本文概述的是作者近期在 IEEE TIP 期刊上发表的论文:《A Deep Learning Approach for Multi-Frame In-Loop Filter of HEVC》,主要思想是利用深度学习方法,发掘HEVC中连续多帧的图像信息,将其用于环路滤波器的设计,以显著提高滤波后的图像质量,进而提高HEVC编码效率。
此论文是北京航空航天大学博士生李天一,在导师徐迈的指导下,完成的一项工作。
论文链接:
A Deep Learning Approach for Multi-Frame In-Loop Filter of HEVC
A Deep Learning Approach for Multi-Frame In-Loop Filter of HEVC ieeexplore.ieee.org数据库和代码链接:
tianyili2017/HIF-Database github.com对视频编码的一些理解 本文主要涉及的是视频编码与深度学习。介绍本文之前,先在这里写一下对视频编码的粗浅理解,已有了解的可以跳过这部分。我们平时看到的视频,原始数据量往往非常庞大,尤其对高清视频而言,如果直接存储和传输原始信息,需要占用大量的空间和带宽(例如1080p@30Hz&24-bit,数据量高达11.2GB/min)。为解决这个问题,学术界和工业界制定出了多代视频编码标准,用于将原始视频数据压缩成体积较小的比特流。压缩,可以利用无损和有损的方式进行,但无损压缩的压缩比往往很有限,目前关注的绝大部分是有损压缩方式。这种方式允许压缩后恢复出的视频存在失真,但只要没有使视频质量明显降低,还能够被人眼接受,那么这种有损压缩就是合理的。不同的有损压缩方法(例如各种压缩标准之间、同一标准中的不同配置)性能一般不同,而在作者看来,需要关注的性能,主要在于“多快好省”的后三个字:
•“快”:编码时间。与视频播放时间无关,此指标是把原始视频编码成比特流所需的时间,即编码器的运行时间。编码时间越短,往往意味着消耗计算资源越少,说明这种编码方法越有希望得到广泛应用。
•“好”:压缩后的视频质量。最常用的,可以用所有帧平均PSNR来表示。或者用其他客观指标如SSIM等描述,也可用人的主观打分来衡量。
•“省”:压缩后的码率。即比特流体积与视频时间之比。
以上三项中,编码时间描述的是过程,视频质量和码率描述的是结果,显然,过程和结果都需要我们关注。其中,形容结果的两项指标往往联合使用,因为单纯的高质量和单纯的低码率都很难说明编码性能如何,一般公认的是固定单一变量来对比另一个变量,例如相同视频质量下的码率变化率(BD-BR)或相同码率下的PSNR变化量(BD-PSNR)。这种“好”和“省”,更科学地说,称为“率-失真性能”,即反映码率和失真两项指标的综合性能。
随着编码标准的发展,例如H.264/AVC->H.265/HEVC->H.266/VVC,率失真性能在不断地优化,但代价是时间复杂度成倍提高,这主要因为后续的编码标准往往支持更灵活的分块/预测/变换等策略,使得编码器能在更广大的策略空间中搜索最优解,用更多的搜索时间换取率-失真性能。对于一种编码标准,研究者改进的目标也往往基于复杂度或率失真性能,因此,据本人有限了解,编码领域至少有以下几类研究:
1. 保证率-失真性能前提下,节省编码时间:可以理解为减小编码时间的均值(一阶性能)
2. 在编码时间可接受的前提下,优化率-失真性能:可以理解为优化BD-BR或BD-PSNR的均值(一阶性能)
3. 复杂度控制,减小编码时间复杂度的波动:即减小编码时间的方差(二阶性能)
4. 码率控制,减小编码过程中的码率波动:即减小码率的方差(二阶性能)
对于不断发展的编码标准,提案/论文/专利等可以说是浩如烟海,但往往可以归结为对复杂度、码率与视频质量的追求,按照这个思路,就比较容易理解了。作者曾在2018年TIP中提出过基于深度学习的HEVC复杂度优化方法,属于上表中比较基本的第1类研究;对本文而言,利用HEVC多帧信息进行环路滤波,则属于第2类研究。当然,第3、4类或者其他类型的工作,在作者所属的课题组,以及其他编码相关的课题组,也都有涉及,就暂不详细说明了。
一、研究背景 作为一种比较先进的视频压缩方法,HEVC标准相比于上一代AVC标准,能够在相同质量下降低约50%码率,使编码效率进一步提高。但也需要考虑到,AVC、HEVC等基于块的编码方法通常用于有损压缩而不是完全无损的,因此不可避免会带来了多种失真(如块失真、模糊和振铃效应等),尤其在低码率情况下,这些失真更为显著。为了减轻编码过程中的失真,人们提出了多种滤波算法。尽管具体方法不同,这些滤波算法具有一个共同点:都对编码后的每帧视频进行质量增强,并且已经增强过的帧又作为参考帧,为后续帧的编码过程提供帧间预测信息。可见,这类滤波算法既作用于当前帧的输出,又作用于后续帧的输入,逻辑上形成一个闭环,因此统称为环路滤波。合理设计的环路滤波器,使得视频编码的效率可以进一步提高。
首先,HEVC标准的制定过程涉及到三种环路滤波器,包括去块滤波器(Deblocking filter,DBF)、样本自适应偏移(Sample adaptive offset,SAO)滤波器以及自适应环路滤波器(Adaptive loop filter,ALF)。其中,DBF首先用于消减压缩视频中的块效应;然后,SAO滤波器通过对每个采样点叠加自适应的偏移量,来减少压缩失真;最后,ALF则基于维纳滤波算法,进一步降低失真程度。最终,DBF和SAO被纳入HEVC标准。
除了HEVC标准环路滤波器,另有多种启发式的和基于深度学习的环路滤波方法,也被陆续提出。启发式方法是根据一些先验特征(如纹理复杂度和相似视频块个数等)对压缩失真构建统计模型,再根据此模型设计滤波器,例如非局域均值(Non-local means,NLM)滤波器[Matsumura, JCTVC-E206, 2011]和基于图像块矩阵奇异值分解的滤波器[Ma, MM 2016][Zhang, TCSVT 2017]等。启发式方法能在一定程度上提高编码效率,但模型中的先验特征需要手动提取,这高度依赖于研究者的经验,并且难以利用多种特征进行准确建模,因此在一定程度上限制了滤波器的性能。从2016年开始,基于深度学习的方法显著提高了环路滤波性能。此类方法一般通过构建卷积神经网络(convolutional neural network,CNN)来学习视频帧中的空间相关性。例如,文献[Dai, MMM 2017]设计了一种可变滤波器尺寸的残差CNN(Variable-filter-size residue-CNN,VRCNN),以替换帧内模式中的标准DBF和SAO。文献[Zhang, TIP 2018]则提出一种带有捷径的残差CNN(Residual highway CNN,RHCNN),用于帧内或帧间模式的标准SAO过程之后。上述基于深度学习的方法有效发掘了单帧内容的空间相关性,然而却没有发掘多帧内容中的时间相关性。实际上,压缩视频一般存在明显的质量波动,而且其中的连续多帧往往包含相似的事物或场景。因此,低质量帧中的视频内容可以由临近的高质量帧推测得到,这即为本文的出发点:基于深度学习的HEVC多帧环路滤波。
二、数据分析 对于本文的环路滤波问题,首先构建一个大规模数据库,以便在设计算法之前进行必要分析,并为本文或后续的相关工作提供数据支撑。本数据库由182个无损视频组成,分别来自http:// Xiph.org
表1 环路滤波数据库构成 库中的182个视频包括训练集(120个视频)、验证集(40个视频)以及测试集(40个视频)三个不重叠的部分。此外,JCT-VC标准推荐的所有18个视频也参与测试,但因为版权不全开放,就没有计入本文构建的数据库中。所有182个开源视频都利用HM 16.5在4个QP下进行编码,并包含LDP、LDB和RA三种帧间配置。在编码过程中,提取出所有的未滤波重建帧(Unfiltered reconstructed frame,URF)和对应的无损帧,作为神经网络的输入和输出信息。另外,考虑到CTU分割结构会显著影响压缩失真,所有帧的CU和TU分割情况也被提取出来,作为辅助信息。因此,数据库中的每个帧级别样本都包括四部分:一个URF、对应的无损帧,以及表示CU和TU分割深度的两个矩阵。最终,根据3种不同配置和4种不同QP值,总共构建出12个子数据库。完整的数据库共包含了约60万个帧级别样本,每个帧级别样本又可以拆分成多个块级别样本(取自视频帧中的任意位置),能够为数据分析和模型训练提供充足的数据支撑。
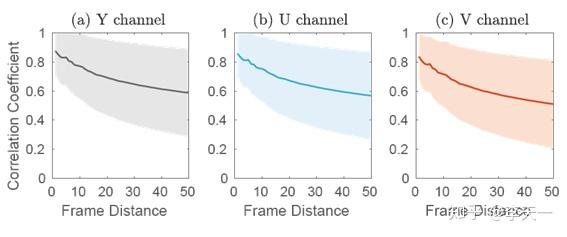
构建数据库后,利用其中的训练集和验证集上的160个视频,分析编码过程中的视频内容相似度和质量波动情况。首先,图2反应了不同帧间距离下的Y、U、V三通道内容相似度,用每个通道两帧矩阵之间的线性相关系数(CC)来衡量。
图1 帧间内容相似度
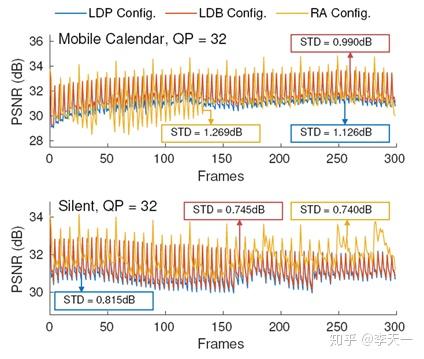
另外,对于压缩视频的质量波动,可以用PSNR的标准差来衡量。下图以两个视频为例,表示出同一个视频中帧间PSNR存在显著变化,同样,其他视频中也存在相似的现象。
图2 HEVC编码视频质量波动示例 表2 PSNR波动与标准滤波器的PSNR增量 为更全面地衡量HEVC中的视频质量波动,表2进一步比较了所有视频PSNR的波动情况,和标准环路滤波器DBF和SAO所带来的PSNR增量。可见,在LDP、LDB和RA配置下,PSNR的标准差平均为0.891 dB、0.882 dB和0.929 dB,远高于由标准滤波器带来的提升(0.064 dB、0.048 dB和0.050 dB)。这说明在HEVC的不同编码配置下,视频质量波动提供了设计多帧滤波器的潜力(用高质量帧补偿邻近的低质量帧),但标准环路滤波器没有有效地利用这种潜力。这也不难理解,因为标准滤波器没有直接利用多帧信息。本文则把握住这种潜力,设计出一个基于多帧信息的环路滤波器。
三、研究内容 3.1 方法框架
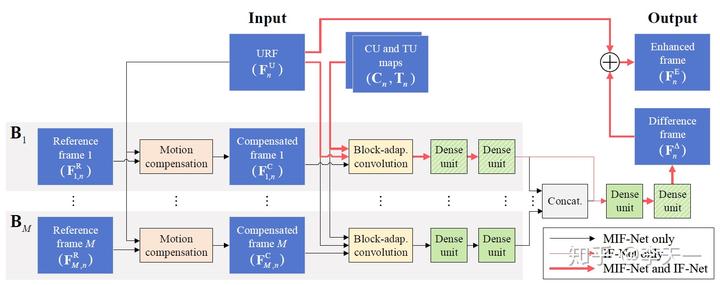
本文中多帧环路滤波器(Multi-frame in-loop filter, MIF)的框架如下图所示。
图3 方法框架 图中上半部分是标准编码步骤:每个原始视频帧通过帧内或帧间预测、离散变换和量化等必要步骤进行编码。预测得到的帧与残差帧之和,构成一个未滤波的重建帧URF。下半部分则是本文的贡献:利用每个URF及其临近帧的信息,增强URF的视觉质量。首先,由参考帧选择器(Reference frame selector, RFS)选出一些高质量且内容相似的帧,作为当前URF的参考帧。之后,根据参考帧的数量,在以下两种可能情况中选择一种,对URF进行增强。
· 模式1:MIF-Net 。设多帧增强方法需要
· 模式2:IF-Net 。对于一个URF,如果RFS未能选出
最终,编码器比较MIF-Net/IF-Net与标准滤波器DBF+SAO的性能,并将PSNR最佳的方案作为实际的选择,以保证整体性能。
3.2 RFS的设计
RFS为每个URF选取参考帧的原理如图。
图4 RFS原理 假设当前帧URF是第
· Y、U、V三个通道上,参考帧相对于当前URF的PSNR增量;
· Y、U、V三个通道上,参考帧和当前URF内容的相关系数CC。
对于某个参考帧,若至少在一个通道上,满足PSNR增量大于0且CC大于一个阈值,则认为此参考帧可能有潜力提高URF的质量,即该参考帧有效。否则,认为此参考帧无效。若有效的参考帧超过
3.3 网络结构与训练过程
RFS的运行结果,为绝大多数的URF选出了具有足够数量的参考帧;对于少数URF,也存在参考帧不足的可能。本文核心内容在于,对以上两种情况(尤其是参考帧足够的情况),分别设计合适的深度神经网络,以显著增强URF的质量。首先会比较详细地介绍MIF-Net的结构及其训练方法,之后将指出IF-Net和MIF-Net的不同之处。
图5 MIF-Net或IF-Net结构,由箭头型号区分代表两种网络。 MIF-Net的结构如上图所示。其输入包括一个URF和它的
图6 运动补偿网络 运动补偿网络。 MIF-Net中的运动补偿网络,是基于文献[Caballero, CVPR 2017]中的空间变换运动补偿(Spatial transformer motion compensation,STMC)模型改进得到,以实现参考帧和URF的内容对齐,如图6所示。若直接利用此文献的方法,则STMC的输入为参考帧和URF,输出为一个运动补偿后的帧(图中的
· 在×4和×2降采样支路的基础上,增加一个原尺寸支路,以提升MV的估计精度;
· 受ResNet启发,在已有的卷积层旁边增加了6条捷径(图中6个加号附近),以提高网络容量并使网络更容易训练;
· 将原先所有的ReLU激活层替换成PReLU,使网络可以学习激活函数负半轴的斜率。
进行上述改进之后,根据新增的原尺寸支路得到两个新的MV图,寻找补偿后的帧中每个像素在参考帧中的对应坐标,再根据双线性插值法,计算出运动补偿后的帧,即图中的
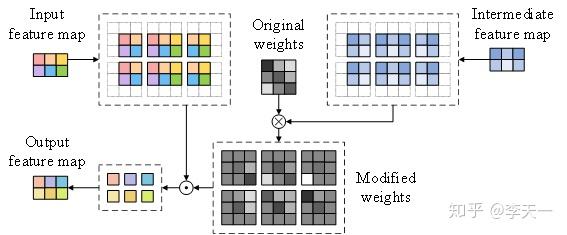
块适应卷积层。
· 首先,将引导特征图通过普通卷积层进行处理,生成若干个中介特征图。在此步骤的处理中,需要保持特征图尺寸不变。
· 之后,在对输入特征图进行卷积的过程中,根据中介特征图来生成输出特征图。
图7给出一个例子,说明带有引导信息的卷积计算过程。假设一种简单情况,输入、输出特征图的尺寸均为3×2,卷积核大小为3×3。与普通卷积的区别,在于新增的中介特征图(图中的intermediate feature map)。考虑引导信息,用原本的卷积核3*3权重,乘以中介特征图里各个像素周围3*3感受野中的数值,逐元素相乘,得到修改后的权重。此时,各个像素对应的3*3权重都可能不同,即卷积核权重可以受到中介特征图控制。之后的运算则与普通卷积类似,由输入特征图每个像素周围的3*3感受野,与对应的3*3权重做内积,得到输出特征图的对应像素值。
比较而言,考虑每个输入通道向每个输出通道做卷积的过程,传统卷积中的权重与位置无关,具有空间不变性;带引导的卷积中,卷积核权重会受到中介特征图控制,即带有一定程度的空间相关性。尽管这里的卷积核权重与位置相关,但并不会像全连接层那样完全随机,这是因为中介特征图也是通过卷积得到的,而不是杂乱无章。并且,只需增加少量的可训练参数,即可实现带引导信息的卷积,不会导致明显的过拟合。这些特点使得带有引导信息的卷积,可以利用更丰富的额外信息(如本文中的CU和TU分割情况),提高神经网络的建模能力。
图7 带有引导信息的卷积示例 用于质量增强的密集单元。 作为普通CNN的改进版,文献[Huang, CVPR 2017]提出的DenseNet包含了多种长度的层间连接,能有效缓解梯度消失问题,并促进网络不同位置的参数共享。考虑到这些优势,MIF-Net中引入了
图8 dense unit 结构 MIF-Net训练过程。 考虑到运动补偿和质量增强两大部分,MIF-Net难以作为一个整体直接训练。因此,本文采用了中间监督方法,在不同步骤引入各自的代价函数,进行训练。首先,可以用URF和每个参考帧内容的差距来衡量运动补偿网络的性能,即基于MSE loss定义一个中间代价函数
3.4 IF-Net和MIF-Net的区别
两个网络的区别在于MIF-Net的输入包含了
四、实验结果 首先考虑环路滤波器的一种基本性能,即客观率失真性能,一般用BD-BR和BD-PSNR来衡量。利用JCT-VC标准推荐的所有18个视频来测试,包括Class A~E,QP设置为22、27、32和37。在三种帧间模式中,以最接近实用的RA模式为例,下表给出了标准环路滤波器、两种对比算法和本文算法的性能。
表3 RA模式率失真性能比较 表格中,所有数据都是和去掉环路滤波器的HM-16.5编码器相比的,例如,可以看出标准环路滤波器DBF+SAO带来了5.031%的码率节省,也代表相同码率下0.162dB的质量提升。表中的[10]和[20]代表一种基于图像块矩阵SVD分解的启发式算法[Zhang, TCSVT 2017]和一种基于高速残差CNN的深度学习算法[Zhang, TIP 2018],与标准算法相比,性能都有所提高。表格右侧的多帧环路滤波算法,从BD-BR和BD-PSNR两项指标来看,都优于其他三种算法,证明了本文方法的客观率失真性能。
图9 RA模式下主观率失真性能对比 在主观质量方面,本文也进行了对比,例如图9中,多帧环路滤波相比于其他滤波方法,能观察到马尾边缘更清晰、行人和街道图像上的块效应更轻、人的手指更容易分辨,等等。这种质量提升,在一定程度上得益于高质量帧补偿低质量帧的思想,尤其在内容运动明显、质量波动剧烈的地方,优势更明显。限于篇幅,论文难以对比所有图像局部的主观质量,但本文方法在18个标准视频上所有的编码结果,已经上传到数据库网站 https:// github.com/tianyili2017 /HIF-Database
为了进一步验证多帧环路滤波方法各个部分的作用,本文加入了溶解性实验,如图10所示。溶解性实验从完整方法(考虑多帧信息、网络中存在块适应卷积和dense units)开始,每次去掉一个主要部分,测量这种情况的BD-BR和BD-PSNR。图10中,完整方法为配置1,去掉多帧网络MIF-Net后成为配置2,再去掉块适应卷积后成为配置3,接着把dense units换成普通卷积层后成为配置4(即深度学习方法的最简情况)。最终,不带深度学习的标准环路滤波器,为配置5。可以看出,图中每对相邻的配置都只改变一个变量,构成一组对比实验,并且存在着明显的性能差别。这就验证了本文方法的各个主要成分,都起到了一定的作用,同时也说明了,多帧思想的引入和网络结构的改进,都有助于提升环路滤波器的性能。
图10 溶解性分析 除了率失真性能,算法的复杂度也是需要考虑的因素,尤其对于深度学习方法而言,时间复杂度影响着算法的实用性。在表4中,本文以RA模式为例,在Intel(R) Core (TM) i7-7700K CPU @4.2 GHz,Ubuntu 16.04平台上,给出了标准编码器HM16.5在纯CPU模式下的每帧编码时间
表4 RA模式时间复杂度分析 小结 本文主要贡献包括:
构建一个大规模的环路滤波数据库,为本方法提供足够的数据支撑,也可用于对HEVC环路滤波的后续研究。 根据视频内容和质量波动情况的分析,提出一种参考帧选择算法RFS。 提出一种多帧环路滤波网络MIF-Net,同时利用时间和空间信息,显著提升视频帧的质量。其中包含了本文新提出的块适应卷积、改进版运动补偿网络,以及引入DenseNet先进结构设计出的质量增强网络。 在作者看来,未来还可以做些进一步工作。例如,在基于深度学习的环路滤波器中,引入更多样的信息,如跳过模式(skip mode)、PU分块信息、编码器估计出的运动矢量和残差帧信息等。另外,可以利用一些网络加速算法对深度神经网络进行简化,提高本方法或未来环路滤波方法的实用性,并促进硬件实现。