反爬虫的几重措施
1.IP限制
如果是个人编写的爬虫,IP可能是固定的,那么发现某个IP请求过于频繁并且短时间内访问大量的页面,有爬虫的嫌疑,作为网站的管理或者运维人员,你可能就得想办法禁止这个IP地址访问你的网页了。那么也就是说这个IP发出的请求在短时间内不能再访问你的网页了,也就暂时挡住了爬虫。
2.User-Agent
User-Agent是用户访问网站时候的浏览器的标识
下面我列出了常见的几种正常的系统的User-Agent大家可以参考一下,
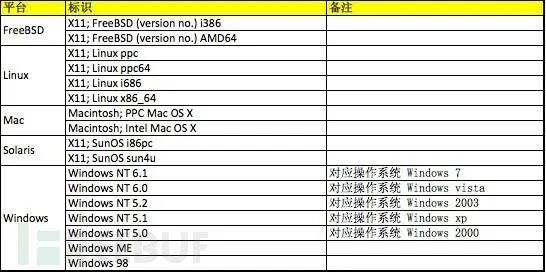
并且在实际发生的时候,根据浏览器的不同,还有各种其他的User-Agent,我举几个例子方便大家理解:
safari 5.1 – MAC
User-Agent:Mozilla/5.0 (Macintosh; U; IntelMac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1Safari/534.50
Firefox 4.0.1 – MAC
User-Agent: Mozilla/5.0 (Macintosh; IntelMac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1
Firefox 4.0.1 – Windows
User-Agent:Mozilla/5.0 (Windows NT 6.1;rv:2.0.1) Gecko/20100101 Firefox/4.0.1
同样的也有很多的合法的User-Agent,只要用户访问不是正常的User-Agent极有可能是爬虫再访问,这样你就可以针对用户的User-Agent进行限制了。
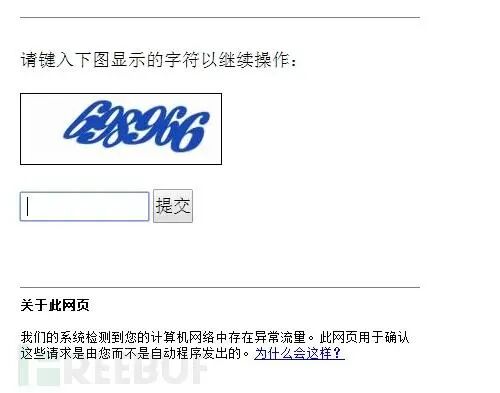
3、 验证码反爬虫
这个办法也是相当古老并且相当的有效果,如果一个爬虫要解释一个验证码中的内容,这在以前通过简单的图像识别是可以完成的,但是就现在来讲,验证码的干扰线,噪点都很多,甚至还出现了人类都难以认识的验证码(某二三零六)。

4.Ajax异步加载
5.Noscript标签的使用









