
来源 | 早起Python(ID:zaoqi-python)很多同学在学习机器学习时往往掉进了不停看书、刷视频的,但缺少实际项目训练的坑,有时想去练习却又找不到一个足够完整的教程,本项目翻译自kaggle入门项目Titanic金牌获得者的Kernel,该篇文章通过大家并不陌生的泰坦尼克数据集详细的介绍了如何分析问题、数据预处理、建立模型、特征选择、模型评估与改进,是一份不可多得的优秀教程。
本文在翻译的同时删减了部分介绍性文字,并对结构进行了调整方便大家阅读,由于篇幅原因,本篇文章中并没有包含大段的代码,仅保留过程与结果。建议在文末获取Notebook版本与数据集完整复现一遍,如果你正处于机器学习入门阶段相信一定会有所收获!目录
01
项目背景与分析
泰坦尼克号沉没是历史上有名的沉船事件之一。1912年4月15日,在泰坦尼克号的首次航行中,与冰山相撞后沉没,使2224名乘客和机组人员中的1502人丧生。这一耸人听闻的悲剧震惊了国际社会。沉船事故导致人员丧生的原因之一是没有足够的救生艇供乘客和船员使用。尽管在下沉中幸存有一定的运气,但某些群体比其他群体更可能生存,例如妇女,儿童和上层阶级。在这个项目中,我们被要求完成对可能生存的人群的分析,并使用机器学习工具来预测哪些乘客可以幸免于悲剧。
02
数据读取与检查
首先导入与数据处理相关的库,并检查版本与数据文件夹#导入相关库
import sys
print("Python version: {}". format(sys.version))
import pandas as pd
print("pandas version: {}". format(pd.__version__))
import matplotlib
print("matplotlib version: {}". format(matplotlib.__version__))
import numpy as np
print("NumPy version: {}". format(np.__version__))
import scipy as sp
print("SciPy version: {}". format(sp.__version__))
import IPython
from IPython import display
print("IPython version: {}". format(IPython.__version__))
import sklearn
print("scikit-learn version: {}". format(sklearn.__version__))
import
random
import time
#忽略警号
import warnings
warnings.filterwarnings('ignore')
print('-'*25)
# 将三个数据文件放入主目录下
from subprocess import check_output
print(check_output(["ls"]).decode("utf8"))
#导入建模相关库
from sklearn import svm, tree, linear_model, neighbors, naive_bayes, ensemble, discriminant_analysis, gaussian_process
from xgboost import XGBClassifier
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn import feature_selection
from sklearn import model_selection
from sklearn import metrics
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
import seaborn as sns
from pandas.tools.plotting import scatter_matrix
#可视化相关设置
%matplotlib inline
mpl.style.use('ggplot')
sns.set_style('white')
pylab.rcParams['figure.figsize'] = 12,8
现在来读取并对数据做一个初步的预览,我们使用info()和sample()函数来快速概览变量数据类型。data_raw = pd.read_csv('train.csv')
data_val = pd.read_csv('test.csv')
data1 = data_raw.copy(deep = True)
data_cleaner = [data1, data_val]
print (data_raw.info())
data_raw.sample(10)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889
non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
None
- 存活变量是我们的结果或因变量。这是一个二进制标称数据类型的1幸存,0没有生存。所有其他变量都是潜在的预测变量或独立变量。重要的是要注意,更多的预测变量并并不会形成更好的模型,而是正确的变量才会。
- 乘客ID和票证变量被假定为随机唯一标识符,对结果变量没有影响。因此,他们将被排除在分析之外。
- Pclass变量是票券类的序数数据,是社会经济地位(SES)的代表,代表1 =上层,2=中产阶级,3 =下层。
- Name变量是一个标称数据类型。用于提取特征中,可以从标题、家庭大小、姓氏中获得性别,如SES可以从医生或硕士来判断。因为这些变量已经存在,我们将利用它来查看title(如master)是否会产生影响。
- 性别和装载变量是一种名义数据类型。它们将被转换为数学计算的哑变量。
- SIBSP代表相关上船的兄弟姐妹/配偶的数量,而PARCH代表上传的父母/子女的数量。两者都是离散的定量数据类型。这可以特征工程创建一个关于家庭大小的变量。
- 舱室变量是一个标称数据类型,可用于特征工程中描述事故发生时船舶上的大致位置和从甲板上的船位。然而,由于有许多空值,它不增加值,因此被排除在分析之外。
03
数据预处理
数据校正
检查数据,似乎没有任何异常或不可接受的数据输入。此外,我们发现我们在年龄和票价上可能存在潜在异常值。但是,由于它们是合理的值,我们将等到完成探索性分析后再确定是否应从数据集中包括或排除。应该注意的是,如果它们是不合理的值,例如age = 800而不是80,那么现在修复是一个安全的决定。但是,从原始值修改数据时,我们要格外小心,因为可能需要创建准确的模型。缺失值填充
年龄,机舱和出发区域中存在空值或缺少数据。缺少值可能是不好的,因为某些算法不知道如何处理空值,并且会失败。而其他决策树等可以处理空值。因此,在开始建模之前进行修复很重要,因为我们将比较和对比多个模型。有两种常用方法,即删除记录或使用合理的输入填充缺失值。不建议删除该记录,尤其是大部分记录,除非它确实代表不完整的记录。相反,最好估算缺失的值。定性数据的基本方法是估算使用模式。定量数据的基本方法是使用均值,中位数或均值+随机标准差估算。中间方法是根据特定标准使用基本方法。例如按舱位划分的平均年龄,或按票价和SES出发前往港口。有更复杂的方法,但是在部署之前,应将其与基本模型进行比较,以确定复杂性是否真正增加了价值。对于此数据集,年龄将用中位数来估算,机舱属性将被删除,而登船将以mode进行估算。随后的模型迭代可能会修改此决策,以确定它是否会提高模型的准确性。数据创建
特征工程是当我们使用现有特征来创建新特征以确定它们是否提供新信号来预测我们的结果时。对于此数据集,我们将创建标题功能以确定其是否在生存中发挥作用。数据转换
最后但同样重要的是,我们将对数据格式进行转换。对于此数据集,我们将对象数据类型转换为分类虚拟变量。print('Train columns with null values:\n', data1.isnull().sum())
print("-"*10)
print('Test/Validation columns with null values:\n', data_val.isnull().sum())
print("-"*10)
data_raw.describe(include = 'all')
开始清洗
完成这个步骤你需要对下面的Pandas功能有一定的了解- pandas.DataFrame.describe
- Indexing and Selecting Data
-
- pandas.Series.value_counts
###缺失值处理
for dataset in data_cleaner:
#用中位数填充
dataset['Age'].fillna(dataset['Age'].median(), inplace = True)
dataset['Embarked'].fillna(dataset['Embarked'].mode()[0], inplace = True)
dataset['Fare'].fillna(dataset['Fare'].median(), inplace = True)
#删除部分数据
drop_column = ['PassengerId','Cabin', 'Ticket']
data1.drop(drop_column, axis=1, inplace = True)
print(data1.isnull().sum())
print("-"*10)
print(data_val.isnull().sum())
接下来我们将把分类数据转换成用于数学分析的哑变量。有多种方法来对分类变量进行编码,在这个步骤中,我们还将定义X(独立/特征/解释/预测器/等)和Y(依赖/目标/结果/响应/等)变量用于数据建模。label = LabelEncoder()
for dataset in data_cleaner:
dataset['Sex_Code'] = label.fit_transform(dataset['Sex'])
dataset['Embarked_Code'] = label.fit_transform(dataset['Embarked'
])
dataset['Title_Code'] = label.fit_transform(dataset['Title'])
dataset['AgeBin_Code'] = label.fit_transform(dataset['AgeBin'])
dataset['FareBin_Code'] = label.fit_transform(dataset['FareBin'])
Target = ['Survived']
data1_x = ['Sex','Pclass', 'Embarked', 'Title','SibSp', 'Parch', 'Age', 'Fare', 'FamilySize', 'IsAlone'] #pretty name/values for charts
data1_x_calc = ['Sex_Code','Pclass', 'Embarked_Code', 'Title_Code','SibSp', 'Parch', 'Age', 'Fare'] #coded for algorithm calculation
data1_xy = Target + data1_x
print('Original X Y: ', data1_xy, '\n')
#为原始特征定义x变量以删除连续变量
data1_x_bin = ['Sex_Code','Pclass', 'Embarked_Code', 'Title_Code', 'FamilySize', 'AgeBin_Code', 'FareBin_Code']
data1_xy_bin = Target + data1_x_bin
print('Bin X Y: ', data1_xy_bin, '\n')
data1_dummy = pd.get_dummies(data1[data1_x])
data1_x_dummy = data1_dummy.columns.tolist()
data1_xy_dummy = Target + data1_x_dummy
print('Dummy X Y: ', data1_xy_dummy, '\n')
data1_dummy.head()
现在我们已经基本完成了数据的清洗,让我们再次进行检查print('Train columns with null values: \n', data1.isnull().sum())
print("-"*10)
print (data1.info())
print("-"*10)
print('Test/Validation columns with null values: \n', data_val.isnull().sum())
print("-"*10)
print (data_val.info())
print("-"*10)
data_raw.describe(include = 'all')
划分测试集与训练集
如前所述,提供的测试文件实际上是比赛提交的验证数据。因此,我们将使用sklearn函数将训练数据分为两个数据集,这不会过度拟合我们的模型。train1_x, test1_x, train1_y, test1_y = model_selection.train_test_split(data1[data1_x_calc], data1[Target], random_state = 0)
train1_x_bin, test1_x_bin, train1_y_bin, test1_y_bin = model_selection.train_test_split(data1[data1_x_bin], data1[Target] , random_state = 0)
train1_x_dummy, test1_x_dummy, train1_y_dummy, test1_y_dummy = model_selection.train_test_split(data1_dummy[data1_x_dummy], data1[Target], random_state = 0)
print("Data1 Shape: {}".format(data1.shape))
print("Train1 Shape: {}".format(train1_x.shape))
print("Test1 Shape: {}".format(test1_x.shape))
train1_x_bin.head()
04
探索性分析
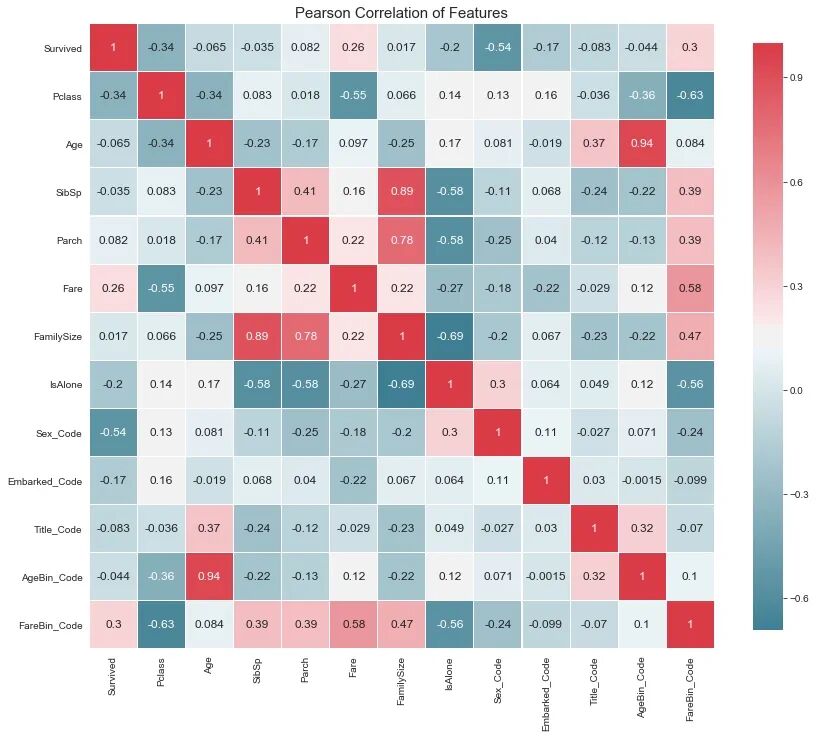
现在,我们的数据已清理完毕,我们将使用描述性和图形统计数据探索数据,以描述和总结变量。在此阶段,你将发现自己对特征进行了分类,并确定了它们与目标变量的相互关系。
for x in data1_x:
if data1[x].dtype != 'float64' :
print('Survival Correlation by:', x)
print(data1[[x, Target[0]]].groupby(x, as_index=False).mean())
print('-'*10, '\n')
print(pd.crosstab(data1['Title'],data1[Target[0]]))
接下来是一些可视化的分析,首先探索各个标签的不同特征值的生存结果对比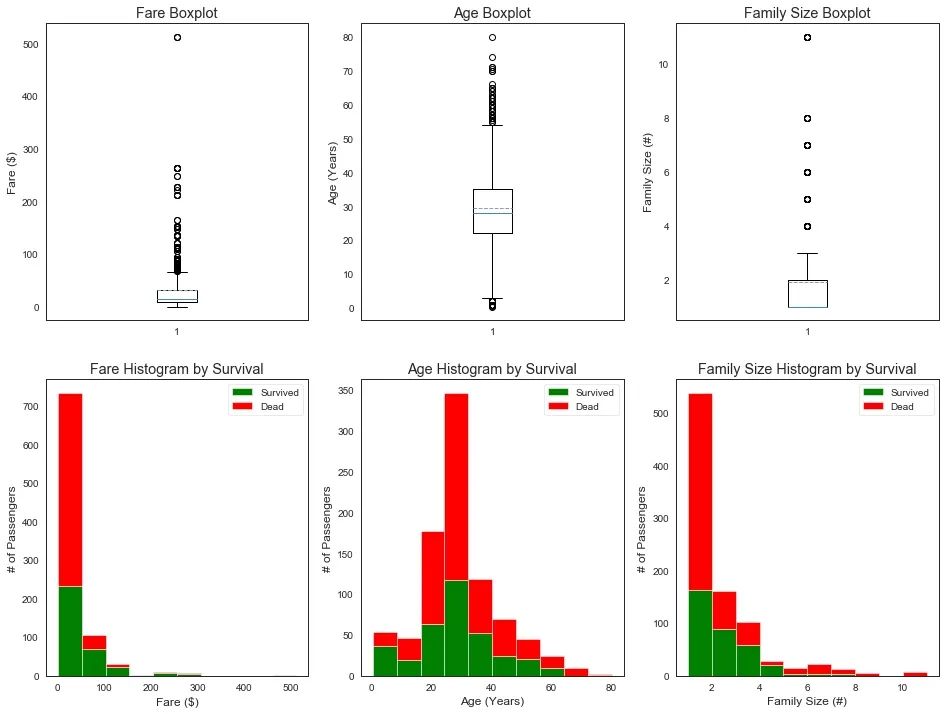
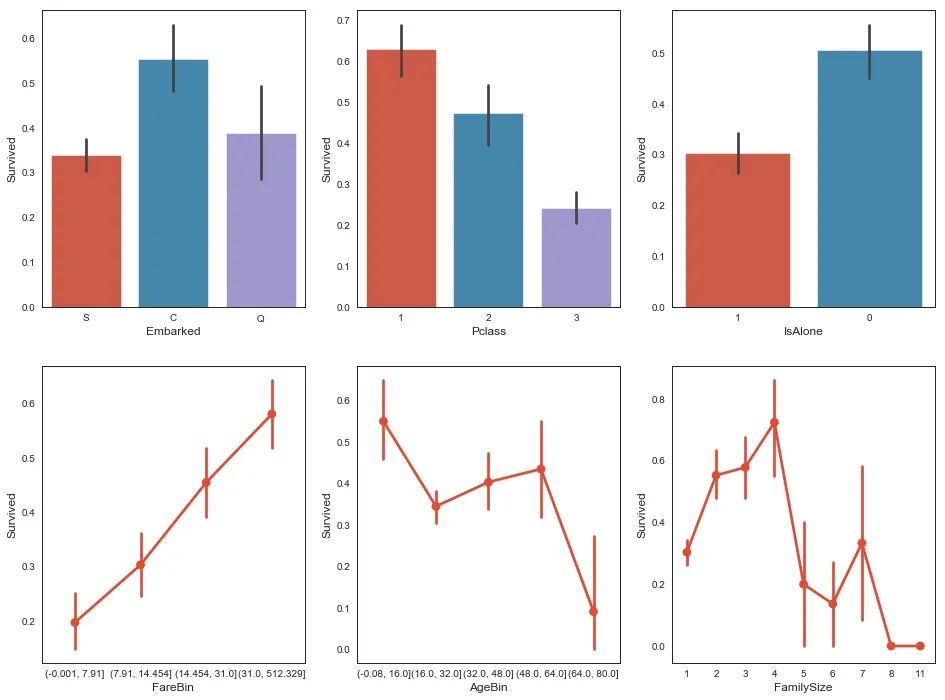
我们知道阶级对生存很重要,现在让我们比较不同阶级的特征。
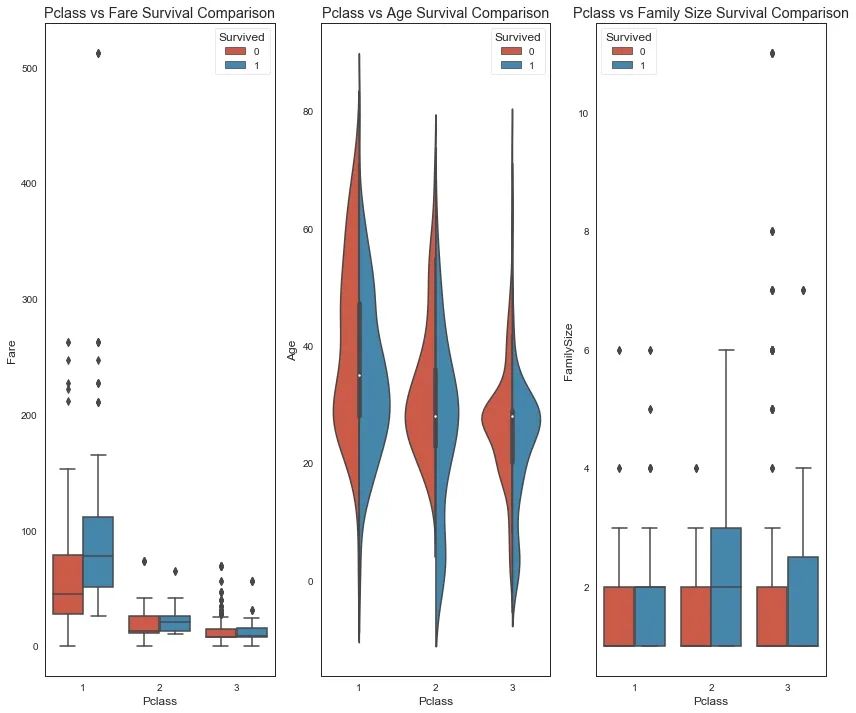
由图可看出:1)船舱等级越高,票价越贵。2)船舱等级高的人的年龄相对较大。3)船舱等级越高,家庭出游人数越少。死亡比例与船舱等级关系不大,另外我们知道性别对生存很重要,现在我们来比较一下性别和第二个特征。
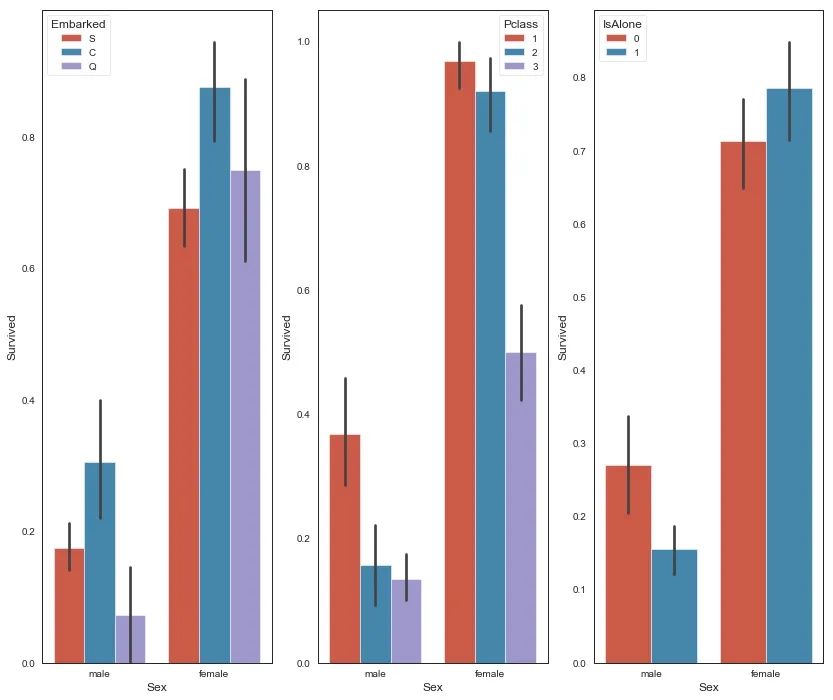
可以看到女性的存活比例大于男性,且C甲板、独自出行的女士存活率较高,接着观察更多比较。
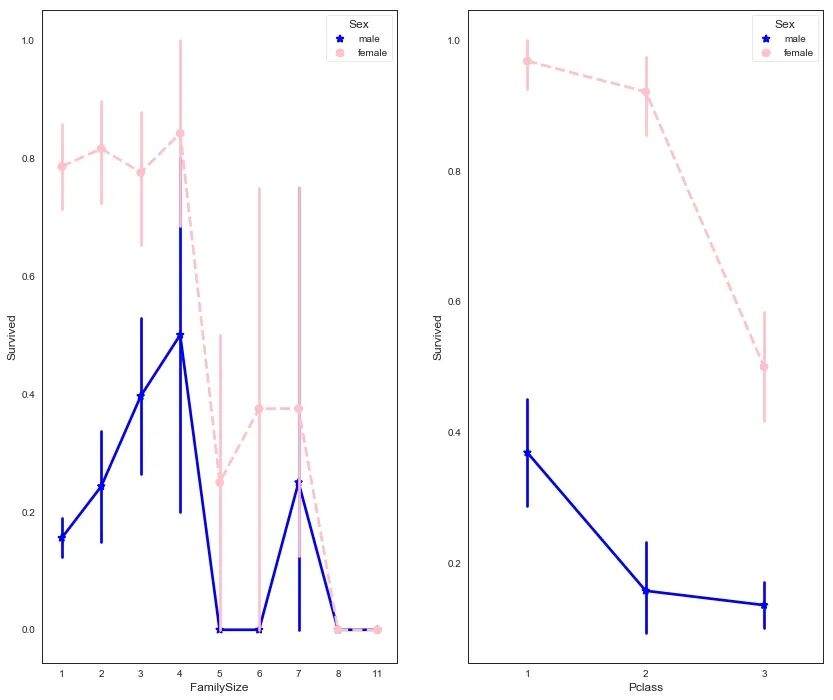
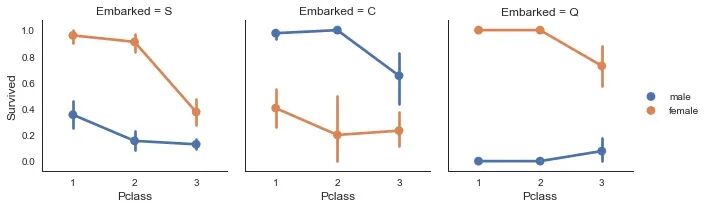
接下来绘制幸存或未幸存乘客的年龄分布。
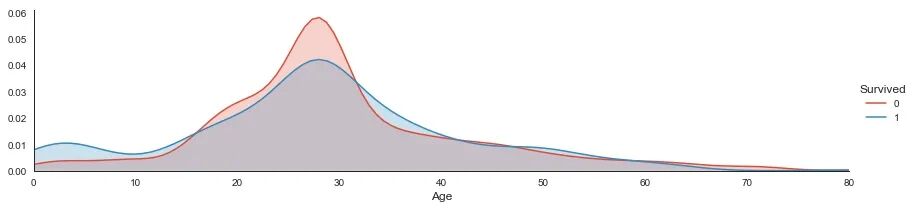
绘制幸存者性别年龄等直方图
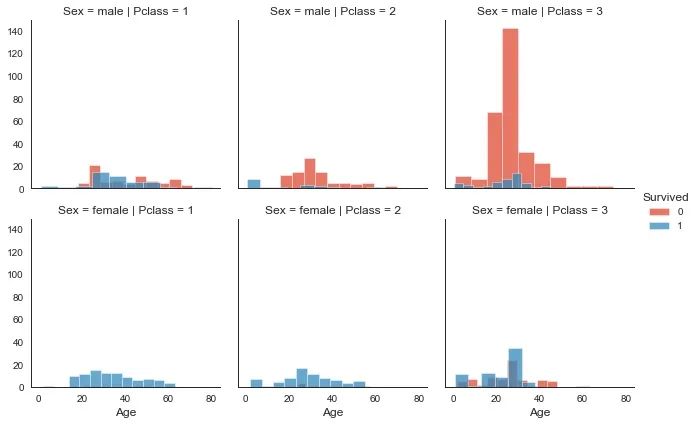
最后对整个数据集进行可视化

05
建模分析
首先,我们必须了解机器学习的目的是解决人类问题。机器学习可分为:监督学习,无监督学习和强化学习。在监督学习中,您可以通过向模型提供包含正确答案的训练数据集来训练模型。在无监督学习中,您可以使用未包含正确答案的训练数据集来训练模型。强化学习是前两种方法的混合,在这种情况下,模型不会立即得到正确答案,而是在一系列事件之后才得到强化学习。我们正在进行有监督的机器学习,因为我们正在通过向算法展示一组功能及其对应的目标来训练我们的算法。然后,我们希望从相同的数据集中为它提供一个新的子集,并且在预测准确性方面具有相似的结果。机器学习算法有很多,但是根据目标变量和数据建模目标的不同,它们可以分为四类:分类,回归,聚类或降维。我们将重点放在分类和回归上。可以概括地说,连续目标变量需要回归算法,而离散目标变量则需要分类算法。;另外逻辑回归虽然名称上具有回归,但实际上是一种分类算法。由于我们的问题是预测乘客是否幸存下来,因此这是一个离散的目标变量。我们将使用sklearn库中的分类算法来开始我们的分析。并使用交叉验证和评分指标(在后面的部分中进行讨论)来对算法的性能进行排名和比较。下面,我们将使用不同的方法进行比较(因代码过长,详细代码请在后台回复kaggle获得源码查看)。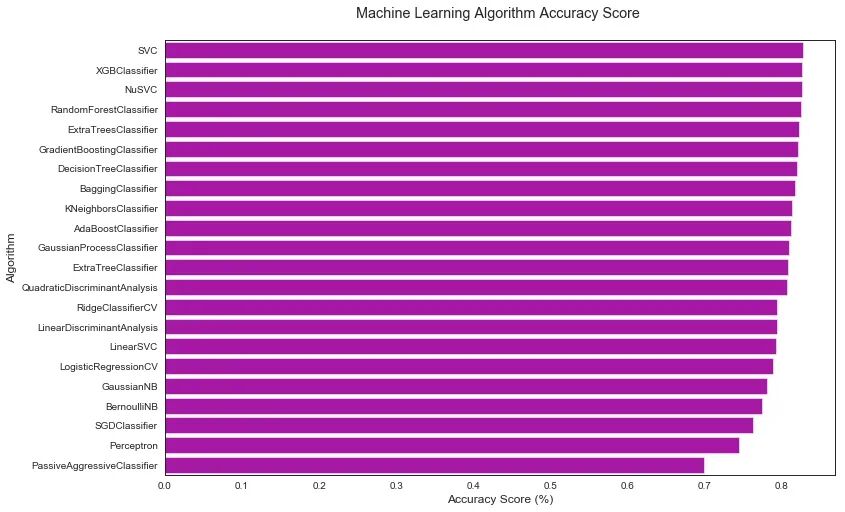
06
模型评估
让我们回顾一下,通过一些基本的数据清理,分析和机器学习算法(MLA),我们能够以约82%的准确度预测乘客的存活率。几行代码还不错。但是,我们始终提出的问题是,我们可以做得更好,更重要的是,我们可以为所投资的时间获得应有的投资回报率吗?例如,如果我们仅将精度提高1%,那么真的值得进行3个月的开发?因此,在改进模型时请牢记这一点。
在决定如何改善模型之前,让我们确定我们的模型是否值得保留。为此,我们必须返回到数据科学101的基础知识。我们知道这是一个二元问题,因为只有两种可能的结果。乘客幸存或死亡。将其视为硬币翻转问题。如果有一个硬币,并且猜到了正面或反面,那么您就有50-50的机会猜对了。所让我们将50%设为最差的模型性能。好了,没有关于数据集的信息,我们总是可以得到50%的二进制问题。但是我们有关于数据集的信息,所以我们应该能够做得更好。我们知道有1502/2224或67.5%的人死亡。因此,如果我们预测最高的概率,100%的人死亡,那么我们的预测的67.5%的时间是正确的。所以,让我们把68%作为坏的模型性能,任何低于这个的模型都没有意义,我可以预测对象全部死亡。这是一个纯手工制作的模型,仅用于学习目的。无需花哨的算法就可以创建自己的预测模型。1表示存活,0表示死亡。Coin Flip Model Accuracy: 49.49%
Coin Flip Model Accuracy w/SciKit: 49.49%
对结果进行汇总。
Survival Decision Tree w/Female Node:
Sex Pclass Embarked FareBin
female 1 C (14.454, 31.0] 0.666667
(31.0, 512.329] 1.000000
Q (31.0, 512.329] 1.000000
S (14.454, 31.0] 1.000000
(31.0, 512.329] 0.955556
2 C (7.91, 14.454] 1.000000
(14.454, 31.0] 1.000000
(31.0, 512.329] 1.000000
Q (7.91, 14.454] 1.000000
S (7.91, 14.454] 0.875000
(14.454, 31.0] 0.916667
(31.0, 512.329] 1.000000
3 C (-0.001, 7.91] 1.000000
(7.91, 14.454] 0.428571
(14.454, 31.0] 0.666667
Q (-0.001, 7.91] 0.750000
(7.91, 14.454
] 0.500000
(14.454, 31.0] 0.714286
S (-0.001, 7.91] 0.533333
(7.91, 14.454] 0.448276
(14.454, 31.0] 0.357143
(31.0, 512.329] 0.125000
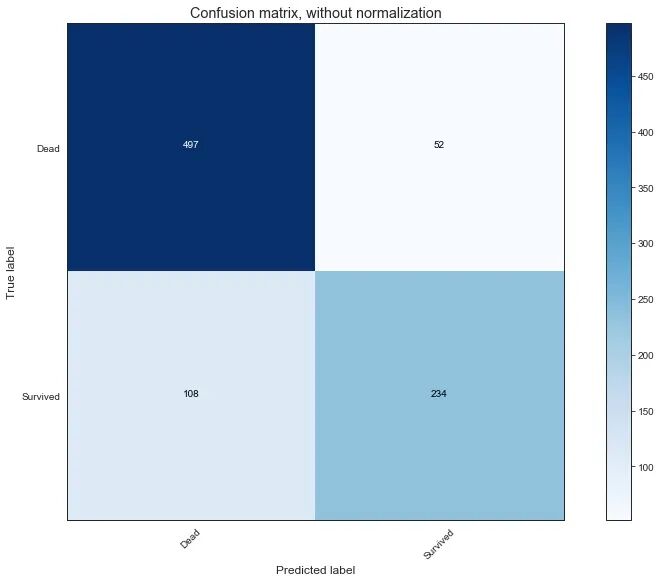
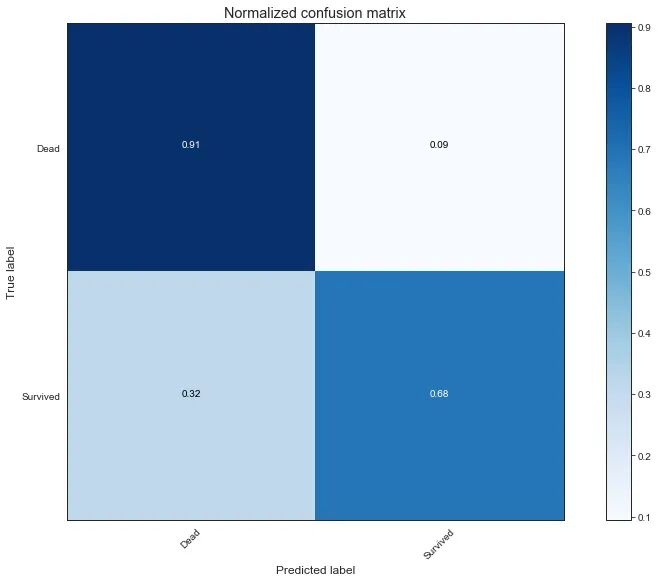
现在使用决策树进行建模并查看相关指标。
Decision Tree Model Accuracy/Precision Score: 82.04%
precision recall f1-score support
0 0.82 0.91 0.86 549
1 0.82 0.68 0.75 342
accuracy 0.82 891
macro avg 0.82 0
.79 0.80 891
weighted avg 0.82 0.82 0.82 891
交叉验证
接下来是交叉验证,但是重要的是我们使用不同的子集来训练数据来构建模型,并使用测试数据来评估模型。否则,我们的模型将过拟合。这意味着在“预测”已经看到的数据方面很棒,但是在预测尚未看到的数据方面很糟糕;这根本不是预测。这就像在学校测验中作弊以获得100%的成绩,但是然后当您去参加考试时,就会失败,CV本质上是多次拆分和评分模型的捷径,因此我们可以了解它在看不见的数据上的表现如何。它在计算机处理上要贵一些,但是这很重要,因此我们不会产生虚假的信心。这在Kaggle竞赛或任何避免一致性和意外的用例中很有用。超参数调整
当我们使用sklearn决策树(DT)分类器时,我们接受了所有功能默认值。这使我们有机会了解各种超参数设置将如何改变模型的准确性。(单击此处以了解有关参数与超参数的更多信息。)但是,为了调整模型,我们需要实际了解它。这就是为什么我在前几节中花时间向您展示预测的原理,因此你需要具体了解决策树算法的优点与不足在哪!下面是使用ParameterGrid, GridSearchCV和customizedsklearn scoring评分来调整我们的模型结果。BEFORE DT Parameters: {'ccp_alpha': 0.0, 'class_weight': None, 'criterion': 'gini', 'max_depth': None, 'max_features': None, 'max_leaf_nodes': None, 'min_impurity_decrease': 0.0, 'min_impurity_split': None, 'min_samples_leaf': 1, 'min_samples_split': 2
, 'min_weight_fraction_leaf': 0.0, 'presort': 'deprecated', 'random_state': 0, 'splitter': 'best'}
BEFORE DT Training w/bin score mean: 82.09
BEFORE DT Test w/bin score mean: 82.09
BEFORE DT Test w/bin score 3*std: +/- 5.57
----------
AFTER DT Parameters: {'criterion': 'gini', 'max_depth': 4, 'random_state': 0}
AFTER DT Training w/bin score mean: 87.40
AFTER DT Test w/bin score mean: 87.40
AFTER DT Test w/bin score 3*std: +/- 5.00
特征选择
正如一开始所说的,不是说预测变量越多模型就越好,而正确的预测因子可以提高模型的准确率。因此,数据建模的另一个步骤是特征选择。在Sklearn中我们将使用recursive feature elimination(RFE)与cross validation(CV)BEFORE DT RFE Training Shape Old: (891, 7)
BEFORE DT RFE Training Columns Old: ['Sex_Code' 'Pclass' 'Embarked_Code' 'Title_Code' 'FamilySize'
'AgeBin_Code' 'FareBin_Code']
BEFORE DT RFE Training w/bin score mean: 82.09
BEFORE DT RFE Test w/bin score mean: 82.09
BEFORE DT RFE Test w/bin score 3*std: +/- 5.57
----------
AFTER DT RFE Training Shape New: (891, 6)
AFTER DT RFE Training Columns New: ['Sex_Code' 'Pclass' 'Title_Code' 'FamilySize' 'AgeBin_Code'
'FareBin_Code']
AFTER DT RFE Training w/bin score mean: 83.06
AFTER DT RFE Test w/bin score mean: 83.06
AFTER DT RFE Test w/bin score 3*std: +/- 6.22
----------
AFTER DT RFE Tuned Parameters: {'criterion': 'gini', 'max_depth': 4, 'random_state': 0}
AFTER DT RFE Tuned Training w/bin score mean: 87.34
AFTER DT RFE Tuned Test w/bin score mean: 87.34
AFTER DT RFE Tuned Test w/bin score 3*std: +/- 6.21
----------
07
模型验证
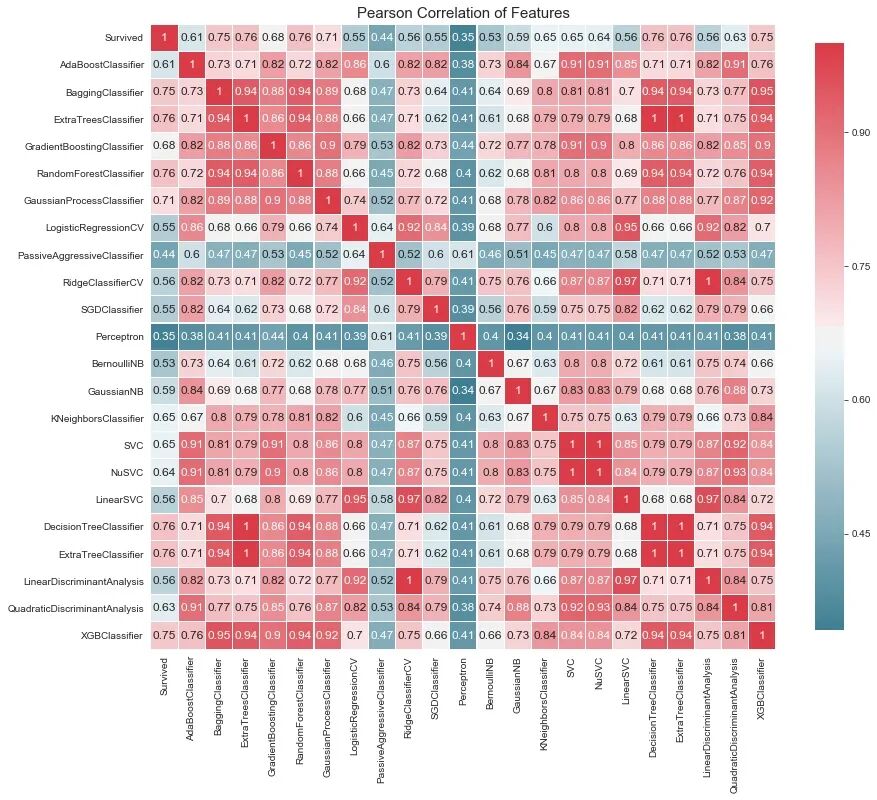
接下来是通过投票选择模型
Hard Voting Training w/bin score mean: 86.59
Hard Voting Test w/bin score mean: 82.39
Hard Voting Test w/bin score 3*std: +/- 4.95
----------
Soft Voting Training w/bin score mean: 87.15
Soft Voting Test w/bin score mean: 82.35
Soft Voting Test w/bin score 3*std: +/- 4.85
----------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 21 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 418 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 418 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
FamilySize 418 non-null int64
IsAlone 418 non-null int64
Title 418 non-null object
FareBin 418 non-null category
AgeBin 418 non-null category
Sex_Code 418 non-null int64
Embarked_Code 418 non-null int64
Title_Code 418 non-null
int64
AgeBin_Code 418 non-null int64
FareBin_Code 418 non-null int64
dtypes: category(2), float64(2), int64(11), object(6)
memory usage: 63.1+ KB
None
----------
Validation Data Distribution:
0 0.633971
1 0.366029
Name: Survived, dtype: float64
08
总结
最终我们得到了0.77990精度的模型。使用相同的数据集和不同的决策树实现(adaboost、random forest、梯度boost、xgboost等)并进行调优不会超过0.77990提交精度。对于这个数据集来说,有趣的是,简单的决策树算法拥有最好的默认提交分数,并且通过调优获得了同样最好的准确性分数。并且虽然在单一数据集上测试少数算法不能得出相同的结果,但在提到的数据集上有一些观察结果。同时训练数据集与测试/验证数据集和填充数据集的分布不同。这使得交叉验证(CV)的准确性得分和Kaggle提交的准确性得分之间有很大的差距。对于相同的数据集,基于决策树的算法,似乎在适当调整后收敛于相同的精度分数。为了更好的对齐CV评分和Kaggle评分,提高整体准确率,之后可以在预处理和特性工程上做更多的处理,这些就交给感兴趣的读者完成!https://www.kaggle.com/ldfreeman3/a-data-science-framework-to-achieve-99-accuracy/

豆瓣9.2分!17万条弹幕告诉你《沉默的真相》凭什么口碑高开暴走!











