constructing-custom-stop-word-lists/
https://kavgan.github.io/phrase-at-scale/
参考资料
有关论文的最新列表,请参阅我的原始文章。
原始文章
https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit_v2&action=edit&isNew=1&type=10&token=838611073&lang=zh_CN#Relevant-Papers
Bio:Kavita Ganesan是一名数据科学家,拥有自然语言处理,文本挖掘,搜索和机器学习方面的专业知识。在过去十年中,她曾在多个科技机构工作,包括GitHub(微软),3M健康信息系统和eBay。
Kavita Ganesan
http://kavita-ganesan.com/about-me/
原版。 转载许可。
原版
https://medium.freecodecamp.org/all-you-need-to-know-about-text-preprocessing-for-nlp-and-machine-learning-bc1c5765ff67
资源:
https://www.kdnuggets.com/education/online.html
https://www.kdnuggets.com/software/index.html
相关资料:
https://www.kdnuggets.com/2019/04/nlp-pytorch.html
https://www.kdnuggets.com/2019/03/building-nlp-classifiers-cheaply-transfer-learning-weak-supervision.html
https://www.kdnuggets.com/2019/03/beyond-news-contents-role-of-social-context-for-fake-news-detection.html
原文标题:
All you need to know about text preprocessing for NLP and Machine Learning
原文链接:
https://www.kdnuggets.com/2019/04/text-preprocessing-nlp-machine-learning.html
译者简介:陈雨琳,清华大学大二在读,英语专业。专业学习之外喜欢学些数学、计算机类课程,被数据和模型的魅力所吸引,希望未来能往这个方向发展。道阻且长,行则将至。
本文转自:数据派THU ;获授权;
END
合作请加QQ:365242293
数据分析(ID : ecshujufenxi )互联网科技与数据圈自己的微信,也是WeMedia自媒体联盟成员之一,WeMedia联盟覆盖5000万人群。











